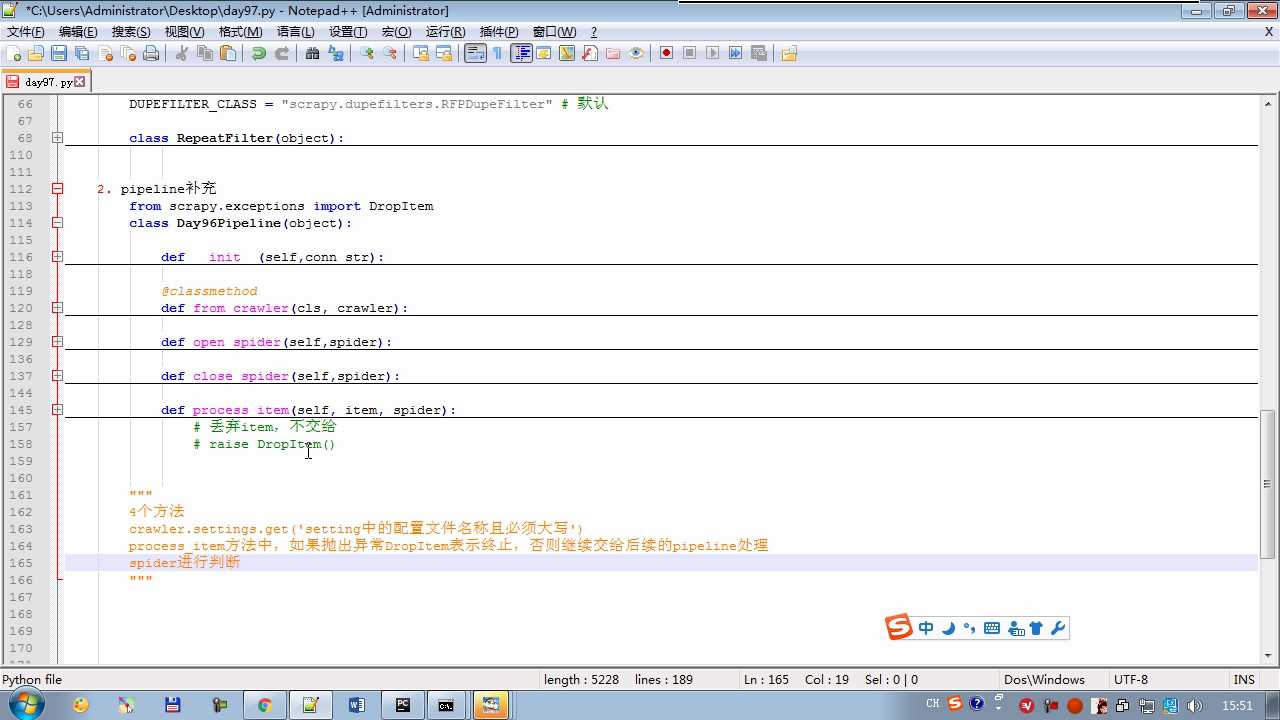
pipeline补充
Posted jintian
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了pipeline补充相关的知识,希望对你有一定的参考价值。
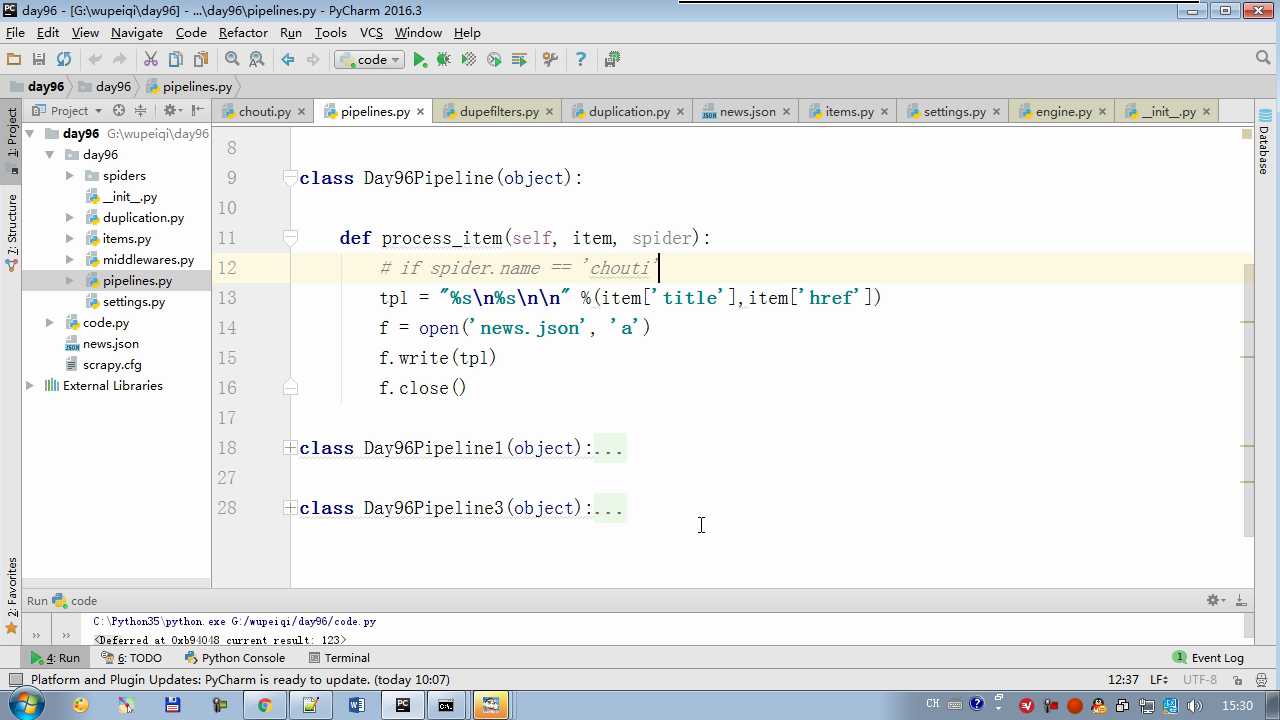
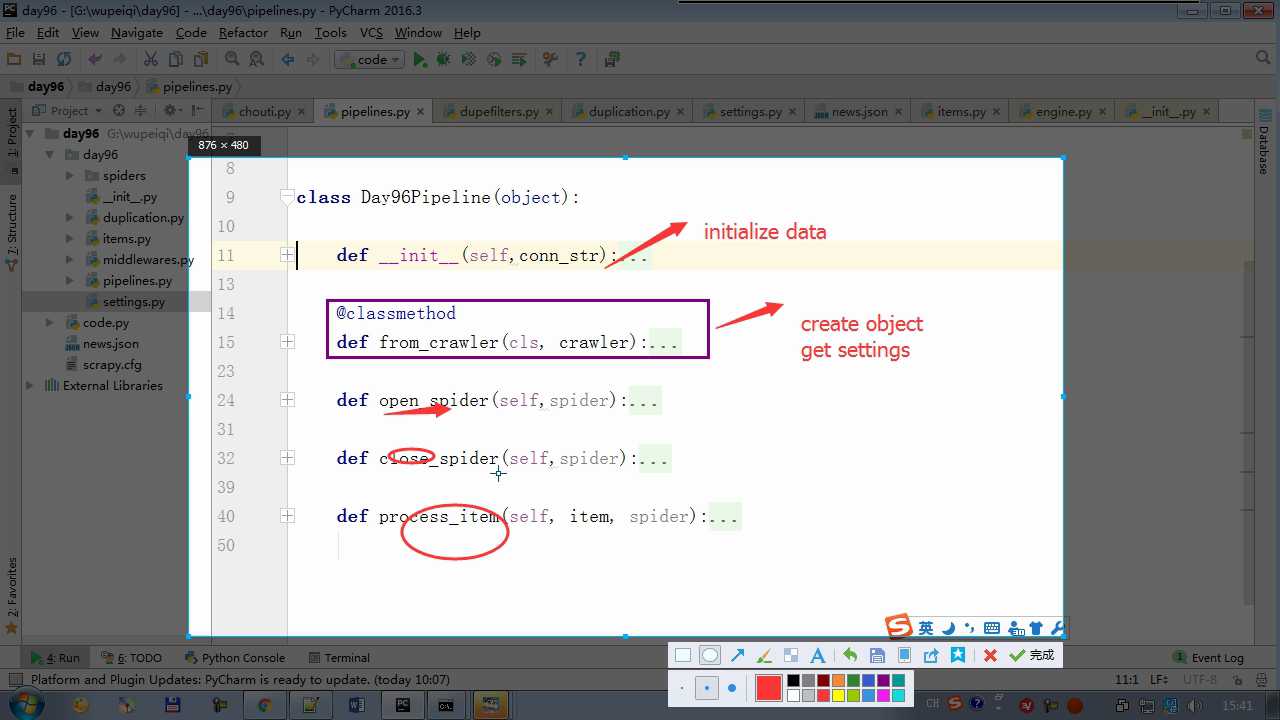
yield item 会执行 process_item
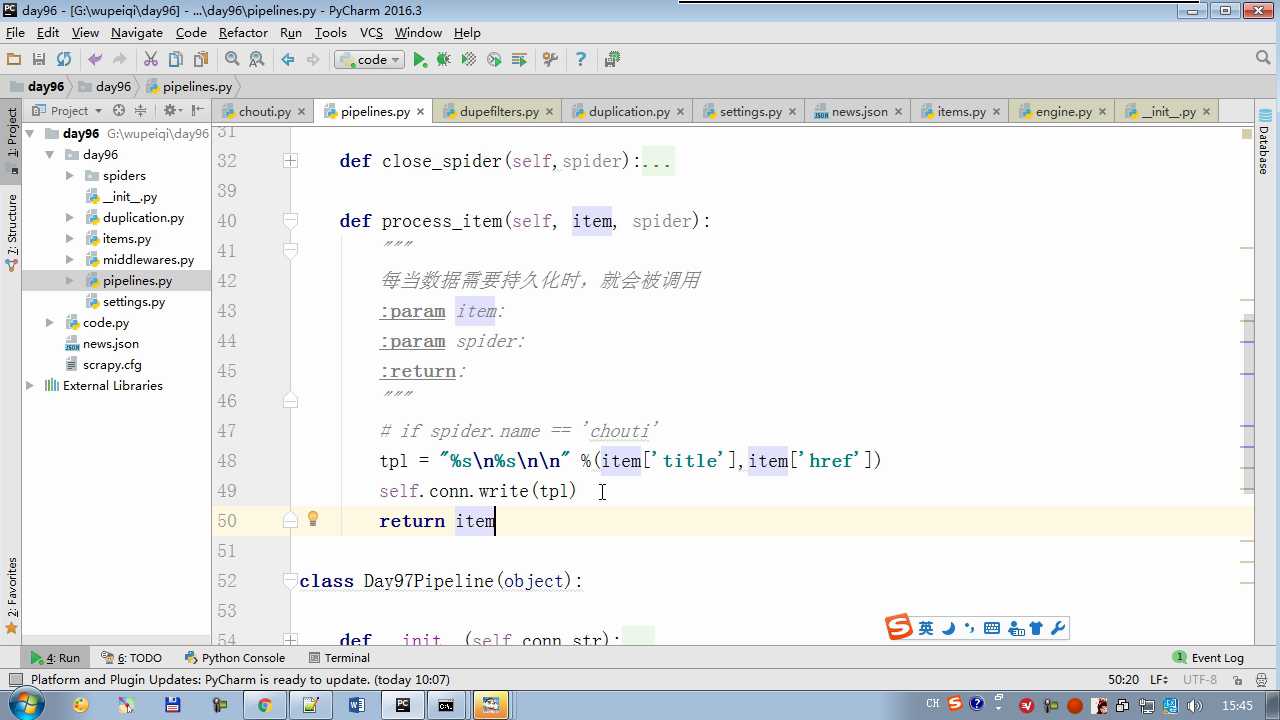
def process_item return item 交给下一个pipeline
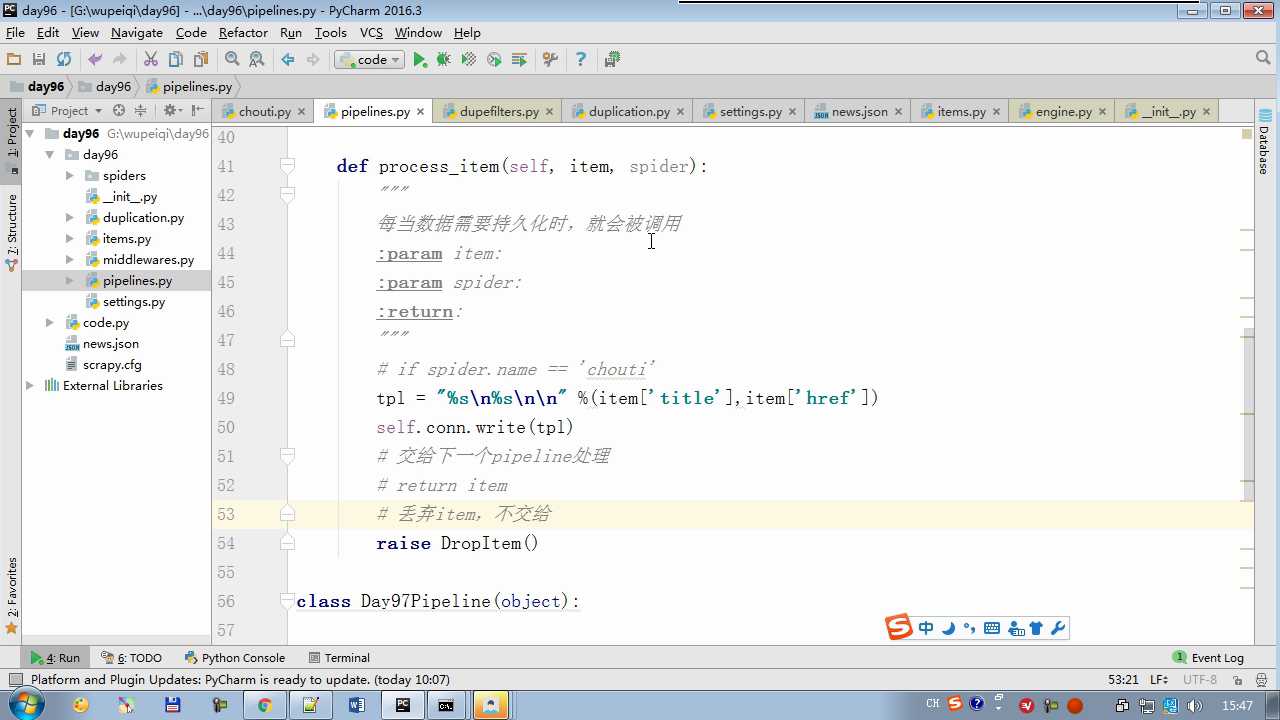
raise DropItem 丢弃掉,不给下一个pipeline
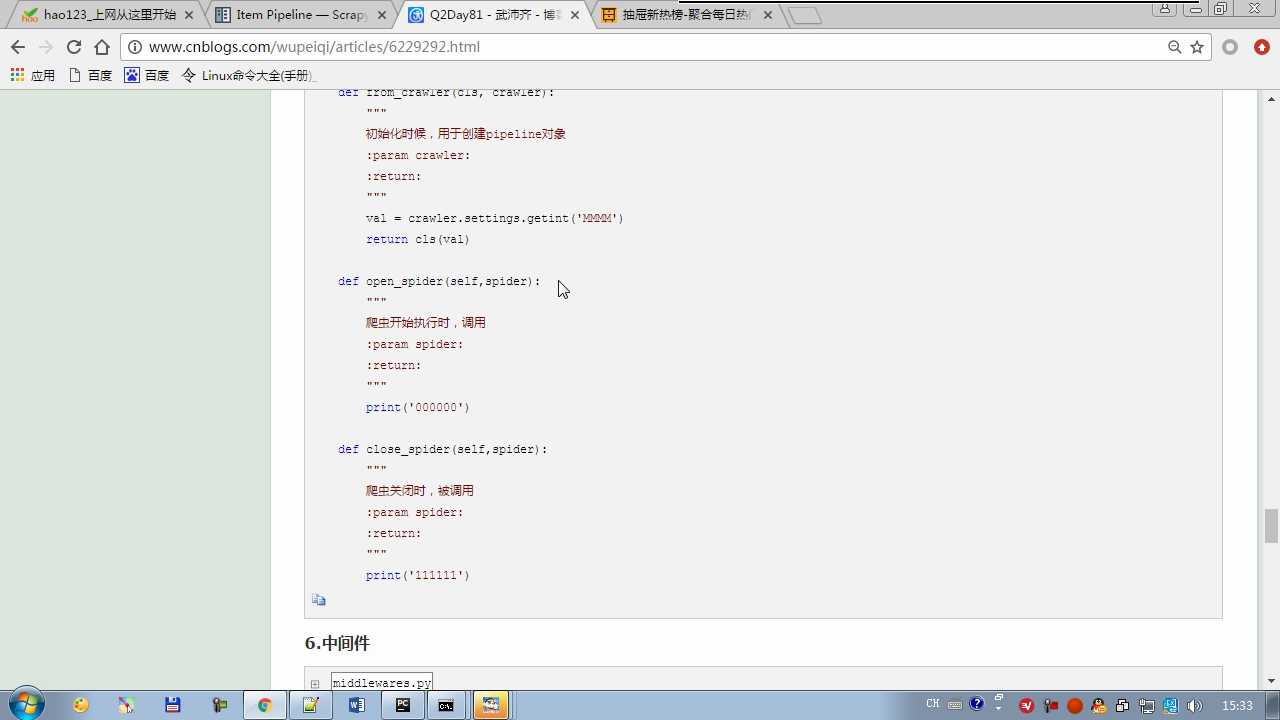
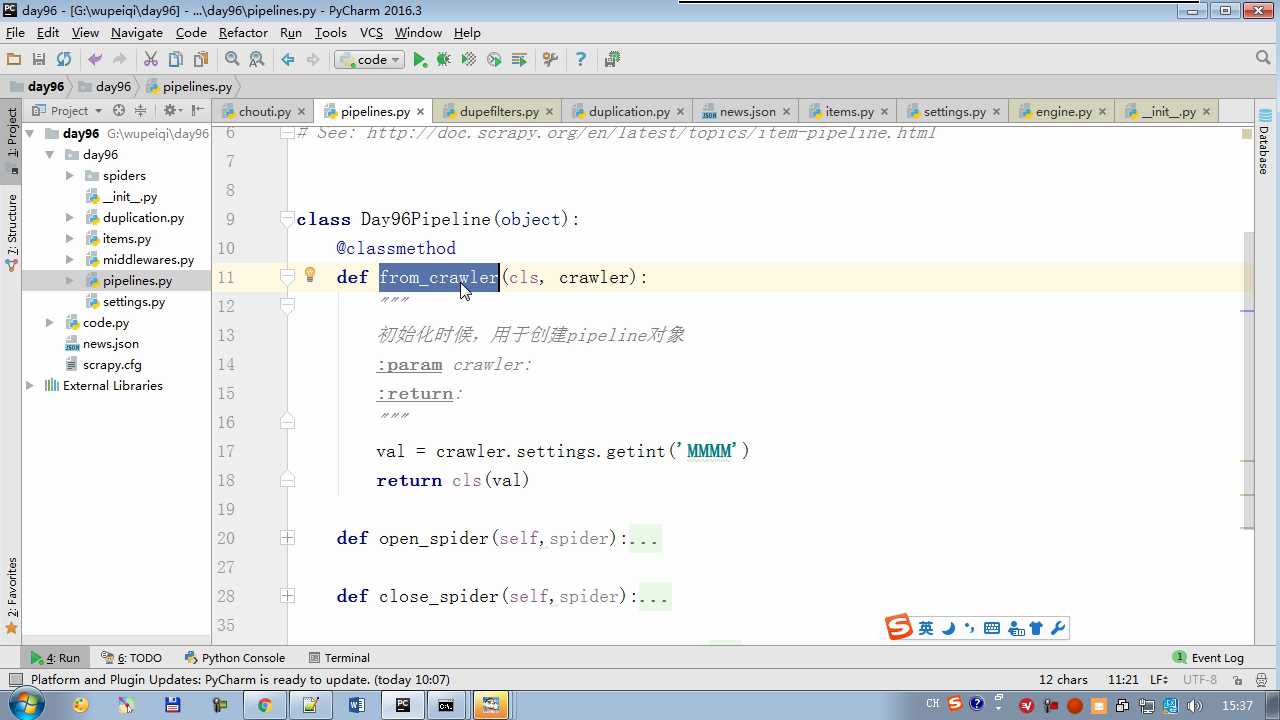
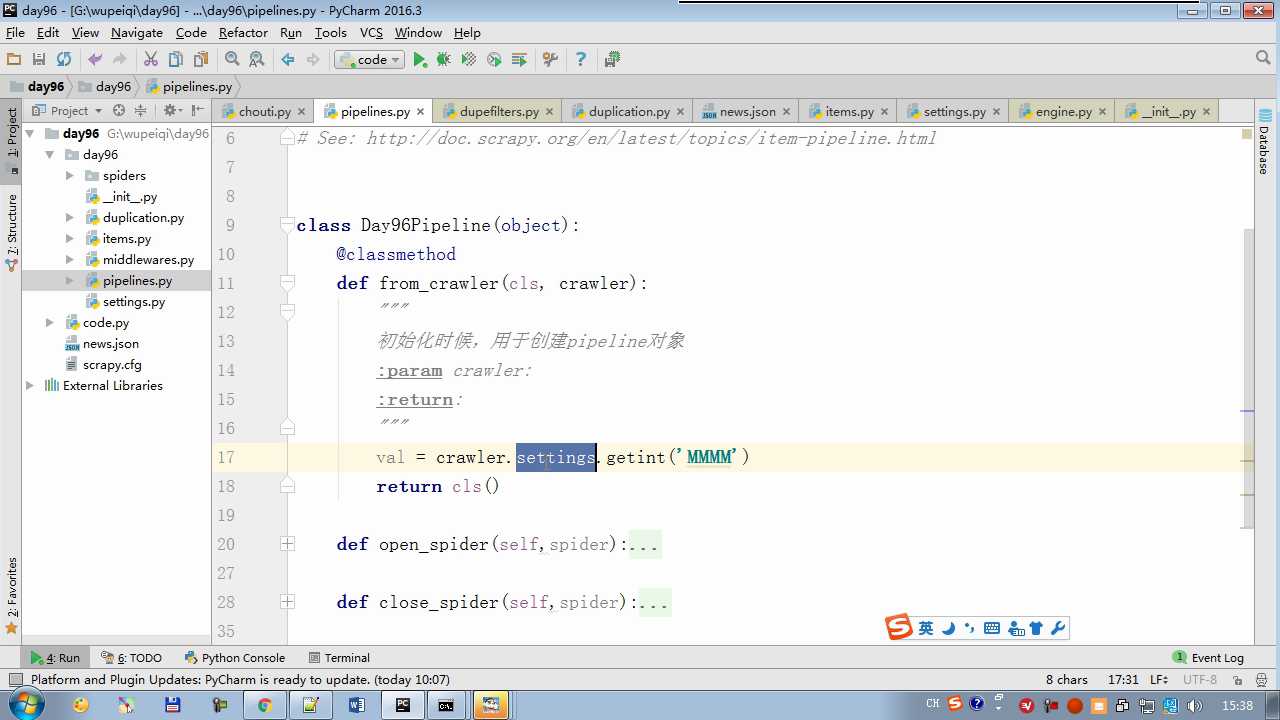
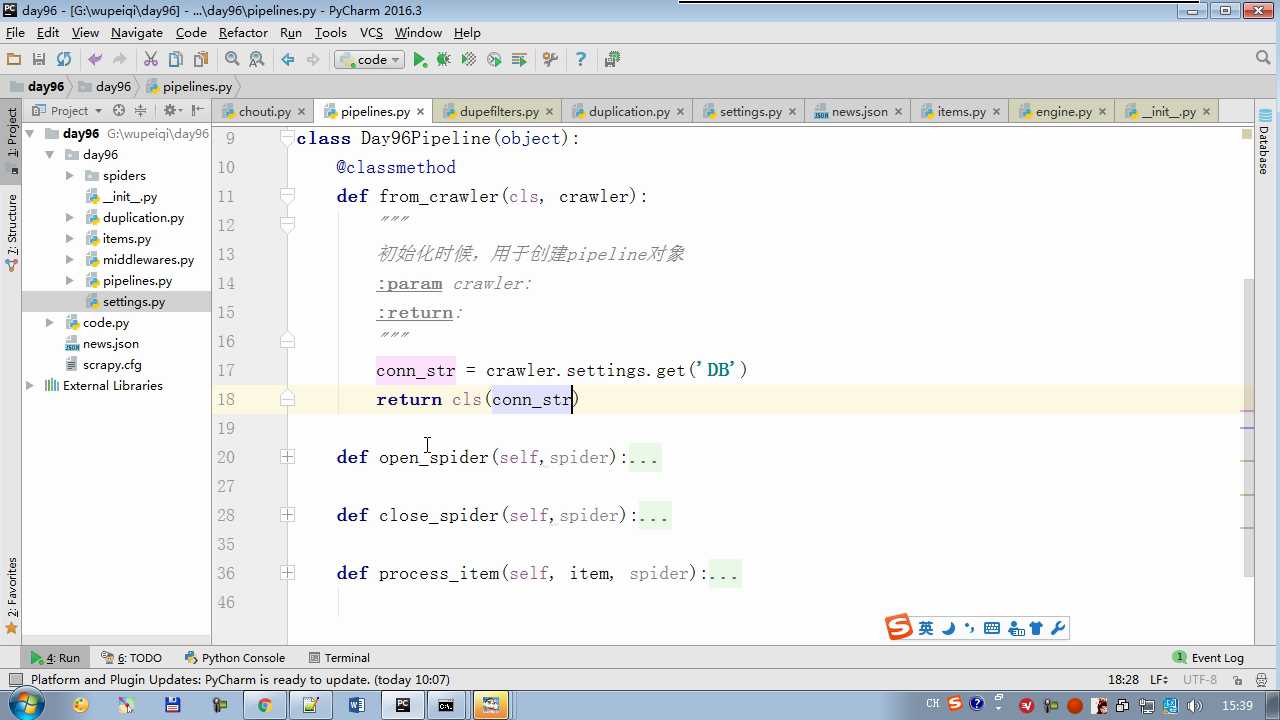
crawler.settings crawler封装了settings
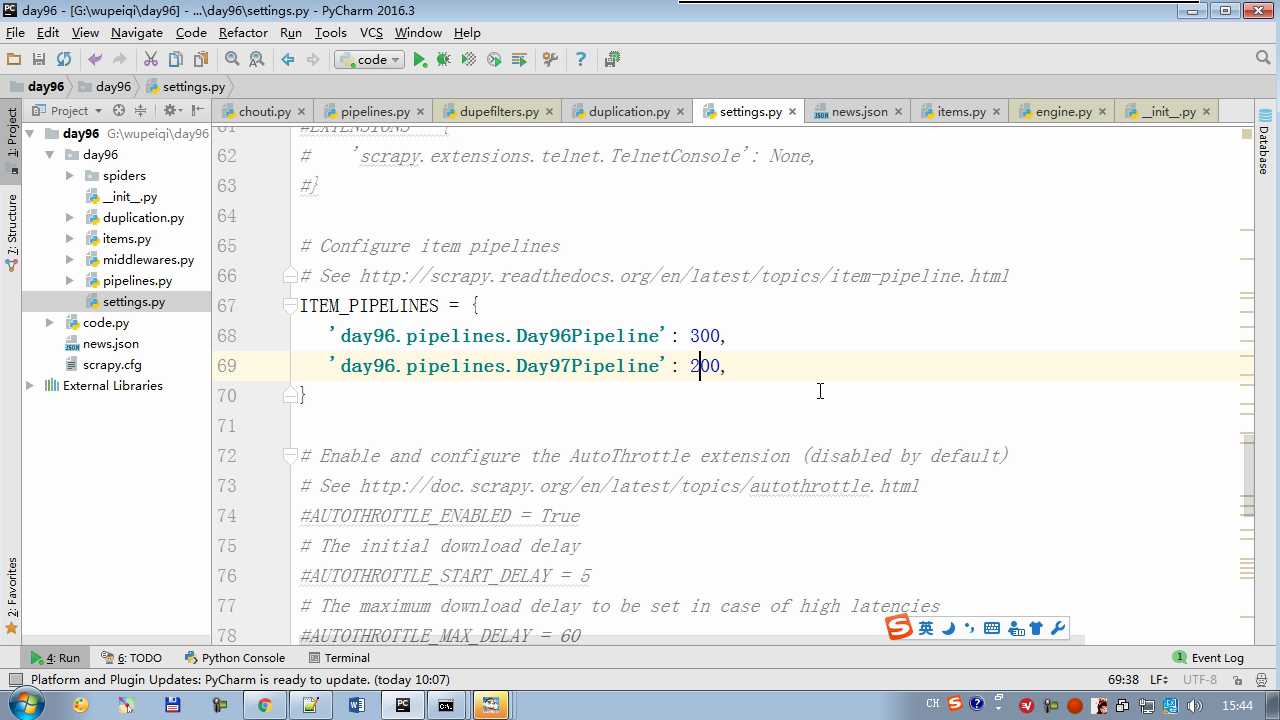
配置文件必须大写


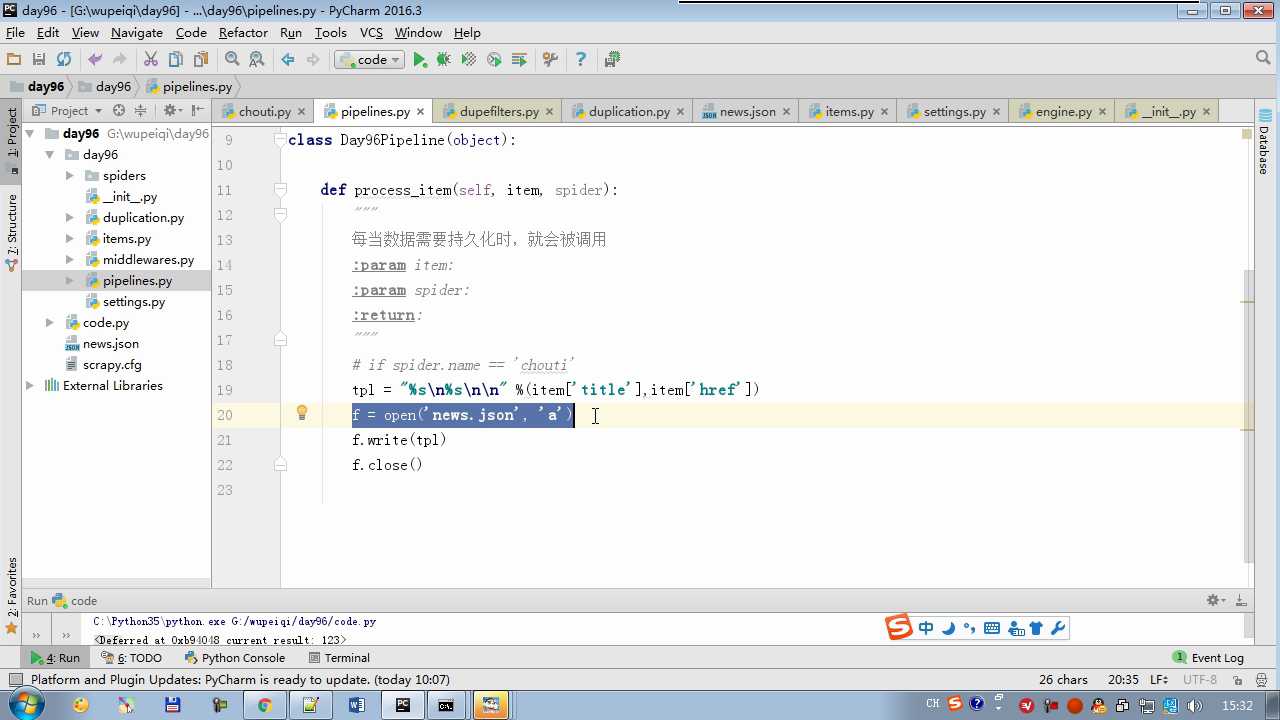
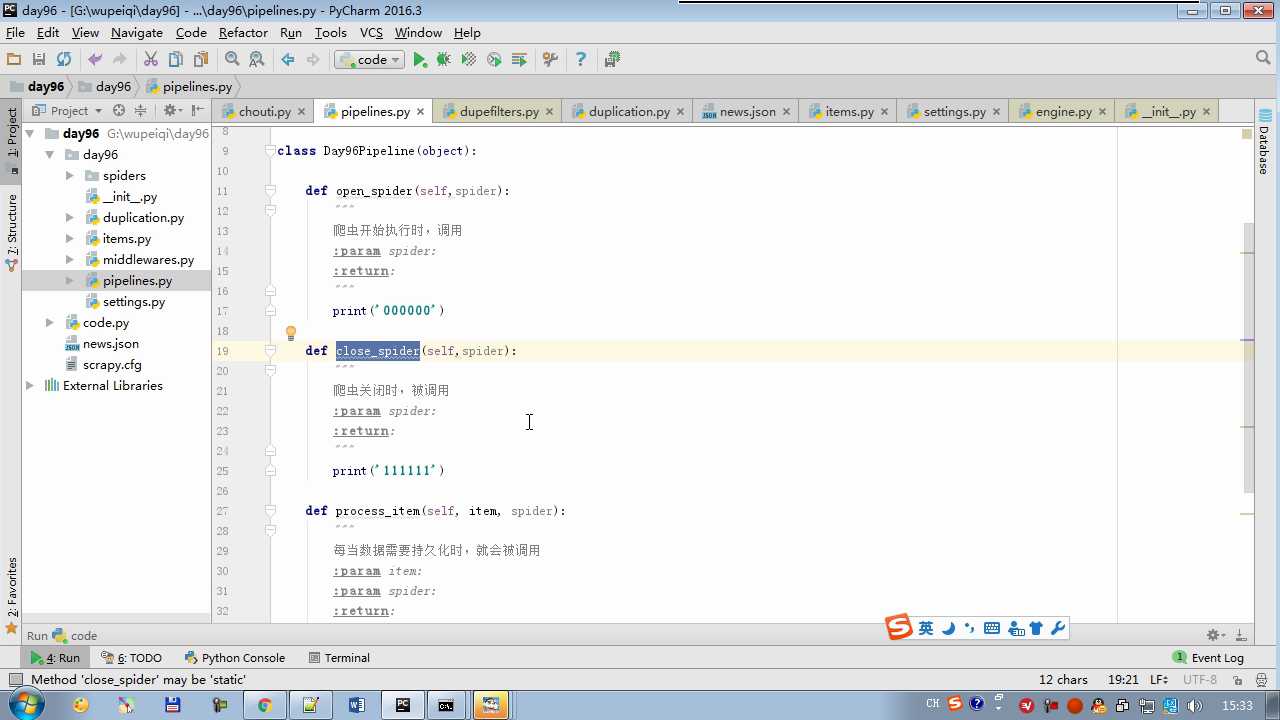
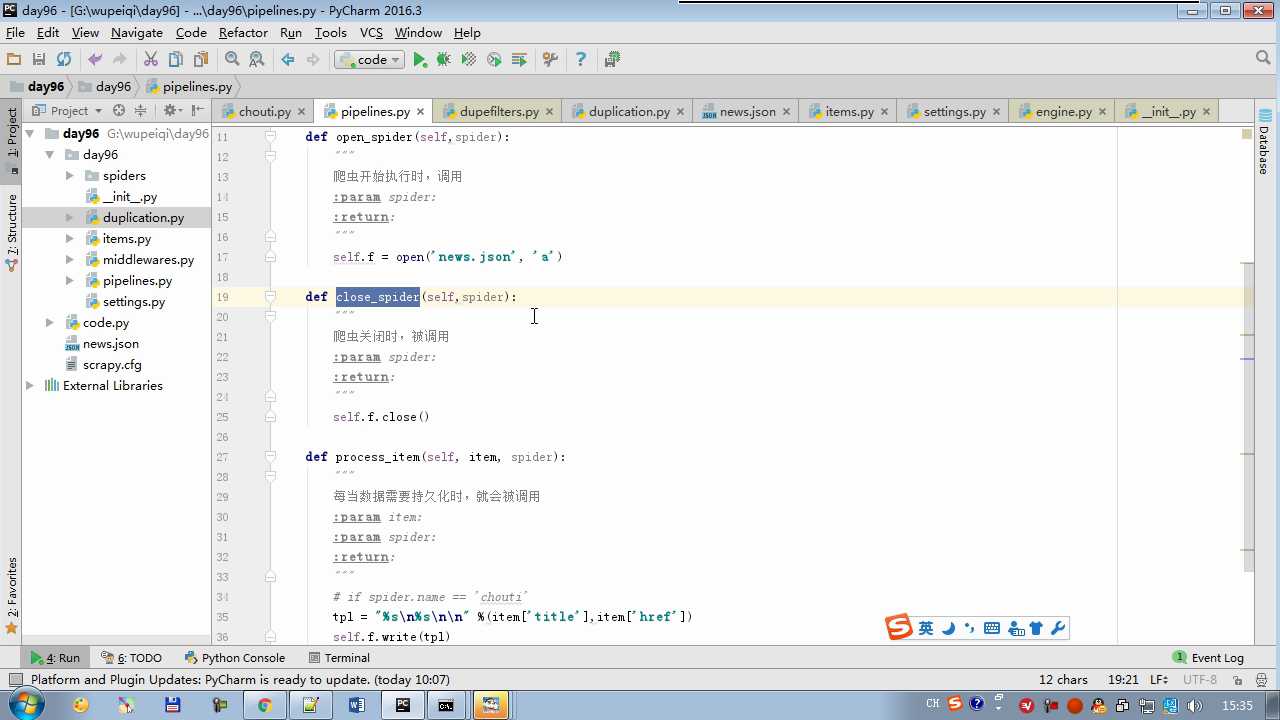
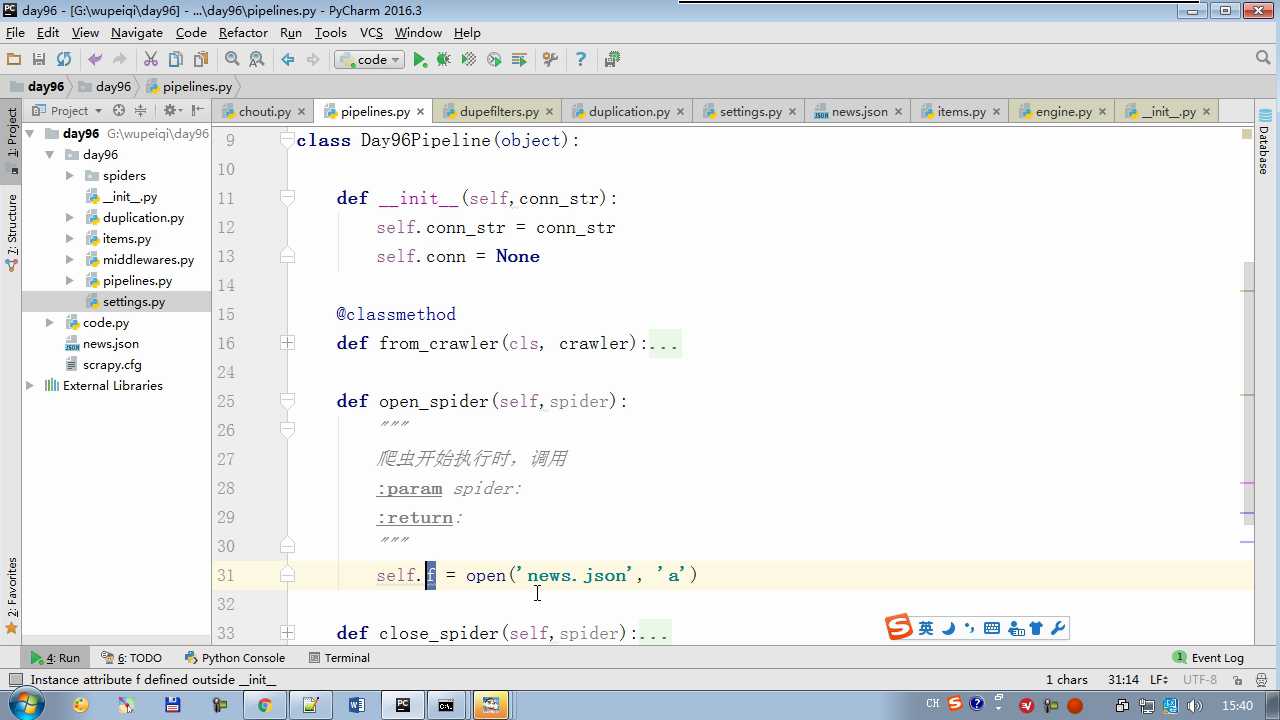
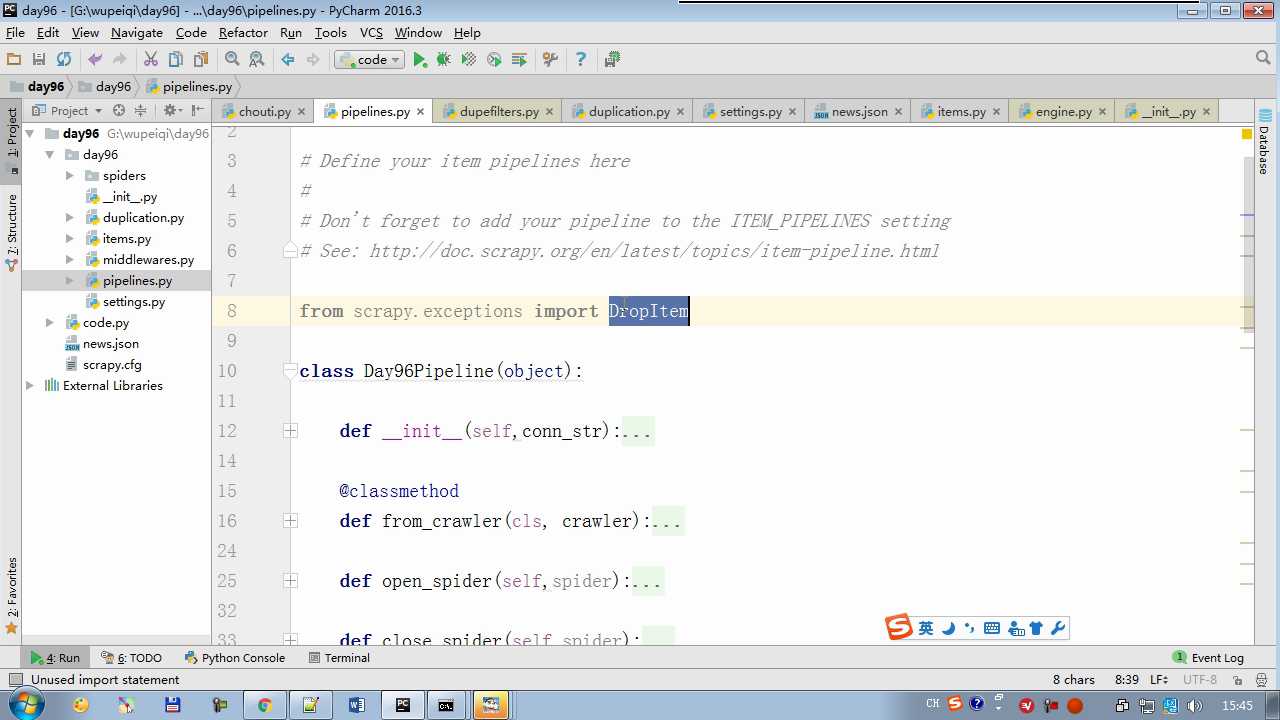
# -*- coding: utf-8 -*- # Define your item pipelines here # # Don‘t forget to add your pipeline to the ITEM_PIPELINES setting # See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html from scrapy.exceptions import DropItem class Day96Pipeline(object): def __init__(self,conn_str): self.conn_str = conn_str @classmethod def from_crawler(cls, crawler): """ 初始化时候,用于创建pipeline对象 :param crawler: :return: """ conn_str = crawler.settings.get(‘DB‘) return cls(conn_str) def open_spider(self,spider): """ 爬虫开始执行时,调用 :param spider: :return: """ self.conn = open(self.conn_str, ‘a‘) def close_spider(self,spider): """ 爬虫关闭时,被调用 :param spider: :return: """ self.conn.close() def process_item(self, item, spider): """ 每当数据需要持久化时,就会被调用 :param item: :param spider: :return: """ # if spider.name == ‘chouti‘ tpl = "%s\\n%s\\n\\n" %(item[‘title‘],item[‘href‘]) self.conn.write(tpl) # 交给下一个pipeline处理 return item # 丢弃item,不交给 # raise DropItem() class Day97Pipeline(object): def __init__(self,conn_str): self.conn_str = conn_str @classmethod def from_crawler(cls, crawler): """ 初始化时候,用于创建pipeline对象 :param crawler: :return: """ conn_str = crawler.settings.get(‘DB‘) return cls(conn_str) def open_spider(self,spider): """ 爬虫开始执行时,调用 :param spider: :return: """ self.conn = open(self.conn_str, ‘a‘) def close_spider(self,spider): """ 爬虫关闭时,被调用 :param spider: :return: """ self.conn.close() def process_item(self, item, spider): """ 每当数据需要持久化时,就会被调用 :param item: :param spider: :return: """ # if spider.name == ‘chouti‘ tpl = "%s\\n%s\\n\\n" %(item[‘title‘],item[‘href‘]) self.conn.write(tpl)
以上是关于pipeline补充的主要内容,如果未能解决你的问题,请参考以下文章
27-Jenkins-Pipeline-Pipeline Basic Steps插件之timeoutwaitUntilwithEnv方法