python requests返回中文乱码
Posted 大神笨蛋
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python requests返回中文乱码相关的知识,希望对你有一定的参考价值。
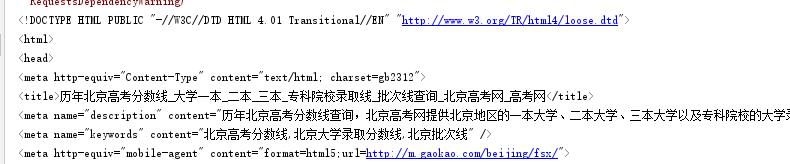
最近在使用python爬取高考分数线时,获得的response里面输出了中文乱码:
from bs4 import BeautifulSoup import requests def get_provice_link(url): response=requests.get(url) print(response.text) soup=BeautifulSoup(response.text,\'lxml\') print(soup.title) def main(): url=\'http://www.gaokao.com/beijing/fsx/\' get_provice_link(url) if __name__ == \'__main__\': main()

解决方案是:将response设置编码格式,一般的如果网页中没有标明type格式,一般默认的都是\'ISO-8859-1\'编码,我们只需要把编码格式转为 \'gb2312\' 即可
添加一行代码:下面标红的,这样就可以解决。
response=requests.get(url) response.encoding = \'gb2312\' print(response.text)

以上是关于python requests返回中文乱码的主要内容,如果未能解决你的问题,请参考以下文章
请教python 采 集 requests post请求一个第三方接口中文乱码的问题
Python3的requests类抓取中文页面出现乱码的解决办法