.NET基础拾遗字符串集合和流1
Posted 王乐
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了.NET基础拾遗字符串集合和流1相关的知识,希望对你有一定的参考价值。
一、字符串处理
1.1 StringBuilder类型
众所周知,在.NET中String是引用类型,具有不可变性,当一个String对象被修改、插入、连接、截断时,新的String对象就将被分配,这会直接影响到性能。在这个组装过程中必将会产生很多临时的String对象,而这些String对象将会在堆上分配,需要GC来回收。
鉴于此,在.NET中提供了StringBuilder,其设计思想源于构造器(Builder)设计模式,致力于解决复杂对象的构造问题。StringBuilder类型在最终生成String对象之前,将不会产生任何String对象,这很好地解决了字符串操作的性能问题。
以下代码展示了使用StringBuilder和不适用StringBuilder的性能差异:(这里的性能检测工具使用了老赵的CodeTimer类)


public class Program { private const String item = "一个项目"; private const String split = ";"; static void Main(string[] args) { int number = 10000; // 使用StringBuilder CodeTimer.Time("使用StringBuilder: ", 1, () => { UseStringBuilder(number); }); // 不使用StringBuilder CodeTimer.Time("使用不使用StringBuilder: : ", 1, () => { NotUseStringBuilder(number); }); Console.ReadKey(); } static String UseStringBuilder(int number) { System.Text.StringBuilder sb = new System.Text.StringBuilder(); for (int i = 0; i < number; i++) { sb.Append(item); sb.Append(split); } sb.Remove(sb.Length - 1, 1); return sb.ToString(); } static String NotUseStringBuilder(int number) { String result = ""; for (int i = 0; i < number; i++) { result += item; result += split; } return result; } }
上述代码的运行结果如下图所示,可以看出由于StringBuilder不会产生任何的中间字符串变量,因此效率上优秀不少!
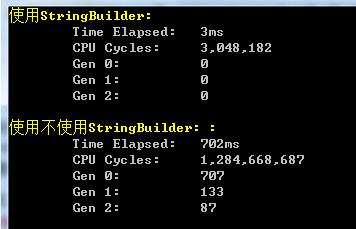
看到StringBuilder这么优秀,不禁想发出一句:卧槽,牛逼!
于是,我们拿起我们的锤子(Reflector)撕碎StringBuilder的外套,看看里面到底装了什么?我们发现,在StringBuilder中定义了一个字符数组m_ChunkChars,它保存StringBuilder所管理着的字符串中的字符。

经过对StringBuilder默认构造方法的分析,系统默认初始化m_ChunkChars的长度为16(0x10),当新追加进来的字符串长度与旧有字符串长度之和大于该字符数组容量时,新创建字符数组的容量会增加到2n+1(假如当前字符数组容量为2n)。
1.2 String和Byte[]对象之间如何相互转换?
字符串和字节数组的转换,事实上是代表了现实世界信息和数字世界信息之间的转换。
(1)比特:bit是一个位,计算机内物理保存的最基本单元,一个bit就是一个二进制位;
(2)字节:byte由8个bit构成,其值可以由一个0~255的整数表示;
(3)编码:编码是数字信息和现实信息的转换机制,一种编码通常就定义了一种字符集和转换的原则,常用的编码方式包括UTF8、GB2312、Unicode等。
下图直观地展示了比特、字节、编码和字符串的关系:
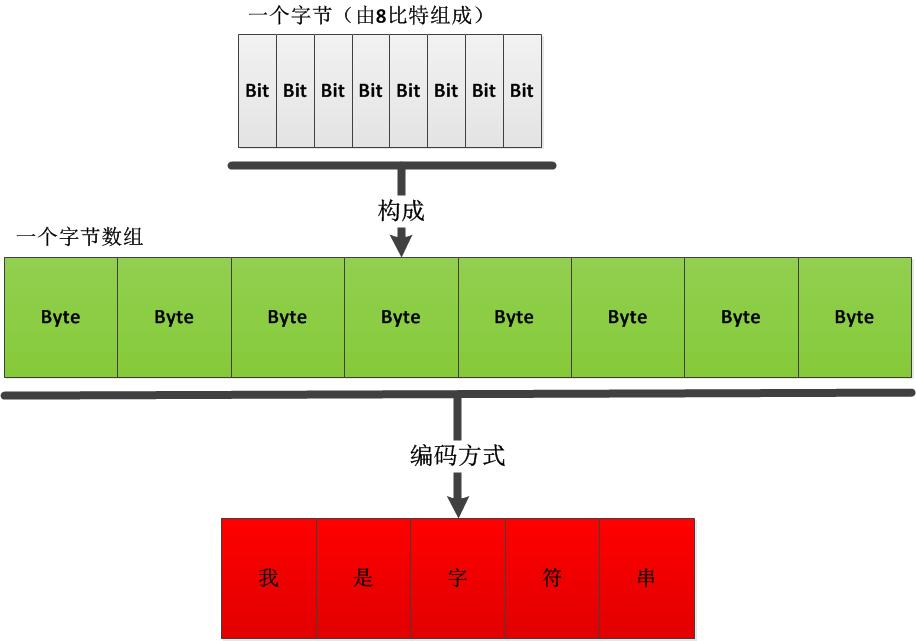
可以看出,字节数组和字符串的转换必然涉及到某种编码方式,不同的编码方式由不同的转换结果。在C#中,可以使用System.Text.Encoding来管理常用的编码。
下面的代码展示了如何在字节数组和字符串之间进行转换(分别使用UTF8、GB2312以及Unicode三种编码方式):
class Program { static void Main(string[] args) { string s = "我是字符串,I am a string!"; // 字节数组 -> 字符串 Byte[] utf8 = StringToByte(s, Encoding.UTF8); Byte[] gb2312 = StringToByte(s, Encoding.GetEncoding("GB2312")); Byte[] unicode = StringToByte(s, Encoding.Unicode); Console.WriteLine(utf8.Length); Console.WriteLine(gb2312.Length); Console.WriteLine(unicode.Length); // 字符串 -> 字符数组 Console.WriteLine(ByteToString(utf8, Encoding.UTF8)); Console.WriteLine(ByteToString(gb2312, Encoding.GetEncoding("GB2312"))); Console.WriteLine(ByteToString(unicode, Encoding.Unicode)); Console.ReadKey(); } // 字符串 -> 字节数组 static Byte[] StringToByte(string str, Encoding encoding) { if (string.IsNullOrEmpty(str)) { return null; } return encoding.GetBytes(str); } // 字节数组 -> 字符串 static string ByteToString(Byte[] bytes, Encoding encoding) { if (bytes == null || bytes.Length <= 0) { return string.Empty; } return encoding.GetString(bytes); } }
上述代码的运行结果如下图所示:
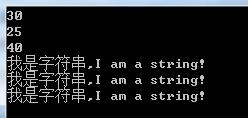
我们也可以从上图中看出,不同的编码方式产生的字节数组的长度各不相同。
1.3 BASE64编码的作用以及C#中对其的支持
和传统的编码不同,BASE64编码的设计致力于混淆那些8位字节的数据流(解决网络传输中的明码问题),在网络传输、邮件等系统中被广泛应用。需要明确的是:BASE64不属于加密机制,但它却是把明码变成了一种很难识别的形式。
BASE64的算法如下:
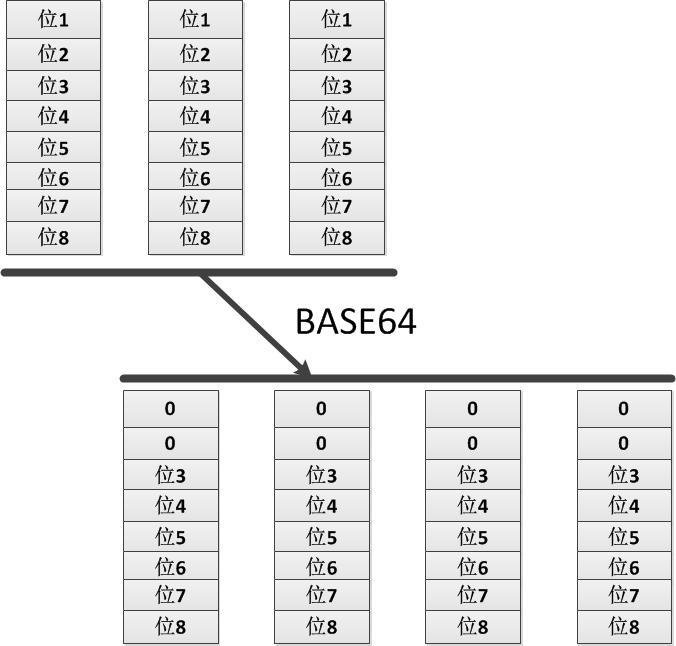
BASE64把所有的位分开,并且重新组合成字节,新的字节只包含6位,最后在每个字节前添加两个0,组成了新的字节数组。例如:一个字节数组只包含三个字节(每个字节又有8位比特),对其进行BASE64编码时会将其分配到4个新的字节中(为什么是4个呢?计算3*8/6=4),其中每个字节只填充低6位,最后把高2位置为零。
下图清晰地展示了上面所讲到的BASE64的算法示例:
在.NET中,BASE64编码的应用也很多,例如在ASP.NET WebForm中,默认为我们生成了一个ViewState来保持状态,如下图所示:

这里的ViewState其实就是服务器在返回给浏览器前进行了一次BASE64编码,我们可以通过一些解码工具进行反BASE64编码查看其中的奥秘:
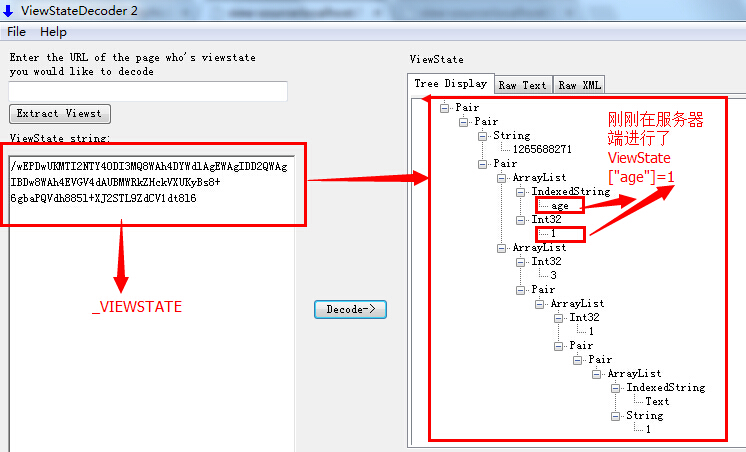
那么,问题来了?在.NET中开发中,怎样来进行BASE64的编码和解码呢,.NET基类库中提供了一个Convert类,其中有两个静态方法提供了BASE64的编码和解码,但要注意的是:Convert类型在转换失败时会直接抛出异常,我们需要在开发中注意对潜在异常的处理(比如使用is或as来进行高效的类型转换)。下面的代码展示了其用法:
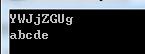
class Program { static void Main(string[] args) { string test = "abcde "; // 生成UTF8字节数组 byte[] bytes = Encoding.UTF8.GetBytes(test); // 转换成Base64字符串 string base64 = BytesToBase64(bytes); Console.WriteLine(base64); // 转换回UTF8字节数组 bytes = Base64ToBytes(base64); Console.WriteLine(Encoding.UTF8.GetString(bytes)); Console.ReadKey(); } // Bytes to Base64 static string BytesToBase64(byte[] bytes) { try { return Convert.ToBase64String(bytes); } catch { return null; } } // Base64 to Bytes static Byte[] Base64ToBytes(string base64) { try { return Convert.FromBase64String(base64); } catch { return null; } } }
上面代码的执行结果如下图所示:
1.4 简述SecureString安全字符串的特点和用法
顾名思义,SecureString意为安全的字符串,它被设计用来保存一些机密的字符串,完成传统字符串所不能做到的工作。
(1)传统字符串以明码的形式被分配在内存中,一个简单的内存读写软件就可以轻易地捕获这些字符串,而在这某些机密系统中是不被允许的。也许我们会觉得对字符串加密就可以解决类似问题,But,事实总是残酷的,对字符串加密时字符串已经以明码方式驻留在内存中很久了!对于该问题唯一的解决办法就是在字符串的获得过程中直接进行加密,SecureString的设计初衷就是解决该类问题。
(2)为了保证安全性,SecureString是被分配在非托管内存上的(而普通String是被分配在托管内存中的)且SecureString的对象从分配的一开始就以加密的形式存在,我们所有对于SecureString的操作(无论是增删查改)都是逐字符进行的。
逐字符机制:在进行这些操作时,驻留在非托管内存中的字符串就会被解密,然后进行具体操作,最后再进行加密。不可否认的是,在具体操作的过程中有小段时间字符串是处于明码状态的,但逐字符的机制让这段时间维持在非常短的区间内,以保证破解程序很难有机会读取明码的字符串。
(3)为了保证资源释放,SecureString实现了标准的Dispose模式(Finalize+Dispose双管齐下,因为上面提到它是被分配到非托管内存中的),保证每个对象在作用域退出后都可以被释放掉。
内存释放方式:将其对象内存全部置为0,而不是仅仅告诉CLR这一块内存可以分配,当然这样做仍然是为了确保安全。熟悉C/C++的朋友可能就会很熟悉,这不就是 memset 函数干的事情嘛!下面这段C代码便使用了memset函数将内存区域置为0:
// 下面申请的20个字节的内存有可能被别人用过 char chs[20]; // memset内存初始化:memset(void *,要填充的数据,要填充的字节个数) memset(chs,0,sizeof(chs));
看完了SecureString的原理,现在我们通过下面的代码来熟悉一下在.NET中的基本用法:
using System; using System.Runtime.InteropServices; using System.Security; namespace UseSecureString { class Program { static void Main(string[] args) { // 使用using语句保证Dispose方法被及时调用 using (SecureString ss = new SecureString()) { // 只能逐字符地操作SecureString对象 ss.AppendChar(\'e\'); ss.AppendChar(\'i\'); ss.AppendChar(\'s\'); ss.AppendChar(\'o\'); ss.AppendChar(\'n\'); ss.InsertAt(1, \'d\'); // 打印SecureStrign对象 PrintSecureString(ss); } Console.ReadKey(); } // 打印SecureString对象 public unsafe static void PrintSecureString(SecureString ss) { char* buffer = null; try { // 只能逐字符地访问SecureString对象 buffer = (char*)Marshal.SecureStringToCoTaskMemUnicode(ss); for (int i = 0; *(buffer + i) != \'\\0\'; i++) { Console.Write(*(buffer + i)); } } finally { // 释放内存对象 if (buffer != null) { Marshal.ZeroFreeCoTaskMemUnicode((System.IntPtr)buffer); } } } } }
其运行显示的结果很简单:
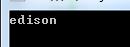
这里需要注意的是:为了显示SecureString的内容,程序需要访问非托管内存,因此会用到指针,而要在C#使用指针,则需要使用unsafe关键字(前提是你在项目属性中勾选了允许不安全代码,对你没看错,指针在C#可以使用,但是被认为是不安全的!)。此外,程序中使用了Marshal.SecureStringToCoTaskMemUnicode方法来把安全字符串解密到非托管内存中,最后就是就是我们不要忘记在使用非托管资源时需要确保及时被释放。
1.5 简述字符串驻留池机制
字符串具有不可变性,程序中对于同一个字符串的大量修改或者多个引用赋值同一字符串在理论上会产生大量的临时字符串对象,这会极大地降低系统的性能。对于前者,可以使用StringBuilder类型解决,而后者,.NET则提供了另一种不透明的机制来优化,这就是传说中的字符串驻留池机制。
当CLR启动时,会在内部创建一个容器,该容器内部维持了一个类似于key-value对的数据结构,其中key是字符串的内容,而value则是字符串在托管堆上的引用(也可以理解为指针或地址)。当一个新的字符串对象需要分配时,CLR首先监测内部容器中是否已经存在该字符串对象,如果已经包含则直接返回已经存在的字符串对象引用;如果不存在,则新分配一个字符串对象,同时把其添加到内部容器中取。But,这里有一个例外是当程序员用new关键字显示地申明新分配一个字符串对象时,该机制将不会起作用。
我们可以通过下面一段代码来加深对于字符串驻留池的理解:
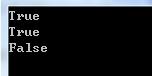
class Program { static void Main(string[] args) { // 01.两个字符串对象,理论上引用应该不相等 // 但是由于字符串池机制,二者指向了同一对象 string a = "abcde"; string b = "abcde"; Console.WriteLine(object.ReferenceEquals(a, b)); // 02.由于编译器的优化,所以下面这个c仍然指向了同一引用地址 string c = "a" + "bc" + "de"; Console.WriteLine(object.ReferenceEquals(a, c)); // 03.显示地使用new来分配内存,这时候字符串池不起作用 char[] arr = { \'a\', \'b\', \'c\', \'d\', \'e\' }; string d = new string(arr); Console.WriteLine(object.ReferenceEquals(a, d)); Console.ReadKey(); } }
在上述代码中,由于字符串驻留池机制的使用,变量a、b、c都指向了同一个字符串实例对象,而d则使用了new关键字显示申明,因此字符串驻留池并没有对其起作用,其运行结果如下图所示:
字符串驻留池的设计本意是为了改善程序的性能,因此在C#中默认是打开了字符串驻留池机制,But,.NET也为我们提供了字符串驻留池的开关接口,如果程序集标记了一个System.Runtime.CompilerServices.CompilationRelaxationsAttribute特性且指定了一个System.Runtime.CompilerServices.CompilationRelaxations.NoStringInterning标志,那么CLR不会采用字符串驻留池机制,其代码声明如下所示,但是我添加后一直没有尝试成功:
[assembly: System.Runtime.CompilerServices.CompilationRelaxations(System.Runtime.CompilerServices.CompilationRelaxations.NoStringInterning)]
PSP:
字符串本性及相关优化(stringbuilder 字符串逐流--键值对结构)
bit---byte--字符数组
以上是关于.NET基础拾遗字符串集合和流1的主要内容,如果未能解决你的问题,请参考以下文章