神奇的 SQL 之谓词 → 难理解的 EXISTS
Posted youzhibing
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了神奇的 SQL 之谓词 → 难理解的 EXISTS相关的知识,希望对你有一定的参考价值。
前言
开心一刻

我要飞的更高,飞的更高,啊!
谓词
SQL 中的谓词指的是:返回值是逻辑值的函数。我们知道函数的返回值有可能是数字、字符串或者日期等等,但谓词的返回值全部是逻辑值(TRUE/FALSE/UNKNOW),谓词是一种特殊的函数。关于逻辑值,可以查看:神奇的 SQL 之温柔的陷阱 → 三值逻辑 与 NULL !
SQL 中的谓词有很多,如 =、>、<、<> 等,我们来看看 SQL 具体有哪些常用的谓词
比较谓词
创建表与初始化数据
-- 1、表创建并初始化数据 DROP TABLE IF EXISTS tbl_student; CREATE TABLE tbl_student ( id INT(8) unsigned NOT NULL AUTO_INCREMENT COMMENT ‘自增主键‘, sno VARCHAR(12) NOT NULL COMMENT ‘学号‘, name VARCHAR(5) NOT NULL COMMENT ‘姓名‘, age TINYINT(3) NOT NULL COMMENT ‘年龄‘, sex TINYINT(1) NOT NULL COMMENT ‘性别,1:男,2:女‘, PRIMARY KEY (id) ); INSERT INTO tbl_student(sno,name,age,sex) VALUES (‘20190607001‘,‘李小龙‘,21,1), (‘20190607002‘,‘王祖贤‘,16,2), (‘20190608003‘,‘林青霞‘,17,2), (‘20190608004‘,‘李嘉欣‘,15,2), (‘20190609005‘,‘周润发‘,20,1), (‘20190609006‘,‘张国荣‘,18,1); DROP TABLE IF EXISTS tbl_student_class; CREATE TABLE tbl_student_class ( id int(8) unsigned NOT NULL AUTO_INCREMENT COMMENT ‘自增主键‘, sno varchar(12) NOT NULL COMMENT ‘学号‘, cno varchar(5) NOT NULL COMMENT ‘班级号‘, cname varchar(20) NOT NULL COMMENT ‘班级名‘, PRIMARY KEY (`id`) ) COMMENT=‘学生班级表‘; INSERT INTO tbl_student_class VALUES (‘1‘, ‘20190607001‘, ‘0607‘, ‘影视7班‘), (‘2‘, ‘20190607002‘, ‘0607‘, ‘影视7班‘), (‘3‘, ‘20190608003‘, ‘0608‘, ‘影视8班‘), (‘4‘, ‘20190608004‘, ‘0608‘, ‘影视8班‘), (‘5‘, ‘20190609005‘, ‘0609‘, ‘影视9班‘), (‘6‘, ‘20190609006‘, ‘0609‘, ‘影视9班‘); SELECT * FROM tbl_student; SELECT * FROM tbl_student_class;
相信大家对 =、>、<、<>(!=)等比较运算符都非常熟悉,它们的正式名称就是比较谓词,使用示例如下
-- 比较谓词示例 SELECT * FROM tbl_student WHERE name = ‘王祖贤‘; SELECT * FROM tbl_student WHERE age > 18; SELECT * FROM tbl_student WHERE age < 18; SELECT * FROM tbl_student WHERE age <> 18; SELECT * FROM tbl_student WHERE age <= 18;
LIKE
当我们想用 SQL 做一些简单的模糊查询时,都会用到 LIKE 谓词,分为 前一致、中一致和后一致,使用示例如下
-- LIKE谓词 SELECT * FROM tbl_student WHERE name LIKE ‘李%‘; -- 前一致 SELECT * FROM tbl_student WHERE name LIKE ‘%青%‘; -- 中一致 SELECT * FROM tbl_student WHERE name LIKE ‘青%‘; -- 后一致
如果name字段上建了索引,那么前一致会利用索引;而中一致、后一致会走全表扫描。
BETWEEN
当我们想进行范围查询时,往往会用到 BETWEEN 谓词,示例如下
-- BETWEEN谓词 SELECT * FROM tbl_student WHERE age BETWEEN 15 AND 22; SELECT * FROM tbl_student WHERE age NOT BETWEEN 15 AND 22;
BETWEEN 和它之后的第一个 AND 组成一个范围条件;BETWEEN 会包含临界值 15 和 22
SELECT * FROM tbl_student WHERE age BETWEEN 15 AND 22; -- 等价于 SELECT * FROM tbl_student WHERE age >= 15 AND age <= 22;
若不想包含临界值,那就需要这么写了
SELECT * FROM tbl_student WHERE age > 15 AND age = 22;
IS NULL 和 IS NOT NULL
NULL 的水很深,具体可看:神奇的 SQL 之温柔的陷阱 → 三值逻辑 与 NULL !
IN
有这样一个需求:查询出年龄等于 15、18以及20的学生,我们会用 OR 来查
-- OR SELECT * FROM tbl_student WHERE age = 15 OR age = 18 OR age = 20;
用 OR 来查没问题,但是有一点不足,如果选取的对象越来越多,SQL会变得越来越长,阅读性会越来越差。所以我们可以用 IN 来代替
-- IN SELECT * FROM tbl_student WHERE age IN(15,18,20);
IN 有一种其他谓词没有的使用方法:使用子查询作为其参数,这个在平时项目中也是用的非常多的,例如:查询出影视7班的学生信息
-- IN实现,但不推荐 SELECT * FROM tbl_student WHERE sno IN ( SELECT sno FROM tbl_student_class WHERE cname = ‘影视7班‘ ); -- 联表查,推荐 SELECT ts.* FROM tbl_student_class tsc LEFT JOIN tbl_student ts ON tsc.sno = ts.sno WHERE tsc.cname = ‘影视7班‘;
很多情况下,IN 是可以用联表查询来替换的
EXISTS
EXISTS也是 SQL 谓词,但平时用的不多,不是说适用场景少,而是它不好驾驭,我们用不好它。它用法与其他谓词不一样,而且不好理解,另外很多情况下我们都用 IN 来替代它了。
理论篇
在真正讲解 EXSITS 示例之前,我们先来了解下理论知识:实体的阶层 、全称量化与存在量化
实体的阶层
SQL 严格区分阶层,不能跨阶层操作。就用我们常用的谓词来举例,同样是谓词,但是与 = 、BETWEEN 等相比,EXISTS 的用法还是大不相同的。概括来说,区别在于“谓词的参数可以取什么值”;“x = y”或 “x BETWEEN y ” 等谓词可以取的参数是像 “21” 或者 “李小龙” 这样的单一值,我们称之为标量值,而 EXISTS 可以取的参数究竟是什么呢?从下面这条 SQL 语句来看,EXISTS 的参数不像是单一值
SELECT * FROM tbl_student ts WHERE EXISTS ( SELECT * FROM tbl_student_class tsc WHERE ts.sno = tsc.sno );
我们可以看出 EXISTS 的参数是行数据的集合。之所以这么说,是因为无论子查询中选择什么样的列,对于 EXISTS 来说都是一样的。在 EXISTS 的子查询里, SELECT 子句的列表可以有下面这三种写法。
1. 通配符:SELECT * 2. 常量:SELECT ‘1‘ 3. 列名:SELECT tsc.id
也就是说如下 3 条 SQL 查到的结果是一样的


-- SELECT * SELECT * FROM tbl_student ts WHERE EXISTS ( SELECT * FROM tbl_student_class tsc WHERE ts.sno = tsc.sno ); -- SELECT 常量 SELECT * FROM tbl_student ts WHERE EXISTS ( SELECT 1 FROM tbl_student_class tsc WHERE ts.sno = tsc.sno ); -- SELECT 列名 SELECT * FROM tbl_student ts WHERE EXISTS ( SELECT tsc.sno FROM tbl_student_class tsc WHERE ts.sno = tsc.sno );
用个图来概括下一般的谓词与 EXISTS 的区别
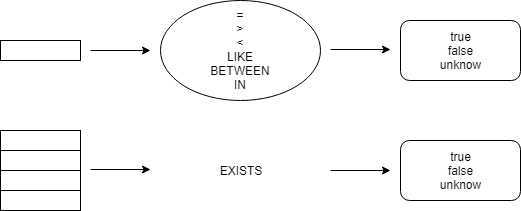
从上图我们知道,EXISTS 的特殊性在于输入值的阶数(输出值和其他谓词一样,都是逻辑值)。谓词逻辑中,根据输入值的阶数对谓词进行分类。= 或者 BETWEEEN 等输入值为一行的谓词叫作“一阶谓词”,而像 EXISTS 这样输入值为行的集合的谓词叫作 “二阶谓词”。关于 “阶” ,有兴趣的可以区看我的另一篇博客:神奇的 SQL 之层级 → 为什么 GROUP BY 之后不能直接引用原表中的列
全称量化和存在量化
谓词逻辑中有量词(限量词、数量词)这类特殊的谓词。我们可以用它们来表达一些这样的命题:“所有的 x 都满足条件 P” 或者 “存在(至少一个)满足条件 P 的 x ”,前者称为“全称量词”,后者称为“存在量词”,分别记作 ∀(A的下倒)、∃(E的左倒)。
SQL 中的 EXISTS 谓词实现了谓词逻辑中的存在量词,然而遗憾的是, SQL 却并没有实现全称量词。但是没有全称量词并不算是 SQL 的致命缺陷,因为全称量词和存在量词只要定义了一个,另一个就可以被推导出来。具体可以参考下面这个等价改写的规则(德·摩根定律)。
∀ x P x = ¬ ∃ x ¬P(所有的 x 都满足条件 P =不存在不满足条件 P 的 x )
∃ x P x = ¬ ∀ x ¬Px(存在 x 满足条件 P =并非所有的 x 都不满足条件 P)
因此在 SQL 中,为了表达全称量化,需要将"所有的行都满足条件P" 这样的命题转换成 "不存在不满足条件 P 的行"
实践篇
上面的理论篇,大家看了以后可能还是有点晕,我们结合具体的实际案例来看看 EXISTS 的妙用
查询表中“不”存在的数据
上面的 tbl_student中的学生都分配到了具体的班级,假设新来了两个学生(刘德华、张家辉),他们暂时还未被分配到班级,我们如何将他们查询出来(查询未被分配到班级的学生信息)。
-- 新来、未被分配到班级的学生 INSERT INTO tbl_student(sno,name,age,sex) VALUES (‘20190610010‘,‘刘德华‘,55,1), (‘20190610011‘,‘张家辉‘,46,1);
我们最容易想到的 SQL 肯定是下面这条
-- NOT IN 实现 SELECT * FROM tbl_student WHERE sno NOT IN(SELECT sno FROM tbl_student_class);
其实用 NOT EXISTS 也是可以实现的
-- NOT EXISTS 实现 SELECT * FROM tbl_student ts WHERE NOT EXISTS ( SELECT * FROM tbl_student_class tsc WHERE ts.sno = tsc.sno );
全称量化 :习惯 “肯定 ⇔ 双重否定” 之间的转换
EXISTS 谓词来表达全称量化,这是EXISTS 的用法中很具有代表性的一个用法。但是需要我们打破常规思维,习惯从全称量化 “所有的行都××” 到其双重否定 “不××的行一行都不存在” 的转换。
假设我们有学生成绩表:tbl_student_score
-- 学生成绩表 DROP TABLE IF EXISTS tbl_student_score; CREATE TABLE tbl_student_score ( id INT(8) unsigned NOT NULL AUTO_INCREMENT COMMENT ‘自增主键‘, sno VARCHAR(12) NOT NULL COMMENT ‘学号‘, subject VARCHAR(5) NOT NULL COMMENT ‘课程‘, score TINYINT(3) NOT NULL COMMENT ‘分数‘, PRIMARY KEY (id) ); INSERT INTO tbl_student_score(sno,subject,score) VALUES (‘20190607001‘,‘数学‘,100), (‘20190607001‘,‘语文‘,80), (‘20190607001‘,‘物理‘,80), (‘20190608003‘,‘数学‘,80), (‘20190608003‘,‘语文‘,95), (‘20190609006‘,‘数学‘,40), (‘20190609006‘,‘语文‘,90), (‘20190610011‘,‘数学‘,80); SELECT * FROM tbl_student_score;
1、查询出“所有科目分数都在 50 分以上的学生”
20190607001、20190608003、20190610011 这三个学生满足条件,我们需要将这 3 个学生查出来,这个 SQL 该如何写? 我们需要转换下命题,将查询条件“所有科目分数都在 50 分以上” 转换成它的双重否定 “没有一个科目分数不满 50 分”,然后用 NOT EXISTS 来表示转换后的命题
-- 没有一个科目分数不满 50 分 SELECT DISTINCT sno FROM tbl_student_score tss1 WHERE NOT EXISTS -- 不存在满足以下条件的行 ( SELECT * FROM tbl_student_score tss2 WHERE tss2.sno = tss1.sno AND tss2.score < 50 -- 分数不满50 分的科目 );
2、查询出“数学分数在 80 分以上(包含80)且语文分数在 50 分以上(包含)的学生”
结果应该是学号分别为 20190607001、20190608003 的学生。像这样的需求,我们在实际业务中应该会经常遇到,但是乍一看可能会觉得不太像是全称量化的条件。如果改成下面这样的说法,可能我们一下子就能明白它是全称量化的命题了。
"某个学生的所有行数据中,如果科目是数学,则分数在 80 分以上;如果科目是语文,则分数在 50 分以上。"
我们再转换成它双重否定:某个学生的所有行数据中,如果科目是数学,则分数不低于 80;如果科目是语文,则分数不低于 50 ;我们可以按照如下顺序写出我们想要的 SQL
-- 1、CASE 表达式,肯定 CASE WHEN subject = ‘数学‘ AND score >= 80 THEN 1 WHEN subject = ‘语文‘ AND score >= 50 THEN 1 ELSE 0 END; -- 2、CASE 表达式,单重否定(加上 NOT EXISTS才算双重) CASE WHEN subject = ‘数学‘ AND score < 80 THEN 1 WHEN subject = ‘语文‘ AND score < 50 THEN 1 ELSE 0 END; -- 3、结果包含了 20190610011 的 SQL SELECT DISTINCT sno FROM tbl_student_score tss1 WHERE subject IN (‘数学‘, ‘语文‘) AND NOT EXISTS ( SELECT *FROM tbl_student_score tss2 WHERE tss2.sno = tss1.sno AND 1 = CASE WHEN subject = ‘数学‘ AND score < 80 THEN 1 WHEN subject = ‘语文‘ AND score < 50 THEN 1 ELSE 0 END ); -- 4、20190610011 没有语文成绩,剔除掉 SELECT sno FROM tbl_student_score tss1 WHERE subject IN (‘数学‘, ‘语文‘) AND NOT EXISTS ( SELECT * FROM tbl_student_score tss2 WHERE tss2.sno = tss1.sno AND 1 = CASE WHEN subject = ‘数学‘ AND score < 80 THEN 1 WHEN subject = ‘语文‘ AND score < 50 THEN 1 ELSE 0 END ) GROUP BY sno HAVING COUNT(*) = 2; -- 必须两门科目都有分数
关于 EXISTS 的案例有很多,这里就不再举例了,有兴趣的小伙伴可以看看:SQL 中的 EXISTS 到底做了什么?
如果大家想掌握 EXISTS,希望大家多看看 EXISTS 的案例,看多了你就会发现其中的通性:哪些场景适合用 EXISTS。
总结
1、SQL 中的谓词分两种:一阶谓词和二阶谓词(EXISTS),区别主要在于接收的参数不同,一阶谓词接收的是 行,而二阶谓词接收的是 行的集合;
2、SQL 中没有与全称量词相当的谓词,可以使用 NOT EXISTS 代替;
3、EXISTS 之所以难用(不是不好用,而是不会用),主要是全称量词的命题转换(肯定 ⇔ 双重否定)比较难(楼主也懵!)。实际工作中往往会舍弃 EXISTS,寻找它的替代方式,可能是 SQL 的替代,也可能是业务方面的转换,所以说,EXISTS 掌握不了没关系,当然,能掌握那是最好了;
参考
《SQL基础教程》
《SQL进阶教程》
以上是关于神奇的 SQL 之谓词 → 难理解的 EXISTS的主要内容,如果未能解决你的问题,请参考以下文章
SQL基础教程(第2版)第6章 函数谓词CASE表达式:6-2 谓词