信息论_熵
Posted rebel3
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了信息论_熵相关的知识,希望对你有一定的参考价值。
信息论主要是对信号所含信息的多少进行量化,其基本思想是一个不太可能发生的事情要比一个可能发生的事情提供更多的信息。
度量信息的集中常用指标有信息熵、条件熵、互信息、交叉熵。
信息熵
信息熵(entropy)简称熵,是对随机变量不确定性的度量。定义为:
H(x)=∑pi*log2(pi)
用以下代码来实现对0-1分布变量概率与其信息熵的关系:
import matplotlib.pyplot as plt # %matplotlib inline 只有Jupyter需要加这一行,其余常用editor都无需此行代码 p = np.arange(0, 1.05, 0.05) HX = [] for i in p: if i == 0 or i == 1: HX.append(0) else: HX.append(-i * np.log2(i) - (1 - i) * np.log2(1 - i)) plt.plot(p, HX, label=‘entropy‘) plt.xlabel(‘P‘) plt.ylabel(‘H(x)‘) plt.show()
其中p是一个一维数组,其值范围为[0,1.05),步长为0.05,HX是一个列表,用于记录一维数组每个数据的熵值。
得到结果如下:
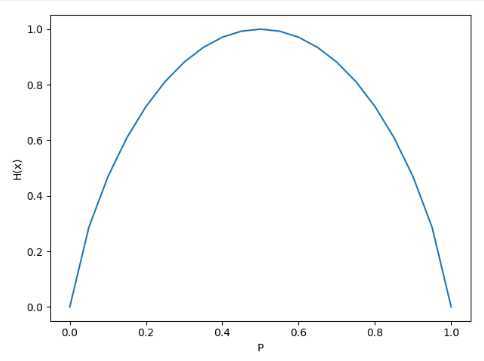
可见,当概率为0或1时,H(x)= 0 ;当 p = 0.5 时,随机变量的不确定性最大,即图像中熵值最大。
条件熵
条件熵 H(Y|X) 白哦是在已知随机变量 X 的条件下,随机变量 Y 的不确定性。定义如下:
H(Y|X)=-∑ni=1∑mj=1p(X=xiY=yi)*x*logp(Y=yi|X=xi)
由定义可知,H(Y|X)≤H(Y)
互信息
互信息又称信息增益,评价一个事件的出现对另一个事件出现所贡献的信息量。计为:
I(X,Y)=H(Y)-H(Y|X)
在决策树的特征选择中,信息增益为主要依据。对于给定训练数据集D,假设数据集由n维特征构成,构建决策树时,一个核心问题就是选择哪个特征来划分数据集,使得划分后的纯度最大。一般而言,信息增益越大,意味着使用某信息 a 来划分所得“纯度提升”越大。因此常用信息增益来固件决策树划分属性。
相对熵
相对熵之两个随机变量的个体差异,个体差异越大,相对熵越大。又被称为KL散度,如p(x)表示 X 的真实分布,q(s) 表示X的训练分布与预测分布,则p与q的相对熵为:
KL(p(x)||q(x))=∑x∈Xp(x)log2(p(x)/q(x))
相对熵的意义在于:
1.相对熵不是传统意义上的距离,没有对称性,即KL(p(x)||q(x))≠KL(q(x)||p(x))
2.当预测分布与实际分布完全相等时,相对熵为0
3.如果两个分布差异越大,则相对熵也越大;反之相对熵越小
4.相对熵满足非负性
交叉熵
交叉嫡可在神经网络(机器学习)中作为代价函数,p表示真实标记的分布,q则为训练后的模型的预测标记分布,交叉熵代价函数可以衡量p与q的相似性。交叉熵作为代价函数还有一个好处是使用sigmoid函数在梯度下降时能避免均方误差代价函数学习速率降低的问题,因为学习速率可以被输出的误差所控制。交叉熵(cross entropy),其定义为:
H(p(x0, q(x)) = H(X) + KL(p(x)|q(x))
其中:
H(x)=-∑x∈Xp(x)log2(x)
KL(p(x)||q(x))= Sxup(x)(logz p(x)- lgq(x)故H(p(x0, q(x))化简后为:
故H(p(x0, q(x))化简后为
H(p(x0, q(x))= ∑x∈Xp(x)(log2p(x)-log2q(x))
以上是关于信息论_熵的主要内容,如果未能解决你的问题,请参考以下文章