浙大&川大提出脉冲版ResNet:继承ResNet优势,实现当前最佳
Posted cx2016
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了浙大&川大提出脉冲版ResNet:继承ResNet优势,实现当前最佳相关的知识,希望对你有一定的参考价值。
浙大&川大提出脉冲版ResNet:继承ResNet优势,实现当前最佳
选自arXiv,作者:Yangfan Hu等,机器之心编译。
脉冲神经网络(SNN)具有生物学上的合理性,并且其计算潜能和传统神经网络相同,主要障碍在于训练难度。为解决这个问题,浙江大学和四川大学近日提出了脉冲版的深度残差网络 Spiking ResNet。为解决模型转换的问题,研究者提出了一种新机制,对连续值的激活函数进行标准化,以匹配脉冲神经网络中的脉冲激发频率,并设法减少离散化带来的误差。在多个基准数据集上的实验结果表明,该网络取得了脉冲神经网络的当前最佳性能。
引言
研究表明,脉冲神经网络 [21] 是一种弥合模型性能和计算开销之间鸿沟的解决方案。从理论上讲,脉冲神经网络可以像人工神经网络(ANN)一样逼近任意的函数。与传统的人工神经网络(ANN)不同,脉冲神经网络的神经元通过离散的事件(尖峰脉冲)而不是连续值的激活函数来相互通信。当事件到达时,这个系统会被异步更新,从而减少在每个时间步上所需要的运算步数。最新的研究进展表明,脉冲神经网络可以通过像 TrueNorth [24],SpiNNaker[9],以及 Rolls [26] 这样的神经形态的硬件来模拟,其能量消耗比当前的计算机硬件少几个数量级。此外,由于其基于事件的特性,脉冲神经网络天生就适合处理从具有低冗余、低延迟和高动态范围的基于 AER(地址时间表达)的传感器那里得到的输入数据,例如:动态视觉传感器(DVS)[19] 和听觉传感器(硅耳蜗)[20]。最近的一项研究 [28] 指出,脉冲立体神经网络的实现比基于经典绝对误差和(SAD)算法的微控制器的实现少消耗大约一个数量级的能量。
如今,脉冲神经网络所面临的一大挑战是如何找到一种有效的训练算法,克服脉冲的不连续性,并且获得和人工神经网络(ANN)相当的性能。转换方法,即通过训练一个传统的人工神经网络并建立一个转换算法,将权重映射到一个等价的脉冲神经网络中去,取得了迄今为止最好的性能。然而,对一个非常深的人工神经网络进行转换的难题在这之前从未被解决过。
在本文中,我们研究了基于残差神经网络 [11] 的深度脉冲神经网络的学习,这是一种非常前沿的卷积神经网络(CNN)架构,它在许多数据集上取得了非常好的性能,并且大大增加了网络的深度。在假设被转化的残差神经网络仍然具有它原本的优势的前提条件下,我们将一个预训练好的残差神经网络转换到它的脉冲版本。为了放缩连续值的激活函数使其适用于脉冲神经网络,我们开发了一种快捷正则化技术去标准化快捷连接并且在整个脉冲神经网络上保持了单元的最大脉冲激发频率,换言之,每一层上的神经元能够达到理论上最大的脉冲激发频率(每个时间步都会激活脉冲)。我们还提出了一种分层的误差补偿方法,通过减少每一层的采样误差来提高近似程度。
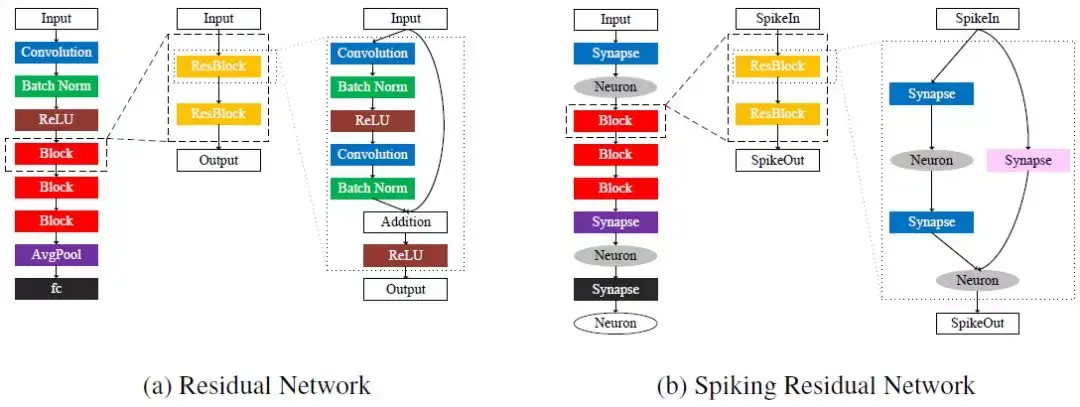 图 1: 脉冲残差网络架构示意图。
图 1: 脉冲残差网络架构示意图。
构建脉冲残差网络
起初,研究者们提出用残差神经网络解决深度神经网络退化的问题。由于意识到一个通过增加恒等识别层构建的深度网络不会比原来的浅层网络性能差,He 等人 [11] 用堆叠起来的非线形层去接近 F(x) := H(x) − x 的映射,其中 H(x) 是所需的潜在的映射。接着,原始的映射就变成了一个残差映射:H(x) = F(x) + x。它们假设残差映射更容易通过现有的优化方法来优化,并且通过实证证明了他们的假设。他们的实验表明,残差网络能够在非常大的深度下获得出色的性能。受到他们成果的启发,我们假设残差神经网络的脉冲版本继承了残差神经网络的优势,并且通过脉冲残差网络探索了学习非常深的脉冲神经网络的未知领域。
与其它的深度脉冲神经网络的对比
在表 1 中,我们总结了在 MNIST、CIFAR-10、CIFAR-100 数据集上得到的结果,并且与其它的深度脉冲神经网络的结果进行了比较。此处,我们定义深度时考虑了神经网络中所有可以学习权重的层,即卷基层和全连接层。在上述三个数据集上,我们的脉冲残差网络取得了比其它的深度脉冲神经网络更好的性能。在 MNIST 数据集上,我们实现了对 ResNet-8 的无损转换,并且得到了 99.59% 的准确率。我们没有在 MNIST 上用更深的网络进行实验,因为我们相信一个较浅的网络所做的工作已经足以学到这些手写数字背后的隐藏映射。在 CIFAR-10 数据集上,深度为 44 的脉冲残差网络取得了(脉冲神经网络中)最佳的性能 92.37%,它也是目前最深的前馈脉冲神经网络。原始的深度为 44 的残差神经网络的准确率是 92.85%,由转换导致的精度损失是 0.48%,这与其它的深度脉冲神经网络相比已经相当低了。在 CIFAR-100 数据集上,深度为 44 的脉冲残差网络也取得了很好的性能,准确率达到了 68.56%,转换过程导致准确率降低了 1.62%。
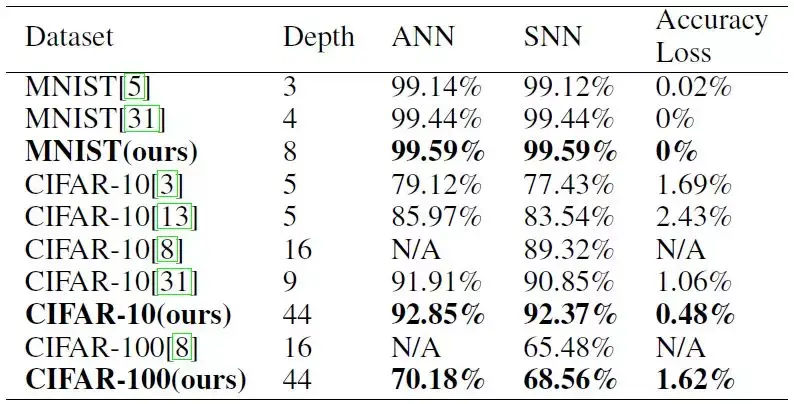 表 1:和其他的转化方法在 MNIST,CIFAR-10 和 CIFAR-100 数据集上的对比。
表 1:和其他的转化方法在 MNIST,CIFAR-10 和 CIFAR-100 数据集上的对比。
快捷正则化技术的实验
为了评估快捷正则化的有效性,我们在 CIFAR-10 数据集上训练了深度为 20、32、44、56、110 的残差神经网络,并且将它们转换为带有/不带有快捷正则化的脉冲残差网络。表 2 给出了原始的残差神经网络和相应的带有/不带有快捷正则化的脉冲残差网络所取得的识别准确率。在所有的不同深度的脉冲神经网络中,带有快捷正则化的网络都比不带快捷正则化的网络性能更好。随着深度从 20 增大到 32、44、56、110,他们相应的性能差距也从 2.34% 增大到 6.32%、7.42%、8.31%、8.59%。随着网络的加深,不带快捷正则化的脉冲神经网络比带有快捷正则化的脉冲神经网络受到的性能损失也随之增大。此外,带有快捷正则化的脉冲神经网络的性能在深度为 20、32、44、56 时十分稳定。在深度为 20 时,转换后的性能仅仅下降了 0.20%。
 表 2: 残差神经网络和脉冲残差网络(带有/不带有快捷正则化技术)在 CIFAR-10 数据集上的分类准确率。
表 2: 残差神经网络和脉冲残差网络(带有/不带有快捷正则化技术)在 CIFAR-10 数据集上的分类准确率。 图 4: 普通网络和残差网络在 CIFAR-10 数据集上转化效率的对比。
图 4: 普通网络和残差网络在 CIFAR-10 数据集上转化效率的对比。 图 5: 普通人工神经网络(ANN)和残差人工神经网络的对比。
图 5: 普通人工神经网络(ANN)和残差人工神经网络的对比。
论文:Spiking Deep Residual Network

论文链接:https://arxiv.org/abs/1805.01352
摘要:近一段时间以来,脉冲神经网络因其生物学上的合理性受到了广泛的关注。从理论上讲,脉冲神经网络至少与传统的人工神经网络(ANN)具有相同的计算能力,并且有潜力实现革命性的高效节能。然而,当前的状况是,训练一个非常深的 SNN 是一个巨大的挑战。在本文中,我们提出了一个高效的方法去构建一个脉冲版的深度残差网络(ResNet),它也代表了最先进的卷积神经网络(CNN)。我们将训练好的残差神经网络(ResNet)转换成一个脉冲神经元组成的网络,并将该网络命名为「脉冲残差网络(Spiking ResNet)」。为了解决这个转换的问题,我们提出了一种快捷的正则化机制,适当地对连续值的激活函数进行放缩(标准化),用来匹配脉冲神经网络中的脉冲激发频率。并且,我们还采用了分层的误差补偿方法来减少离散化带来的误差。我们在 MNIST、CIFAR-10 和 CIFAR-100 数据集上的实验结果表明,我们提出的脉冲残差网络取得了脉冲神经网络当前最佳性能。
-
默默然1 年前

-
万盛中路摇滚乐队1 年前

-
秦睿1 年前

-
少卿de少羽1 年前

-
ThomasLoveMandy回复少卿de少羽1 年前

-
xbigot回复ThomasLoveMandy5 个月前

-
秦睿1 年前
-
陆勐1 年前

-
退乎保平安1 年前

以上是关于浙大&川大提出脉冲版ResNet:继承ResNet优势,实现当前最佳的主要内容,如果未能解决你的问题,请参考以下文章