Flink入门宝典(详细截图版)
Posted tree1123
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink入门宝典(详细截图版)相关的知识,希望对你有一定的参考价值。

本文基于java构建Flink1.9版本入门程序,需要Maven 3.0.4 和 Java 8 以上版本。需要安装Netcat进行简单调试。
这里简述安装过程,并使用IDEA进行开发一个简单流处理程序,本地调试或者提交到Flink上运行,Maven与JDK安装这里不做说明。
一、Flink简介
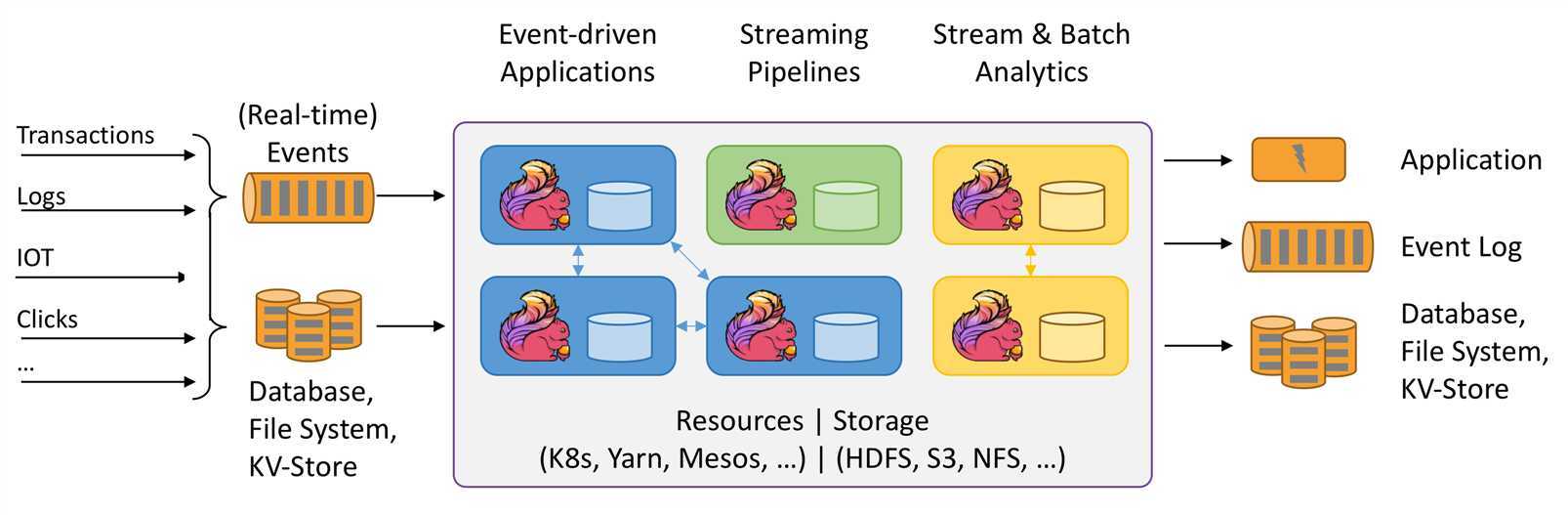
Flink诞生于欧洲的一个大数据研究项目StratoSphere。该项目是柏林工业大学的一个研究性项目。早期,Flink是做Batch计算的,但是在2014年,StratoSphere里面的核心成员孵化出Flink,同年将Flink捐赠Apache,并在后来成为Apache的顶级大数据项目,同时Flink计算的主流方向被定位为Streaming,即用流式计算来做所有大数据的计算,这就是Flink技术诞生的背景。
2015开始阿里开始介入flink 负责对资源调度和流式sql的优化,成立了阿里内部版本blink在最近更新的1.9版本中,blink开始合并入flink,
未来flink也将支持java,scala,python等更多语言,并在机器学习领域施展拳脚。
二、Flink开发环境搭建
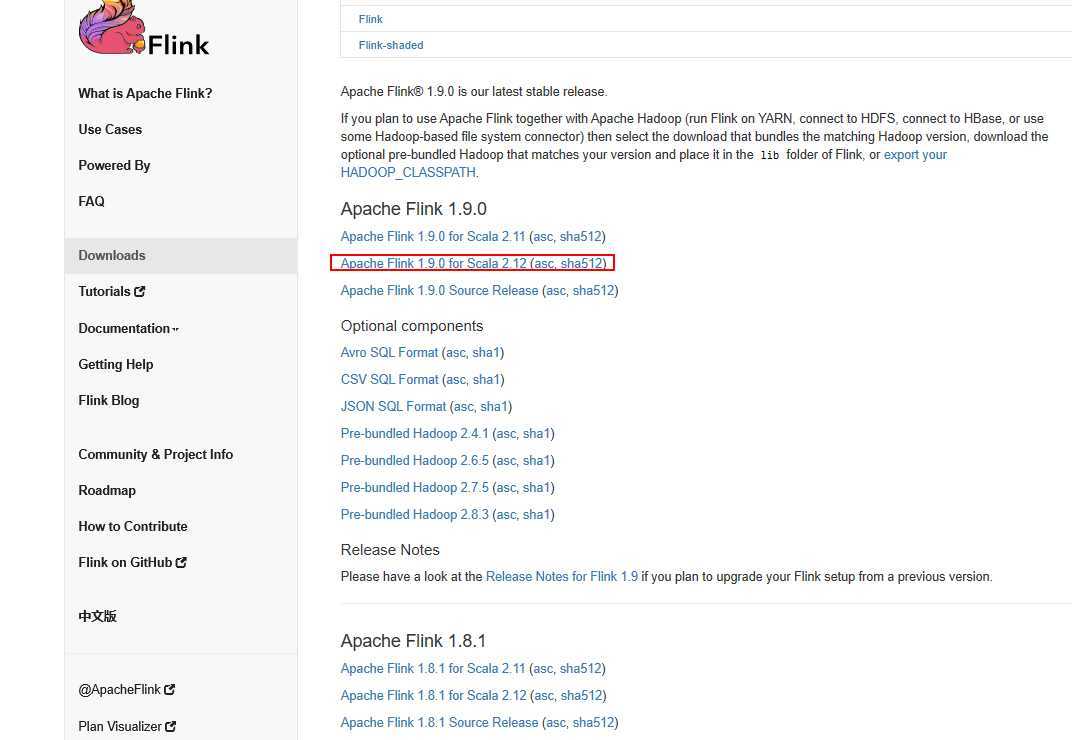
首先要想运行Flink,我们需要下载并解压Flink的二进制包,下载地址如下:https://flink.apache.org/downloads.html
我们可以选择Flink与Scala结合版本,这里我们选择最新的1.9版本Apache Flink 1.9.0 for Scala 2.12进行下载。
Flink在Windows和Linux下的安装与部署可以查看 Flink快速入门--安装与示例运行,这里演示windows版。
安装成功后,启动cmd命令行窗口,进入flink文件夹,运行bin目录下的start-cluster.bat
$ cd flink
$ cd bin
$ start-cluster.bat
Starting a local cluster with one JobManager process and one TaskManager process.
You can terminate the processes via CTRL-C in the spawned shell windows.
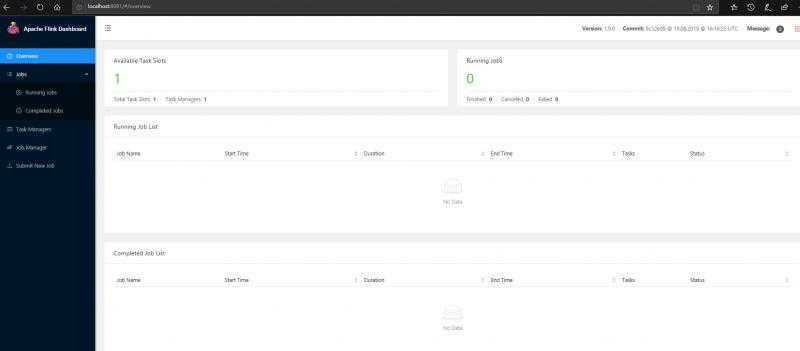
Web interface by default on http://localhost:8081/.显示启动成功后,我们在浏览器访问 http://localhost:8081/可以看到flink的管理页面。
三、Flink快速体验
请保证安装好了flink,还需要Maven 3.0.4 和 Java 8 以上版本。这里简述Maven构建过程。
其他详细构建方法欢迎查看:快速构建第一个Flink工程
1、搭建Maven工程
使用Flink Maven Archetype构建一个工程。
$ mvn archetype:generate -DarchetypeGroupId=org.apache.flink -DarchetypeArtifactId=flink-quickstart-java -DarchetypeVersion=1.9.0你可以编辑自己的artifactId groupId
目录结构如下:
$ tree quickstart/
quickstart/
├── pom.xml
└── src
└── main
├── java
│ └── org
│ └── myorg
│ └── quickstart
│ ├── BatchJob.java
│ └── StreamingJob.java
└── resources
└── log4j.properties在pom中核心依赖:
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>$flink.version</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>$flink.version</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.11</artifactId>
<version>$flink.version</version>
</dependency>
</dependencies>2、编写代码
StreamingJob
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
public class StreamingJob
public static void main(String[] args) throws Exception
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<Tuple2<String, Integer>> dataStreaming = env
.socketTextStream("localhost", 9999)
.flatMap(new Splitter())
.keyBy(0)
.timeWindow(Time.seconds(5))
.sum(1);
dataStreaming.print();
// execute program
env.execute("Flink Streaming Java API Skeleton");
public static class Splitter implements FlatMapFunction<String, Tuple2<String, Integer>>
@Override
public void flatMap(String sentence, Collector<Tuple2<String, Integer>> out) throws Exception
for(String word : sentence.split(" "))
out.collect(new Tuple2<String, Integer>(word, 1));
3、调试程序
安装netcat工具进行简单调试。
启动netcat 输入:
nc -l 9999启动程序
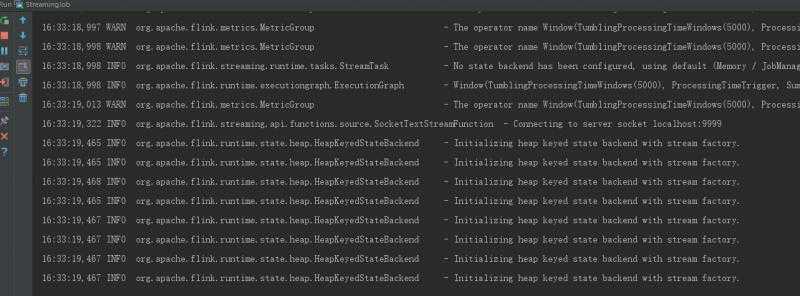
在netcat中输入几个单词 逗号分隔
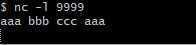
在程序一端查看结果
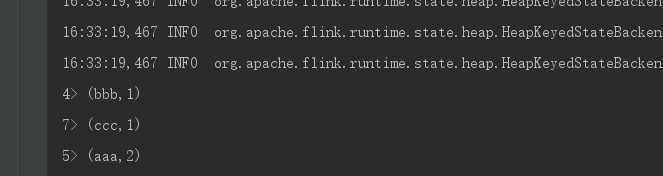
4、程序提交到Flink
启动flink
windows为 start-cluster.bat linux为start-cluster.shlocalhost:8081查看管理页面
通过maven对代码打包
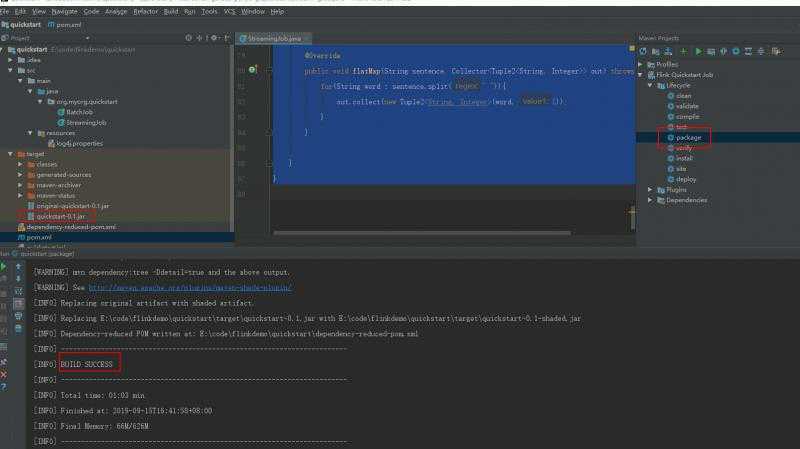
将打好的包提交到flink上
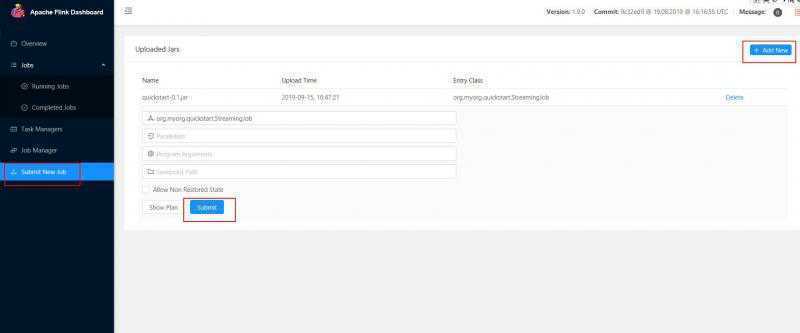
查看log
tail -f log/flink-***-jobmanager.out在netcat中继续输入单词,在Running Jobs中查看作业状态,在log中查看输出。
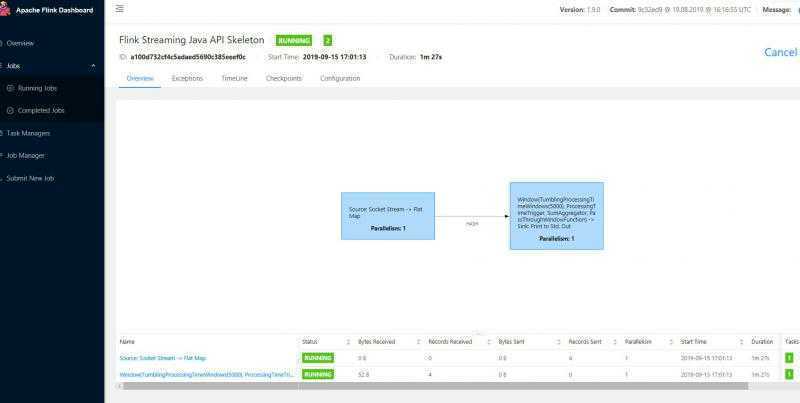
四、Flink 编程模型
Flink提供不同级别的抽象来开发流/批处理应用程序。
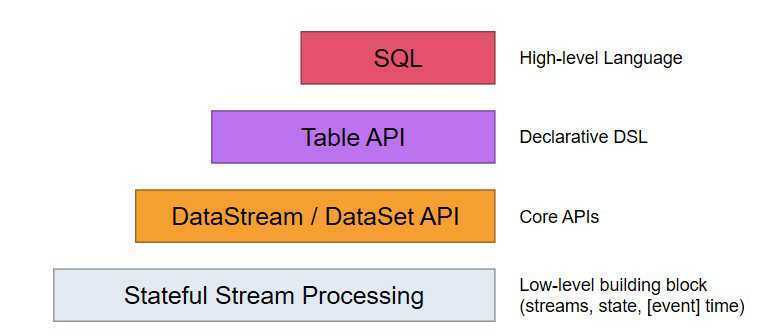
最低级抽象只提供有状态流。
在实践中,大多数应用程序不需要上述低级抽象,而是针对Core API编程,?如DataStream API(有界/无界流)和DataSet API(有界数据集)。
Table Api声明了一个表,遵循关系模型。
最高级抽象是SQL。
我们这里只用到了DataStream API。
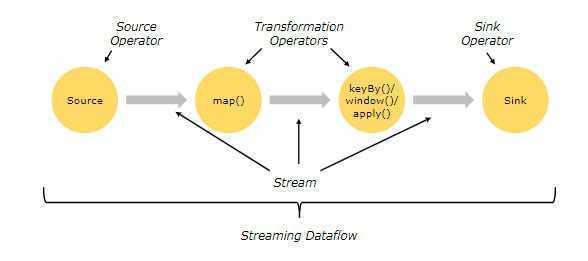
Flink程序的基本构建块是流和转换。
一个程序的基本构成:
l?获取execution environment
l?加载/创建原始数据
l?指定这些数据的转化方法
l?指定计算结果的存放位置
l?触发程序执行
五、DataStreaming API使用
1、获取execution environment
StreamExecutionEnvironment是所有Flink程序的基础,获取方法有:
getExecutionEnvironment()
createLocalEnvironment()
createRemoteEnvironment(String host, int port, String ... jarFiles)
一般情况下使用getExecutionEnvironment。如果你在IDE或者常规java程序中执行可以通过createLocalEnvironment创建基于本地机器的StreamExecutionEnvironment。如果你已经创建jar程序希望通过invoke方式获取里面的getExecutionEnvironment方法可以使用createRemoteEnvironment方式。
2、加载/创建原始数据
StreamExecutionEnvironment提供的一些访问数据源的接口
(1)基于文件的数据源
readTextFile(path)
readFile(fileInputFormat, path)
readFile(fileInputFormat, path, watchType, interval, pathFilter, typeInfo)(2)基于Socket的数据源(本文使用的)
l?socketTextStream
?
(3)基于Collection的数据源
fromCollection(Collection)
fromCollection(Iterator, Class)
fromElements(T ...)
fromParallelCollection(SplittableIterator, Class)
generateSequence(from, to)3、转化方法
(1)Map方式:DataStream -> DataStream
功能:拿到一个element并输出一个element,类似Hive中的UDF函数
举例:
DataStream<Integer> dataStream = //...
dataStream.map(new MapFunction<Integer, Integer>()
????@Override
????public Integer map(Integer value) throws Exception
????????return 2 * value;
????
);(2)FlatMap方式:DataStream -> DataStream
功能:拿到一个element,输出多个值,类似Hive中的UDTF函数
举例:
dataStream.flatMap(new FlatMapFunction<String, String>()
????@Override
????public void flatMap(String value, Collector<String> out)
????????throws Exception
????????for(String word: value.split(" "))
????????????out.collect(word);
????????
????
);(3)Filter方式:DataStream -> DataStream
功能:针对每个element判断函数是否返回true,最后只保留返回true的element
举例:
dataStream.filter(new FilterFunction<Integer>()
????@Override
????public boolean filter(Integer value) throws Exception
????????return value != 0;
????
);(4)KeyBy方式:DataStream -> KeyedStream
功能:逻辑上将流分割成不相交的分区,每个分区都是相同key的元素
举例:
dataStream.keyBy("someKey") // Key by field "someKey"
dataStream.keyBy(0) // Key by the first element of a Tuple(5)Reduce方式:KeyedStream -> DataStream
功能:在keyed data stream中进行轮训reduce。
举例:
keyedStream.reduce(new ReduceFunction<Integer>()
????@Override
????public Integer reduce(Integer value1, Integer value2)
????throws Exception
????????return value1 + value2;
????
);(6)Aggregations方式:KeyedStream -> DataStream
功能:在keyed data stream中进行聚合操作
举例:
keyedStream.sum(0);
keyedStream.sum("key");
keyedStream.min(0);
keyedStream.min("key");
keyedStream.max(0);
keyedStream.max("key");
keyedStream.minBy(0);
keyedStream.minBy("key");
keyedStream.maxBy(0);
keyedStream.maxBy("key");(7)Window方式:KeyedStream -> WindowedStream
功能:在KeyedStream中进行使用,根据某个特征针对每个key用windows进行分组。
举例:
dataStream.keyBy(0).window(TumblingEventTimeWindows.of(Time.seconds(5))); // Last 5 seconds of data(8)WindowAll方式:DataStream -> AllWindowedStream
功能:在DataStream中根据某个特征进行分组。
举例:
dataStream.windowAll(TumblingEventTimeWindows.of(Time.seconds(5))); // Last 5 seconds of data(9)Union方式:DataStream* -> DataStream
功能:合并多个数据流成一个新的数据流
举例:
dataStream.union(otherStream1, otherStream2, ...);(10)Split方式:DataStream -> SplitStream
功能:将流分割成多个流
举例:
SplitStream<Integer> split = someDataStream.split(new OutputSelector<Integer>()
????@Override
????public Iterable<String> select(Integer value)
????????List<String> output = new ArrayList<String>();
????????if (value % 2 == 0)
????????????output.add("even");
????????
????????else
????????????output.add("odd");
????????
????????return output;
????
);(11)Select方式:SplitStream -> DataStream
功能:从split stream中选择一个流
举例:
SplitStream<Integer> split;
DataStream<Integer> even = split.select("even");
DataStream<Integer> odd = split.select("odd");
DataStream<Integer> all = split.select("even","odd");4、输出数据
writeAsText()
writeAsCsv(...)
print() / printToErr()
writeUsingOutputFormat() / FileOutputFormat
writeToSocket
addSink更多Flink相关原理:
更多实时计算,Flink,Kafka等相关技术博文,欢迎关注实时流式计算:

以上是关于Flink入门宝典(详细截图版)的主要内容,如果未能解决你的问题,请参考以下文章
最新 Flink 1.13 运行时架构(JobManagerTaskManagerYARNSlotsJobGraph)快速入门详细教程