3D目标检测&6D姿态估计之SSD-6D算法--by leona
Posted bupt213
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了3D目标检测&6D姿态估计之SSD-6D算法--by leona相关的知识,希望对你有一定的参考价值。
最近的研究主要以6D检测为主,本篇介绍基于2D检测器SSD的3D检测器SSD-6D。
1)论文链接:https://arxiv.org/pdf/1711.10006.pdf
训练部分代码链接:https://github.com/wadimkehl/ssd-6d
2)介绍:
许多3D检测器都是基于视角的(view based),生成一系列离散的目标视角用于后续视频序列的特征计算。在测试过程中,从不同的离散视角对场景进行采样,然后计算特征,并与目标数据库匹配来建立训练视角和场景位置的对应。此处的特征可指编码后的图像特征(颜色梯度,深度值,方向),或者学习得到的结果。但无论是哪种情况,检测和姿态估计的精度都受一下三个方面影响: 1. 在对应的视角和尺度上,6D姿态空间的收敛性;2. 特征区别目标和视角的辨别能力;3. 在场景混乱,光照变化,出现遮挡时的鲁棒性。
YOLO和SSD等2D检测器的思想:改变采样策略,使场景采样不再是得到连续输出的离散的输入点。输入空间在整个图片上是稠密的,输出空间被离散为不同形状和尺寸的边界框。
本文贡献:1. 使用动态3D模型信息的训练阶段; 2. 分解模型姿态空间, 便于对称的训练和处理; 3. 扩展SSD, 产生2D检测并推断合适的6D位姿。(当正确使用颜色信息的时候,过度依赖3D实例检测的深度信息使不合理的)。
3)相关工作:
对于所有的3D检测,场景采样都至关重要。如果太粗糙,小尺寸的目标容易被漏检;细粒度采样会增加计算量且常常导致更多的假阳性检测。
其他基于SSD的位姿估计算法:
- A. Mousavian, D. Anguelov, J. Flynn, and J. Kosecka. 3D Bounding Box Estimation Using Deep Learning and Geometry. arXiv:1612.00496, 2016. (推断3D边界框,回归3D框的角和方向角,城市交通)
- P. Poirson, P. Ammirato, C.-Y. Fu, W. Liu, J. Kosecka, and A. C. Berg. Fast Single Shot Detection and Pose Estimation. In 3DV, 2016. (引入额外的姿势组合,不仅表达类别,还有局部取向的概念)
这两篇都是使用真实图片训练的,本文使用合成模型训练,并包围所有的6D姿态空间。
4)本文方法:
- 网络结构:
Base network:预训练的InceptionV4
Input:RGB image 299*299,计算得到多尺度特征图
在最后一个池化层前分支,加入一个Inception-A模块,得到71*71*384的特征图;在Inception-A后继续分支得到35*35*384,加入Inception-B;Inception-B后得到17*17*1024;Inception-C后得到9*9*1536。为了检测大尺寸的目标,又增加了两个模块:Reduction-B后面跟着两个Inception-C模块,得到5*5*1024的特征图;Reduction-B和Inception-C得到3*3*1024的特征图。得到的6个特征图都与预测卷积核卷积,从特征图的位置返回局部检测。
(ws; hs; cs)表示尺寸s的宽、高和通道数。对于每个尺寸,训练一个3*3*cs的核,此核提供每个特征图的位置和目标ID的得分、离散视角和平面内旋转。由于网格引入离散误差,在每个位置创建Bs个不同横纵比的边界框。
对于尺寸s,有(ws; hs;Bs*(C+V +R+4))个检测图,C: 目标类别数,V: 视角采样数,R: 平面内旋转采样数,最后网络会得到21222个不同尺寸和形状的可能的边界框。
网络在给出离散的视角的得分并进行分类上,比直接给出精确的平移和旋转数值表现的更好。因此对视角分类而非回归位姿。6D位姿在视角和平面内旋转的分解可简化问题。当一个新的视点呈现出一个新的视觉结构时,平面内旋转的视点是同一视点的非线性变换。

- 训练过程:
以来自MS COCO[20]的随机图像为背景,使用OpenGL命令将对象随机转换到场景中。对于每个处理过的实例,计算其每个边界框与mask的IoU,大于0.5的被选做此目标类别的正样本。此外,我们为所使用的变换确定其的最接近的采样离散视点和平面内旋转,并将其四个角值设置为最紧贴合掩模,设置后的四个角值作为回归目标。
与SSD相似,采取多种数据增强的方式,改变图片的亮度和对比度。但是不会旋转图像,因其会导致视角混淆进而得到错误的姿态检测。再反向传播的过程中,保证对每个图片,正负样本的比例为1:2(选取困难负样本)。
损失函数:Pos: 正样本集合,Neg: 负样本集合。对于分类概率,将正负样本框相加,此外,每个正样本为视角和平面内旋转还有四角的拟合误差贡献权值。对于分类损失Lclass, Lview, Linplane 采用标准softmax cross-entropy loss,四角的回归使用smooth L1-norm 损失。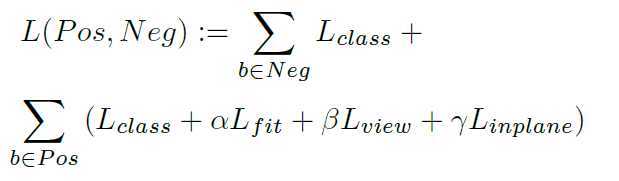
处理对称和视角模糊:本文方法需要消除视角的不确定性,因此需要特殊处理对称和半对称(可由平面反射构成)的目标,给定等距采样的球体,从其中选取视点,并抛弃可能会产生歧义的位置。对于对称对象,只沿着一条弧线采样视图,而对于半对称对象,完全省略了一个半球。这种方法很容易进行概括,以处理相互不可分辨的视图,尽管在实践中可能需要对特定对象进行手工注释。本质上,只是在测试过程中忽略了卷积分类器输出的某些视图,在训练中特别注意视点分配。
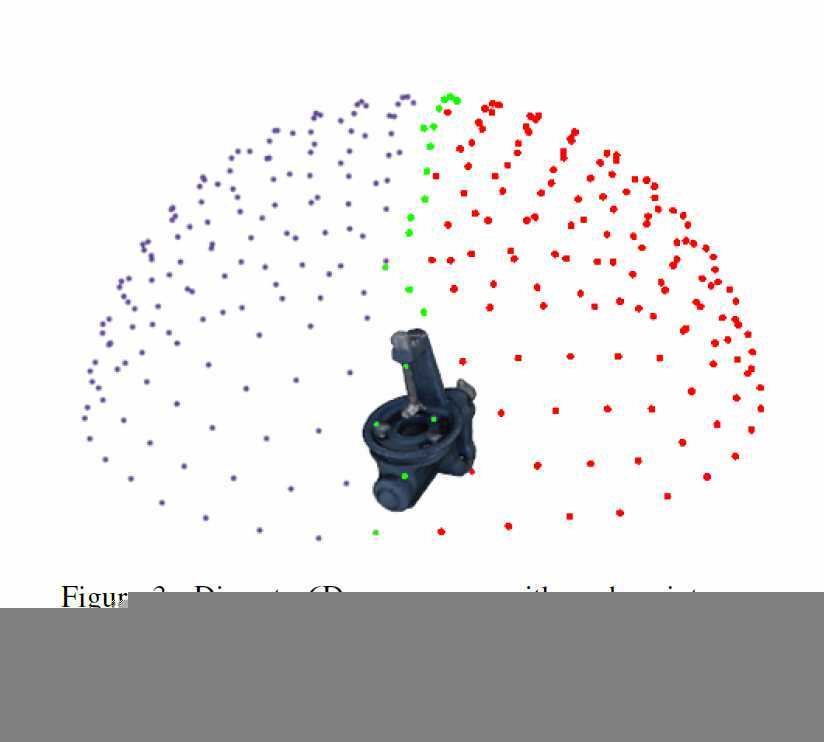
-
检测阶段:
前向传播得到所有高于某一阈值的所有检测结果,极大值抑制。这将得到紧密且精细的2D边界框,带有目标ID和所有视角和平面内旋转的得分。对于每个2D检测结果,分析最有可能的视角和平面内旋转,进而建立一系列6D假设,并在其中选择一个最优的。


从2D框建立6D假设:到目前为止,所有的计算都是在平面上的,通过视角ID和平面内旋转ID可以3D旋转,通过边界框可以推断3D平移。在离线阶段,以标准质心距离zr = 0.5m呈现所有离散视图和平面内旋转的可能组合,并计算它们的边界框。

姿态矫正和确认:对于RGB图像,将每个假设呈现到场景中,并提取一组稀疏的3D轮廓点。对于每一个3D点Xi,计算投影π(Xi) = xi, 然后用一条垂直于其方向的光线,找到最近的场景边缘yi,寻求三维模型的最佳对齐,使平均投影误差最小(使用IRLS方法来最小化,Geman-McLure权重来使其鲁棒)。
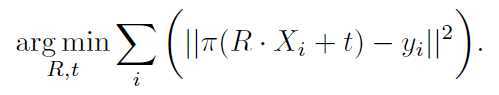
对于RGB-D图像,给出了当前的位姿,并用标准投影ICP求解,并用点对面公式。两种情况都会进行多轮对应来提高准确度,并使用多线程来加速。
这个过程为每个2D框都提供了多个调整过后的位姿,需要选择一个最好的。对于RGB图像,进行最终渲染,并通过绝对点积计算轮廓梯度和重叠场景梯度之间的方向平均偏差。在RGB-D数据可用的情况下,我们提出假设,估计相机空间法线来用绝对点积测量相似性。
- 实现细节:
网络参数和训练过程:
为了得到好的结果,需要合适的方法来对模型的视觉空间进行采样,采样过于稀疏,则要么错过了某些姿势的对象,要么建立的是次优的6D假设,而非常精细的采样可能导致难以训练。采用在单位圆上等距离采样642的视角,因为数据集只有上半球,所以最后只有337个可能的视角ID。对于平面内旋转,从-45°到45°每隔5°采样一次,共有19个bin。
使用ADAM和0:0003的恒定学习率对网络的最后一层和预测器内核进行训练,直到在合成验证集上收敛。
损失函数权重:α= 1:5, β= 2:5, γ= 1:5(实验经验值)。
单一目标:
2D检测结果如下:检测框与gt的IoU大于0.5即保留检测结果
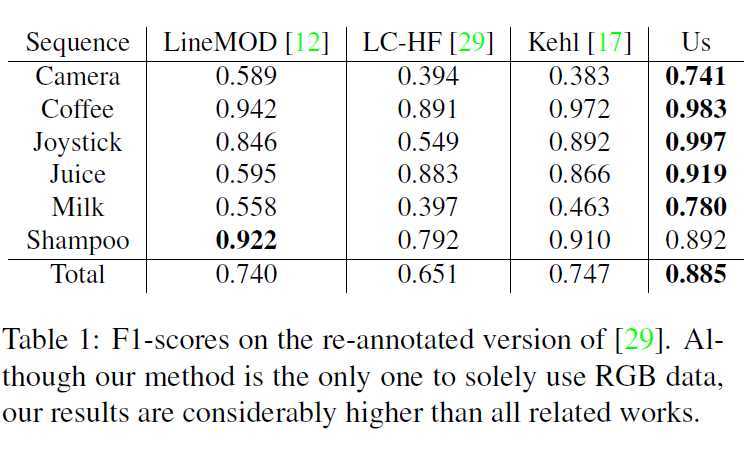
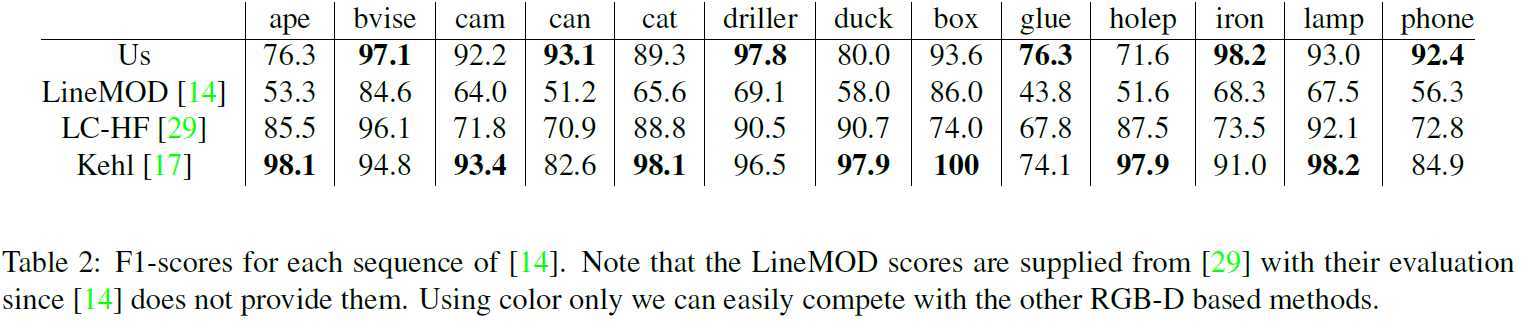
本文方法只依赖于颜色信息,因此需要CAD模型的合成效果图与其在场景中的外观之间具有一定的颜色相似性。
多目标
5)总结:
第一个提出了一个SSD方式检测器用于三维实例检测和全6D位姿估计,并且是在合成模型数据集上训练的。本文证明,基于颜色的探测器确实能够匹敌甚至超越目前最先进的利用RGB-D数据的方法,同时大约快一个数量级。进一步工作是提高CAD模型和场景中物体外观颜色差异的鲁棒性,还有各个损失项之间的平衡问题。
以上是关于3D目标检测&6D姿态估计之SSD-6D算法--by leona的主要内容,如果未能解决你的问题,请参考以下文章
ECCV2020优秀论文汇总|涉及点云处理3D检测识别三维重建立体视觉姿态估计深度估计SFM等方向