python爬取html中文乱码
Posted bingchuan-study
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python爬取html中文乱码相关的知识,希望对你有一定的参考价值。
环境:
python3.6
爬取网址:https://www.dygod.net/html/tv/hytv/
爬取代码:
import requests
url = ‘https://www.dygod.net/html/tv/hytv/‘
req = requests.get(url)
print(req.text)
爬取结果:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<META http-equiv=Content-Type content="text/html; charset=gb2312">
<title>µçÊÓ¾ç / »ªÓïµçÊÓ¾ç_µçÓ°ÌìÌÃ-ѸÀ×µçÓ°ÏÂÔØ</title>
<meta name="keywords" content="ѸÀ×µçÓ°£¬Ñ¸À×ÏÂÔØ£¬Ãâ·ÑµçÓ°">
<meta name=description content="Ãâ·ÑѸÀ×µçÓ°ÏÂÔØ,ѸÀ×ÏÂÔØ£¬×îºÃµÄѸÀ×ÏÂÔØÕ¾£¬ÊÇÓ°ÃÔµÄÊ×Ñ¡">
<link href="/css/dygod.css" rel="stylesheet" type="text/css" />
如上,title内容出现乱码,自己感觉应该是编码的问题,但是不知道如何解决,于是上网查看
参考网址:
https://www.cnblogs.com/bw13/p/6549248.html
问题找到,原来是reqponse header只指定了type,但是没有指定编码(一般现在页面编码都直接在html页面中),查找原网页可以看到
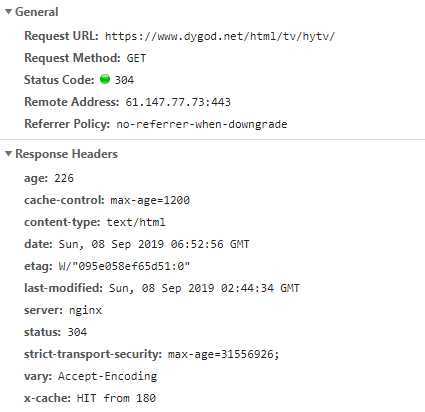
在content-type属性中,未设置编码格式,正常设置如下
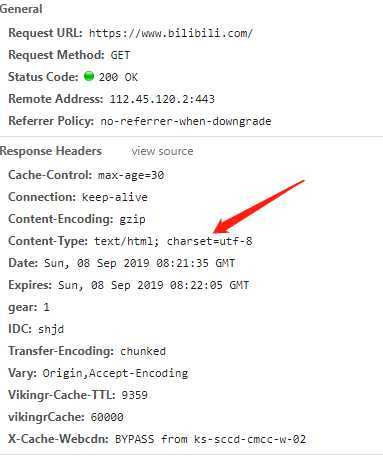
所以使用默认的编码格式
《HTTP权威指南》里第16章国际化里提到,如果HTTP响应中Content-Type字段没有指定charset,则默认页面是‘ISO-8859-1‘编码。
这处理英文页面当然没有问题,但是中文页面,就会有乱码了!
print(req.apparent_encoding)
结果为:GB2312
所以只需要加上
req.encoding = req.apparent_encoding
这个就可以了!
代码:
import requests
url = ‘https://www.dygod.net/html/tv/hytv/‘
req = requests.get(url)
req.encoding = req.apparent_encoding
print(req.text)
结果中文就不会乱码了
以上是关于python爬取html中文乱码的主要内容,如果未能解决你的问题,请参考以下文章