PythonScrapy入门实例
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PythonScrapy入门实例相关的知识,希望对你有一定的参考价值。
Scrapy
Scrapy是一个使用Python编写的轻量级网络爬虫,使用起来非常的方便。Scrapy使用了Twisted异步网络库来处理网络通讯。整体架构大致如下:
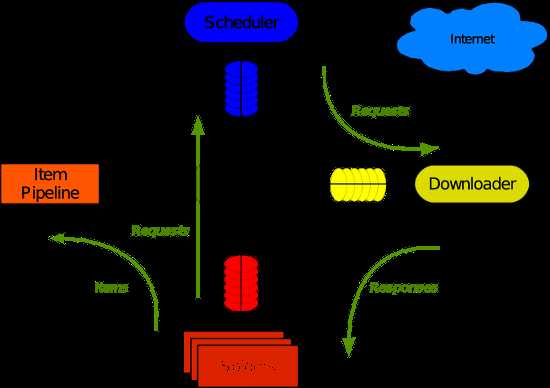
创建一个Scrapy项目
S-57格式是国际海事组织(IMO)颁布的电子海图标准,本身是一种矢量海图。这些标准都公布在http://www.s-57.com/上。以该网页为抓取对象,进入存储代码的目录中,运行下列命令,创建项目 crawls57:
scrapy startproject crawls57
该命令将会创建包含下列内容的 crawls57 目录:
crawls57/ scrapy.cfg crawls57/ __init__.py items.py pipelines.py settings.py spiders/ __init__.py ...
这些文件分别是:
scrapy.cfg: 项目的配置文件crawls57/: 该项目的python模块。之后您将在此加入代码。crawls57/items.py: 项目中的item文件.crawls57/pipelines.py: 项目中的pipelines文件.crawls57/settings.py: 项目的设置文件.crawls57/spiders/: 放置spider代码的目录.
定义Item
Item 是保存爬取到的数据的容器。在www.s-57.com的网页上,数据分为左右两部分,左边是航标对象的信息,右边是航标属性的信息。右边的数据较多,所以我们主要抓取左边,即航标对象的一些数据:
import scrapy class Crawls57Item(scrapy.Item): Object = scrapy.Field() Acronym = scrapy.Field() Code = scrapy.Field() Primitives = scrapy.Field() Attribute_A = scrapy.Field() Attribute_B = scrapy.Field() Attribute_C = scrapy.Field() Definition = scrapy.Field() References_INT = scrapy.Field() References_S4 = scrapy.Field() Remarks = scrapy.Field() Distinction = scrapy.Field()
编写爬虫
有了定义的Item,就可以编写爬虫Spider开始抓取数据。
可以直接通过命令行的方式,创建一个新的Spider:
scrapy genspider s-57 s-57.com
此时,在spiders文件夹里会生成一个 s-57.py 文件。下面我们则需要对该文件进行编辑。
根据网站s-57的结构,抓取的过程主要有两步:
- 抓取航标对象的名称、缩略号、ID等信息;
- 提取每一个航标对象的网页地址,抓取它的详细信息。
s-57.py 里默认有 parse() 方法,可以返回 Request 或者 items。每次运行爬虫, parse() 方法都会被调用。返回的 Request 对象接受一个参数 callback,指定 callback 为一个新的方法,就可以反复调用这个新的方法。所以,通过返回 Request 即可实现对网站的递归抓取。根据上述要求的抓取过程,可创建方法 parse_dir_contents() ,被 parse() 调用抓取航标对象的详细信息,编辑代码如下。
import scrapy from crawls57.items import Crawls57Item import re class S57Spider(scrapy.Spider): name = "s-57" allowed_domains = ["s-57.com"] start_urls = [ "http://www.s-57.com/titleO.htm", ] data_code={} data_obj={} def parse(self, response): for obj in response.xpath(‘//select[@name="Title"]/option‘): obj_name = obj.xpath(‘text()‘).extract()[0] obj_value = obj.xpath(‘@value‘).extract()[0] self.data_obj[obj_value] = obj_name for acr in response.xpath(‘//select[@name="Acronym"]/option‘): acr_name = acr.xpath(‘text()‘).extract()[0] acr_value = acr.xpath(‘@value‘).extract()[0] self.data_code[acr_name] = acr_value url = u‘http://www.s-57.com/Object.asp?nameAcr=‘+acr_name yield scrapy.Request(url, callback=self.parse_dir_contents) def parse_dir_contents(self, response): acr_name = response.url.split(‘=‘)[-1] acr_value = str(self.data_code[acr_name]) obj_name = self.data_obj[acr_value] for sel in response.xpath(‘//html/body/dl‘): item = Crawls57Item() item[‘Object‘] = obj_name item[‘Acronym‘] = acr_name item[‘Code‘] = acr_value item[‘Primitives‘] = sel.xpath(‘b/text()‘).extract() #Atrribute ABC atainfo = u‘‘ apath = sel.xpath(‘.//tr[1]/td[2]/b‘) for ata in apath.xpath(‘.//span‘): atainfo += ata.re(‘>(\\w+)<‘)[0]+"; " item[‘Attribute_A‘] = atainfo atbinfo = u‘‘ bpath = sel.xpath(‘.//tr[2]/td[2]/b‘) for atb in bpath.xpath(‘.//span‘): atbinfo += atb.re(‘>(\\w+)<‘)[0]+"; " item[‘Attribute_B‘] = atbinfo atcinfo = u‘‘ cpath = sel.xpath(‘.//tr[3]/td[2]/b‘) for atc in cpath.xpath(‘.//span‘): atcinfo += atc.re(‘>(\\w+)<‘)[0]+"; " item[‘Attribute_C‘] = atcinfo #Description i = 0 for dec in sel.xpath(‘.//dl/dd‘): i += 1 dt = ‘.//dl/dt[‘ + str(i) + ‘]/b/text()‘ dd = ‘.//dl/dd[‘ + str(i) + ‘]/font/text()‘ if (sel.xpath(dt).extract()[0] == ‘References‘): item[‘References_INT‘] = sel.xpath(‘.//tr[1]/td[2]/font/text()‘).extract()[0] item[‘References_S4‘] = sel.xpath(‘.//tr[2]/td[2]/font/text()‘).extract()[0] if (len(sel.xpath(dd).extract()) == 0): continue if (sel.xpath(dt).extract()[0] == ‘Definition‘): ss = ‘‘ for defi in sel.xpath(dd).extract(): ss += defi item[‘Definition‘] = ss if (sel.xpath(dt).extract()[0] == ‘Remarks:‘): item[‘Remarks‘] = sel.xpath(dd).extract()[0] if (sel.xpath(dt).extract()[0] == ‘Distinction:‘): item[‘Distinction‘] = sel.xpath(dd).extract()[0] yield item
相比正则表达式,用xpath抓取数据要方便许多。但是,用的时候还是免不了反复调试。Scrapy提供了一个shell环境用于调试response的命令,基本语法:
scrapy shell [url]
之后,就可以直接输入response.xpath(‘...‘)调试抓取的数据。
爬取
进入项目的根目录,执行下列命令启动Spider:
scrapy crawl crawls57 -o data.json
最终,抓取的数据被存储在 data.json 中。
以上是关于PythonScrapy入门实例的主要内容,如果未能解决你的问题,请参考以下文章