微软浙大等提出剪枝框架OTO,无需微调即可获得轻量级架构
Posted 人工智能博士
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了微软浙大等提出剪枝框架OTO,无需微调即可获得轻量级架构相关的知识,希望对你有一定的参考价值。
点上方人工智能算法与Python大数据获取更多干货
在右上方 ··· 设为星标 ★,第一时间获取资源
仅做学术分享,如有侵权,联系删除
转载于 :机器之心
来自微软、浙江大学等机构的研究者提出了一种 one-shot DNN 剪枝框架,无需微调即可从大型神经网络中得到轻量级架构,在保持模型高性能的同时还能显著降低所需算力。
大型神经网络学习速度很快,性能也往往优于其他较小的模型,但它们对资源的巨大需求限制了其在现实世界的部署。
剪枝是最常见的 DNN 压缩方法之一,旨在减少冗余结构,给 DNN 模型瘦身的同时提高其可解释性。然而,现有的剪枝方法通常是启发式的,而且只针对特定任务,还非常耗时,泛化能力也很差。
在一篇标题为《 Only Train Once: A One-Shot Neural Network Training And Pruning Framework》的论文中,来自微软、浙江大学等机构的研究者给出了针对上述问题的解决方案,提出了一种 one-shot DNN 剪枝框架。它可以让开发者无需微调就能从大型神经网络中得到轻量级架构。这种方法在保持模型高性能的同时显著降低了其所需的算力。

论文链接:https://arxiv.org/pdf/2107.07467.pdf
该研究的主要贡献概括如下:
One-Shot 训练和剪枝。研究者提出了一个名为 OTO(Only-Train-Once)的 one-shot 训练和剪枝框架。它可以将一个完整的神经网络压缩为轻量级网络,同时保持较高的性能。OTO 大大简化了现有剪枝方法复杂的多阶段训练 pipeline,适合各种架构和应用,因此具有通用性和有效性。
Zero-Invariant Group(ZIG)。研究者定义了神经网络的 zero-invariant group。如果一个框架被划分为 ZIG,它就允许我们修剪 zero group,同时不影响输出,这么做的结果是 one-shot 剪枝。这种特性适用于全连接层、残差块、多头注意力等多种流行结构。
新的结构化稀疏优化算法。研究者提出了 Half-Space Stochastic Projected Gradient(HSPG),这是一种解决引起正则化问题的结构化稀疏的方法。研究团队在实践中展示并分析了 HSPG 在促进 zero group 方面表现出的优势(相对于标准近端方法)。ZIG 和 HSPG 的设计是网络无关的,因此 OTO 对于很多应用来说都是通用的。
实验结果。利用本文中提出的方法,研究者可以从头、同时训练和压缩完整模型,无需为了提高推理速度和减少参数而进行微调。在 VGG for CIFAR10、ResNet50 for CIFAR10/ImageNet 和 Bert for SQuAD 等基准上,该方法都实现了 SOTA 结果。
方法及实验介绍

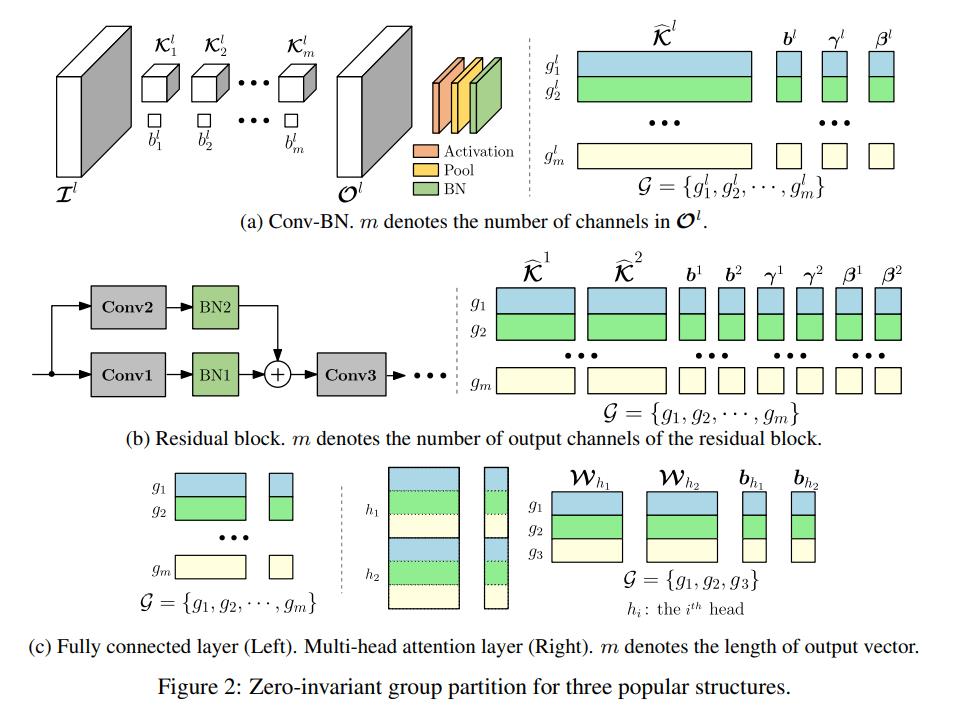
OTO 的结构非常简单。给定一个完整的模型,首先将可训练的参数划分为 ZIG 集,产生了一个结构化稀疏优化问题,通过一个新的随机优化器 (HSPG) 得出高度组稀疏的解。最后通过剪枝这些 zero group 得到一个压缩模型。
团队提出的 HSPG 随机优化算法是针对非光滑正则化问题而设计的,与经典算法相比,该算法在保持相似收敛性的同时,能够更有效地增强群体稀疏性搜索。
为了评估 OTO 在未经微调的 one-shot 训练和剪枝中的性能,研究者在 CNN 的基准压缩任务进行了实验,包括 CIFAR10 的 VGG16,CIFAR10 的 ResNet50 和 ImagetNet (ILSVRC2012),研究者比较了 OTO 与其当前各个 SOTA 算法在 Top-1 精度和 Top-5 精度、剩余的 FLOPs 和相应的 baseline 参数。

表 1:CIFAR10 中的 VGG16 及 VGG16-BN 模型表现。
在 CIFAR10 的 VGG16 实验中,OTO 将浮点数减少了 83.7%,将参数量减少了 97.5%,性能表现令人印象深刻。
在 CIFAR10 的 ResNet50 实验中,OTO 在没有量化的情况下优于 SOTA 神经网络压缩框架 AMC 和 ANNC,仅使用了 12.8% 的 FLOPs 和 8.8% 的参数。

表 2:CIFAR10 的 ResNet50 实验。
在 ResNet50 的 ImageNet 实验中,OTO 减少了 64.5% 的参数,实现了 65.5% 的浮点数减少,与 baseline 的 Top-1/5 精度相比只有 1.4%/0.8% 的差距 。
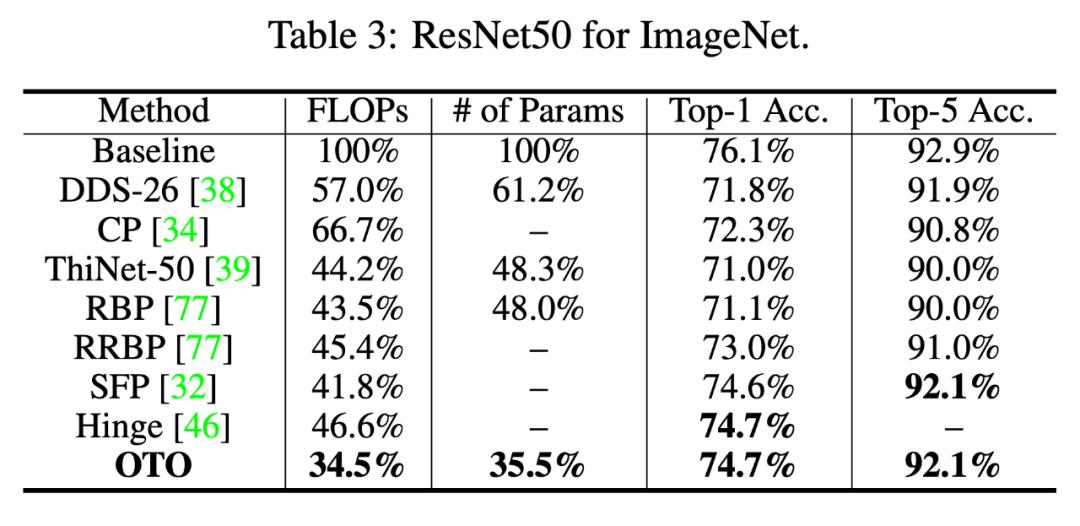
表 3:ResNet50 的 ImageNet。
总体而言,OTO 在所有的压缩基准实验中获得了 SOTA 结果,展现了模型的巨大潜力。研究者表示,未来的研究将关注合并量化和各种任务的应用上。
---------♥---------
声明:本内容来源网络,版权属于原作者
图片来源网络,不代表本公众号立场。如有侵权,联系删除
AI博士私人微信,还有少量空位


点个在看支持一下吧

以上是关于微软浙大等提出剪枝框架OTO,无需微调即可获得轻量级架构的主要内容,如果未能解决你的问题,请参考以下文章
Only Train Once:微软浙大等研究者提出剪枝框架OTO,无需微调即可获得轻量级架构...
Only Train Once:微软浙大等研究者提出剪枝框架OTO,无需微调即可获得轻量级架构...
如何无需在推荐的框架中编写测试用例即可获得 nodejs 应用程序的代码覆盖率?