IDC网络TCP拥塞控制随想录
Posted dog250
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了IDC网络TCP拥塞控制随想录相关的知识,希望对你有一定的参考价值。
“若不对症下药,无异于群盲摸象。“ 这是本文第一句话,本文的倒数第二句话在倒数第二句。
用广域网拥塞控制的思路做IDC网络拥塞控制无疑会误入歧途。
把精力集中在TCP单边优化,企图用一个算法来覆盖IDC网络所有的流量,进行全局拥塞控制,这带来了很多限制。
与之相反,如果希望交换机带来更多信息指导拥塞控制,这无疑是另一极端。类似交换机的INT(In-band Network Telemetry)助力HPCC,那就真把IDC网络当成一块主板了,场面过大,多团队需要配置,容易讲述人月神话的故事。
有没有简单直接的把戏呢?
IDC网络比较难搞的是incast流,这种流显然无法用常规拥塞控制思路处理,除了它的突发,汇集特征导致自身的延迟,丢包外,也会影响其它流量:
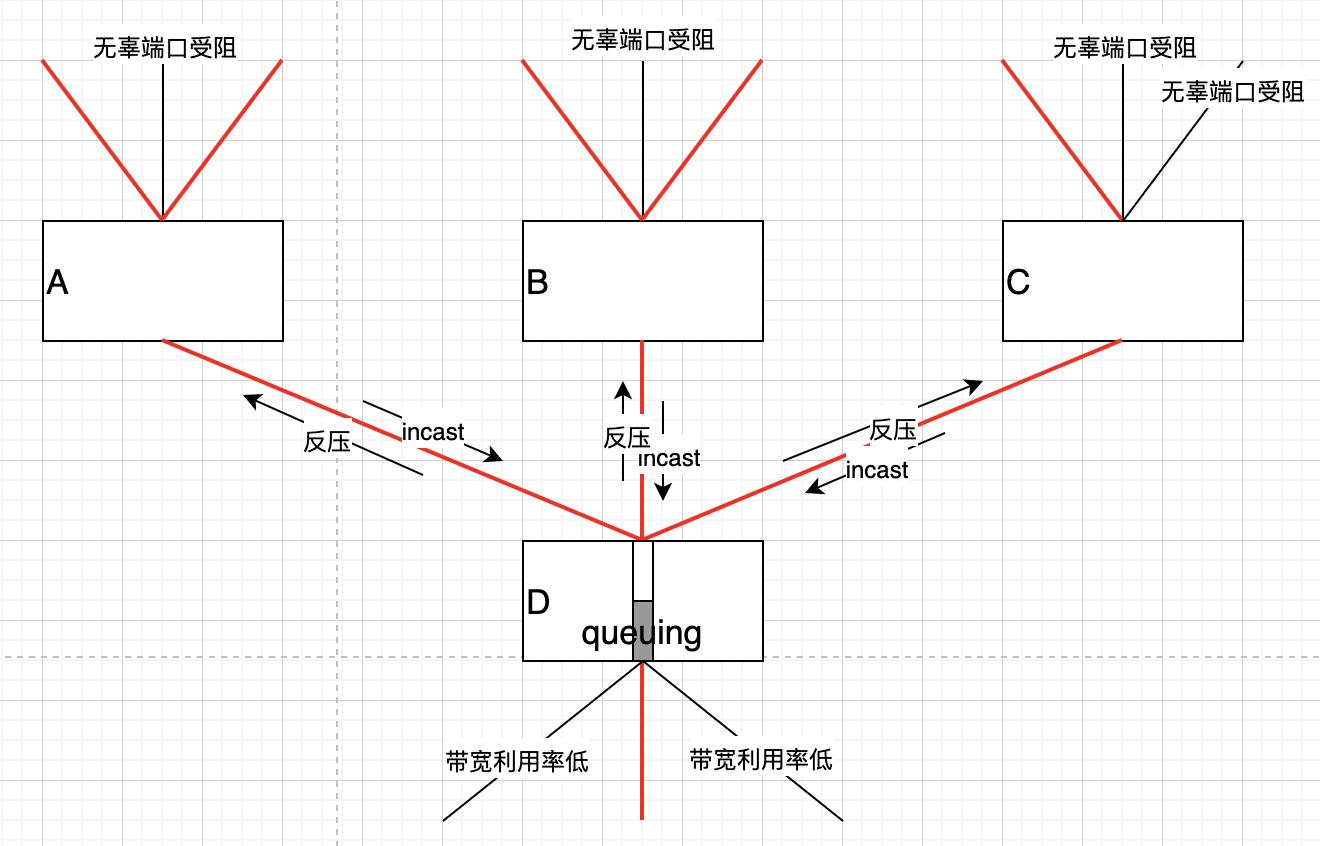
由于瓶颈D处触发了PFC反压,一时间,交换机A,B,C均将queuing并可能标记ECN,因此ECN的指示并不靠谱,甚至QCN在这种情况下也不靠谱,即便INT带回的丰富信息也不知道该咋用。不光传统的拥塞控制算法失效了,就连专门的IDC ECN拥塞控制机制也失效了。
该情况下,假设incast流都预期以oneshot形式在一个RTT内完成,传统算法对谁都不利:
- 对非incast流:等收到拥塞信号后,incast流已经结束,任何措施都不再必要。
- 对incast流:突发,聚集后,丢包已经发生,延时已经增加。
如果没有incast会怎样?甚至都不用PFC反压,BBR最适合这种规则的拓扑。为了不使buffer溢出,PFC反压进行了源抑制。但这些都必要吗?
incast引发问题,那就针对它就是了。最最最简单的方法:
- 识别incast业务。
- 控制其拥塞窗口为1~5的小限额。
- 强制pacing发送,保证不会导致buffer溢出。
- 上述3点为基础,调小RTO(不要试图修改算法!)。
这才是正确的解法。
即便识别不了incast业务,那便识别大象流,大象流一般有固定端口,比如数据库存储,大数据块同步。除这些流采用常规拥塞控制之外,其余一律限制cwnd并强制pacing。
如果业务可以通过API设置自己是incast,那问题就解决了,凭何让让端到端算法于一个RTT感知业务流类型呢?
这么简单的事情看起来会比较low,再复杂点,可以在接收端做拥塞控制。
对吞吐有要求的incast流,比如那种传输1MB+级别数据块的流,控制发送端cwnd显然会影响其吞吐,那就在接收端做文章:
- 定时器维持固定小间隔(或一个RTT)计算接收速率R。
- 定时发送1字节的乱序包到发送端以测量RTT。
- 通过R和RTT计算BDP,作为一个窗口值插入ACK的wnd字段。
通过通告窗口来控制发送端的发送量,不失为一个黑科技。发送端不用改,也算一种单边措施。
这样会有效减少incast流对其它无辜流的影响,更进一步,比如你已经可以通过动态识别或者API设定识别到incast流,当接收端收到CE标记包时:
- 对非incast流:没有计算好R时回传CE标记通告拥塞,计算好R之后不回传CE标记但将BDP回传。
- 对于incast流:无论如何都回传CE标记,计算R和BDP,并将BDP回传。
有一篇论文提到的算法和我上面这个思路很类似,但更加系统化:
https://www.usenix.org/system/files/nsdi20spring_cheng_prepub_0.pdf
我觉得接收端驱动的拥塞控制才是正确做法,接收端可以一步到位确定真实的最大瓶颈带宽,而不像传统拥塞控制算法那样靠probe猜测,或者只靠一个数学公式保证收敛。
本质上,还是BBR那一套:
- 达到最大带宽时,BDP就是保持最小RTT的极限。
识别incast并采取上述简单的措施,目标可达:
- 不queuing,保证流FCT。
- 压满带宽,保证流吞吐。
此外,IDC应有一张整个CLOS两两主机之间的RTT表,任意流路径跳数几乎都很规则,去查表就行,要么就带外探测RTT。带内探测RTT不靠谱,IDC网络RTT极小,带宽极大,BDP对RTT极敏感,排队延迟在总RTT中占比极大,排队对DBP的计算影响极大,这对拥塞控制就是灾难。换句话说,IDC网络没有足够的时间去消化排队造成的影响。
总结一下接收端驱动的拥塞控制就是:
- 接收端自行决定是否回传CE标记。
- 接收端主动回传实际瓶颈BDP。
- 发送端拥塞控制算法可随意。
更普遍的IDC网络拥塞控制思路就是:
- 不要为了特殊流“优化”(劣化)普适算法,针对性搞它就是了。
- 若有全局的SDN控制器就好了,但不是没有嘛。
普遍的拥塞控制算法太过理想,短突发流普遍存在,传统基于长流模型的拥塞控制完全无法应对。传统拥塞控制过于关注识别拥塞丢包和噪声丢包,但本质还是识别哪些退避不必要。
若按流分类,仅存在两种策略,要么谁拥塞谁负责,要么谁拥塞谁先过(incast FCT first),二者不可调和,这是广域网任何普适拥塞控制算法效果不佳的根源,但对广域网,收敛第一,也就无所谓追求极致了。
但IDC网络是规则的,传统拥塞控制并不适用,甚至TCP本身都不适用。拥塞控制在可控环境便是谁的问题控制谁,关键是有简便做法。广域网很难做双边,在IDC网络却很容易,若拿做双边需要改接收端作为不做的理由,那就是自废武功。不做双边完全是因为太困难,向下兼容永远是被逼的,如果没了这些限制,谁能不做?
广域网因为其自组织复杂性导致很难针对性地控制,不得已将目标落实到收敛:
- 要保证所有流基本的传输可用性,必然要收敛到公平。
对IDC网络,收敛则属次要,甚至不必要,因为有条件并有能力针对性拥塞控制了。指望incast流和大象流收敛到公平,却不能定义公平。显然基本的问题都很难。
说TCP本身。超高速超短距环境并行传输才是吞吐的关键,考虑可靠性,又倾向于串行传输,TCP显然属于串行协议。MPTCP使串并行可同时实施。当年的串口,并口之争有点这意思。IDC网络规则的构造为MPTCP铺平了路,如果在广域网,MPTCP只能做active-standby,loadbalance效果肯定不好。MPTCP在IDC并不破坏保序,受惠于IDC网络的规则性,即便是基于包的MP LB,接收端也只需执行归并排序。
“功能,越通用越好,但不存在通用的性能优化方法,极致的性能来自于针对性!“这是本文的倒数第二句话。
浙江温州皮鞋湿,下雨进水不会胖。
以上是关于IDC网络TCP拥塞控制随想录的主要内容,如果未能解决你的问题,请参考以下文章