独立双(N)拥塞窗口的TCP单边加速思想
Posted dog250
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了独立双(N)拥塞窗口的TCP单边加速思想相关的知识,希望对你有一定的参考价值。
让TCP以流水线方式工作靠谱吗?也许你听说过MPTCP,也许你听过P2P下载是多么的天下人为我而我负天下人。
如果我能将一个TCP流拆分成多个TCP流,理论上来讲传输速度会有很大的提升,因为TCP拥塞控制算法是必须携带公平性收敛特征的(不然paper不会通过...),TCP反馈系统会为每一个加入的流分配一张船票,反馈系统不会管你们几个是不是一伙儿的,它只按人头计数,不会分组,这样就有很多好玩的事情可以做了。
我平时比较喜欢跟一些非工作关系的同行做技术交流,随便找个地方,或者就是打电话,大多是下班后,这样会显得比较轻松,惬意并且会大有收获,一般而言,交流沟通都是双向的,如果你老是听而自己不说的话,慢慢人家就会觉得你无非就是一个偷技术者或者说学生气未泯的书生,那种天天盯着别人在干嘛,生怕人家懂得太多把自己甩开的那种学生...上周末我跟前同事聊了个把小时,他目前在构思一个TCP虚拟流的概念,这也正是我比较感兴趣的,不谋而合。
一个超级简单的思路,那就是通过捆绑多个流来达到提速的目的,这个技术无关任何公司和个人的版权或者专利,分享出来也无伤大雅,时间过去了一周,天天做工没时间,又到了周末半夜三点起床的清爽时刻,总结一下,下面是关于这个技术交流的备忘。
首先简单说一下公平性以及公平性的指标
1.TCP的公平性
TCP的公平性指的是资源分配的公平,对于TCP而言,说的就是指带宽分配的公平。业内有一个公平性指数,如下所示: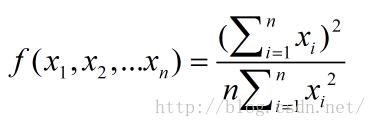

理论上来讲,没有任何算法可以在保证公平性的前提下可以获得比其它流更多的带宽,之所以也有像华夏创新这种,完全是建立在“其它算法不够好”这个基础之上打了擦边球。bic算法在某种特定场景下不是也有抢占性吗?业界专注了三十年也没有一个完美的算法,因此每个公司甚至个人都可以提出一个“在路上”的算法,注意,能被认可的在路上的算法,这是说那种真正考虑了公平性但打了擦边球的算法,业界并没有规定完美的公平,而只是规定了“可用的”公平,至于那种一个数据发两遍等诸如此类的方式,永远都是不登大雅之堂的。
除了那些自私的拥塞控制算法无法被接纳之外,它们自身也将面临算法失败巨大代价。在我们国家,很难想象一个普通公司里会有数学家,也不敢想象如此浮躁的环境可以让一个公司或者个人坚持一个方向数十年,不必说几乎所有的自私拥塞算法已经排除了公平性,它们连自身的“效率-流量”都无法权衡,完全就是以量取胜,这也完全符合我们骨子里的本源,然而运营商那里的流量是要买单的,谁买单那就是另一个话题了。
所以说,与其说费力去开发一个最终还可能不成功的“在路上”的拥塞控制算法,不如说简单一点,在算法之上设计一个新协议。
2.多个流之间的公平性
目前Linux系统默认的拥塞控制算法是Cubic,它工作地非常好,公平性表现也很出色,如果我相信它的表现,那么如果我再可以把一个TCP流变成两个或者N个TCP流,那么这N个TCP流将公平地分享到达接收端的带宽。为了让讨论更加直观,我将模型简化。
假设节点A为发送端,节点B为接收端,中间链路总带宽为W,当前链路上有m个TCP流共享带宽W,按照公平性,每个TCP流的带宽为 W/m,作为其中一员的A-tcp-B,自然它的带宽也是 W/m,现在如果我将该TCP流拆分了,拆成了n个流,那么当前链路上存在的TCP流的数量变成了 m+n个,按照公平性,每一个流的带宽为 W/(m+n),其中 n*(W/(m+n))的带宽属于我。现在证明 n*(W/(m+n))>W/m
程序员不是数学家,如果能有直观的东西就不想去分类讨论,上述结论的证明归为以下:

眼睛看上去,很直接,但有没有更直接的呢?但是如果用数学推导的话,肯定会把大把精力花在实数域的分类讨论上,一个经典问题就是求x+y=xy的整数解,实数解之类,但对于我们这个特定的场景而言,这种定量的推导是不必要的,因为场景本身就可以抛开很多具有数学意义但不具有现实意义的情况,我们只要瞄准90%以上的市场即可,这就是现实与数学的差异。这次我要换一种方式,用gnuplot这个神器来看看,我把两个函数画在一张图上,这很容易做到:
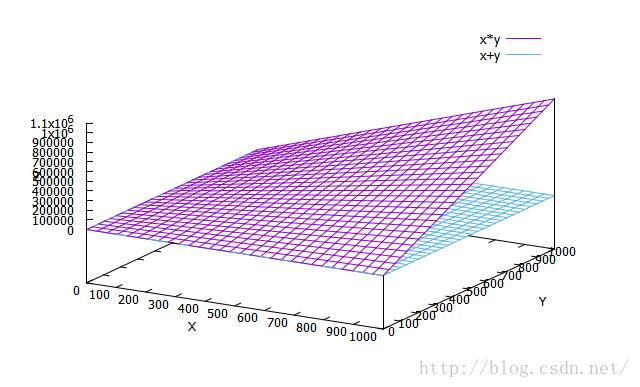
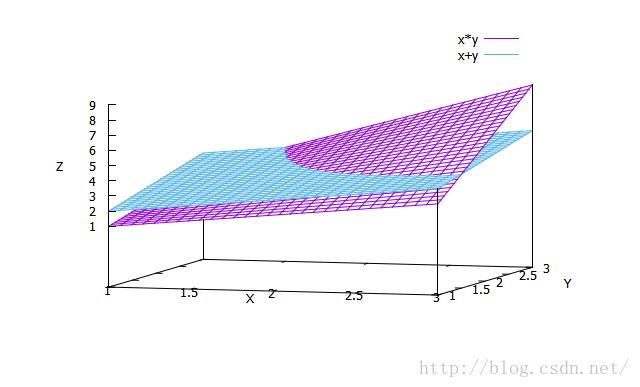
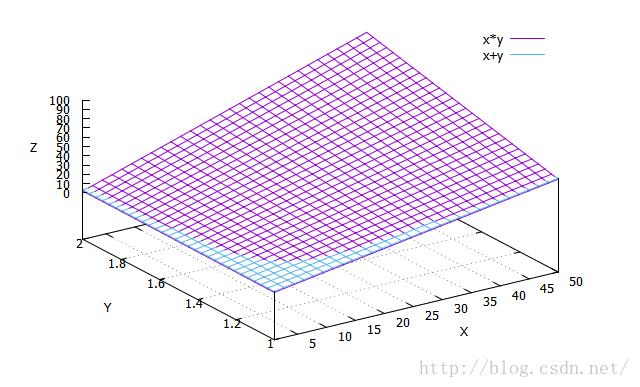
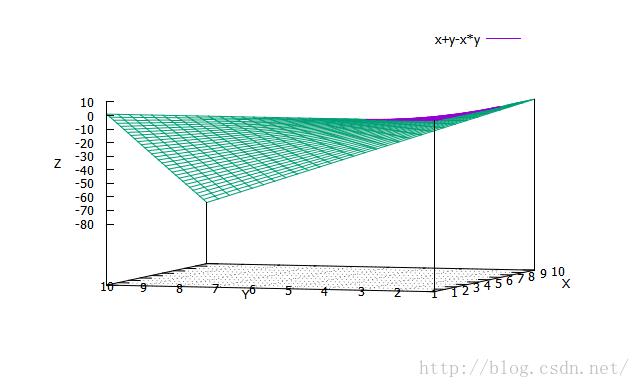
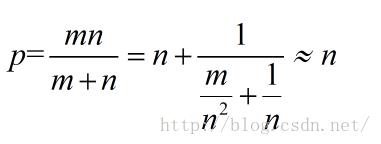
在n远小于m的时候,加速比收敛于n。这个公式看起来不是很直观,再一次,我们用gnuplot来看:
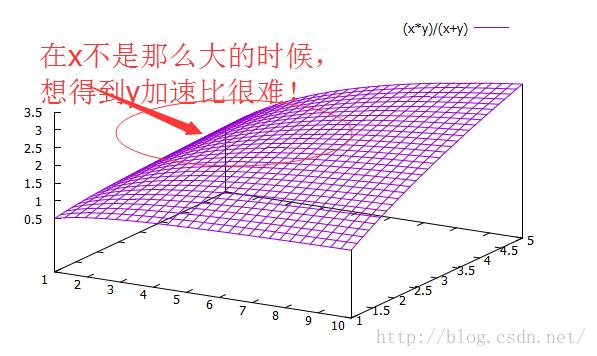
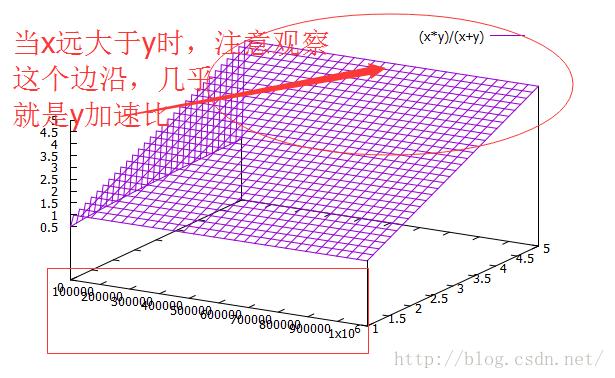
在实际的实现中,n往往受制于系统的开销不能太大,10量级即可看到效果,在我的这个双窗口单边方案中,我自然选择2即可。
3.TCP流组间公平性
上面我们提到,MPTCP以及迅雷都采用了捆绑流的方式来获得最佳的加速比,这两种方案又有不同,MPTCP是在TCP层将流进行捆绑,而迅雷之类的P2P软件则是直接将应用数据进行了拆分,直接在应用层创建了多个流,哪一种方式更好呢?其实无论使用哪种方式,都涉及到了对原有的应用程序或者协议栈进行修改,大部分场景下无法推动,但是它们的这种做法却直接给了我们一些思路。它们之所以可以这么做,是由于TCP虽然规定了流与流之间必须公平共享带宽,但是并没有规定流与流之间协作的细节。我们知道,竞争和互助永远都是任何事情的两个面,一直在相互转换。
类比进程调度的一些原理,近些年来,由于容器,轻虚拟化等技术的兴起,组调度策略也变得越来越复杂。早期的时候,调度的公平性是在进程与进程之间展开的,后来由于进程少的会话会被进程多的会话饿死之类,就引入了类似分组调度。最终,进程调度完全变成了一个分层的机制,谁也无法钻空子了。目前TCP拥塞控制还不是一个分层的机制,起码在协议规范的层面上没有,这就留下了很多空子。
但是,目前的分层分组拥塞控制机制在TCP之外却普遍存在,比如路由器交换机,很多实现了加权公平队列,它们可以根据源IP/目标IP对进行分组,也可以通过目标端口进行分组,甚至可以通过TCP的初始序列号指纹进行分组,由此,只要来自相同的主机,去往相同的服务器的所有TCP流,可能就会被作为一个流来对待,这就为多流捆绑的TCP加速实现造成了很多的障碍。
不过不管怎么说,我们并不是需要完美的N加速比,而是一个可用的N-加速比,不是吗?
4.双(N)拥塞窗口TCP单边加速
前面都是铺垫,分别描述了:1).为什么TCP的新拥塞控制算法很难开发?-因为效率和公平必须权衡但却很难权衡。
2).为什么多流捆绑可以获得收益?-完全基于数学推导,gnuplot非常好用且直观。
3).为什么多流捆版可以实行?-因为TCP没有规定不能这么做。
4).为什么即便是多流捆绑也很难获得N加速比?-因为中间设备会进行流量分组调度。
5).为什么成型的方案无法直接使用?-因为MPTCP是双边方案,要改双方协议栈,P2P是应用层方案,太复杂。
最终我们只剩下了一个问题,那就是:
6).基于上述1-5,怎么实现我们自己的多流捆绑的TCP加速方案?
我们知道,TCP是按序发送的,在拥塞窗口内(我们暂且忽略对端通告窗口的限制)依照序列号每次递增1依次发送,为了实现两个拥塞窗口,我们引入“TCP虚拟流”和“虚拟序列”的概念,虚拟序列将不再保证序列号在发送中每次递增1,而是递增w,w的值由“平滑参数”控制,如下图所示:
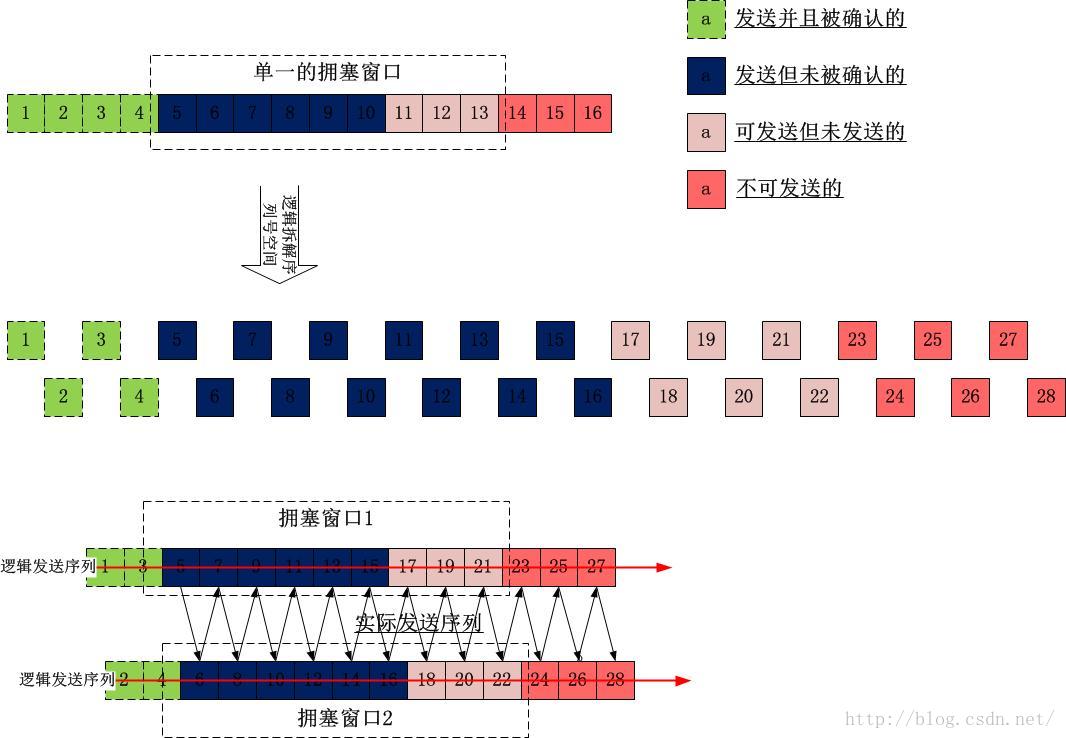
TCP虚拟流如何响应ACK
TCP收到ACK的时候,会清除发送队列中被确认的数据并例行一些“记账”的公事,这个记账主要记录这个ACK一共ACK了多少数据,RTT的测量等,这个账本记录会反过来影响拥塞控制算法的执行策略。标准的TCP中,ACK是积累确认的,一个ACK可以确认多个段,然而对于双拥塞窗口里面的TCP虚拟流而言,是要分别记录两个账本记录的,考虑以下的ACK序列:
LAST_UNA:10
THIS_ACK:21
很显然一个ACK确认了10个段,在双窗口TCP虚拟流中,每一个发出的数据段都有一个与之绑定的“虚拟序列号”,它记录了这个数据段是在哪个窗口中被发送的,收到一个ACK进而在清理发送队列并记账的过程中,TCP会将账目信息记录在与该被确认的段对应的TCP虚拟流中,比如上述ACK序列:
LAST_UNA:10
THIS_ACK:21
10[cwnd0],11[cwnd1],12[cwnd0],13[cwnd1],14[cwnd0],15[cwnd1],16[cwnd0],17[cwnd1],18[cwnd0],19[cwnd1],20[cwnd0]
我们看到,数据20是在拥塞窗口0中被发送的,那么就由拥塞窗口0来执行清理发送队列和记账任务,但是它要把拥塞窗口1的信息记账给TCP虚拟流1而不是它自己,因此账目信息如下:
TCP虚拟流0【记账者】
被确认的数据明细:6个,分别是10,12,14,16,18,20
TCP虚拟流1
被确认的数据明细:5个,分别是11,13,15,17,19
然后TCP虚拟流0和TCP虚拟流1分别基于上述的账目信息来调整自己的拥塞窗口。
TCP虚拟流如何响应拥塞
由于两个虚拟流的拥塞窗口是独立控制的,因此我们不希望它们有粘连,我们不希望一个虚拟流的行为影响另一个,最终,我认为一个比较合理的策略就是,当在一个窗口中检测到拥塞(比如三次重复ACK之类)的时候,另一个虚拟流的窗口只是简单的“僵持住”,也就是停止其AI,但是不缩减窗口。但是由于虚拟序列号组必须可以合并成一个完全按序的真实序列,一旦一个窗口内检测到了比如说重复ACK,那么另一个窗口的虚拟序列号也将无法向前推进,这类似于“流水线停滞”现象,事实上也就是流水线停滞!你也可以将这种现象叫做虚拟序列号同步现象,随便怎么说。所以说,为了尽快让流水线再次启动,这里还有一个策略就是“拥塞互助”,说的是一个窗口内检测到了丢包而必须重传数据包的时候,另一个窗口虽然不缩减但是也要打破自己的虚拟序列号序列,去帮助检测到丢包的窗口内的重传操作。广义的拥塞互助就是只要一个窗口内检测到了拥塞,则所有的虚拟流都要进入快速重传快速恢复阶段,所有虚拟流的虚拟序列号重新编号,编号从重传包的第一个开始。待重传完成(NewReno退出快速恢复阶段)后,虚拟序列号按照进入快速恢复时重新分配的继续编号。
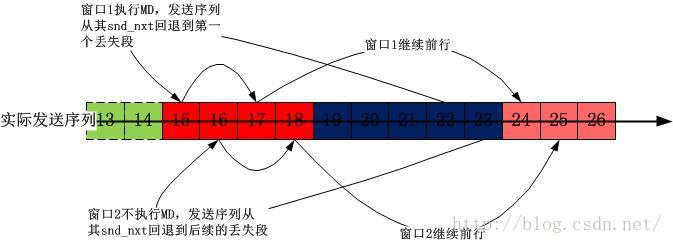
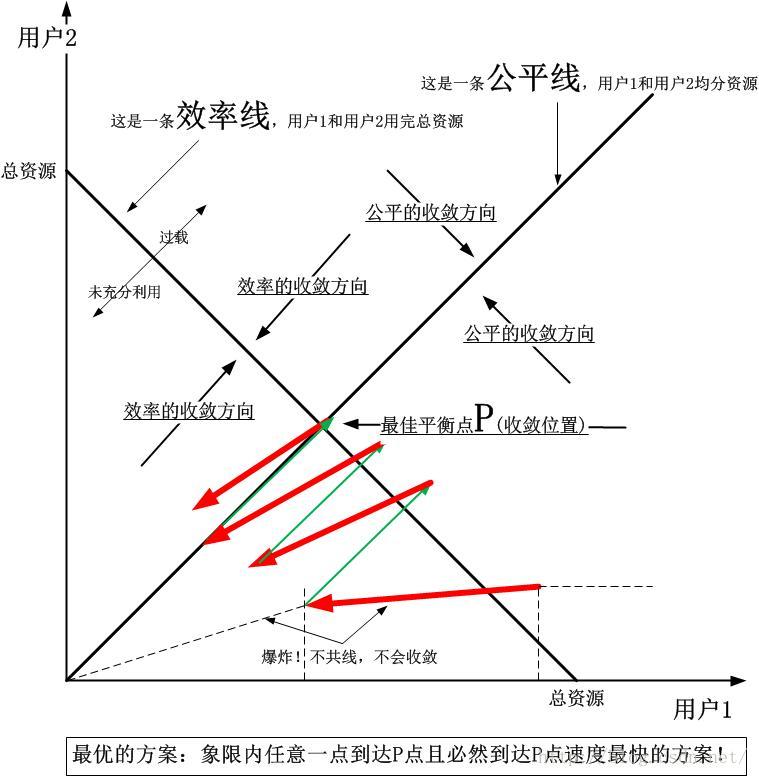
咋一看,好像这个思想其实就是本来应该发x个数据的,现在发x+a个数据,这个和Reno,Bic,Cubic在一个窗口内多发一些数据有什么区别?答案在于这里的方法中x和a是独立的,二者均受到其自身发送数据的ACK以及RTT的独立驱动。还记得那张“公平-效率”坐标系吗?我第三次把那个图贴如下:
TCP虚拟流类比分时系统
TCP虚拟流之间轮转发送类似于将顺序的程序拆分为多个进程或者线程,然后时间片轮转分配给这些进程或者线程,如果原始的程序没有睡眠等待操作,在单核心上这没有任何意义,平添了切换调度的开销,但是如果原始程序中有等待之类的操作,那么拆分后在线程1等待的时候,线程2就可以继续利用CPU。你可以把整个端到端的TCP发送行为看作是一个顺序执行的程序,而中间网络就是一个CPU集合,当窗口1由于检测到拥塞而停止发送的时候,窗口2可以继续发送,和进程调度系统一样,网络本身也在进行资源的公平分配。那么问题来了。见“附加价值”TCP虚拟流的附加价值
窗口1既然已经停止发送了,那么按照拥塞控制的理论,它是检测到了网络拥塞才停止发送的,此时窗口2继续发送有意义吗?这不是添堵吗?双窗口,甚至N窗口的有利副作用此时要表现出来了。问题在于“窗口1中检测到拥塞”的可信度有多高!我们知道,网络中有很多的假拥塞,特别在无线环境中,如果是假拥塞,窗口1缩减就是不必要的。我们分类讨论。1).如果窗口1中检测到了真拥塞
此时窗口2中的发送行为也将检测到拥塞,进而缩减窗口。2).如果窗口1中检测到的是假拥塞
此时窗口2中的发送行为可能不会检测到拥塞,这将弥补窗口1中的误判!这里使用的Bloom Filter的思想,为了避免精确匹配的开销,采用了“少数服从多数”的原则,我们可以预见,独立的拥塞窗口数目越多,对拥塞的判断就越准确。在所有窗口都是独立控制的情况下,所有窗口中大部分均误判拥塞的概率极低!
因此,这个“双(N)窗口TCP单边加速”在AI(加性增)阶段,可以提高带宽利用率,在MD(乘性减)阶段可以降低拥塞误判率。
最后我们来看一下加速比方面的问题,本节是定性的分析,并没有定量分析。
TCP虚拟流的串行加速比
严格来讲,串行发送的双TCP虚拟流的总发送时间和标准TCP流的总发送时间是一样的。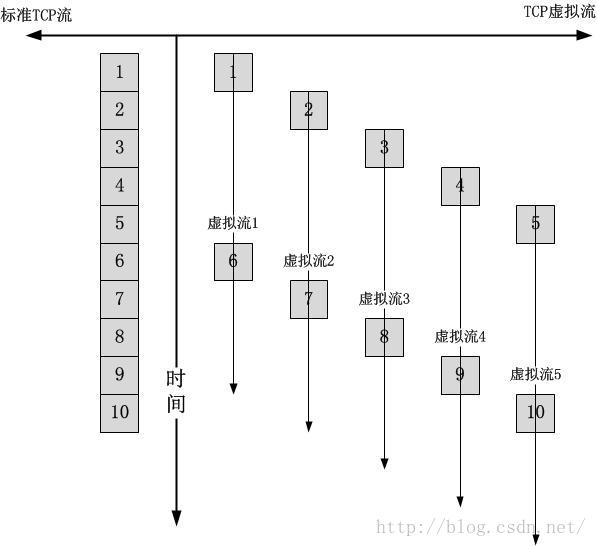
由上图可以看出,如果TCP按照标准流序列发送,假设拥塞窗口是10,那么它只能发出去10个段,然而创建了5个TCP虚拟流之后,每一个虚拟流的拥塞窗口都是独立计算的,这里n就是5,而m可能是一个数以万计的数值,此时每一个虚拟流计算出的拥塞窗口应该接近于10,这就达到了N加速比。
串行TCP虚拟流还有两个额外的作用,那就是:
1.可以平滑网络设备整形的影响
如果是标准的TCP流的发送,即便的连续发送的段,到了接收端也可能被整形成阵发的到达的形式,这个我也在多篇文章中有所提及。加入多个TCP虚拟流之后,可以有效弥补整形之间的空闲时隙,但是有个前提,那就是,整形设备必须不依赖五元组进行整形,虽然很少见,导致这个有利的副作用很少有人被惠及,然而世事总归聊胜于无。2.降低延迟ACK导致的ACK时钟的慢拍问题
如果TCP数据接收端启用了延迟ACK,这其实也算是一种整形方式,不同的是,整形针对的不是数据,而是ACK,然而被整形的ACK流会反过来作用于数据流。使用多个TCP虚拟流在接收端看来并无法识别这多个虚拟流,客户端感知到的只是数据的到达更加快了,更加平滑了,因此ACK更容易被触发了。TCP虚拟流的并行加速比
在超高速网络中,有一条优化原则是降低时延!此时串行TCP虚拟流就显得不合适了,我们更希望的是两个或者多个TCP虚拟流同时被发送,MPTCP就是这么做的,但是由于我们是一个单边加速方案,没有接收端会配合我们去重组多个流为一个流,考虑到网络的无序性,如果我们在多个CPU核心同时并行发送以下的TCP虚拟流:虚拟流1:1,3,5,7,9,11
虚拟流2:2,4,6,8,10,12
考虑到网卡调度同样不保证时序,接收端存在很大的乱序收包的概率,而这对于接收端的接收缓存是一个极大的考验!只要有一个空洞未被补全,数据就无法向上层交付!因此解决方案就是同步并行发送,每个TCP虚拟流在不同CPU核心上的发送时机与其前一个TCP虚拟流的发送错开一个固定的间隔时隙:
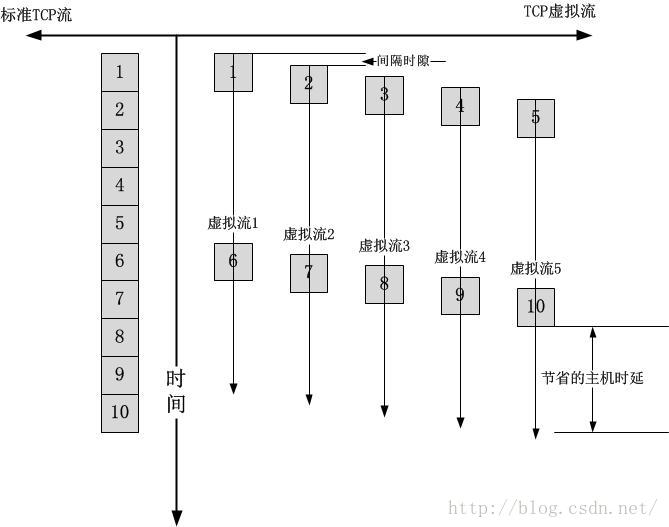
由上我们知道了TCP虚拟流主要是提高了带宽的利用率以及避免了拥塞误判,最后在高速网络上,它还可以减少主机延时。
关于实现的Tips
说实话这个实现起来比抄一个拥塞控制算法简单多了,而且在2014年迷茫的时间跟经理的一次谈话也让我明白,善于组装东西的人可能比善于制作构件的人更加优秀,但大多数情况下会被人觉得没有制作构件更酷。这个TCP虚拟流明显就是组装行为,没啥技术含量,对于Linux协议栈而言,只需要把tcp_sock结构体里面的跟拥塞控制相关的字段改成数组即可,比如snd_cwnd就改成snd_cwnd[2]...就这样。然后独立地根据ACK应答来去控制这些变量值的变化,可能还需要为TCP控制块结构体加一个虚拟序号字段,保存该skb目前由哪个虚拟流所持有。我就不明白为什么有人会觉得这样是“乱改内核”!
不想改内核也可以,那就用Netfilter的HOOK来做,该IP层HOOK完全接管TCP层传下来的所有数据,直接回复ACK给上层,造成一种数据已经送达的假象,事实上数据只是被缓存在这个HOOK的缓冲区里而已,每一个CPU核心启动一个内核线程来独立处理拥塞窗口的AIMD,然后各个虚拟流自行从缓冲区里取数据并发送之。很简单的一个模型,这个Netfilter HOOK事实上只是一个代理,把这个HOOK单独抽出来做到一台设备里,这就是可以卖钱的加速网关了,而且真的可以卖钱!但是如果你不把这个装到盒子里,而只是作为一个温州老板从卖皮鞋改成卖内核模块,根本无法卖钱,或者说,起码很难。
以上是关于独立双(N)拥塞窗口的TCP单边加速思想的主要内容,如果未能解决你的问题,请参考以下文章