初识Solr,基于Lucene的全文搜索服务器
Posted 毛奇志
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了初识Solr,基于Lucene的全文搜索服务器相关的知识,希望对你有一定的参考价值。
文章目录
一、前言
本文分为三个部分,包括初识solr、单机版solr、集群版solr。
Solr是什么?
Solr 是Apache下的一个顶级开源项目,采用Java开发,它是基于Lucene的全文搜索服务器。Solr提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展,并对索引、搜索性能进行了优化。
Solr可以独立运行,运行在Jetty、Tomcat等这些Servlet容器中,Solr 索引的实现方法很简单,用 POST 方法向 Solr 服务器发送一个描述 Field 及其内容的 XML 文档,Solr根据xml文档添加、删除、更新索引 。Solr 搜索只需要发送 HTTP GET 请求,然后对 Solr 返回Xml、json等格式的查询结果进行解析,组织页面布局。Solr不提供构建UI的功能,Solr提供了一个管理界面,通过管理界面可以查询Solr的配置和运行情况。
二、初识Solr
2.1 solr和Lucene区别?
Lucene是一个基于Java的全文信息检索工具包,局限于Java调用,而Solr底层的核心技术是使用Lucene来实现的,是一个跨平台的搜索应用,而且提供了一个HTTP的管理页面(安装完只有我们可以在浏览器上操作这个界面)。
2.2(项目开发中)为什么要使用solr?
web项目开发中,经常会用到搜索功能,电商项目(如淘宝、京东)首页会有一个搜索框,用户在这个搜索框里输入关键字,回车或点击搜索按钮即可找到(满足关键字)的商品。
如何实现这个商品搜索功能呢?用sql语句查询持久层数据库。。。。。
如果这样做的话,对于数据小的系统还能凑合着用,对于淘宝、京东这样的大型系统,一个搜索就让这个系统崩溃,
所以,我们需要一个查找速度非常快、且与数据库数据一致的库,这就是索引库,而本文的主角,就是全文检索服务器——Solr.
2.3 初识Solr小结
到底什么是Solr? Solr是干什么用的?
这里给出最容易让初学者接受的回答,即在项目开发中,我们常常用到搜索功能,但是直接通过MVC三层结构,使用sql语句到持久层数据库中去查找,速度太慢,在数据量巨大的时候没有办法满足我们的需求,我们追求一种更加快捷的方式,全文搜索服务器,如Solr、ElasticSearch就满足了我们的需求(即快捷式搜索)。在使用过程中,按照业务需求将数据库中用于搜索的字段的数据导入到Solr索引库中,并在其中配置好中文分词器,就可以实现全文搜索了。还有,一般来说,这类全文搜索服务器(solr、elasticsearch)可以与我们部署web应用的应用服务器配置使用,部署的时候将其结合起来,这样全文索引库就融合到项目中。
小结:实际项目开发中,单机部署中,Solr是位于底层数据库和web应用的中间的一层;分布式部署中,也可以是web应用的一个模块,全文搜索模块。
三、单机版solr及Java开发实践
solr有window版本和linux版本,本文提供两个版本的完整演示
3.1 solr目录结构介绍
在使用solr的之前,我们先介绍其目录结构了,如图:
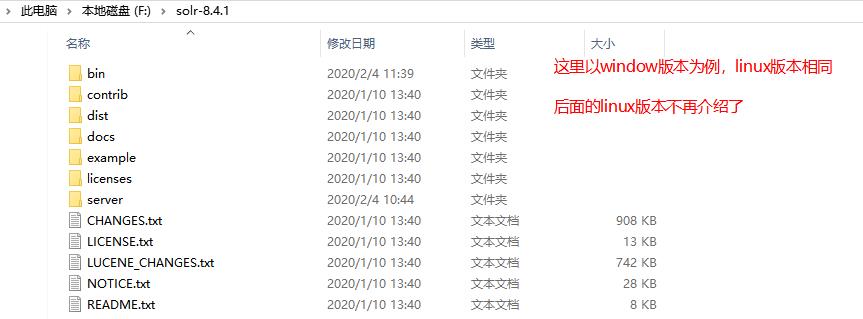
bin:solr的可运行脚本
contrib:solr的一些贡献软件/插件,用于增强solr的功能。
dist:该目录包含build过程中产生的war和jar文件,以及相关的依赖文件。
docs:solr的API文档
example:solr工程的例子目录:
example/solr:该目录是一个包含了默认配置信息的Solr的Core目录。
example/multicore:该目录包含了在Solr的multicore中设置的多个Core目录。
example/webapps:该目录中包括一个solr.war,该war可作为solr的运行实例工程。
licenses:solr相关的一些许可信息
server:Solr Core核心必要文件都存放在这里,分别如下:
server/contexts:启动Solr的Jetty网页的上下文配置。
server/etc:Jetty服务器配置文件,在这里可以把默认的8983端口改成其他的。
server/lib:Jetty服务器程序对应的可执行JAR包和响应的依赖包。
server/logs:默认情况下,日志将被输出到这个文件夹。
server/modules:http\\https\\server\\ssl等配置模块。
server/resources:存放着Log4j的配置文件。这里可以改变输出日志的级别和位置等设置。
server/scripts:Solr运行的必要脚本。
server/solr:运行Solr的配置文件都保存在这里。solr.xml文件,提供全方位的配置;zoo.cfg文件,使用SolrCloud的时候有用。子文件夹/configsets存放着Solr的示例配置文件。每创建一个核心Core都会在server目录下生成相应的core名称目录。
server/solr-webapp:Solr的平台管理界面的站点就存放在这里。
server/tmp:存放临时文件。
接下来,下载安装使用solr。
3.2 单机版solr安装使用(window版)
3.2.1 solr下载安装
注意:项目开发中,solr的出现一般都会与其他应用服务器(如tomcat jetty)一起出现,这就给初学者一个错误认知,好像solr只能与其他项目服务器结合在一起使用才行。其实,solr本身就是一个全文搜索服务器,它可以单独安装运行,不需要和其他服务器绑定。
到官网下载,有window版本和linux版本两种,我们这里选择下载window版本。
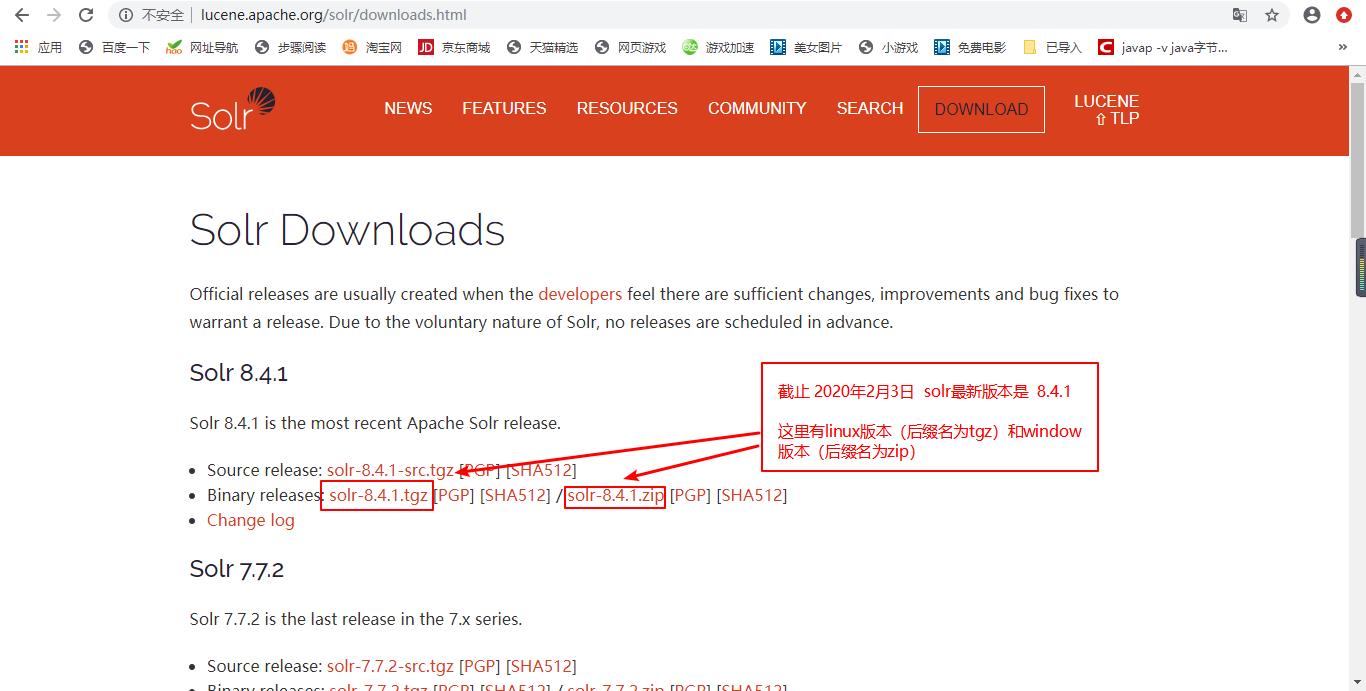
解压到任意目录,这里选择F:/solr-8.4.1,

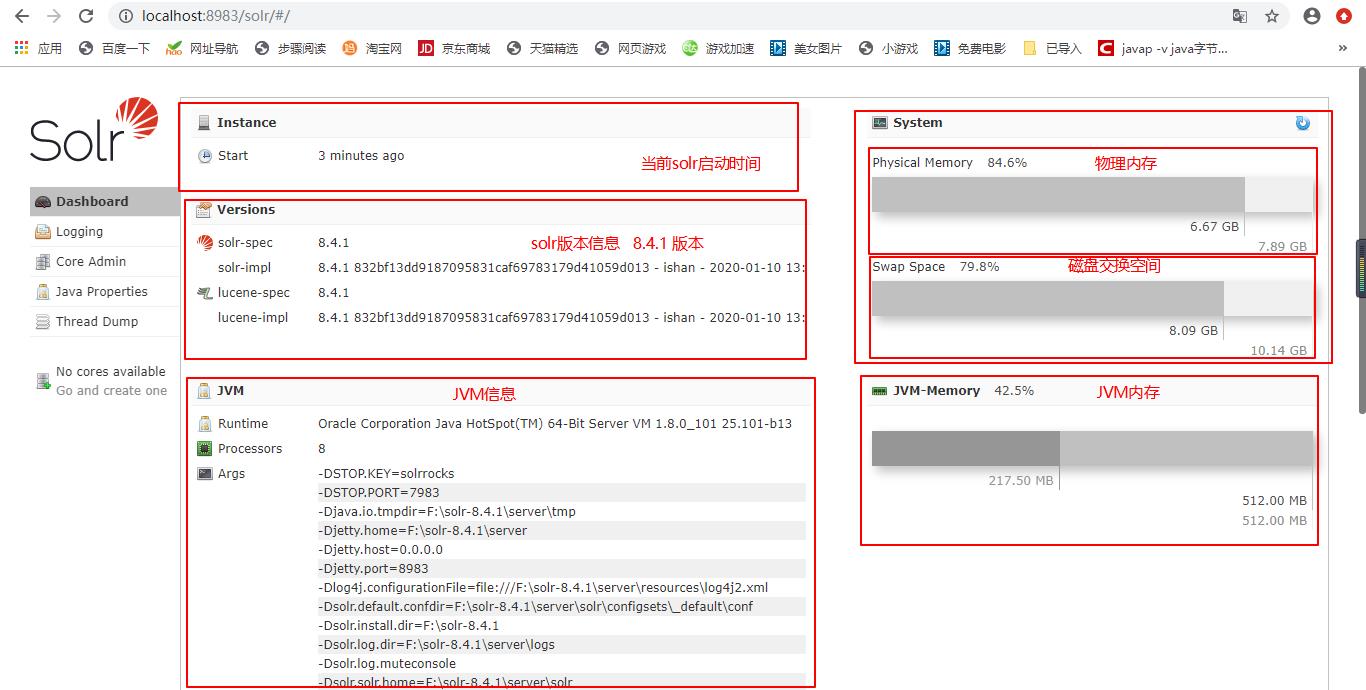
启动

在浏览器上看到这样的界面就是启动成功了
附:solr-8.4.1 和 solrhome的区别
我们经常会涉及到两个目录:solr和solrhome,不同在于:
solr-8.4.1 是solr解压目录,从官网下载下来解压而生成
solrhome 是solr文件目录, 是我们自己新建的solr
3.2.2 新建core
solr是一个全文搜索服务器,它的核心功能就是搜索,但是现在整个索引库没有数据,没有办法介绍solr的搜索功能,所以这里新建core,然后再插入数据。

3.2.3 插入数据并查询
(1)新建字段

编辑managed-schema,这里使用notepad++,读者可以自由使用其他软件编辑

注意,关于新建字段最常用的四个属性
name是字段名,不用解释;
type是字段类型,不用解释;
indexed是索引的字段是在搜索的时候可以用它来查询或排序,值为true表示可以用来查询,值为false表示不可以用来查询(这里id字段和city字段indexed属性值为true,desc字段indexed属性值为false);
stored是表示字段是否被存储,取决于你是否想在solr的查询结果中得到它,也就是说你是否想在查询结果中显示它(指这个字段,是否在查询结果中显示这个字段),值为true表示在查询结果中显示这个字段,值为false表示在查询结果中不显示这个字段,这里三个字段(id city desc)均为true,因为我们等一下查询的时候要看到所有字段值;
required是表示solr拒绝添加没有这个字段的任何文档Documents(这里的文档就是数据、记录的意思),值为true表示这个字段是必须的(类似数据库的非空,如果添加的文档字段为空,则添加不到索引上去,添加失败),值为false表示这个字段是是非必须的(类似数据库的可以为空,如果添加的文档字段为空,可以添加成功),默认这个值设置为false。这里三个字段(id city desc)均为true,表示添加任何一个记录(solr中叫文档documents)都必须同时指定三个字段的值,否则添加失败;
multiValued是表示该字段是否允许存储多个值,值为true表示此字段可以存储多个值,值为false表示此字段只能存储一个值。这里三个字段均为false,表示均仅能存放一个值。
新建完字段之后,现在插入数据。
(2)插入数据


3.2.4 ik分词器来助力
由于Solr是外国人开发的,对于中文的分词效果非常糟糕,不能很好的分词,就不能建立一个很好的索引库,也就不能提供好的搜索服务.于是我们中国人基于solr自己写了个分词器,终于能够愉快的使用solr了,本节这里给出介绍。
在solr的全文搜索功能中,默认只能进行
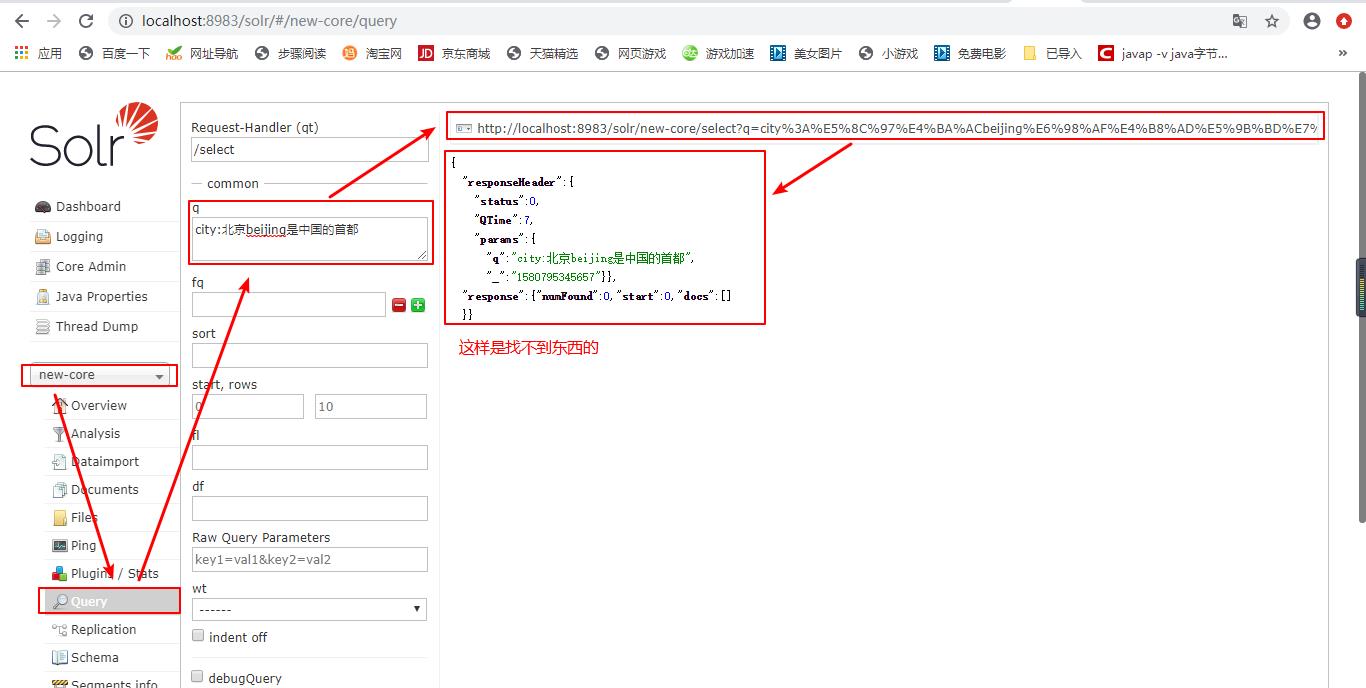
这里我们使用ik分词器,ik分词器可以将一句话(如“北京beijing是中国的首都”)分词,然后对每一个分词实现搜索。
步骤一:
这里笔者使用ik-analyzer-8.3.0.jar(应该可以是其他版本,即应该有对应版本范围,不一定非要用这个),将其解压

步骤二:
ik-analyzer-8.3.0.jar 放入“solr安装目录”\\server\\solr-webapp\\webapp\\WEB-INF\\lib,笔者这里是F:\\solr-8.4.1\\server\\solr-webapp\\webapp\\WEB-INF\\lib,如图:
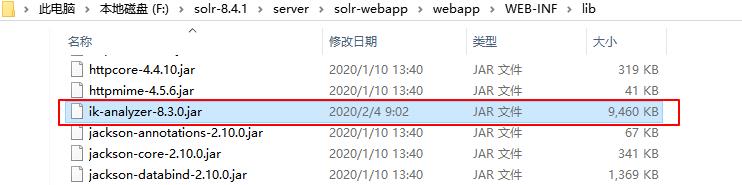
然后在WEB-INF文件夹下新建一个"classes"文件,从ik-analyzer-8.3.0.jar 中找到配置文件IKAnalyzer.cfg.xml中赋值到classes目录下。
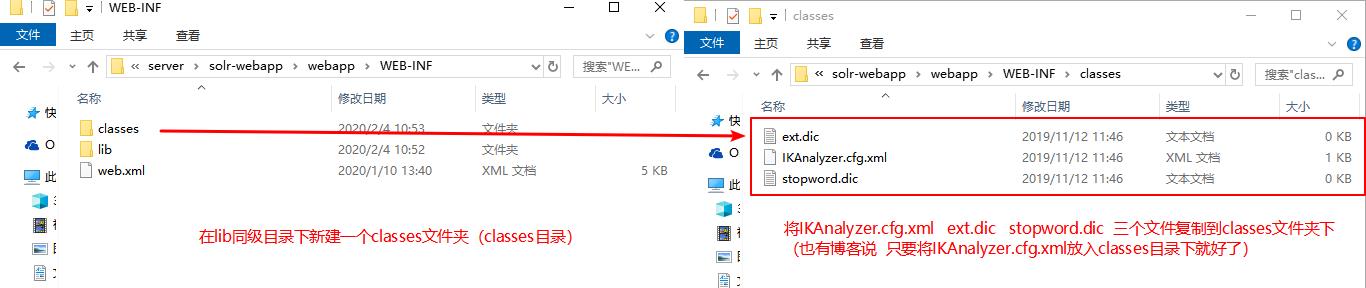
步骤三:
配置managed-schema中添加ik分词器的配置,并且把field city的类型改为ik_word这样搜索的时候才会应用分词。

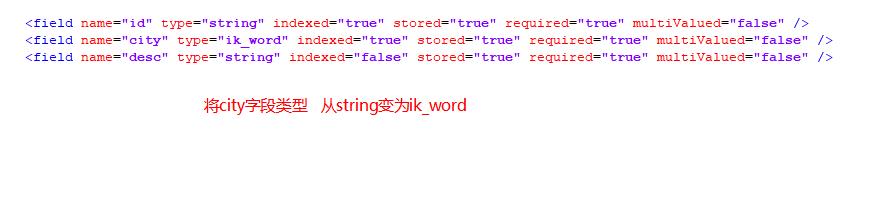
步骤四:
执行分词与查看分词效果
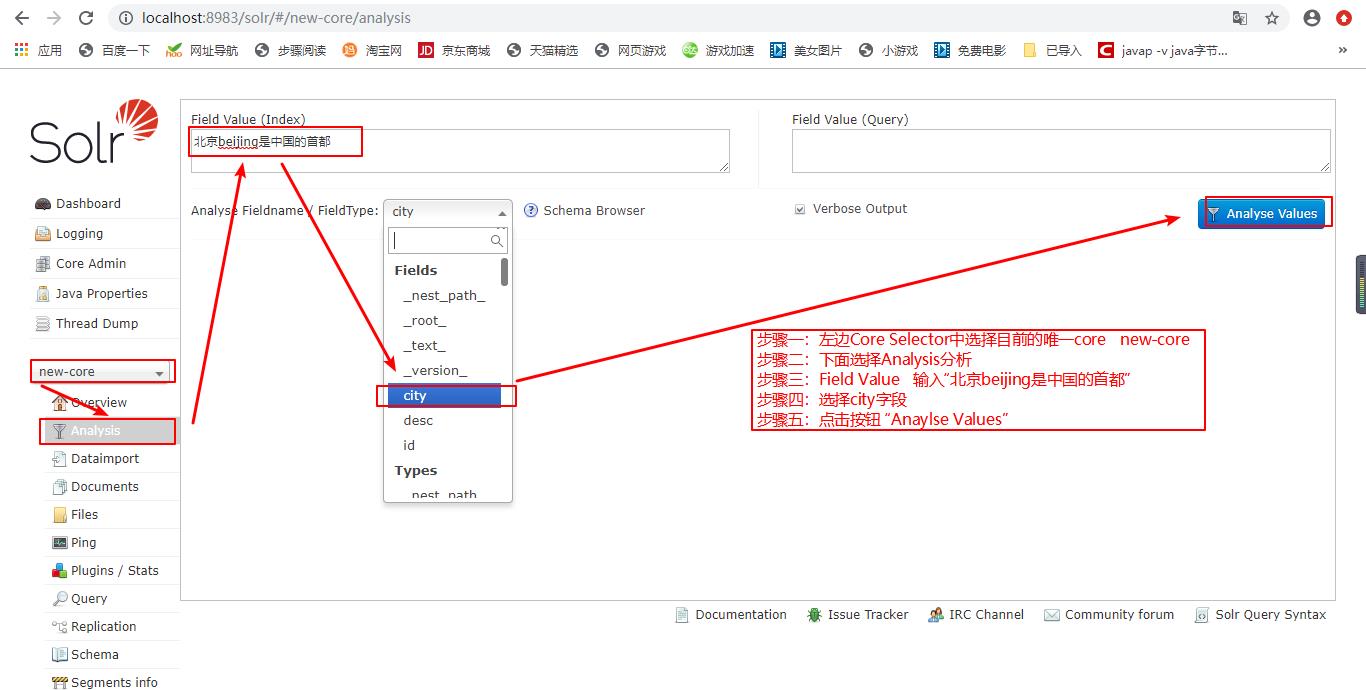
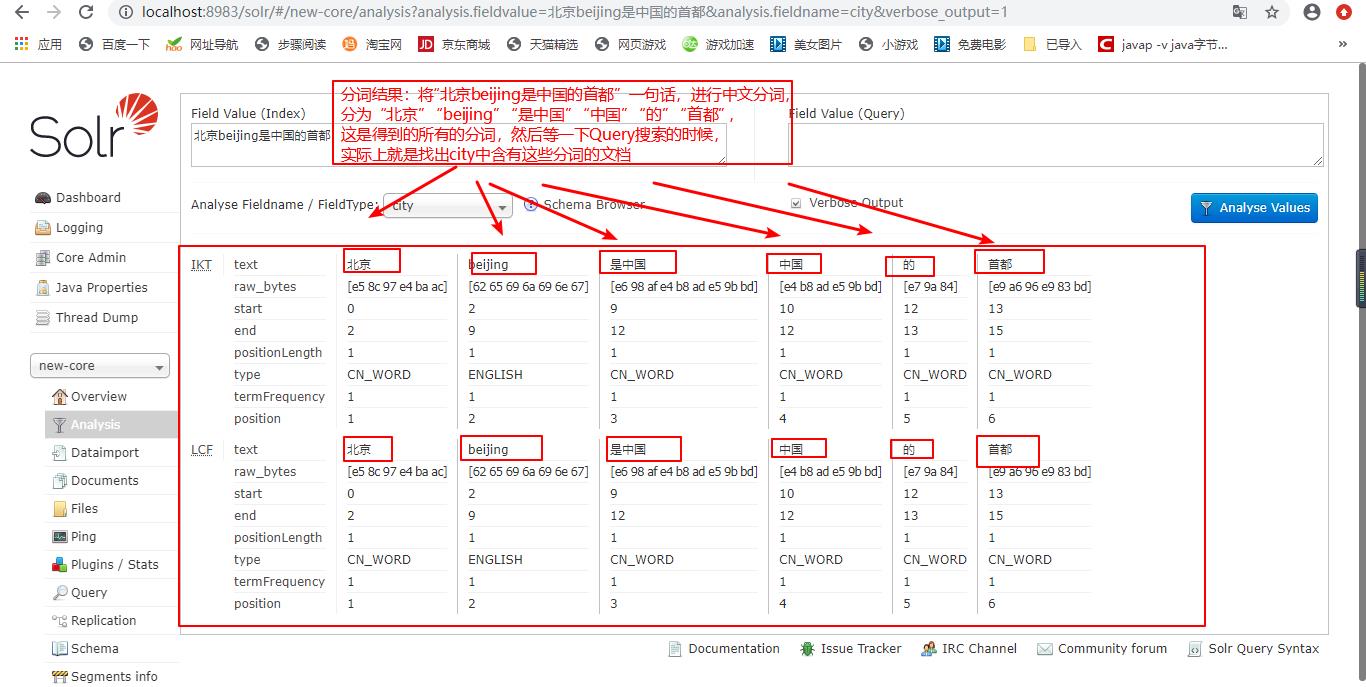
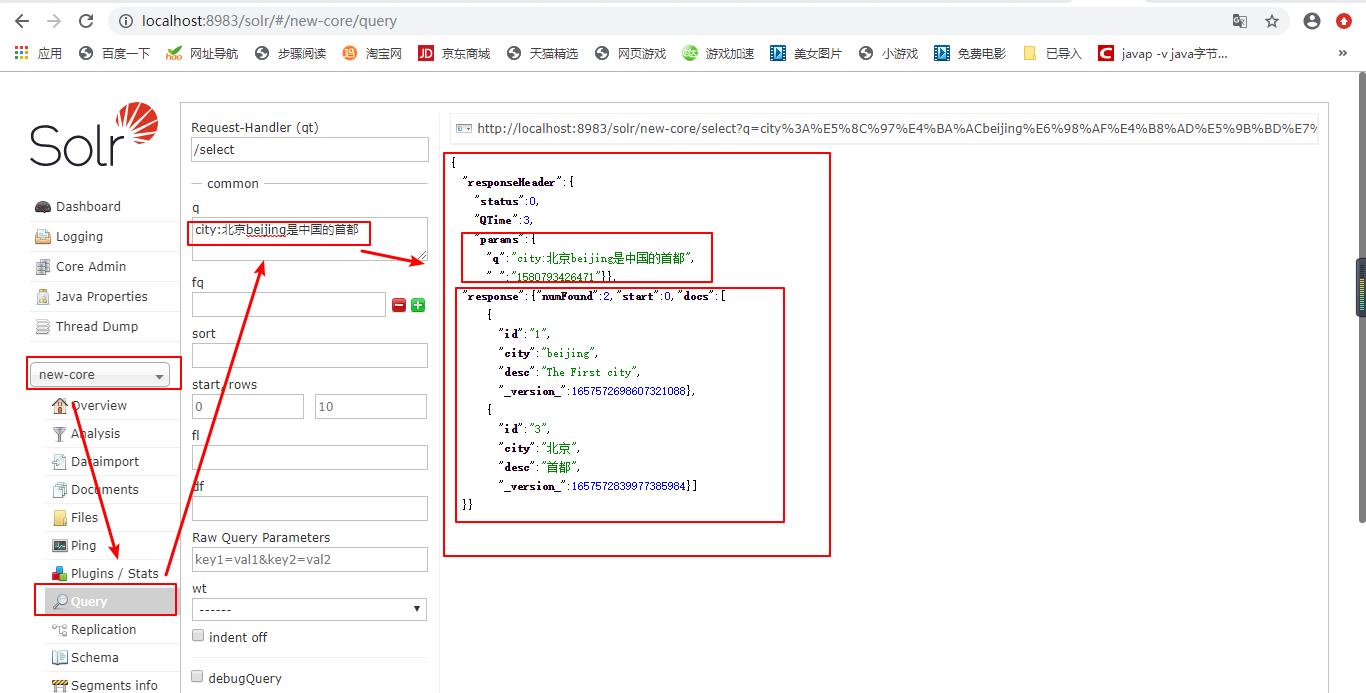
加入了ik分词器后在查询Query,就可以查询出来了:
3.3 单机版solr安装使用(linux版)
除了windows平台上可以使用solr,linux平台上也可以,实际上,linux上的Solr使用更加重要,因为我们部署web项目的时候,更多的是部署在linux上,安装步骤也很简单,下载、解压、启动即可,看到如下界面就是启动成功:

浏览器(看到下面这个界面,solr就安装好了)

其他相关的操作,如Query查询,中文分词等,和上面windows版本的solr都是一样的,这里略去。
四、集群版solr相关知识(仅了解即可)
当处理数据量大,并发量高的搜索的时候,一个solr服务是不可能满足要求的,所以此时需要SolrCloud来解决,solr本身是不支持分布式的,所以使用的是第三方依赖 zookeeper+solr来实现的。
zookeeper,直译为动物园管理员,也是apache下的一个顶级项目(官网域名 http://zookeeper.apache.org/),一般来说,需要用到集群的时候,需要zookeeper来管理,这里多个solr组成集群,需要zookeeper管理。
4.1 什么是集群版Solr?
集群版solr就是solrcloud,是伴随着分布式部署而出现的(主要是Javaweb项目分布式部署)。项目越来越大,部署到一个服务器上,该服务器由于物理性能无法完成大量并发,所以产生了分布式部署,将项目分成不同多个模块,每一个模块部署到一个服务器上,最后组成一个服务器集群,而对于Solr来说,也要承受这样的搜索并发,所以也要部署的多个服务器上,这就要使用到集群版solr(solrcloud)。
4.2 solrcloud结构
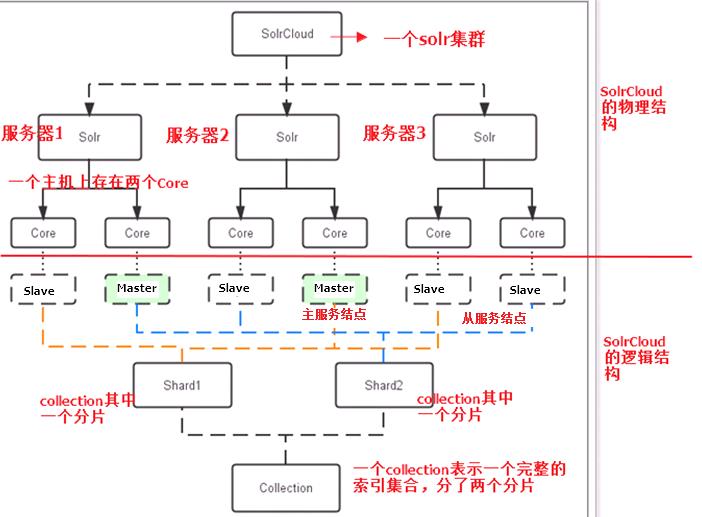
对于上图的理解是:
整个图分为两部分,红线上面是solrcloud物理结构,红线下面是solr逻辑结构
solrcloud物理结构:三个Solr实例(服务器1、服务器2、服务器3,每个实例包括两个Core),组成一个SolrCloud。
solrcloud逻辑结构:从下往上看,
最下面的Collection是一个索引集合,包括两个Shard(shard1和shard2),它们是collection的两个分片,shard1和shard2分别由三个Core组成,其中一个Leader(Master主节点)两个Replication(Slave从节点),Leader(Master主节点)是由zookeeper选举产生,zookeeper控制每个shard上三个Core的索引数据一致,解决高可用问题。
用户发起索引请求分别从shard1和shard2上获取,解决高并发问题。
对于其他概念解释(从下到上 Collection Core Master与Slave Shard):
Collection:是SolrCloud集群中一个具有完整的逻辑意义的索引结构。它常常被划分为一个或多个Shard(分片),它们使用相同的配置信息。
比如:针对商品信息搜索可以创建一个collection,即collection=shard1+shard2+....+shardX
Shard:是Collection的逻辑分片,每个Shard被化成一个或者多个replication,通过zookeeper管理,选举确定哪个是Leader。
Master与Slave:Master是master-slave结构中的主结点(通常说主服务器),Slave是master-slave结构中的从结点(通常说从服务器或备服务器)。同一个Shard下master和slave存储的数据一定是一致的,这是为了达到高可用目的。
Core:每个Core是Solr中一个独立运行单位,提供 索引和搜索服务。一个shard需要由一个Core或多个Core组成,由于collection由多个shard组成所以collection一般由多个core组成。
4.3 ZooKeeper管理
solr集群需要使用ZooKeeper进行管理,ZooKeeper是一种分布式协调服务,用于管理大型主机。在分布式环境中协调和管理服务是一个复杂的过程。ZooKeeper通过其简单的架构和API解决了这个问题。 ZooKeeper允许开发人员专注于核心应用程序逻辑,而不必担心应用程序的分布式特性。
zookeeper进行集群管理,具有两个特性:
- 客户端在节点 x 上注册一个Watcher,那么如果 x 的子节点变化了,会通知该客户端。
- 创建EPHEMERAL类型的节点,一旦客户端和服务器的会话结束或过期,那么该节点就会消失。
在此请区别Zookeeper集群与Redis集群的容错特点:
Zookeeper集群:有一个Leader主节点,若干个Follower备份节点。
Redis集群:有多个Leader,实行彼此互联(PING-PONG机制),每个Leader都存在若干个Follower备份节点。
对于solr集群的搭建,比较复制,搭建起来也是和单机版一样,索引库查询操作,一样的,这里略去。
五、小结
本文简单介绍全文搜索服务器Solr,分为三个部分,包括:
初识solr(solr用途)、单机版solr和集群版solr,简单介绍了solr相关基础知识,可帮助初学solr入门。
天天打码,天天进步!
以上是关于初识Solr,基于Lucene的全文搜索服务器的主要内容,如果未能解决你的问题,请参考以下文章