.NET基础拾遗字符串集合和流3
Posted 王乐
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了.NET基础拾遗字符串集合和流3相关的知识,希望对你有一定的参考价值。
三、流和序列化
3.1 流概念及.NET中常见流
无论什么信息,文字,声音,图像,只要进入了计算机就都被转化为数字,以数字方式运算、存储。由于计算机中使用二进制运算,因此数字只有两个:0 与 1,就是逢 2 进位。所以说最终形式都是一连串的类似00010010101101001111001这样的二进制数据。
要把一片二进制数据逐一输出到某个设备中或从某个设备逐一读取一片二进制数据,不管输入输出设备是什么,我们要用统一的方式来完成这些操作,用一种抽象的方式进行描述,这个抽象描述方式起名为IO流,对应的抽象类为OutputStream和InputStream,不同的实现类就代表不同的输入和输出设备,它们都是针对字节进行操作的。
计算机中的一切都是二进制的字节形式存在。对于“中国”这些字符,首先要得到其对应的字节,然后将字节写入到输出流。读取时,首先读到的是字节,可是我们要把它显示为字符,需要将字节转换成字符。
字符流是字节流的包装,字符流则是直接接受字符串,它内部将串转成字节,再写入底层设备,这为我们向IO设别写入或读取字符串提供了一点点方便。
字符向字节转换时,要注意编码的问题,因为字符串转成字节数组其实是转成该字符的某种编码的字节形式,读取也是反之的道理!!
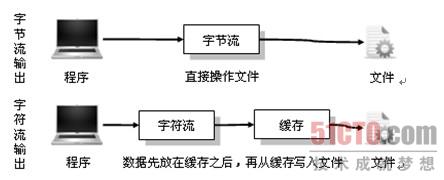
实际上字节流在操作时本身不会用到缓冲区(内存),是文件本身直接操作的,而字符流在操作时使用了缓冲区,通过缓冲区再操作文件,如图所示。
常见的流类型包括:文件流、终端操作流及网络Socket等,在.NET中,System.IO.Stream类型被设计为作为所有流类型的虚基类,当需要自定义一种流类型时也应该直接或者间接地继承自Stream类型。下图展示了在.NET中常见的流类型以及它们的类型结构:
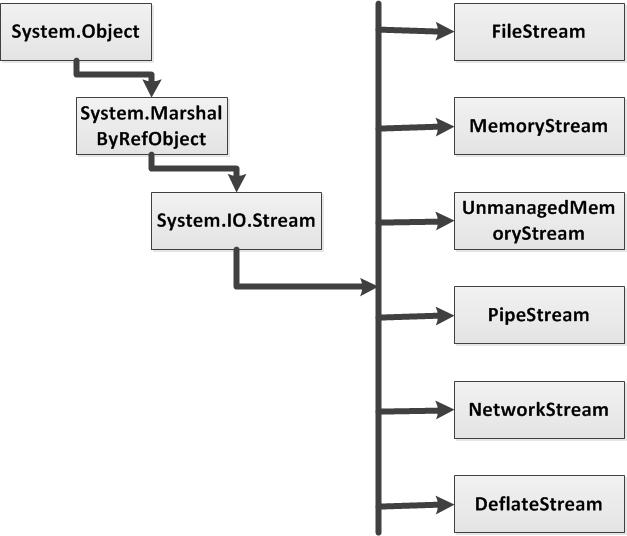
从上图中可以发现,Stream类型继承自MarshalByRefObject类型,这保证了流类型可以跨越应用程序域进行交互。
下面的代码中展示了如何在.NET中使用FileStream文件流进行简单的文件读写操作:


class Program { private const int bufferlength = 1024; static void Main(string[] args) { //创建一个文件,并写入内容 string filename = @"C:\\TestStream.txt"; string filecontent = GetTestString(); try { if (File.Exists(filename)) { File.Delete(filename); } // 创建文件并写入内容 using (FileStream fs = new FileStream(filename, FileMode.Create)) { Byte[] bytes = Encoding.UTF8.GetBytes(filecontent); fs.Write(bytes, 0, bytes.Length); } // 读取文件并打印出来 using (FileStream fs = new FileStream(filename, FileMode.Open)) { Byte[] bytes = new Byte[bufferlength]; UTF8Encoding encoding = new UTF8Encoding(true); while (fs.Read(bytes, 0, bytes.Length) > 0) { Console.WriteLine(encoding.GetString(bytes)); } } // 循环分批读取打印 //using (FileStream fs = new FileStream(filename, FileMode.Open, FileAccess.Read)) //{ // Byte[] bytes = new Byte[bufferlength]; // int bytesRead; // do // { // bytesRead = fs.Read(bytes, 0, bufferlength); // Console.WriteLine(Encoding.UTF8.GetString(bytes, 0, bytesRead)); // } while (bytesRead > 0); //} } catch (IOException ex) { Console.WriteLine(ex.Message); } Console.ReadKey(); } // 01.取得测试数据 static string GetTestString() { StringBuilder builder = new StringBuilder(); for (int i = 0; i < 10; i++) { builder.Append("我是测试数据\\r\\n"); builder.Append("我是长江" + (i + 1) + "号\\r\\n"); } return builder.ToString(); } }
上述代码的执行结果如下图所示:

在实际开发中经常会遇到需要传递一个比较大的文件,或者事先无法得知文件大小,因此也就不能创建一个尺寸正好合适的Byte[]数组,此时只能分批读取和写入,每次只读取部分字节,直到文件尾。例如我们需要复制G盘中一个大小为4.4MB的mp3文件到C盘中去,假设我们对大小超过2MB的文件都采用分批读取写入机制,可以通过如下代码实现:
class Program { private const int BufferSize = 10240; // 10 KB public static void Main(string[] args) { string fileName = @"G:\\My Musics\\BlueMoves.mp3"; // Source 4.4 MB string copyName = @"C:\\BlueMoves-Copy.mp3"; // Destination 4.4 MB using (Stream source = new FileStream(fileName, FileMode.Open, FileAccess.Read)) { using (Stream target = new FileStream(copyName, FileMode.Create, FileAccess.Write)) { byte[] buffer = new byte[BufferSize]; int bytesRead; do { // 从源文件中读取指定的10K长度到缓存中 bytesRead = source.Read(buffer, 0, BufferSize); // 从缓存中写入已读取到的长度到目标文件中 target.Write(buffer, 0, bytesRead); } while (bytesRead > 0); } } Console.ReadKey(); } }
上述代码中,设置了缓存buffer大小为10K,即每次只读取10K的内容长度到buffer中,通过循环的多次读写和写入完成整个复制操作。
3.2 如何使用压缩流?
NET中提供了对于压缩和解压的支持:GZipStream类型和DeflateStream类型,位于System.IO.Compression命名空间下且都继承于Stream类型
对文件压缩的本质其实是针对字节的操作,也属于一种流操作。
下面的代码展示了GZipStream的使用方法,DeflateStream和GZipStream的使用方法几乎完全一致:
class Program { // 缓存数组的长度 private const int bufferSize = 1024; static void Main(string[] args) { string test = GetTestString(); byte[] original = Encoding.UTF8.GetBytes(test); byte[] compressed = null; byte[] decompressed = null; Console.WriteLine("数据的原始长度是:{0}", original.LongLength); // 1.进行压缩 // 1.1 压缩进入内存流 using (MemoryStream target = new MemoryStream()) { using (GZipStream gzs = new GZipStream(target, CompressionMode.Compress, true)) { // 1.2 将数据写入压缩流 WriteAllBytes(gzs, original, bufferSize); } compressed = target.ToArray(); Console.WriteLine("压缩后的数据长度:{0}", compressed.LongLength); } // 2.进行解压缩 // 2.1 将解压后的数据写入内存流 using (MemoryStream source = new MemoryStream(compressed)) { using (GZipStream gzs = new GZipStream(source, CompressionMode.Decompress, true)) { // 2.2 从压缩流中读取所有数据 decompressed = ReadAllBytes(gzs, bufferSize); } Console.WriteLine("解压后的数据长度:{0}", decompressed.LongLength); Console.WriteLine("解压前后是否相等:{0}", test.Equals(Encoding.UTF8.GetString(decompressed))); } Console.ReadKey(); } // 01.取得测试数据 static string GetTestString() { StringBuilder builder = new StringBuilder(); for (int i = 0; i < 10; i++) { builder.Append("我是测试数据\\r\\n"); builder.Append("我是长江" + (i + 1) + "号\\r\\n"); } return builder.ToString(); } // 02.从一个流总读取所有字节 static Byte[] ReadAllBytes(Stream stream, int bufferlength) { Byte[] buffer = new Byte[bufferlength]; List<Byte> result = new List<Byte>(); int read; while ((read = stream.Read(buffer, 0, bufferlength)) > 0) { if (read < bufferlength) { Byte[] temp = new Byte[read]; Array.Copy(buffer, temp, read); result.AddRange(temp); } else { result.AddRange(buffer); } } return result.ToArray(); } // 03.把字节写入一个流中 static void WriteAllBytes(Stream stream, Byte[] data, int bufferlength) { Byte[] buffer = new Byte[bufferlength]; for (long i = 0; i < data.LongLength; i += bufferlength) { int length = bufferlength; if (i + bufferlength > data.LongLength) { length = (int)(data.LongLength - i); } Array.Copy(data, i, buffer, 0, length); stream.Write(buffer, 0, length); } } }
上述代码的运行结果如下图所示:

需要注意的是:使用 GZipStream 类压缩大于 4 GB 的文件时将会引发异常。
通过GZipStream的构造方法可以看出,它是一个典型的Decorator装饰者模式的应用,所谓装饰者模式,就是动态地给一个对象添加一些额外的职责。对于增加新功能这个方面,装饰者模式比新增一个子类更为灵活。就拿上面代码中的GZipStream来说,它扩展的是MemoryStream,为Write方法增加了压缩的功能,从而实现了压缩的应用。

扩展:许多资料表明.NET提供的GZipStream和DeflateStream类型的压缩算法并不出色,也不能调整压缩率,有些第三方的组件例如SharpZipLib实现了更高效的压缩和解压算法,我们可以在nuget中为项目添加该组件。
3.3 Serializable特性有什么作用?
通过上面的流类型可以方便地操作各种字节流,但是如何把现有的实例对象转换为方便传输的字节流,就需要使用序列化技术。对象实例的序列化,是指将实例对象转换为可方便存储、传输和交互的流。在.NET中,通过Serializable特性提供了序列化对象实例的机制,当一个类型被申明为Serializable后,它就能被诸如BinaryFormatter等实现了IFormatter接口的类型进行序列化和反序列化。
[Serializable] public class Person { ...... }
但是,在实际开发中我们会遇到对于一些特殊的不希望被序列化的成员,这时我们可以为某些成员添加NonSerialized特性。例如,有如下代码所示的一个Person类,其中number代表学号,name代表姓名,我们不希望name被序列化,于是可以为name添加NonSerialized特性:
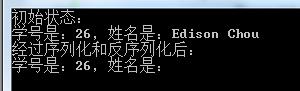
class Program { static void Main(string[] args) { Person obj = new Person(26, "Edison Chou"); Console.WriteLine("初始状态:"); Console.WriteLine(obj); // 序列化对象 byte[] data = Serialize(obj); // 反序列化对象 Person newObj = DeSerialize(data); Console.WriteLine("经过序列化和反序列化后:"); Console.WriteLine(newObj); Console.ReadKey(); } // 序列化对象 static byte[] Serialize(Person p) { // 使用二进制序列化 IFormatter formatter = new BinaryFormatter(); using (MemoryStream ms = new MemoryStream()) { formatter.Serialize(ms, p); return ms.ToArray(); } } // 反序列化对象 static Person DeSerialize(byte[] data) { // 使用二进制反序列化 IFormatter formatter = new BinaryFormatter(); using (MemoryStream ms = new MemoryStream(data)) { Person p = formatter.Deserialize(ms) as Person; return p; } } }
上述代码的运行结果如下图所示:
注意:当一个基类使用了Serializable特性后,并不意味着其所有子类都能被序列化。事实上,我们必须为每个子类都添加Serializable特性才能保证其能被正确地序列化。
3.4 .NET提供了哪几种可进行序列化操作的类型?
我们已经理解了如何把一个类型声明为可序列化的类型,但是万里长征只走了第一步,具体完成序列化和反序列化的操作还需要一个执行这些操作的类型。为了序列化具体实例到某种专用的格式,.NET中提供了三种对象序列格式化类型:BinaryFormatter、SoapFormatter和XmlSerializer。
(1)BinaryFormatter
顾名思义,BinaryFormatter可用于将可序列化的对象序列化成二进制的字节流,在前面Serializable特性的代码示例中已经展示过,这里不再重复展示。
(2)SoapFormatter
SoapFormatter致力于将可序列化的类型序列化成符合SOAP规范的XML文档以供使用。在.NET中,要使用SoapFormatter需要先添加对于SoapFormatter的引用:
using System.Runtime.Serialization.Formatters.Soap;
Tips:SOAP是一种位于应用层的网络协议,它基于XML,并且是Web Service的基本协议。
(3)XmlSerializer
XmlSerializer并不仅仅针对那些标记了Serializable特性的类型,更为需要注意的是,Serializable和NonSerialized特性在XmlSerializer类型对象的操作中完全不起作用,取而代之的是XmlIgnore属性。XmlSerializer可以对没有标记Serializable特性的类型对象进行序列化,但是它仍然有一定的限制:
① 使用XmlSerializer序列化的对象必须显示地拥有一个无参数的公共构造方法;
因此,我们需要修改前面代码示例中的Person类,添加一个无参数的公共构造方法:
[Serializable] public class Person { ...... public Person() { } ...... }
② XmlSerializer只能序列化公共成员变量;
因此,Person类中的私有成员_number便不能被XmlSerializer进行序列化:
[Serializable] public class Person { // 私有成员无法被XmlSerializer序列化 private int _number; }
(4)综合演示SoapFormatter和XmlSerializer的使用方法:
①重新改写Person类
[Serializable] public class Person { // 私有成员无法被XmlSerializer序列化 private int _number; // 使用NonSerialized特性标记此成员不可被BinaryFormatter和SoapFormatter序列化 [NonSerialized] public string _name; // 使用XmlIgnore特性标记此成员不可悲XmlSerializer序列化 [XmlIgnore] public string _univeristy; public Person() { } public Person(int i, string s, string u) { this._number = i; this._name = s; this._univeristy = u; } public override string ToString() { string result = string.Format("学号是:{0},姓名是:{1},大学是:{2}", _number, _name, _univeristy); return result; } }
②新增SoapFormatter和XmlSerializer的序列化和反序列化方法
#region 01.SoapFormatter // 序列化对象-SoapFormatter static byte[] SoapFormatterSerialize(Person p) { // 使用Soap协议序列化 IFormatter formatter = new SoapFormatter(); using (MemoryStream ms = new MemoryStream()) { formatter.Serialize(ms, p); return ms.ToArray(); } } // 反序列化对象-SoapFormatter static Person SoapFormatterDeSerialize(byte[] data) { // 使用Soap协议反序列化 IFormatter formatter = new SoapFormatter(); using (MemoryStream ms = new MemoryStream(data)) { Person p = formatter.Deserialize(ms) as Person; return p; } } #endregion #region 02.XmlSerializer // 序列化对象-XmlSerializer static byte[] XmlSerializerSerialize(Person p) { // 使用XML规范序列化 XmlSerializer serializer = new XmlSerializer(typeof(Person)); using (MemoryStream ms = new MemoryStream()) { serializer.Serialize(ms, p); return ms.ToArray(); } } // 反序列化对象-XmlSerializer static Person XmlSerializerDeSerialize(byte[] data) { // 使用XML规范反序列化 XmlSerializer serializer = new XmlSerializer(typeof(Person)); using (MemoryStream ms = new MemoryStream(data)) { Person p = serializer.Deserialize(ms) as Person; return p; } } #endregion
③改写Main方法进行测试
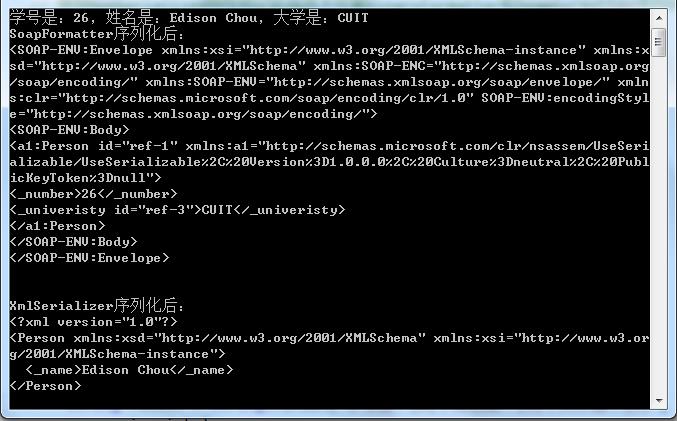
static void Main(string[] args) { Person obj = new Person(26, "Edison Chou", "CUIT"); Console.WriteLine("原始对象为:"); Console.WriteLine(obj.ToString()); // 使用SoapFormatter序列化对象 byte[] data1 = SoapFormatterSerialize(obj); Console.WriteLine("SoapFormatter序列化后:"); Console.WriteLine(Encoding.UTF8.GetString(data1)); Console.WriteLine(); // 使用XmlSerializer序列化对象 byte[] data2 = XmlSerializerSerialize(obj); Console.WriteLine("XmlSerializer序列化后:"); Console.WriteLine(Encoding.UTF8.GetString(data2)); Console.ReadKey(); }
示例运行结果如下图所示:
3.5 如何自定义序列化和反序列化的过程?
对于某些类型,序列化和反序列化往往有一些特殊的操作或逻辑检查需求,这时就需要我们能够主动地控制序列化和反序列化的过程。.NET中提供的Serializable特性帮助我们非常快捷地申明了一个可序列化的类型(因此也就缺乏了灵活性),但很多时候由于业务逻辑的要求,我们需要主动地控制序列化和反序列化的过程。因此,.NET提供了ISerializable接口来满足自定义序列化需求。
下面的代码展示了自定义序列化和反序列化的类型模板:
[Serializable] public class MyObject : ISerializable { protected MyObject(SerializationInfo info, StreamingContext context) { // 在此构造方法中实现反序列化 } public virtual void GetObjectData(SerializationInfo info, StreamingContext context) { // 在此方法中实现序列化 } }
如上代码所示,GetObjectData和特殊构造方法都接收两个参数:SerializationInfo 类型参数的作用类似于一个哈希表,通过key/value对来存储整个对象的内容,而StreamingContext 类型参数则包含了流的当前状态,我们可以根据此参数来判断是否需要序列化和反序列化类型独享。
如果基类实现了ISerializable接口,则派生类需要针对自己的成员实现反序列化构造方法,并且重写基类中的GetObjectData方法。
下面通过一个具体的代码示例,来了解如何在.NET程序中自定义序列化和反序列化的过程:
①首先我们需要一个需要被序列化和反序列化的类型,该类型有可能被其他类型继承
[Serializable] public class MyObject : ISerializable { private int _number; [NonSerialized] private string _name; public MyObject(int num, string name) { this._number = num; this._name = name; } public override string ToString() { return string.Format("整数是:{0}\\r\\n字符串是:{1}", _number, _name); } // 实现自定义的序列化 protected MyObject(SerializationInfo info, StreamingContext context) { // 从SerializationInfo对象(类似于一个HashTable)中读取内容 this._number = info.GetInt32("MyObjectInt"); this._name = info.GetString("MyObjectString"); } // 实现自定义的反序列化 public void GetObjectData(SerializationInfo info, StreamingContext context) { // 将成员对象写入SerializationInfo对象中 info.AddValue("MyObjectInt", this._number); info.AddValue("MyObjectString", this._name); } }
②随后编写一个继承自MyObject的子类,并添加一个私有的成员变量。需要注意的是:子类必须负责序列化和反序列化自己添加的成员变量。
[Serializable] public class MyObjectSon : MyObject { // 自己添加的成员 private string _sonName; public MyObjectSon(int num, string name) : base(num, name) { this._sonName = name; } public override string ToString() { return string.Format("{0}\\r\\n之类字符串是:{1}", base.ToString(), this._sonName); } // 实现自定义反序列化,只负责子类添加的成员 protected MyObjectSon(SerializationInfo info, StreamingContext context) : base(info, context) { this._sonName = info.GetString("MyObjectSonString"); } // 实现自定义序列化,只负责子类添加的成员 public override void GetObjectData(SerializationInfo info, StreamingContext context) { base.GetObjectData(info, context); info.AddValue("MyObjectSonString", this._sonName); } }
③最后编写Main方法,测试自定义的序列化和反序列化
class Program { static void Main(string[] args) { MyObjectSon obj = new MyObjectSon(10086, "Edison Chou"); Console.WriteLine("初始对象为:"); Console.WriteLine(obj.ToString()); // 序列化 byte[] data = Serialize(obj); Console.WriteLine("经过序列化与反序列化之后:"); Console.WriteLine(DeSerialize(data)); Console.ReadKey(); } // 序列化对象-BinaryFormatter static byte[] Serialize(MyObject p) { // 使用二进制序列化 IFormatter formatter = new BinaryFormatter(); using (MemoryStream ms = new MemoryStream()) { formatter.Serialize(ms, p); return ms.ToArray(); } } // 反序列化对象-BinaryFormatter static MyObject DeSerialize(byte[] data) { // 使用二进制反序列化 IFormatter formatter = new BinaryFormatter(); using (MemoryStream ms = new MemoryStream(data)) { MyObject p = formatter.Deserialize(ms) as MyObject; return p; } } }
上述代码的运行结果如下图所示:
