HDFS内存配置
Posted tesla-turing
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HDFS内存配置相关的知识,希望对你有一定的参考价值。
下图是HDFS的架构:
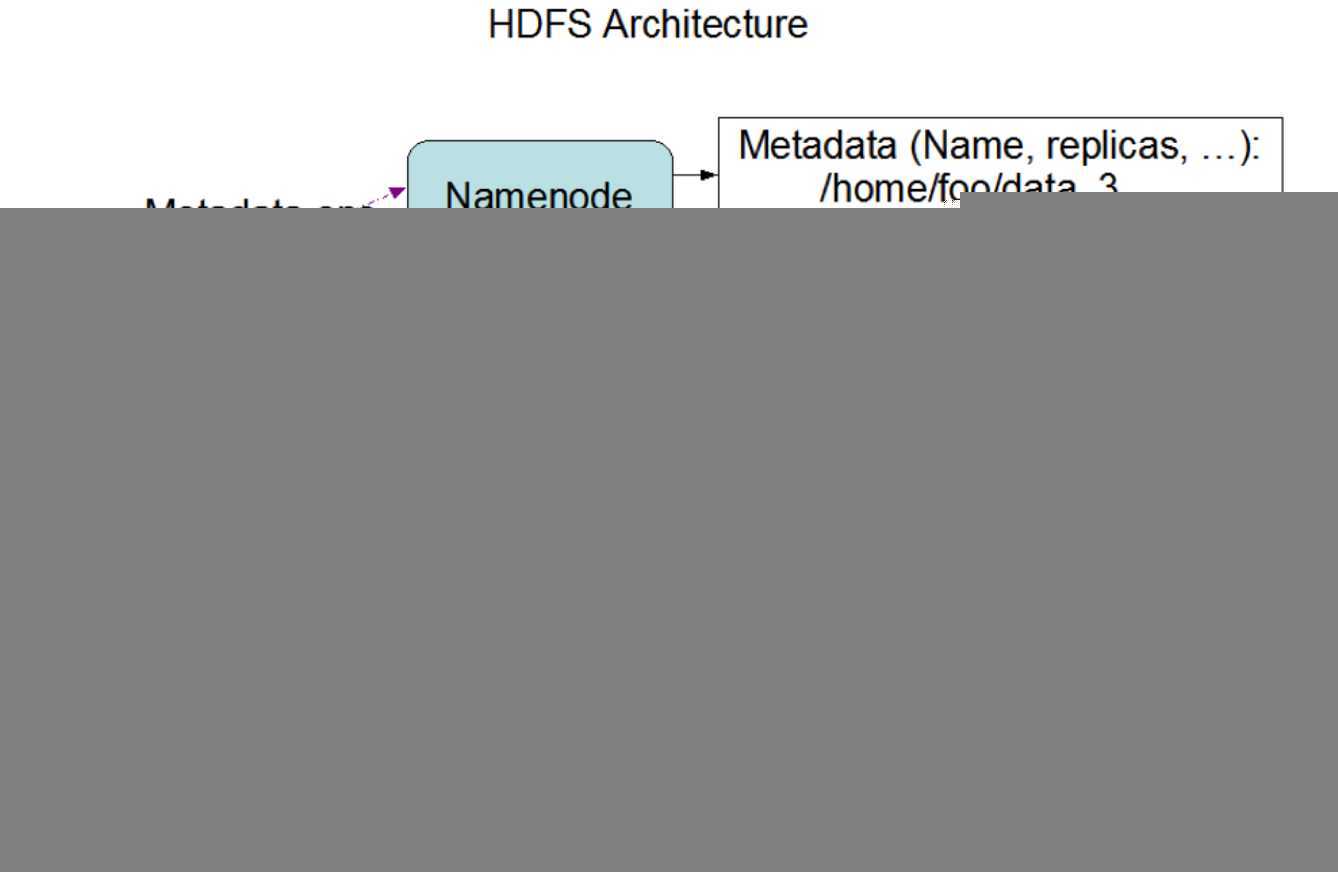
从上图中可以知道,HDFS包含了NameNode、DataNode以及Client三个角色,当我们的HDFS没有配置HA的时候,那还有一个角色就是SecondaryNameNode,这四个角色都是基于JVM之上的Java进程。既然是Java进程,那我们肯定可以调整这四个角色使用的内存的大小。接下来我们就详细来看下怎么配置HDFS每个角色的内存
我们这里说配置的内存主要还是指JVM的堆内存
默认的内存配置
NameNode
当启动我们在视频课程中搭建好HDFS集群后,我们可以在master上通过如下的命令来查看NameNode和SecondaryNameNode这两个进程占用的堆内存:
## 在master机器上执行 ps -ef | grep NameNode
得到的结果如下:
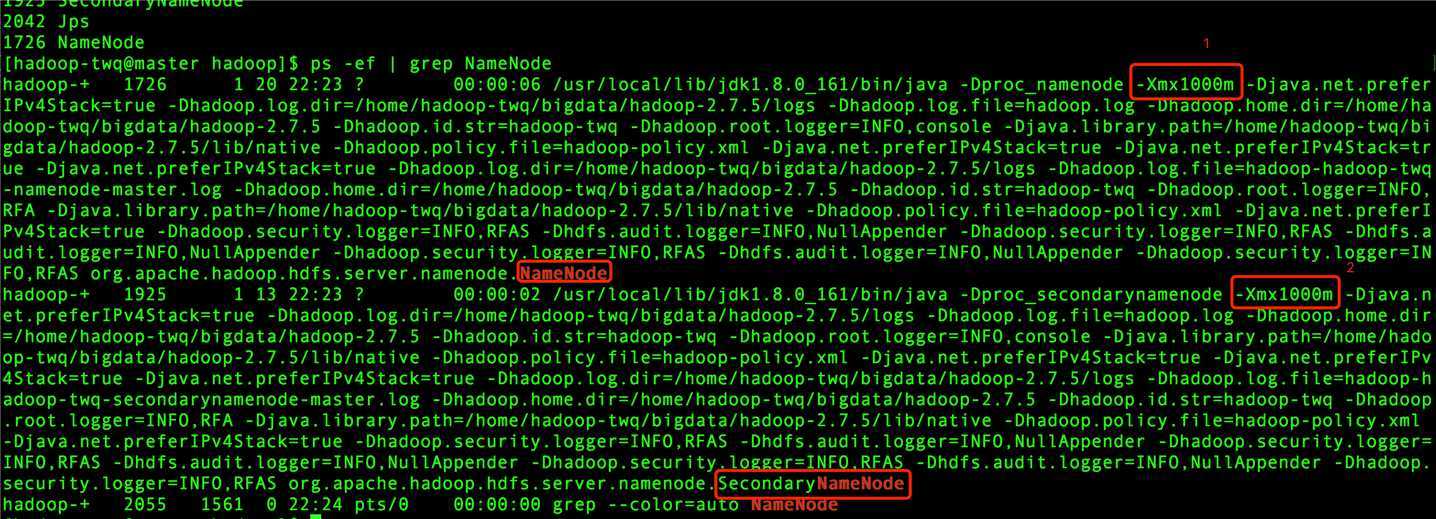
上图中第1处的-Xmx1000m表示NameNode的堆内存是1000M
上图中第2处的-Xmx1000m表示SecondaryNameNode的堆内存是1000M
DataNode
我们可以通过如下的命令来查看slave1和slave2上的DataNode占用的堆内存:
ps -ef | grep DataNode
得到的结果如下:


从上图可以看出,两个slave上的DataNode的堆内存都是1000M
Client
当我们执行下面命令的时候:
hadoop fs -ls /
其实也是启动一个名字为FsShell的Java进程,如下图:

这个FsShell进程就是一个Client进程,这个Client进程的默认堆内存是512M
结论
- HDFS集群中的角色(NameNode、SecondaryNameNode、DataNode)的默认的堆内存大小都是
1000M - Client进程的堆内存大小是
512M
如何配置内存
要想知道如何配置每个角色的内存,我们首先需要搞明白上面默认的内存配置是在哪里配置的。
这些默认的配置都是在Hadoop的安装目录下的配置目录下文件hadoop-env.sh中,即/home/hadoop-twq/bigdata/hadoop-2.7.5/etc/hadoop/hadoop-env.sh
在hadoop-env.sh文件中有几个和内存相关的配置:
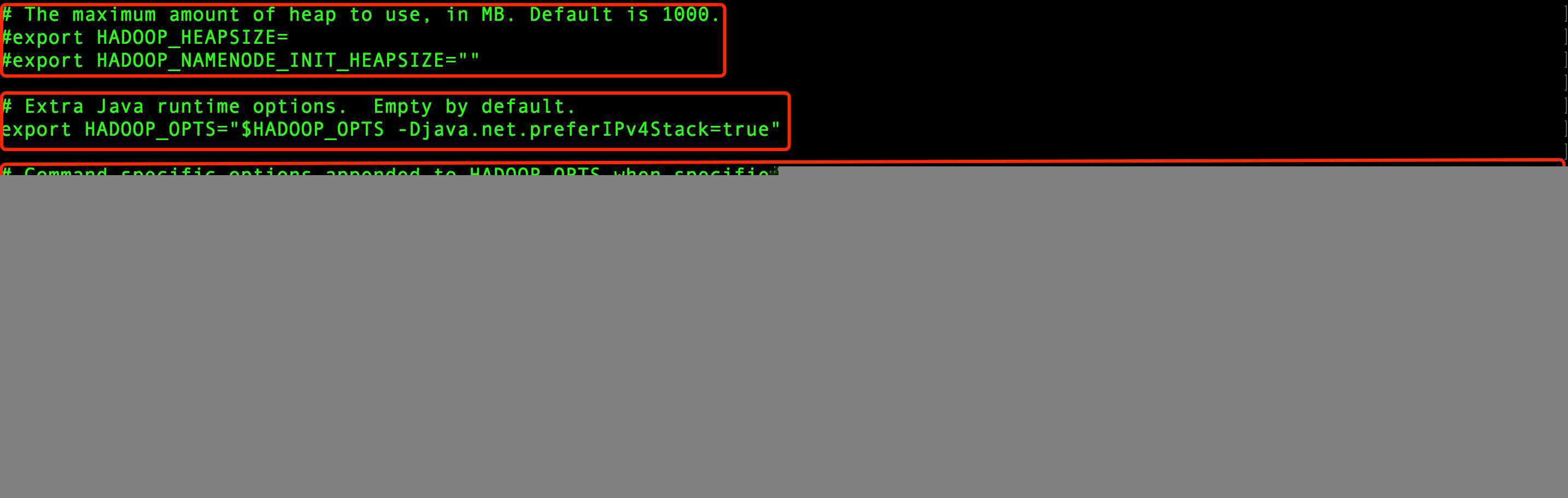
我们按照上图从上往下,分别仔细看下
# The maximum amount of heap to use, in MB. Default is 1000. #export HADOOP_HEAPSIZE= #export HADOOP_NAMENODE_INIT_HEAPSIZE=""
HADOOP_HEAPSIZE:表示HDFS中所有角色的最大堆内存,默认是1000M,这个也就是我们所有HDFS角色进程的默认堆内存大小
HADOOP_NAMENODE_INIT_HEAPSIZE:表示NameNode的初始化堆内存大小,默认也是1000M。
# Extra Java runtime options. Empty by default. export HADOOP_OPTS="$HADOOP_OPTS -Djava.net.preferIPv4Stack=true"
HADOOP_OPTS: 表示HDFS所有角色的JVM参数设置,对于HDFS所有角色的通用的JVM参数可以通过这个配置来设置。默认的话是空的配置
# Command specific options appended to HADOOP_OPTS when specified export HADOOP_NAMENODE_OPTS="-Dhadoop.security.logger=$HADOOP_SECURITY_LOGGER:-INFO,RFAS -Dhdfs.audit.logger=$HDFS_AUDIT_LOGGER :-INFO,NullAppender $HADOOP_NAMENODE_OPTS"
HADOOP_NAMENODE_OPTS:针对NameNode的特殊的JVM参数的配置,默认只设置hadoop.security.logger和hdfs.audit.logger两个日志级别信息参数
export HADOOP_DATANODE_OPTS="-Dhadoop.security.logger=ERROR,RFAS $HADOOP_DATANODE_OPTS"
HADOOP_DATANODE_OPTS:针对DataNode的特殊的JVM参数的配置,默认只设置hadoop.security.logger日志级别信息参数
export HADOOP_SECONDARYNAMENODE_OPTS="-Dhadoop.security.logger=$HADOOP_SECURITY_LOGGER:-INFO,RFAS -Dhdfs.audit.logger=$HDFS_AUD IT_LOGGER:-INFO,NullAppender $HADOOP_SECONDARYNAMENODE_OPTS"
HADOOP_SECONDARYNAMENODE_OPTS:针对SecondaryNameNode的特殊的JVM参数的配置,默认只设置hadoop.security.logger和hdfs.audit.logger两个日志级别信息参数
export HADOOP_PORTMAP_OPTS="-Xmx512m $HADOOP_PORTMAP_OPTS"
HADOOP_PORTMAP_OPTS:这个是在HDFS格式化时需要的JVM配置,也就是执行hdfs namenode -format时的JVM配置
# The following applies to multiple commands (fs, dfs, fsck, distcp etc) export HADOOP_CLIENT_OPTS="-Xmx512m $HADOOP_CLIENT_OPTS"
HADOOP_CLIENT_OPTS:表示HDFS客户端命令启动的JVM的参数配置,这里配置的JVM的堆内存的大小为512M。这个配置是针对客户端命令(比如fs, dfs, fsck, distcp等)的JVM堆内存配置
NameNode、DataNode以及Client进程堆内存的配置方式
NameNode、DataNode以及Client进程堆内存是在hadoop-env.sh中的配置HADOOP_NAMENODE_OPTS、HADOOP_DATANODE_OPTS以及HADOOP_CLIENT_OPTS配置的
所以我们如果想配置NameNode的堆内存可以有两种方式:
## 第一种方式 export HADOOP_NAMENODE_INIT_HEAPSIZE="20480M" ## 第二种方式 export HADOOP_NAMENODE_OPTS="-Xms20480M -Xmx20480M -Dhadoop.security.logger=$HADOOP_SECURITY_LOGGER:-INFO,RFAS -Dhdfs.audit.logger=$HDFS_AUDIT_LOGGER:-INFO,NullAppender $HADOO P_NAMENODE_OPTS"
如果我们想配置DataNode的堆内存可以有以下两种方式:
## 第一种方式 export HADOOP_HEAPSIZE=2048M ## 第二种方式,这种方式会覆盖掉上面第一种方式的配置 export HADOOP_DATANODE_OPTS="-Xms2048M -Xmx2048M -Dhadoop.security.logger=ERROR,RFAS $HADOOP_DATANODE_OPTS"
如果我们想配置Client的堆内存可以有如下方式:
export HADOOP_CLIENT_OPTS="-Xmx1024m $HADOOP_CLIENT_OPTS"
以上是关于HDFS内存配置的主要内容,如果未能解决你的问题,请参考以下文章