最新 Flink 1.13 运行时架构(JobManagerTaskManagerYARNSlotsJobGraph)快速入门详细教程
Posted 数据文
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了最新 Flink 1.13 运行时架构(JobManagerTaskManagerYARNSlotsJobGraph)快速入门详细教程相关的知识,希望对你有一定的参考价值。
Flink 运行时架构
文章目录
下一章: Flink 1.13 DataStream API
一、系统架构
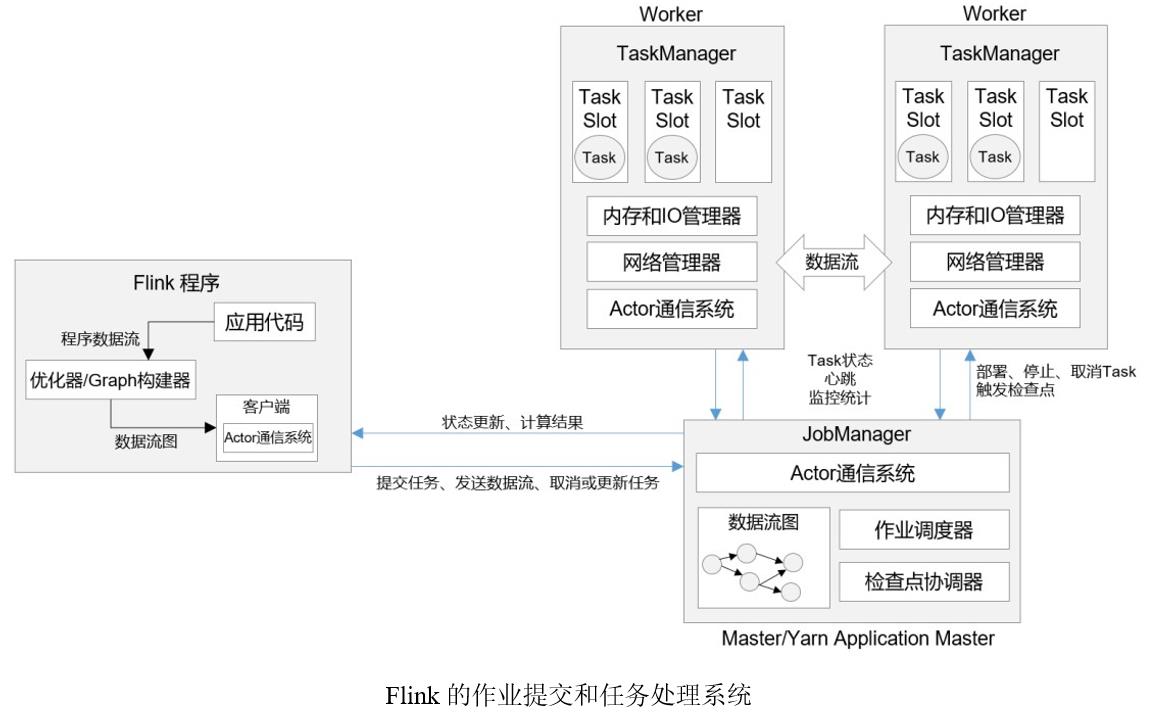
这里首先要说明一下“客户端”。其实客户端并不是处理系统的一部分,它只负责作业的提交。具体来说,就是调用程序的 main 方法,将代码转换成“数据流图”(Dataflow Graph),并最终生成作业图(JobGraph),一并发送给 JobManager。提交之后,任务的执行其实就跟客户端没有关系了;我们可以在客户端选择断开与 JobManager 的连接, 也可以继续保持连接。之前我们在命令提交作业时,加上的-d参数,就是表示分离模式(detached mode),也就是断开连接。
当然,客户端可以随时连接到 JobManager,获取当前作业的状态和执行结果,也可以发送请求取消作业。不论通过 Web UI 还是命令行执行“flink run”的相关操作,都是通过客户端实现的。
1. 作业管理器(JobManager)
JobManager 是一个 Flink 集群中任务管理和调度的核心,是控制应用执行的主进程。
-
JobMaster
JobMaster是JobManager 中最核心的组件,负责处理单独的作业(Job)。所以 JobMaster 和具体的 Job 是一一对应的,多个 Job 可以同时运行在一个 Flink 集群中, 每个 Job 都有一个自己的JobMaster。早期版本没有JobMaster的概念;而JobManager的概念范围较小,实际指的就是现在所说的JobMaster。在作业提交时,JobMaster会先接收到要执行的应用。“应用”一般是客户端提交来的Jar包,数据流图(dataflow graph)和作业图(JobGraph)。JobMaster会把JobGraph转换成一个物理层面的数据流图,这个图被叫作“执行图”ExecutionGraph,它包含了所有可以并发执行的任务。JobMaster 会向资源管理器ResourceManager发出请求,申请执行任务必要的资源。一旦它获取到了足够的资源,就会将执行图分发到真正运行它们的 TaskManager 上。
而在运行过程中,JobMaster会负责所有需要中央协调的操作,比如说检查点的协调。
-
资源管理器(ResourceManager)
ResourceManager 主要负责资源的分配和管理,在 Flink 集群中只有一个。所谓“资源”,主要是指 TaskManager 的任务槽(task slots)。任务槽就是 Flink 集群中的资源调配单元,包含了机器用来执行计算的一组 CPU 和内存资源。每一个任务(Task)都需要分配到一个 slot 上执行。这里注意要把Flink内置的 ResourceManager 和其他资源管理平台(比如 YARN)的ResourceManager 区分开。
Flink 的 ResourceManager,针对不同的环境和资源管理平台(比如 Standalone 部署,或者 YARN),有不同的具体实现。在Standalone部署时,因为 TaskManager 是单独启动的(没有Per-Job 模式),所以 ResourceManager 只能分发可用 TaskManager 的任务槽,不能单独启动新TaskManager。
而在有资源管理平台时,就不受此限制。当新的作业申请资源时,ResourceManager 会将有空闲槽位的TaskManager分配给JobMaster。如果ResourceManager没有足够的任务槽,它还可以向资源提供平台发起会话,请求提供启动 TaskManager 进程的容器。另外,ResourceManager 还负责停掉空闲的 TaskManager,释放计算资源。
-
分发器(Dispatcher)
Dispatcher 主要负责提供一个 REST 接口,用来提交应用,并且负责为每一个新提交的作业启动一个新的 JobMaster 组件。Dispatcher 也会启动一个 Web UI,用来方便地展示和监控作业执行的信息。Dispatcher在架构中并不是必需的,在不同的部署模式下可能会被忽略掉。
2. 任务管理器(TaskManager)
TaskManager 是 Flink 中的工作进程,数据流的具体计算就是它来做的,所以也被称为“Worker”。每一个TaskManager 都包含了一定数量的任务槽(task slots)。Slot 是资源调度的最小单位,slot 的数量限制了TaskManager 能够并行处理的任务数量。
启动之后,TaskManager会向资源管理器注册它的slots;收到资源管理器的指令后, TaskManager 就会将一个或者多个槽位提供给 JobMaster 调用,JobMaster 就可以分配任务来执行了。
在执行过程中,TaskManager可以缓冲数据,还可以跟其他运行同一应用的TaskManager交换数据。每个TaskManager负责管理其所在节点上的资源信息,如内存、磁盘、网络,在启动的时候将资源的状态向JobManager汇报。
二、作业提交流程
1. 高层级抽象
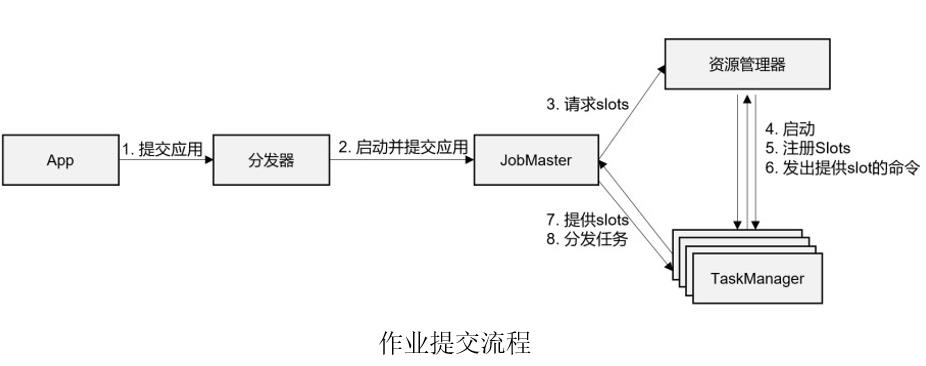
-
一般情况下,由客户端(App)通过分发器提供的 REST 接口,将作业提交给JobManager。
-
由分发器启动 JobMaster,并将作业(包含 JobGraph)提交给 JobMaster。
-
JobMaster 将 JobGraph 解析为可执行的 ExecutionGraph,得到所需的资源数量,然后向资源管理器请求资源(slots)。
-
资源管理器判断当前是否由足够的可用资源;如果没有,启动新的 TaskManager。
-
TaskManager 启动之后,向 ResourceManager 注册自己的可用任务槽(slots)。
-
资源管理器通知 TaskManager 为新的作业提供 slots。
-
TaskManager 连接到对应的 JobMaster,提供 slots。
-
JobMaster 将需要执行的任务分发给 TaskManager。
-
TaskManager 执行任务,互相之间可以交换数据。
2. 独立模式(Standalone)
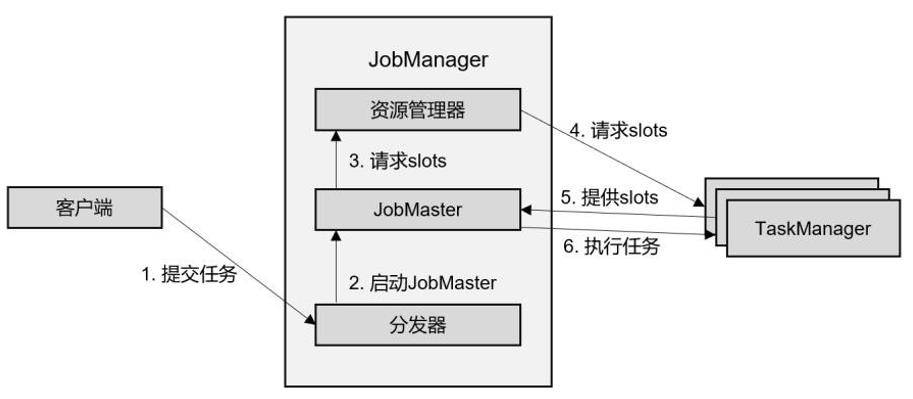
在独立模式(Standalone)下,只有会话模式和应用模式两种部署方式。两者整体来看流程是非常相似的:TaskManager 都需要手动启动,所以当 ResourceManager 收到 JobMaster 的请求时,会直接要求 TaskManager 提供资源。而 JobMaster 的启动时间点,会话模式是预先启动,应用模式则是在作业提交时启动。
3. YARN 集群
-
会话(Session)模式
在会话模式下,我们需要先启动一个YARN session,这个会话会创建一个 Flink 集群。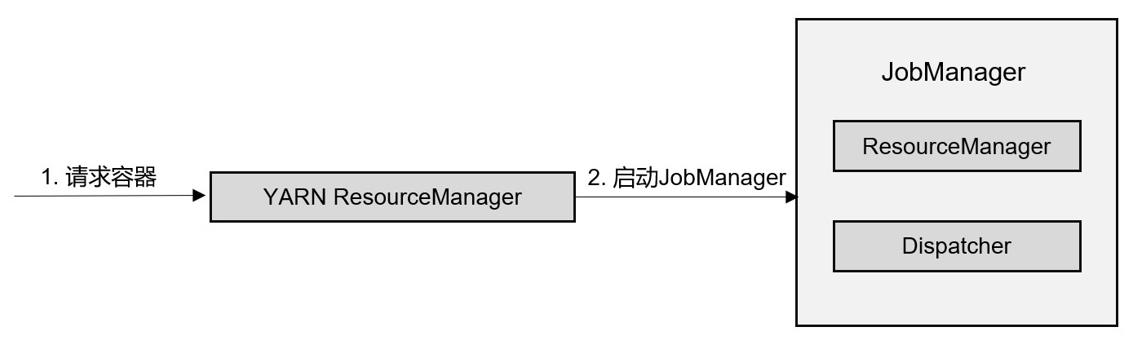
这里只启动了JobManager,而TaskManager可以根据需要动态地启动。在JobManager内部,由于还没有提交作业,所以只有 ResourceManager 和 Dispatcher 在运行
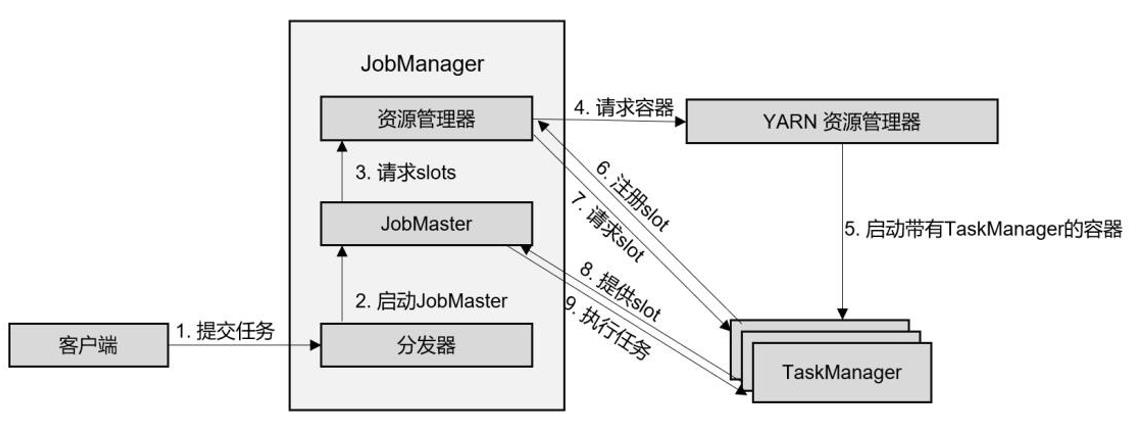
- 客户端通过 REST 接口,将作业提交给分发器。
- 分发器启动 JobMaster,并将作业(包含 JobGraph)提交给 JobMaster。
- JobMaster 向资源管理器请求资源(slots)。
- 资源管理器向 YARN 的资源管理器请求 container 资源。
- YARN 启动新的 TaskManager 容器。
- TaskManager 启动之后,向 Flink 的资源管理器注册自己的可用任务槽。
- 资源管理器通知 TaskManager 为新的作业提供 slots。
- TaskManager 连接到对应的JobMaster,提供slots。
- JobMaster 将需要执行的任务分发给 TaskManager,执行任务。
可见,整个流程除了请求资源时要“上报”YARN 的资源管理器,其他与抽象流程几乎完全一样。
-
单作业(Per-Job)模式
在单作业模式下,Flink 集群不会预先启动,在提交作业时,才启动新的JobManager。
- 客户端将作业提交给 YARN 的资源管理器,这一步中会同时将Flink的Jar包和配置上传到 HDFS,以便后续启动 Flink 相关组件的容器。
- YARN 的资源管理器分配Container 资源,启动Flink JobManager,并将作业提交给JobMaster。这里省略了Dispatcher 组件。
- JobMaster 向资源管理器请求资源(slots)。
- 资源管理器向 YARN 的资源管理器请求 container 资源。
- YARN 启动新的 TaskManager 容器。
- TaskManager 启动之后,向 Flink 的资源管理器注册自己的可用任务槽。
- 资源管理器通知 TaskManager 为新的作业提供 slots。
- TaskManager 连接到对应的JobMaster,提供 slots。
- JobMaster 将需要执行的任务分发给 TaskManager,执行任务。
可见,区别只在于JobManager 的启动方式,以及省去了分发器。当第 2 步作业提交给JobMaster,之后的流程就与会话模式完全一样了。
-
应用(Application)模式
应用模式与单作业模式的提交流程非常相似,只是初始提交给YARN 资源管理器的不再是具体的作业,而是整个应用。一个应用中可能包含了多个作业,这些作业都将在 Flink 集群中启动各自对应的JobMaster。
三、一些重要概念
1. 数据流图(Dataflow Graph)
在运行时,Flink 程序会被映射成所有算子按照逻辑顺序连接在一起的一张图,这被称为 “逻辑数据流”(logical dataflow),或者叫“数据流图”(dataflow graph)。
2. 并行度(Parallelism)
Flink中的任务被分为多个并行任务来执行,其中每个并行的实例处理一部分数据。这些并行实例的数量被称为并行度。我们在实际生产环境中可以从四个不同层面设置并行度:
-
操作算子层面(Operator Level)
stream.map(word -> Tuple2.of(word, 1L)).setParallelism(2); -
执行环境层面(Execution Environment Level)
env.setParallelism(2); -
客户端层面(Client Level)
bin/flink run –p 2 –c com.atguigu.wc.StreamWordCount ./FlinkTutorial-1.0-SNAPSHOT.jar -
系统层面(System Level)
parallelism.default: 2
需要注意的优先级:算子层面>环境层面>客户端层面>系统层面。
并行度的设置:一般设为kafka的分区数,达到1:1; 遵循2的n次方:比如2、4、8、16……
3. 算子链(Operator Chain)
-
算子间的数据传输
- 一对一(One-to-one,forwarding)
这种模式下,数据流维护着分区以及元素的顺序。map、filter、flatMap等算子都是这种 one-to-one 的对应关系。 这种关系类似于 Spark 中的窄依赖。 - 重分区(Redistributing)
在这种模式下,数据流的分区会发生改变。keyBy/window算子前后。这一过程类似于 Spark 中的 shuffle。这种算子间的关系类似于 Spark 中的宽依赖。
- 一对一(One-to-one,forwarding)
-
合并算子链
在 Flink 中,并行度相同的一对一(one to one)算子操作,可以直接链接在一起形成一个 “大”的任务(task),这样原来的算子就成为了真正任务里的一部分,如图 4-11 所示。每个 task 会被一个线程执行。这样的技术被称为“算子链”(Operator Chain)。
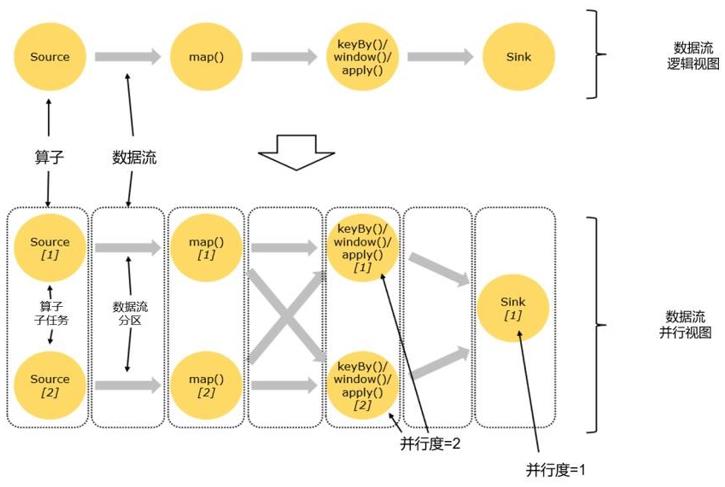
Flink为什么要有算子链这样一个设计呢?这是因为将算子链接成task是非常有效的优化:可以减少线程之间的切换和基于缓存区的数据交换,在减少时延的同时提升吞吐量。
Flink 默认会按照算子链的原则进行链接合并,如果我们想要禁止合并或者自行定义,也
可以在代码中对算子做一些特定的设置:
// 禁用算子链
.map(word -> Tuple2.of(word, 1L)).disableChaining();
// 从当前算子开始新链
.map(word -> Tuple2.of(word, 1L)).startNewChain()
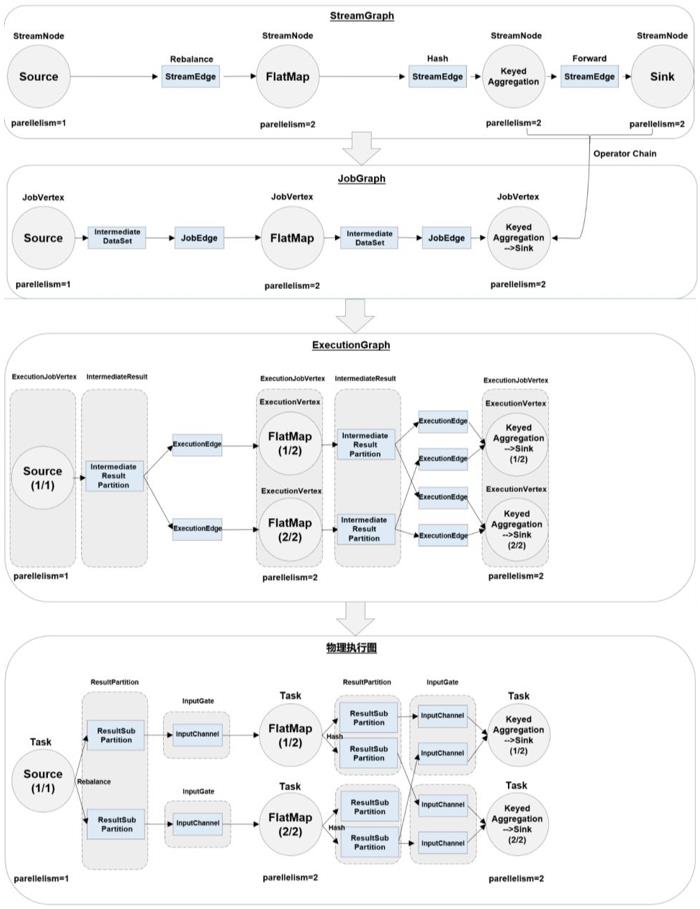
4. 作业图(JobGraph)与执行图(ExecutionGraph)
Flink 中任务调度执行的图,按照生成顺序可以分成四层:
逻辑流图(StreamGraph)→ 作业图(JobGraph)→ 执行图(ExecutionGraph)→ 物理图(Physical Graph)
- 逻辑流图(StreamGraph)(数据流图dataflow graph)
这是根据用户通过 DataStream API 编写的代码生成的最初的DAG图,用来表示程序的拓扑结构。这一步一般在客户端完成。 - 作业图(JobGraph)
StreamGraph 经过优化后生成的就是作业图(JobGraph),这是提交给 JobManager 的数据结构,确定了当前作业中所有任务的划分。主要的优化为: 将多个符合条件的节点链接在一起合并成一个任务节点,形成算子链,这样可以减少数据交换的消耗。JobGraph一般也是在客户端生成的,在作业提交时传递给JobMaster。 - 执行图(ExecutionGraph)
JobMaster 收到 JobGraph 后,根据它来生成执行图(ExecutionGraph)。ExecutionGraph 是 JobGraph 的并行化版本,是调度层最核心的数据结构。 - 物理图(Physical Graph)
JobMaster 生成执行图后, 会将它分发给TaskManager;各个 TaskManager 会根据执行图部署任务,最终的物理执行过程也会形成一张“图”,一般就叫作物理图(Physical Graph)。这只是具体执行层面的图,并不是一个具体的数据结构。
物理图主要就是在执行图的基础上,进一步确定数据存放的位置和收发的具体方式。有了物理图,TaskManager 就可以对传递来的数据进行处理计算了。
env.socketTextStream().flatMap(…).keyBy(0).sum(1).print();
5. 任务(Tasks)和任务槽(Task Slots)
-
任务槽数量的设置
我们可以通过集群的配置文件来设定 TaskManager 的 slot 数量:taskmanager.numberOfTaskSlots: 8通过调整 slot 的数量,我们就可以控制子任务之间的隔离级别。
-
任务对任务槽的共享
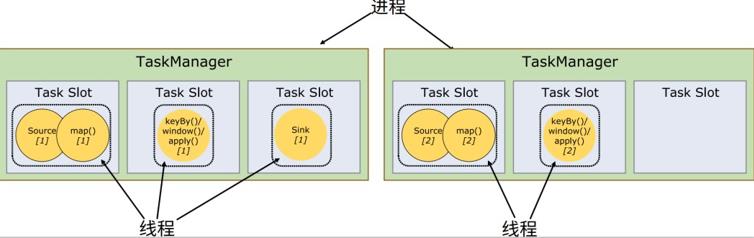
默认情况下,Flink 是允许子任务共享 slot 的。只要属于同一个作业,那么对于不同任务节点的并行子任务,就可以放到同一个 slot 上执行。
每个任务节点的并行子任务一字排开,占据不同的 slot;而不同的任务节点的子任务可以共享 slot。一个 slot 中,可以将程序处理的所有任务都放在这里执行,我们把它叫作保存了整个作业的运行管道(pipeline)。
我们不是希望并行处理、任务之间相互隔离吗,为什么这里又允许共享 slot 呢?
一个slot对应了一组独立的计算资源。在之前不做共享的时候,每个任务都平等地占据了一个slot,但其实不同的任务对资源的占用是不同的。这样资源的利用就出现了极大的不平衡,“忙的忙死,闲的闲死”。
解决这一问题的思路就是允许slot共享。当我们将资源密集型和非密集型的任务同时放到一个 slot 中,它们就可以自行分配对资源占用的比例,从而保证最重的活平均分配给所有的
TaskManager。slot 共享的好处就是允许我们保存完整的作业管道。这样一来,即使某个 TaskManager 出现故障宕机,其他节点也可以完全不受影响,作业的任务可以继续执行。
另外,同一个任务节点的并行子任务是不能共享 slot 的,所以允许slot 共享之后,运行作业所需的 slot 数量正好就是作业中所有算子并行度的最大值。
我们也可以通过设置“slot 共享组”(SlotSharingGroup)手动指定:
.map(word -> Tuple2.of(word, 1L)).slotSharingGroup(“1”);这样,只有属于同一个slot共享组的子任务,才会开启slot共享;不同组之间的任务是完全隔离的,必须分配到不同的 slot 上。在这种场景下,总共需要的 slot 数量,就是各个slot共享组最大并行度的总和。
-
任务槽和并行度的关系
Slot和并行度确实都跟程序的并行执行有关,但两者是完全不同的概念。task slot是静态的概念,指TaskManager 具有的并发执行能力,可以通过参数 taskmanager.numberOfTaskSlots 进行配置;而并行度(parallelism)是动态概念,也就是TaskManager运行程序时实际使用的并发能力,可以通过参数parallelism.default 进行配置。换句话说,并行度如果小于等于集群中可用 slot 的总数,程序是可以正常执行的,因为 slot 不一定要全部占用,有十分力气可以只用八分;而如果并行度大于可用 slot 总数,导致超出了并行能力上限,那么心有余力不足,程序就只好等待资源管理器分配更多的资源了。
关于 Apache Flink 和实时计算的最新动态未来方向,你想知道的都在这里
摘要:Flink Forward Asia 2021 即将于 1 月 8 日开启,除了 80+ 干货议题,还有哪些内容值得关注?本文带你一探究竟!主要内容包括:
大会直播
圆桌论坛
有奖问答
Hackathon
Tips:点击「阅读原文」预约 FFA 2021~
大会直播

1 月 8-9 日,Flink Forward Asia 2021 即将重磅启动。作为开源大数据领域的顶级盛会之一,Flink Forward 持续集结最佳行业实践以及 Flink 最新技术动态,并积极拥抱生态伙伴,共建繁荣开源大数据生态。
其中,阿里巴巴、腾讯、戴尔、字节跳动、快手、网易、工商银行、蔚来、移动、联通、BIGO 等全球 40+ 多行业一线厂商,将在以下专场分享 80+ 干货议题:
主会场、Flink 核心技术、行业实践、平台建设、实时数据湖、实时数仓、流批一体、开源解决方案、生产实践、机器学习。
大会议程详见官网:
https://flink-forward.org.cn
大会线上观看地址 (记得点击预约直播哦) :
https://developer.aliyun.com/special/ffa2021/live
圆桌论坛

FFA 组委会特邀多位行业大咖,以圆桌论坛的形式畅聊 Flink 和实时计算的未来发展,讨论涉及诸多开发者和社区伙伴高度关注的问题,比如:
Flink 在实时计算方面是否已趋于成熟?
如何看待 Flink 与生态项目之间的关系?
实时计算的未来应该是什么样的?
如何看待内部技术实践、技术创新与开源社区之间的关系?
精彩内容抢先看~
有奖问答
为了更好地拉近 FFA 观众与讲师的距离,提高互动性,我们开设了 FFA 有奖问答活动,为观众和讲师之间搭建了线上沟通的桥梁。参与提问还有机会获得 FFA 定制礼品哦~
FFA 2021 有奖问答入口:
https://developer.aliyun.com/ask/387294
在直播窗口下方也可以找到跳转入口,具体步骤如下:

Hackathon
本次 Flink Forward Asia Hackathon 为开放式命题,以实时计算为主题,以 Flink 为工具,解决大家日常学习和工作中遇到的实际问题。可以是气象预测、城市交通管理、金融交易监察这样关乎国计民生的选题;也可以是提升购物体验、增强游戏互动性、个人运动管理、社交等改善生活中琐碎点滴的选题;还可以是对 Flink 本身的创新和改进。
选手需要使用 (但不仅限于使用) Flink 生态中的各种工具,包括统计分析、机器学习、复杂事件处理、各类 connector、StatefulFunction 等等来完成自己的选题。
本次比赛组委会对提交的所有项目进行了评审,其中不乏有充满创意的想法和构思。恭喜以下队伍入围决赛 (顺序不分先后) 冲击最终冠军大奖!

Flink Forward Asia Hackathon 决赛将于 1 月 9 日 8:00 开始,届时大会直播网站也会同步直播,敬请关注!
大会线上观看地址 (记得点击预约直播哦) :
https://developer.aliyun.com/special/ffa2021/live
赞助与合作


▼ 关注「Apache Flink」,获取更多技术干货 ▼
更多 Flink 相关技术问题,可扫码加入社区钉钉交流群~

 戳我,预约 FFA 2021~
戳我,预约 FFA 2021~
以上是关于最新 Flink 1.13 运行时架构(JobManagerTaskManagerYARNSlotsJobGraph)快速入门详细教程的主要内容,如果未能解决你的问题,请参考以下文章