搜索引擎学习初识Lucene
Posted riches
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了搜索引擎学习初识Lucene相关的知识,希望对你有一定的参考价值。
一、Lucene相关基础概念
定义:一个简易的工具包,实现文件搜索的功能,支持中文,关键字,多条件查询,凡是文件名或文件内容包含的都查出来。
数据分类:结构化数据(固定格式或有限长度的数据)和非结构化数据(不定长或无固定格式的数据)
PS:lucene是搜索引擎的底层实现,solr实际上是对lucene进行封装了的框架。
二、数据搜索
【1】结构化数据
由于数据有一定的规范和结构,通常使用sql语句来查询。
【2】非结构化查询
(1)顺序扫描法:一个文档一个文档的找,效率低,相当慢。
(2)全文检索:将非结构化数据中的一部分提取出来重新组织成为索引,这种先建索引,再对索引进行搜索的过程就叫做全文检索。(例:字典)
PS:虽然创建索引的过程非常耗时,但是索引一旦创建就可以多次使用,全文检索主要处理的就是查询,所以耗时间创建索引是非常值得的!
三、搜索流程
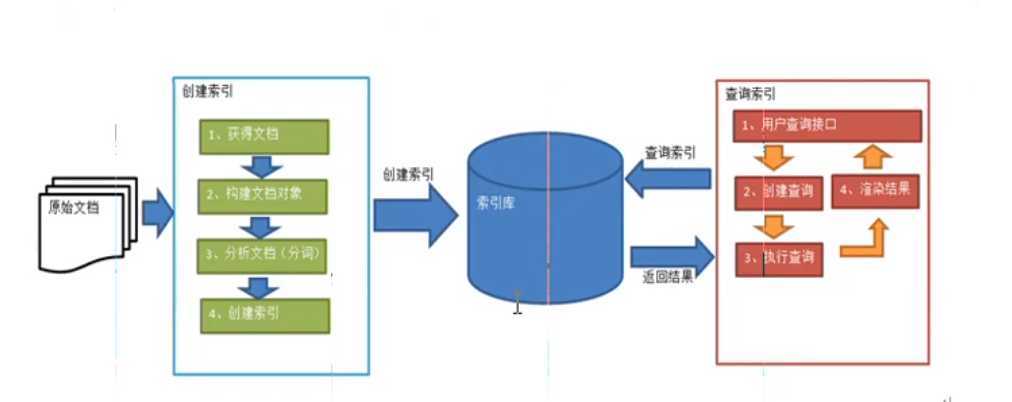
索引:1、使用流读取文档内容 2、构建文档内容的具体对象(bean) 3、对文档内容做分词 4、创建索引
索引库:里面既存放了索引,也存放了具体的文档。(可看做类似字典的结构:有目录,也有具体的内容)
用户查询接口:即关键词输入框,并不是指java实现类的对应接口。
创建索引
1.获得原始文档
原始文档:指的是要索引和搜索的内容,表现形式包括网站的网页,数据库的数据和磁盘上的文件等...
2.创建文档对象
lucene文档对象:包含了许许多多的域(field),每个文档有一个唯一编号,即文档id。
- 每个文档可以有多个域
- 不同文档可以有不同的域
- 同个文档可以有相同的域(域名和域值都相同)

3.分析文档
分词:将原文档提取单词进行分词,去除标点符号,去除停用词,将大写的文字全部转换为小写进行分词,最终生成语汇单元(一个一个的单词)。
term:分词后每个单词称为一个term,不同域中拆出来的相同单词是不同的term!
term的结构:类似于K-V的结构:term 域的名称(K) 域的值(V)
4.创建索引
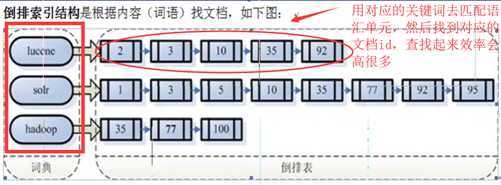
索引结构:倒排索引结构(反向索引结构),包括索引和文档两部分。

以上是关于搜索引擎学习初识Lucene的主要内容,如果未能解决你的问题,请参考以下文章