BeautifulSoup模块详细介绍
Posted jintian
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了BeautifulSoup模块详细介绍相关的知识,希望对你有一定的参考价值。
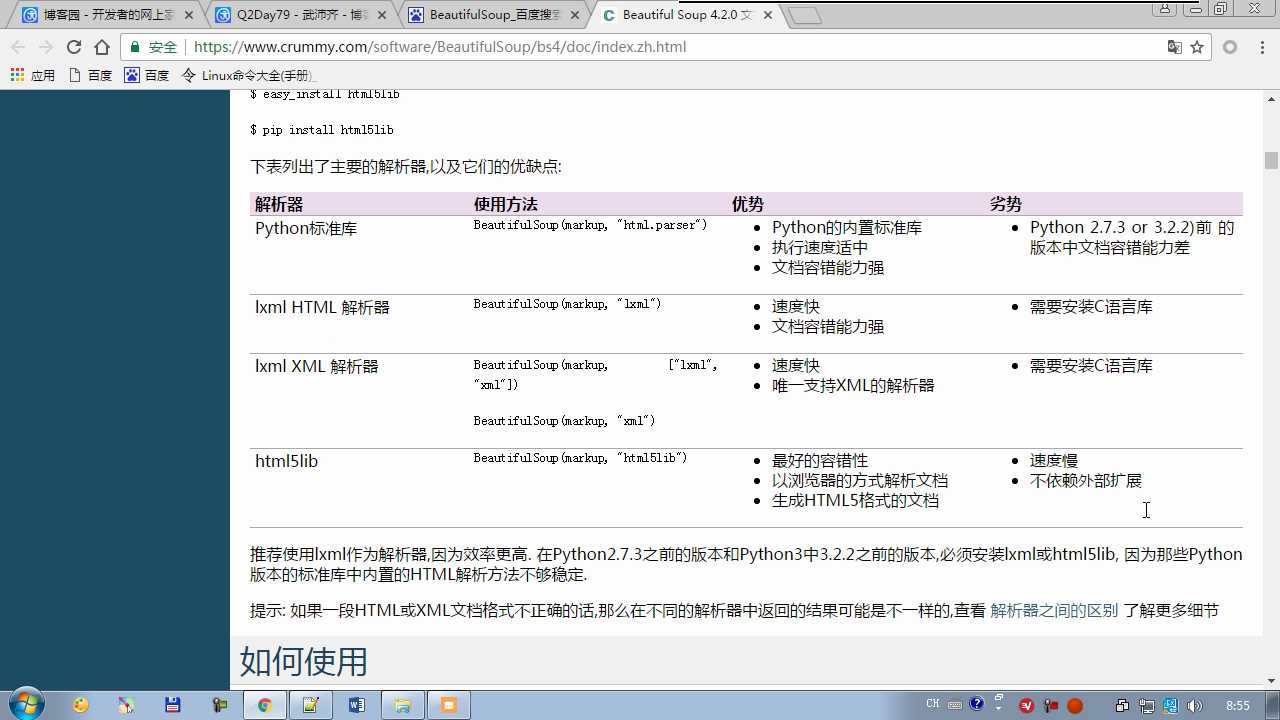
安装lxml,引擎(解析器)
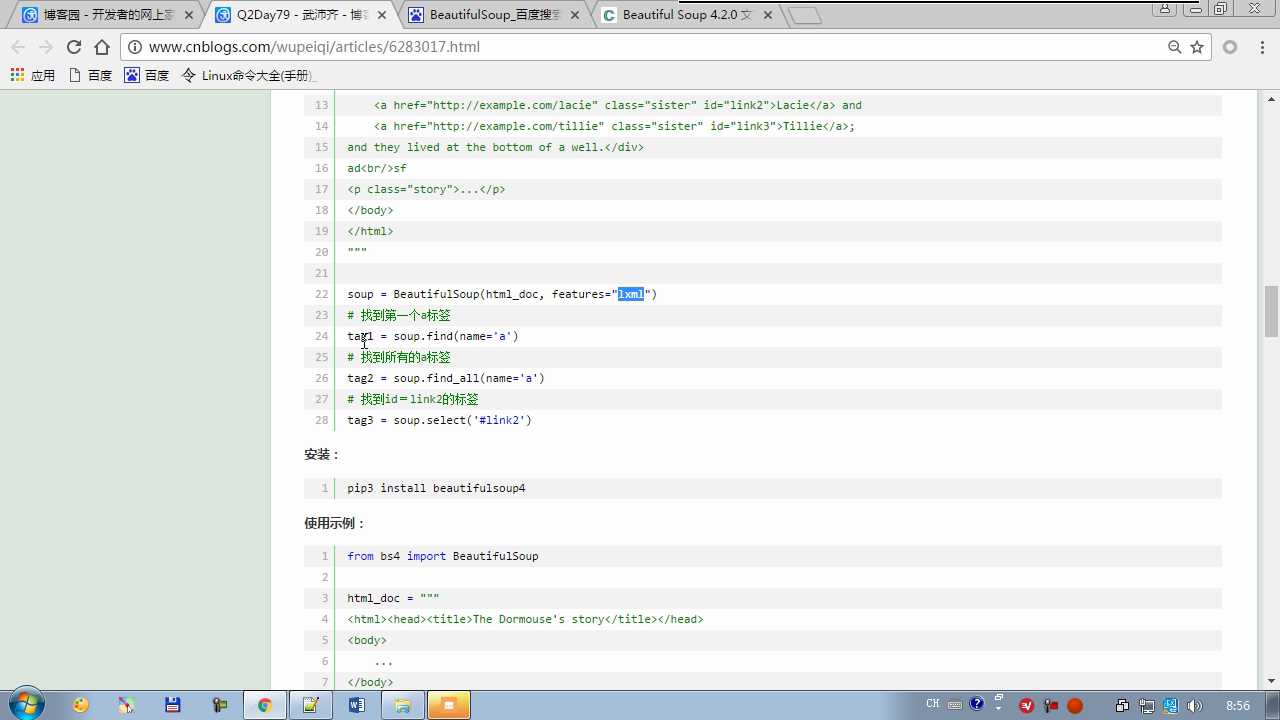
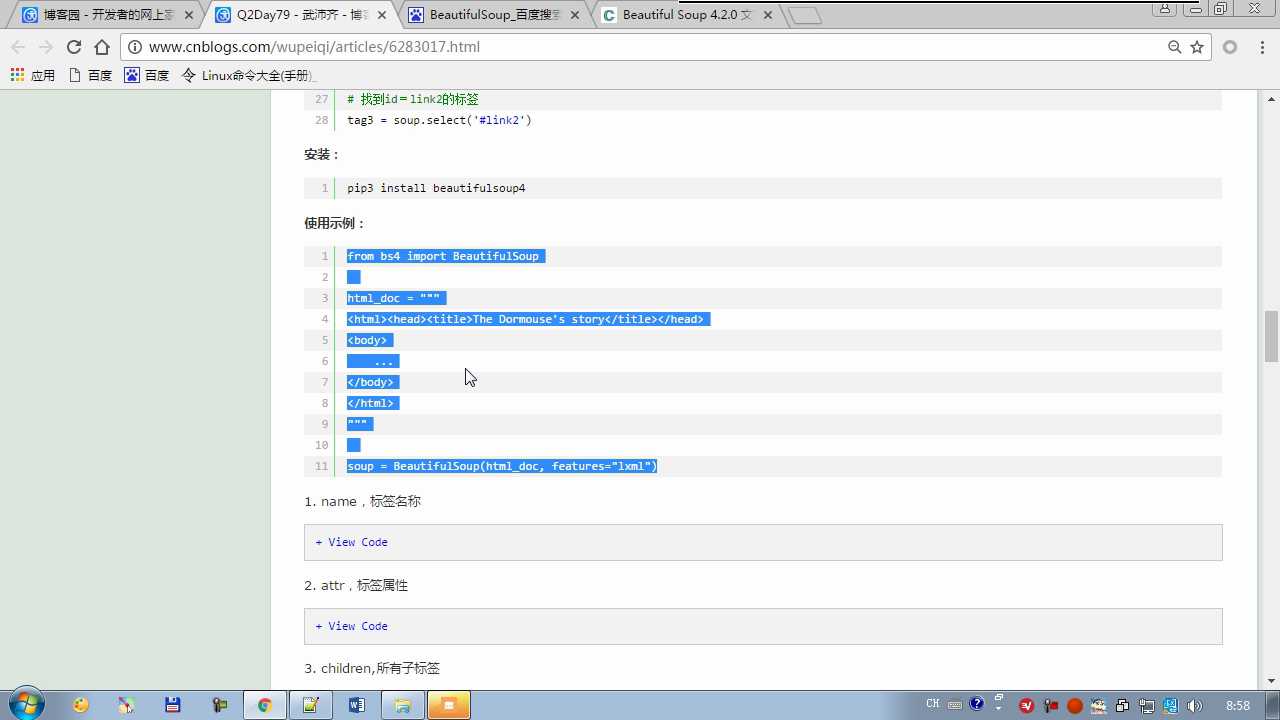
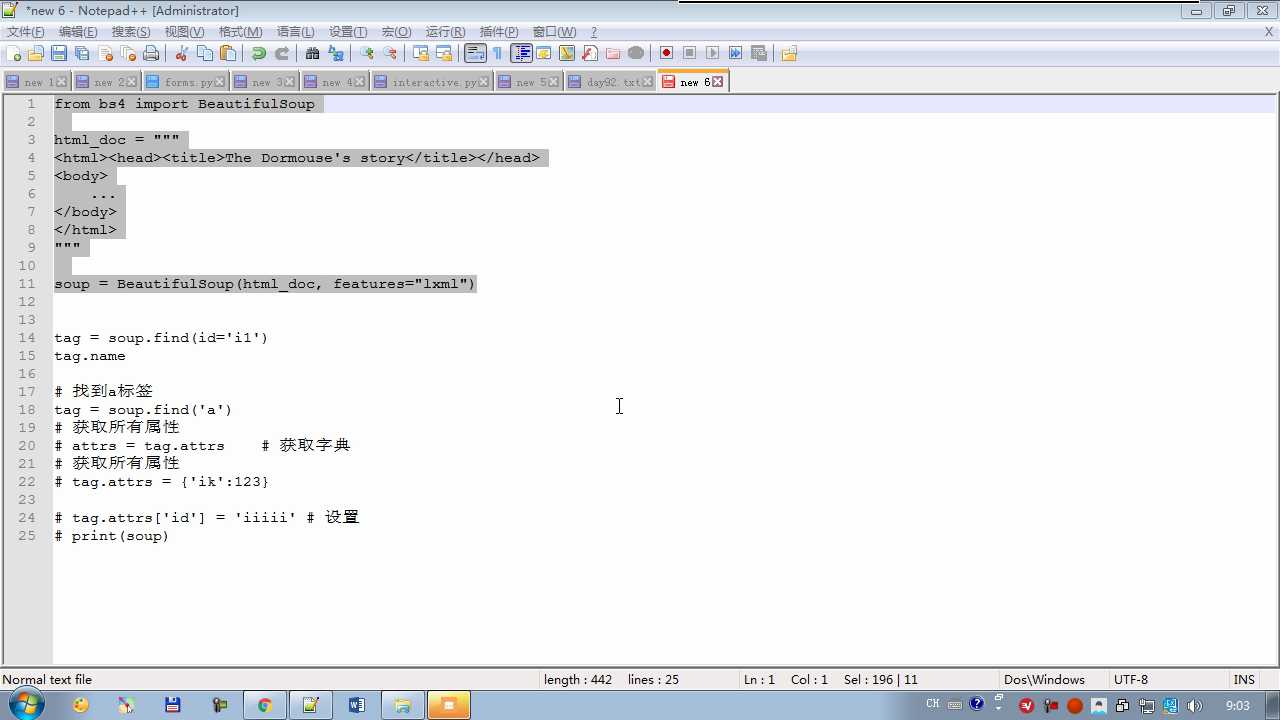
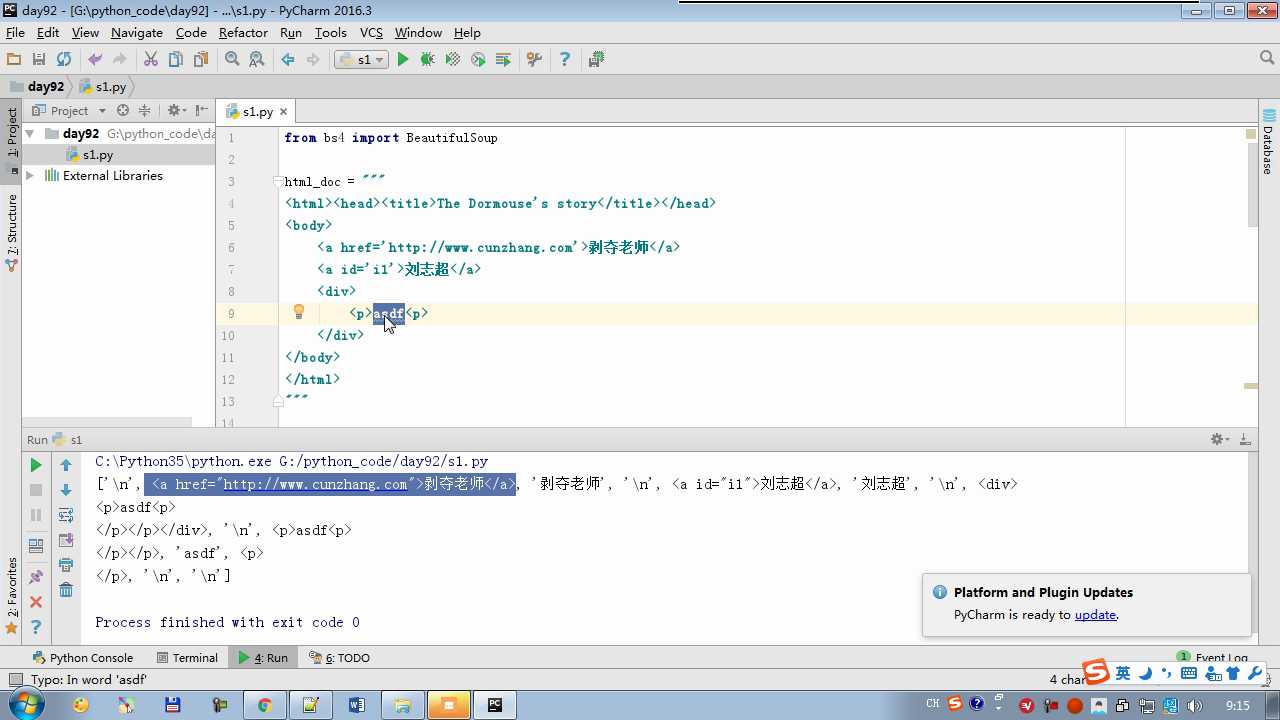
soup=BeautifulSoup(html_doc,features="lxml")
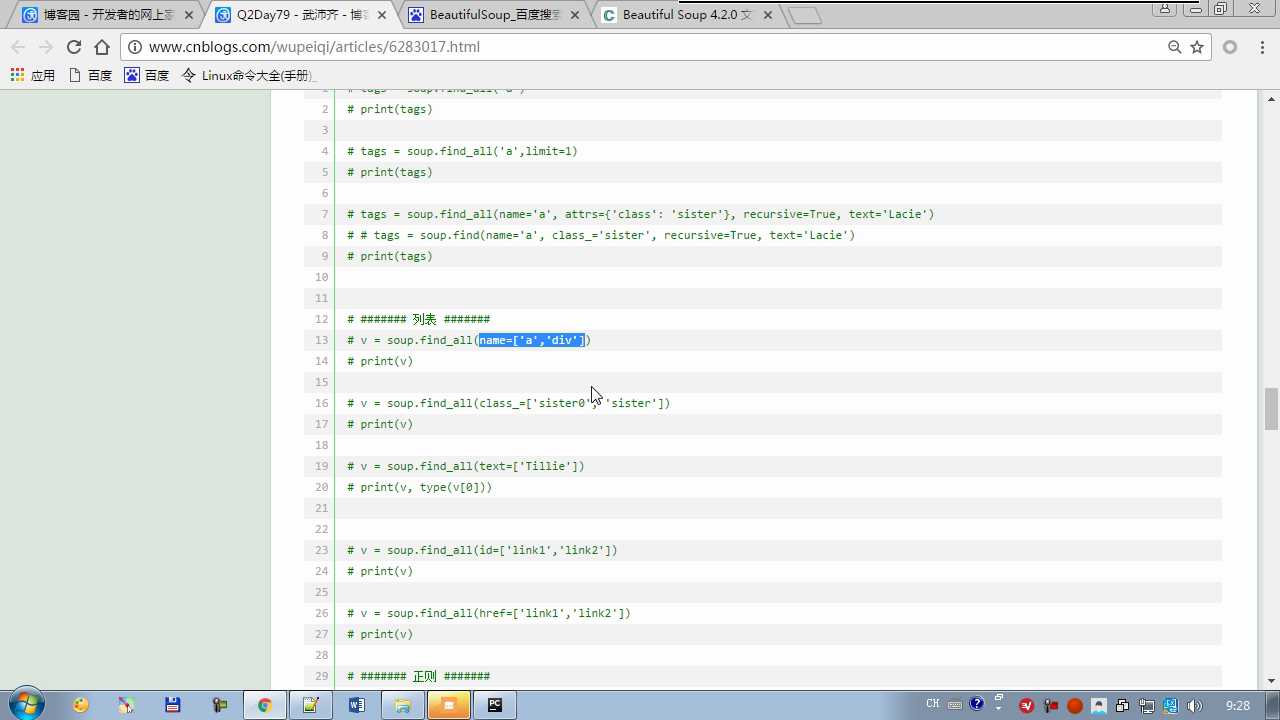
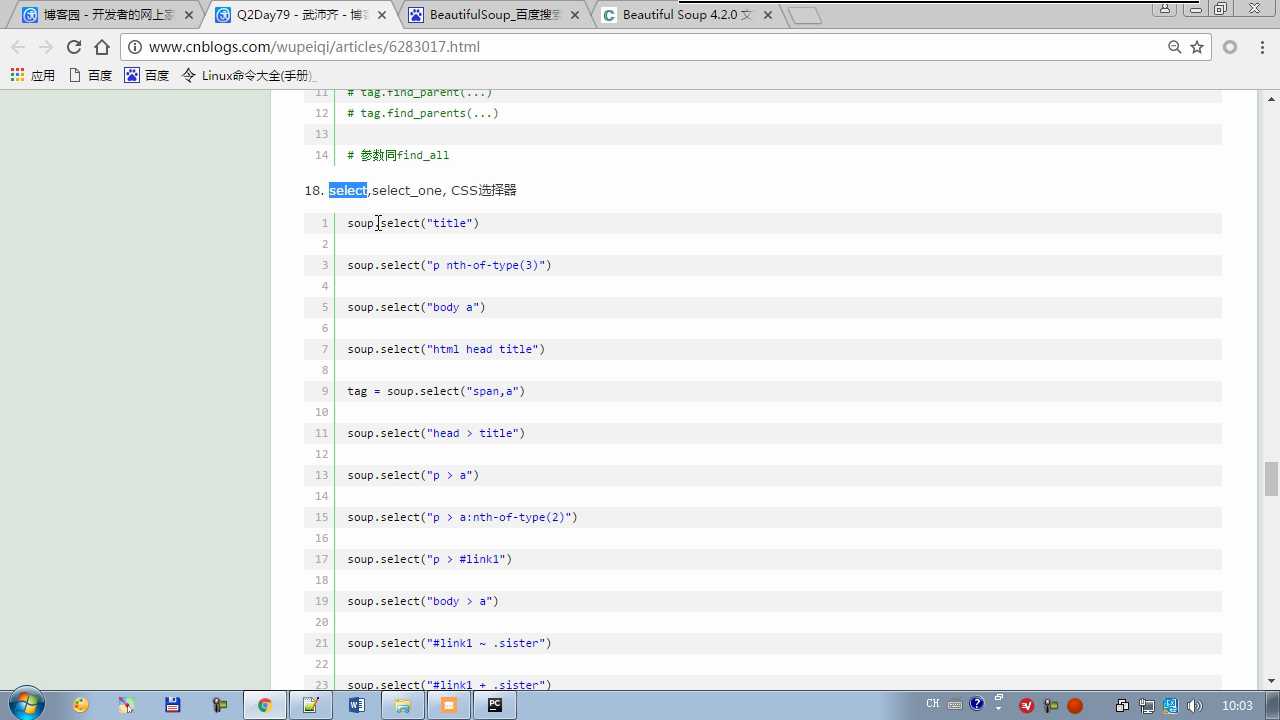
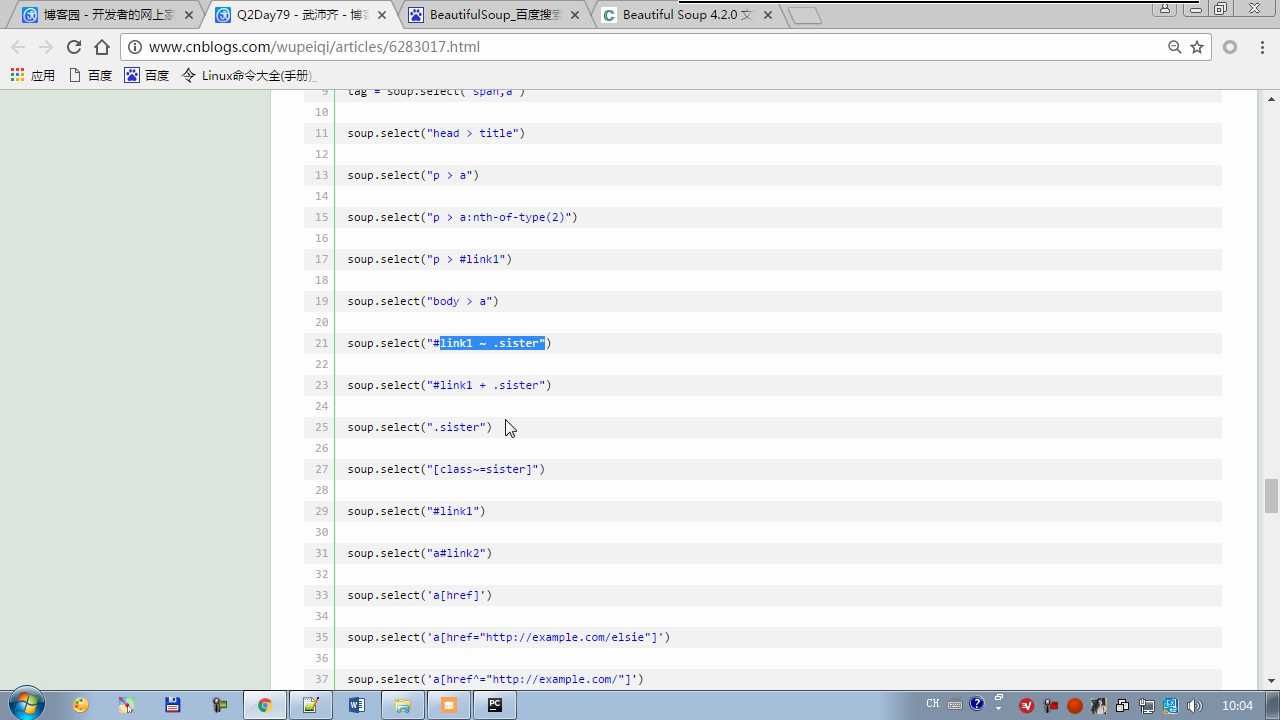
tag=soup.select(‘#link2‘) 选择器的方式
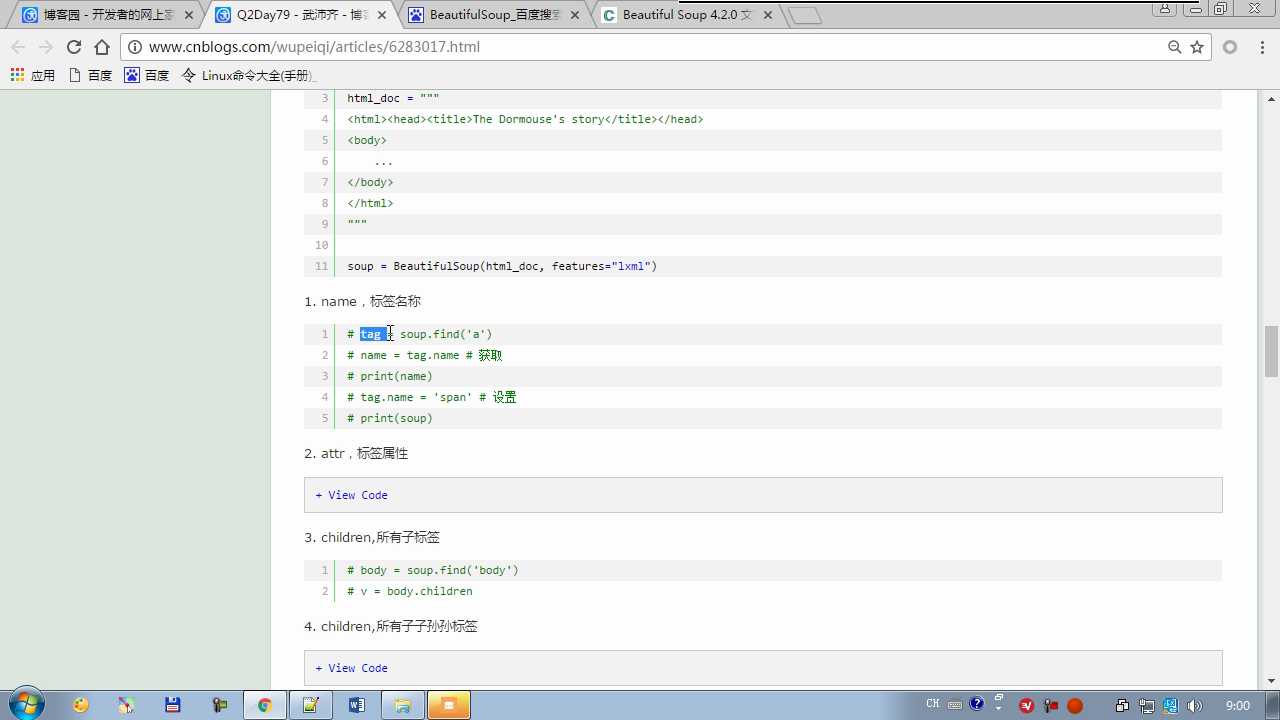
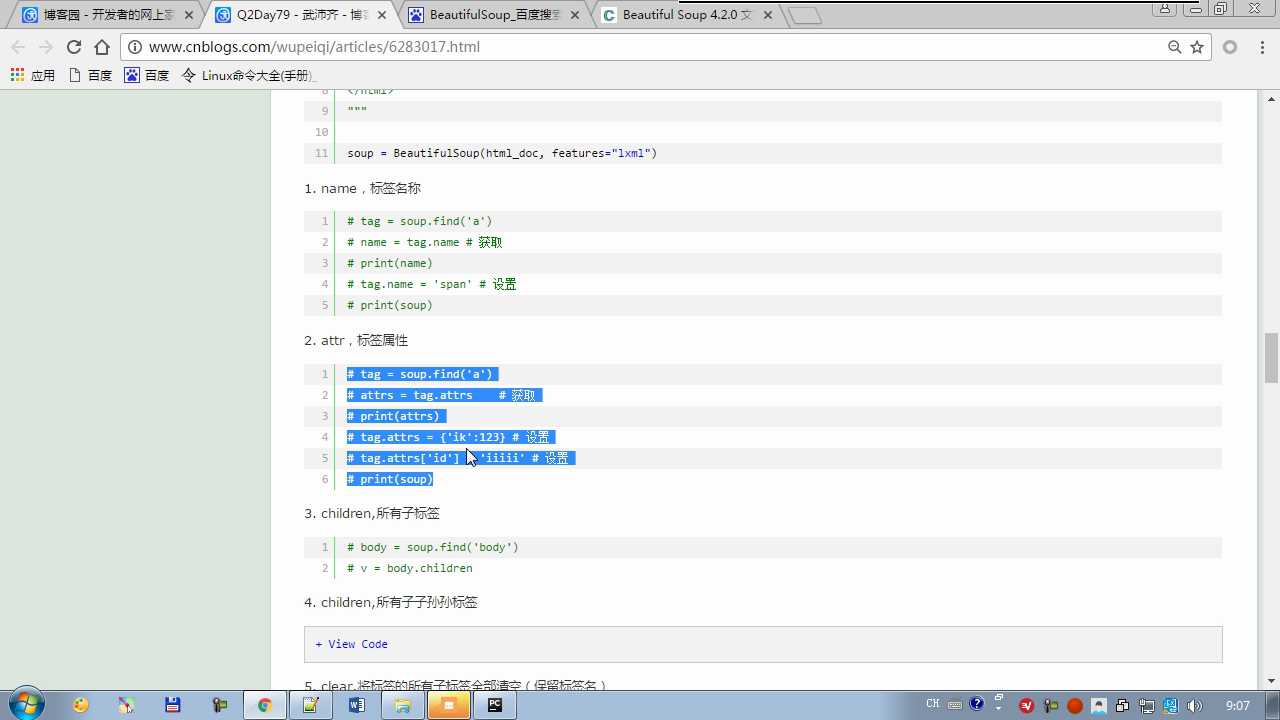
tag.name 获取标签名
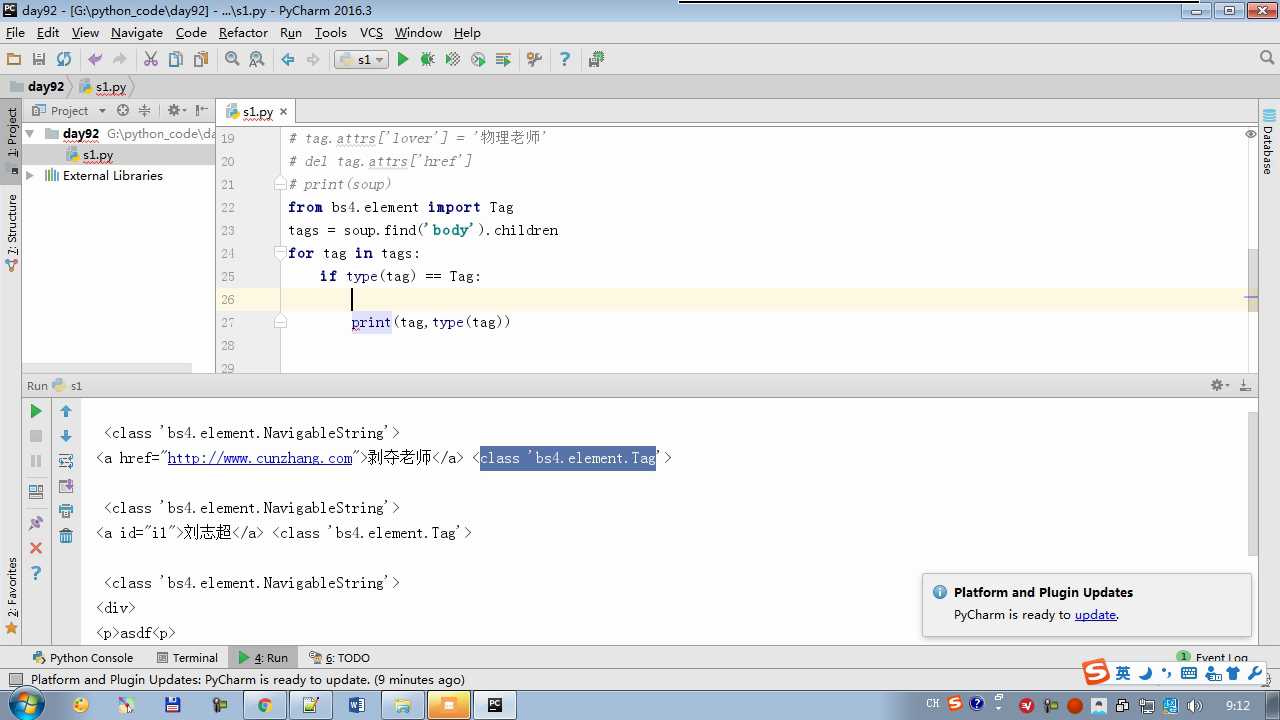
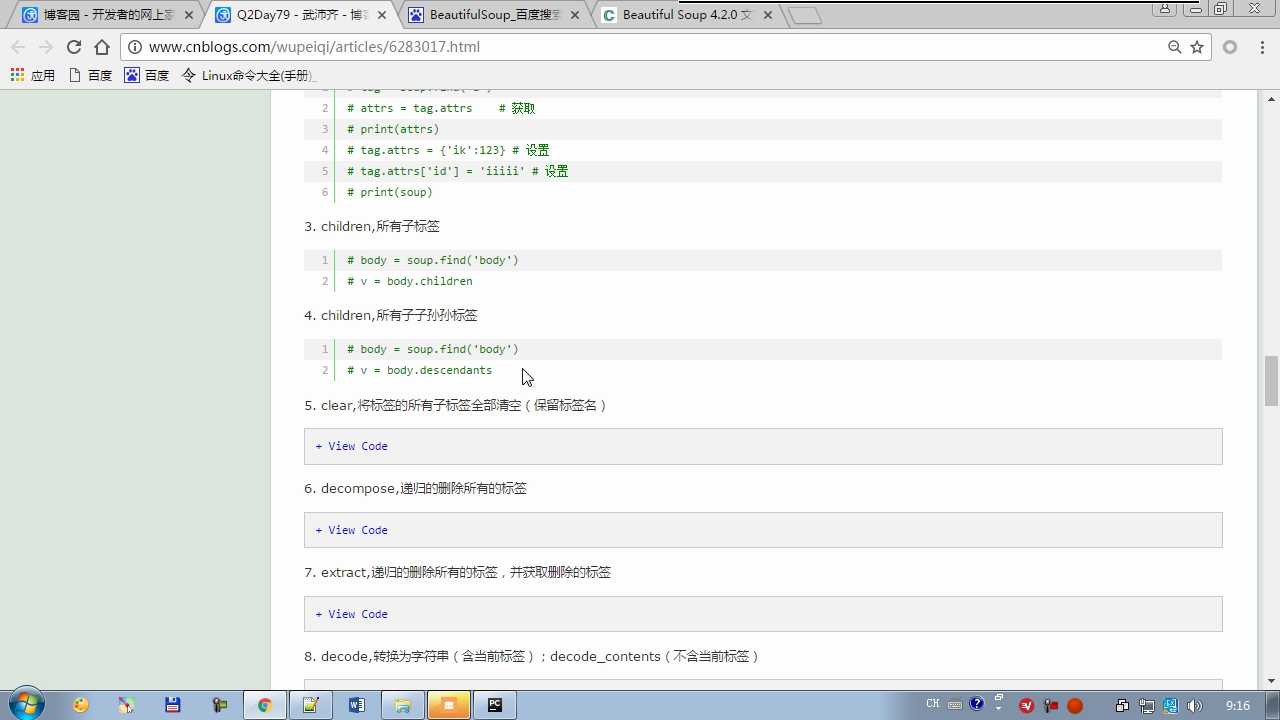
children:儿子 标签和内容是不一样的类型
descendants:后代
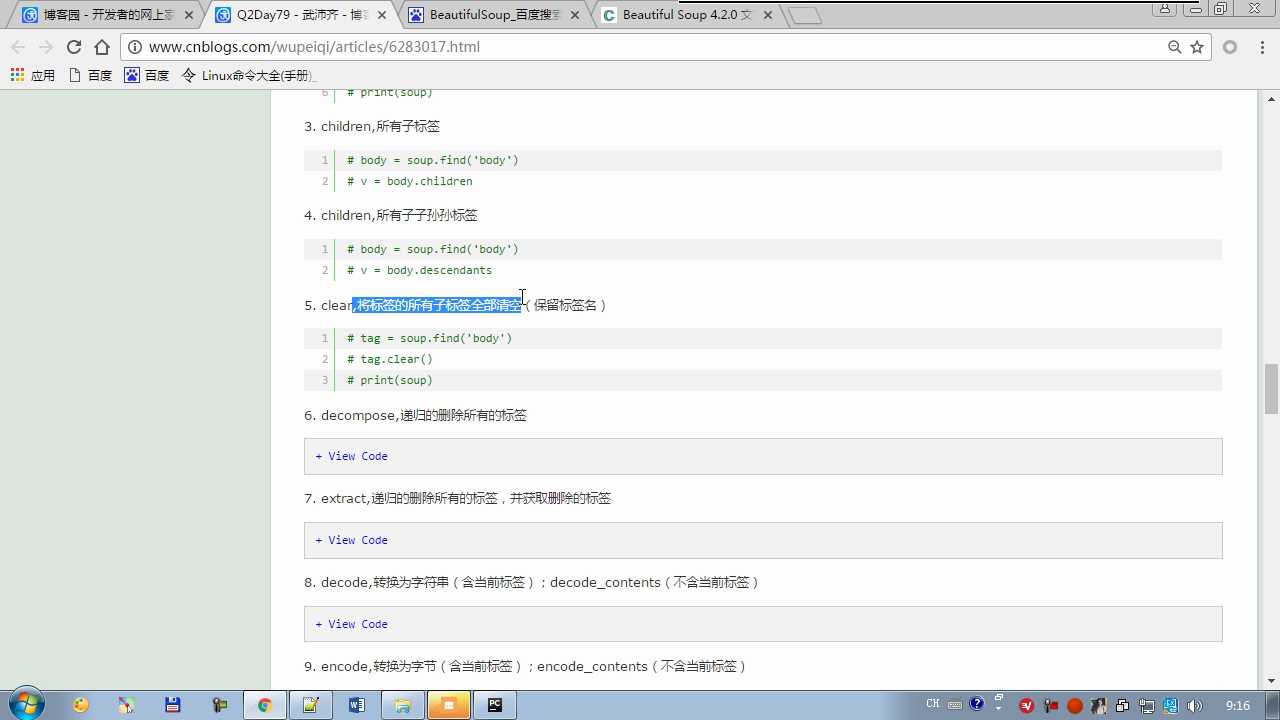
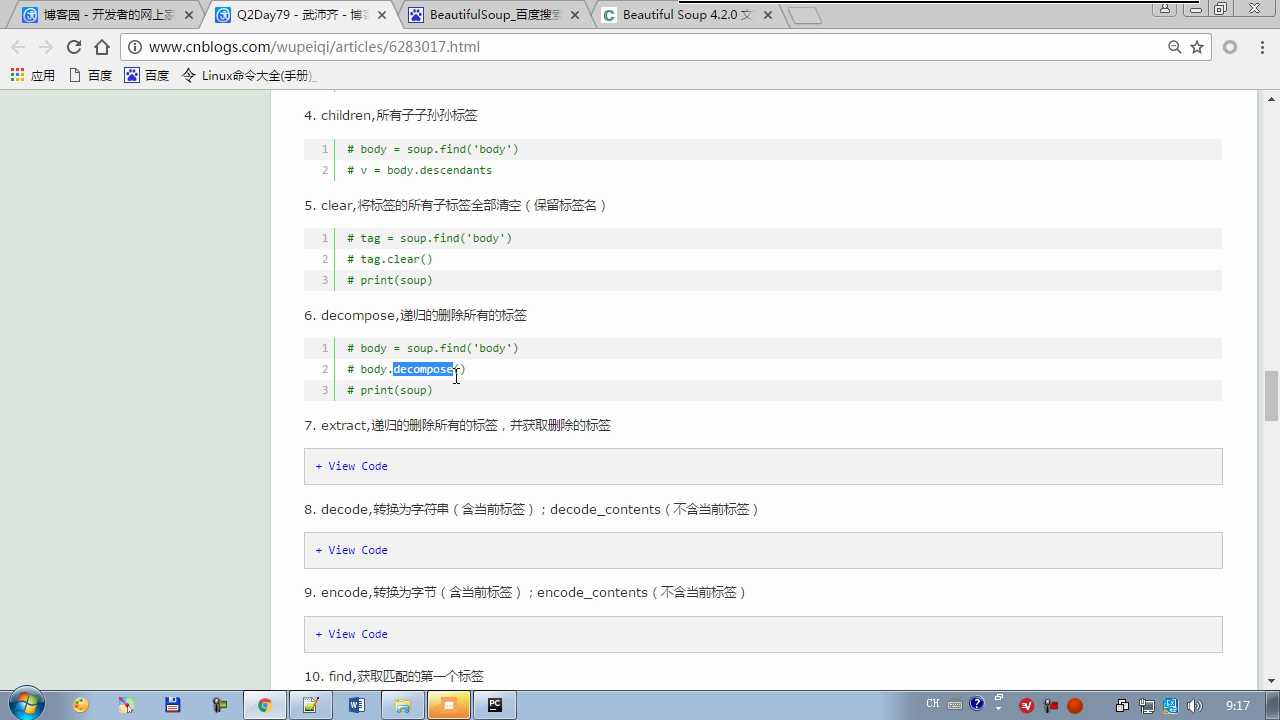
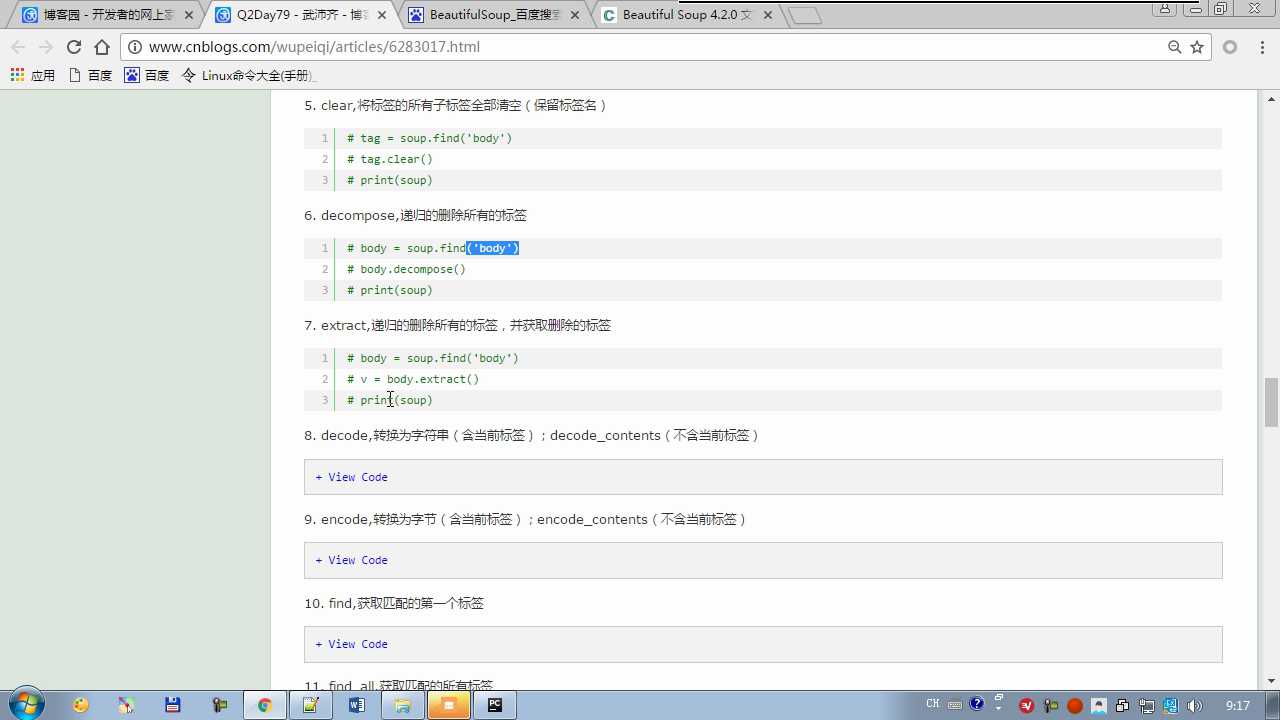
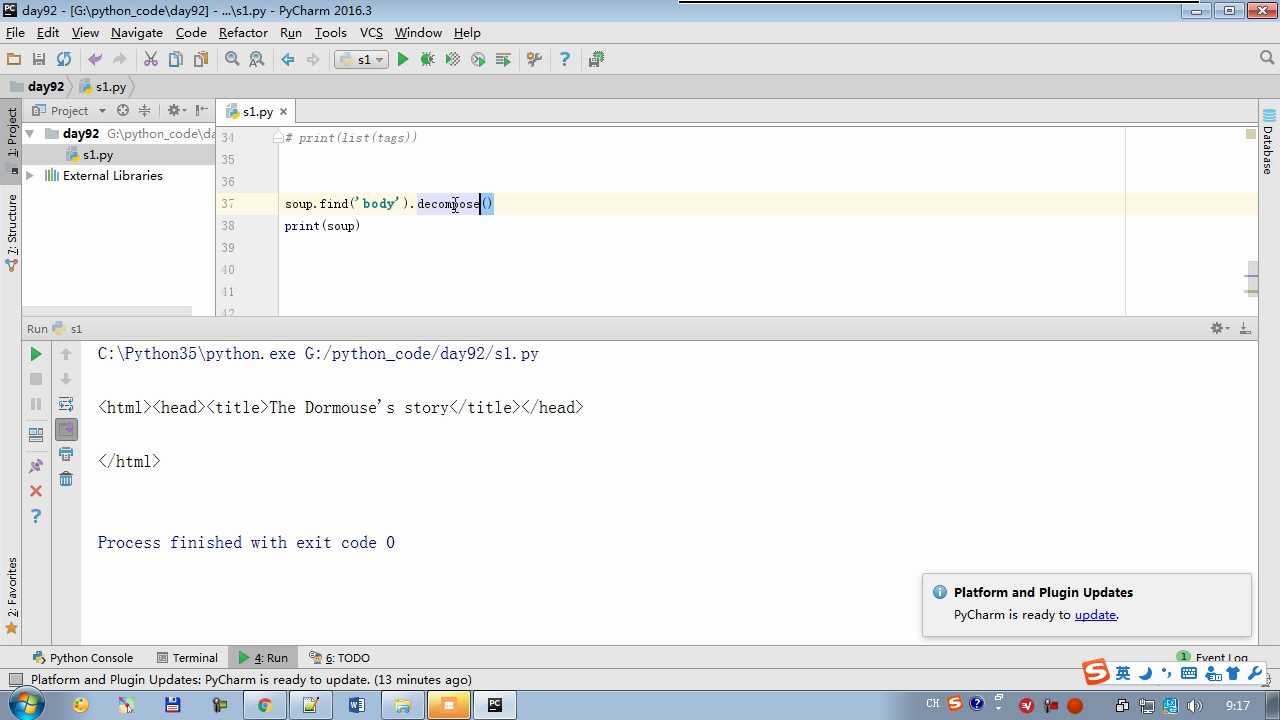
clear:清空保留标签名 decompose:删除,不保留标签名
extract:删除并有返回值(删除的标签)
encode:把对象转化为字节类型 decode:把对象转化为字符串类型
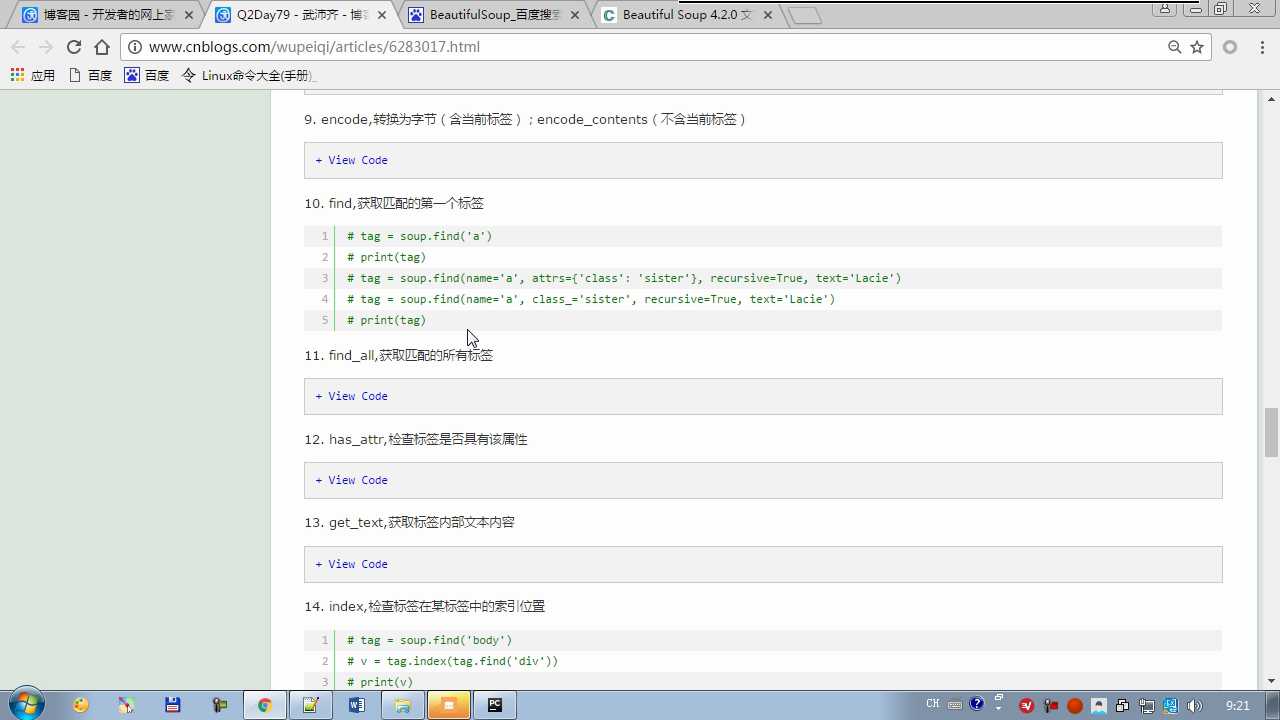
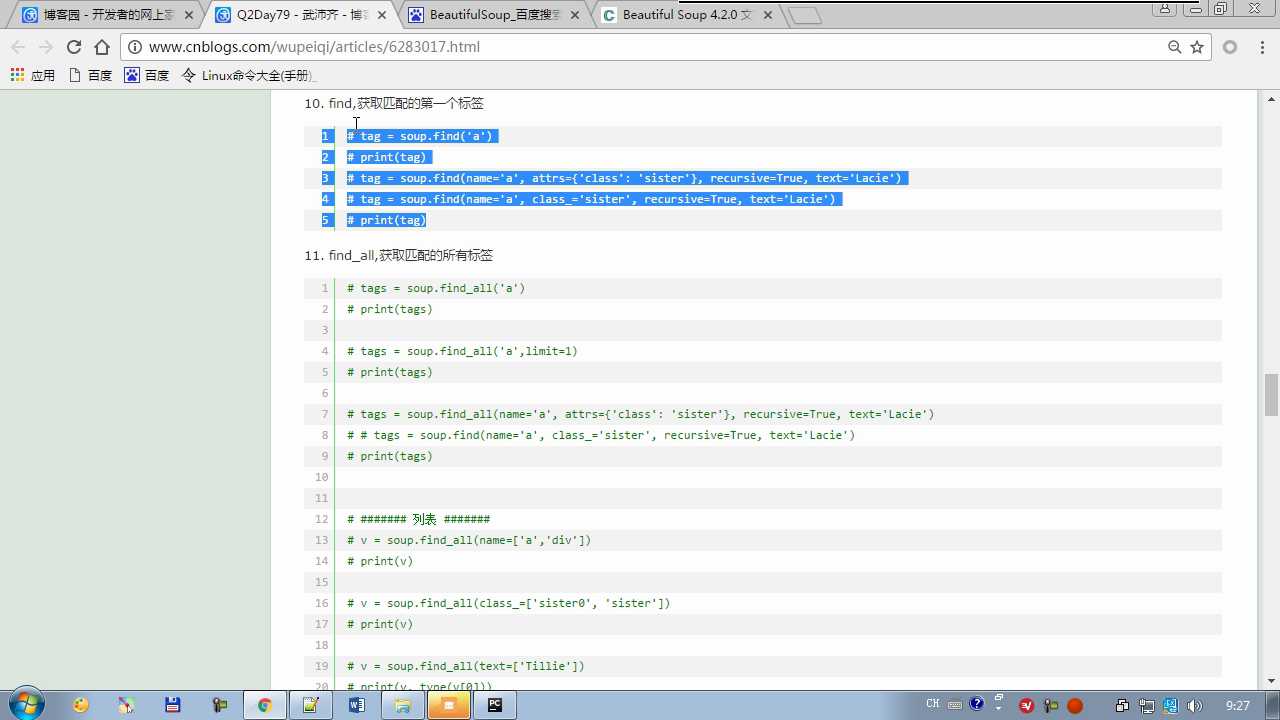
recursive=True 是否递归去找
soup.find(class_=‘ ‘) class写在attrs外面要加下划线避免与定义类class关键字冲突
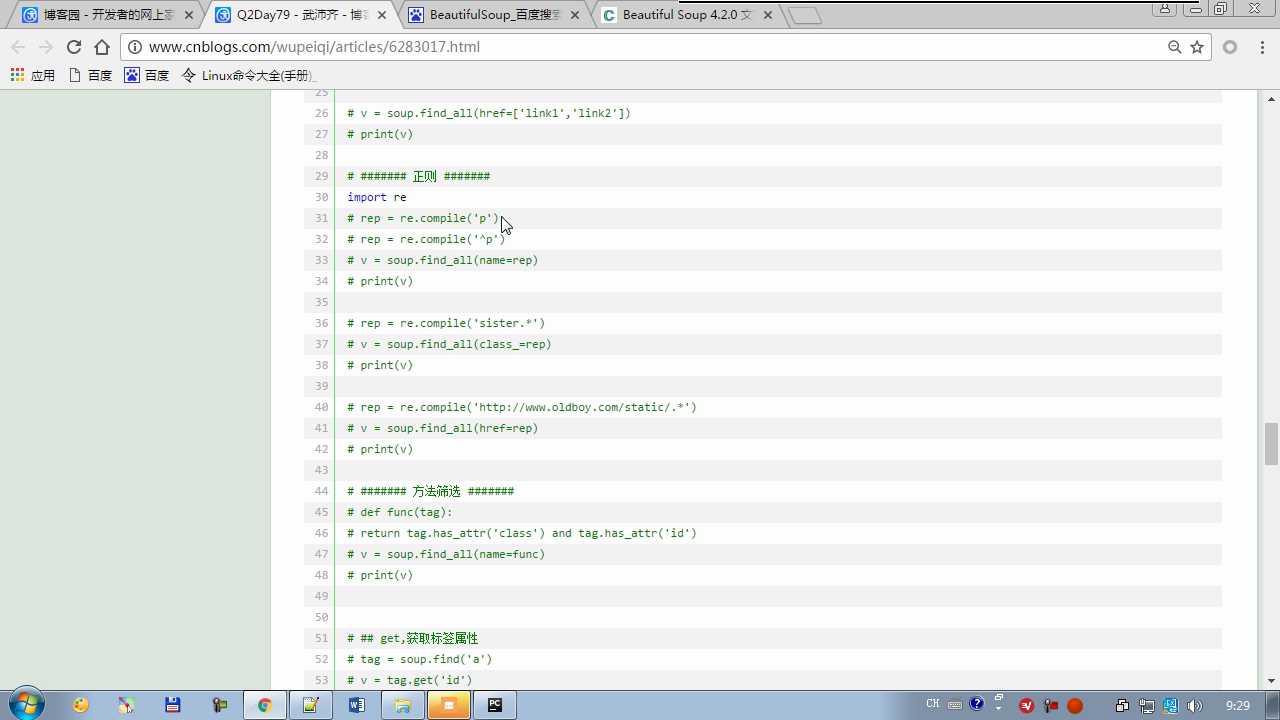
. 是通配符除了换行符 \\n
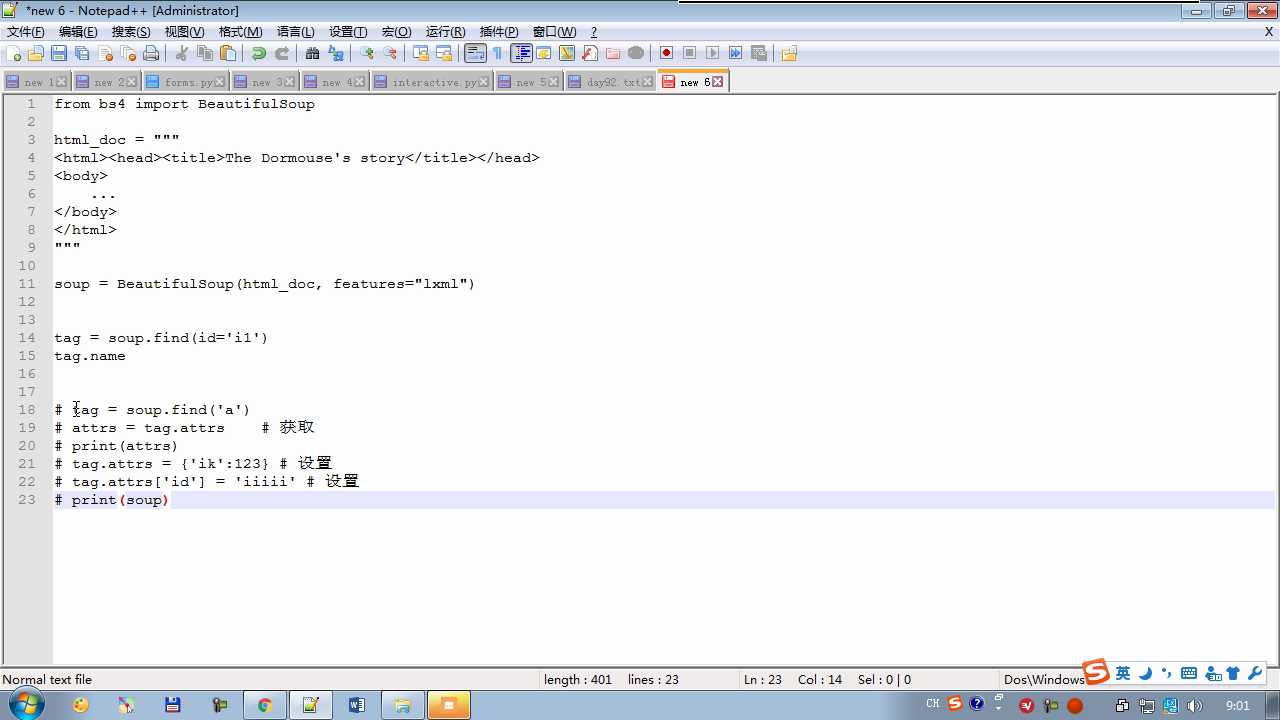
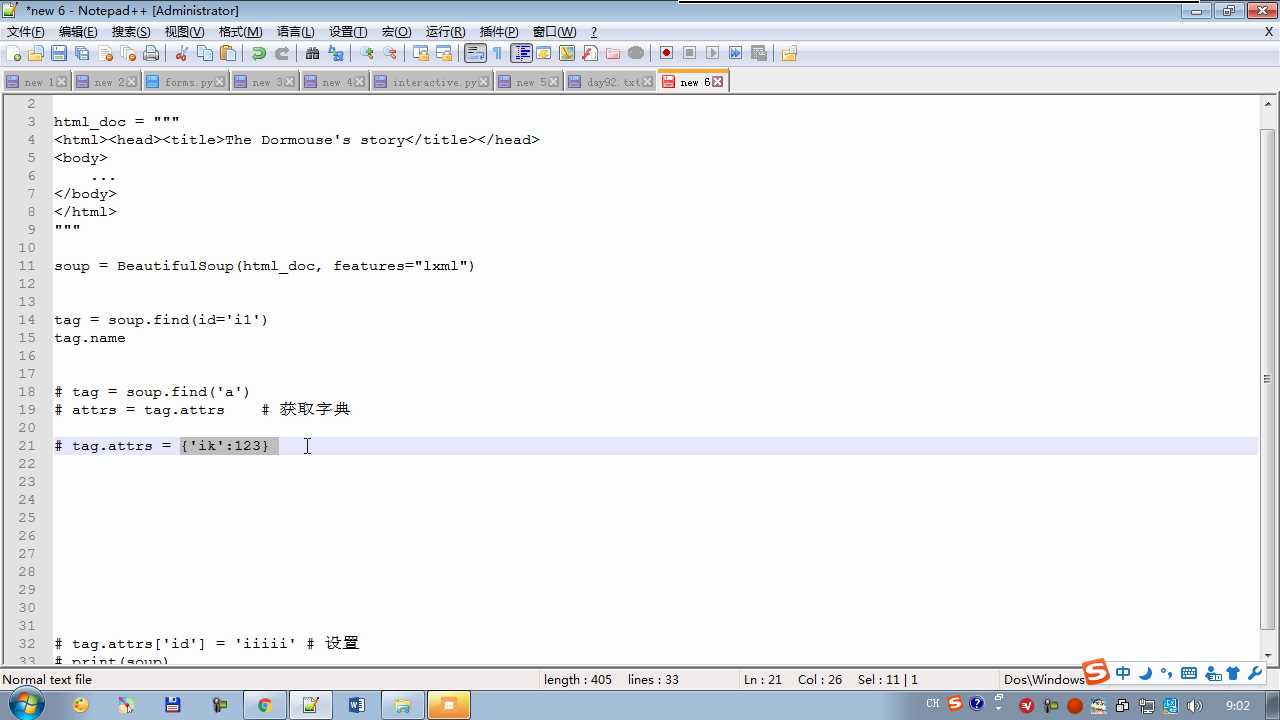
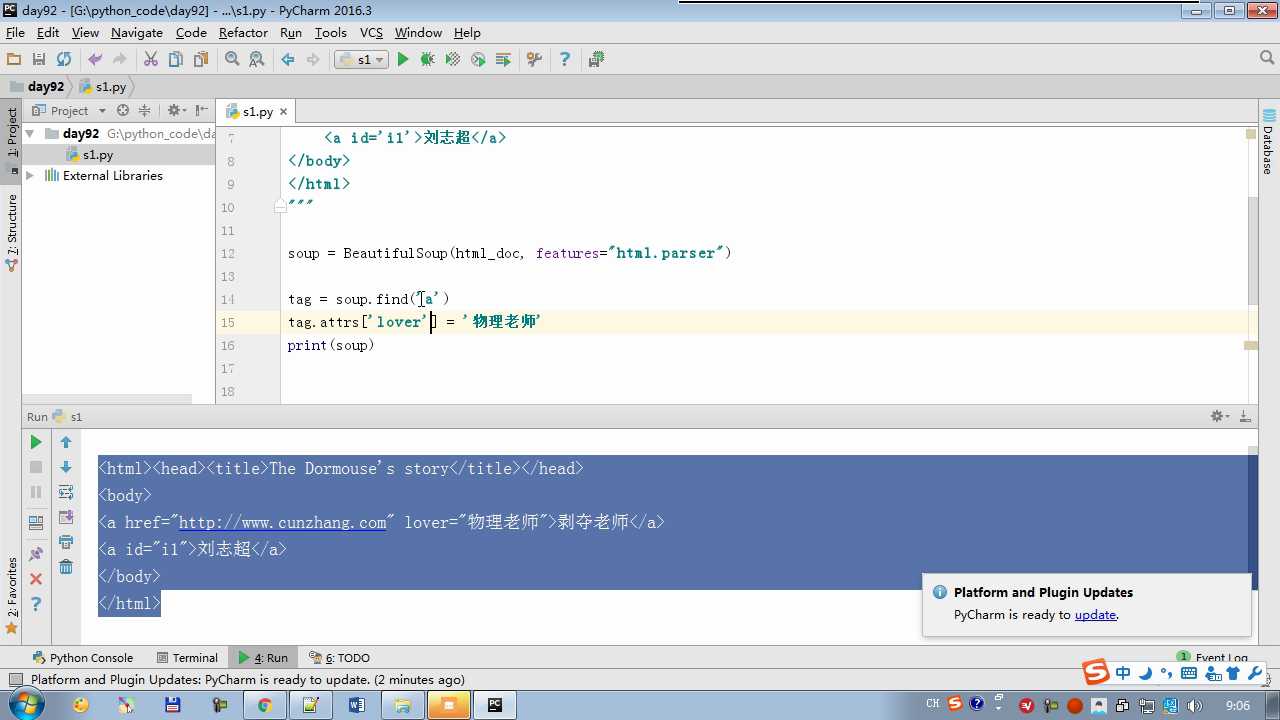
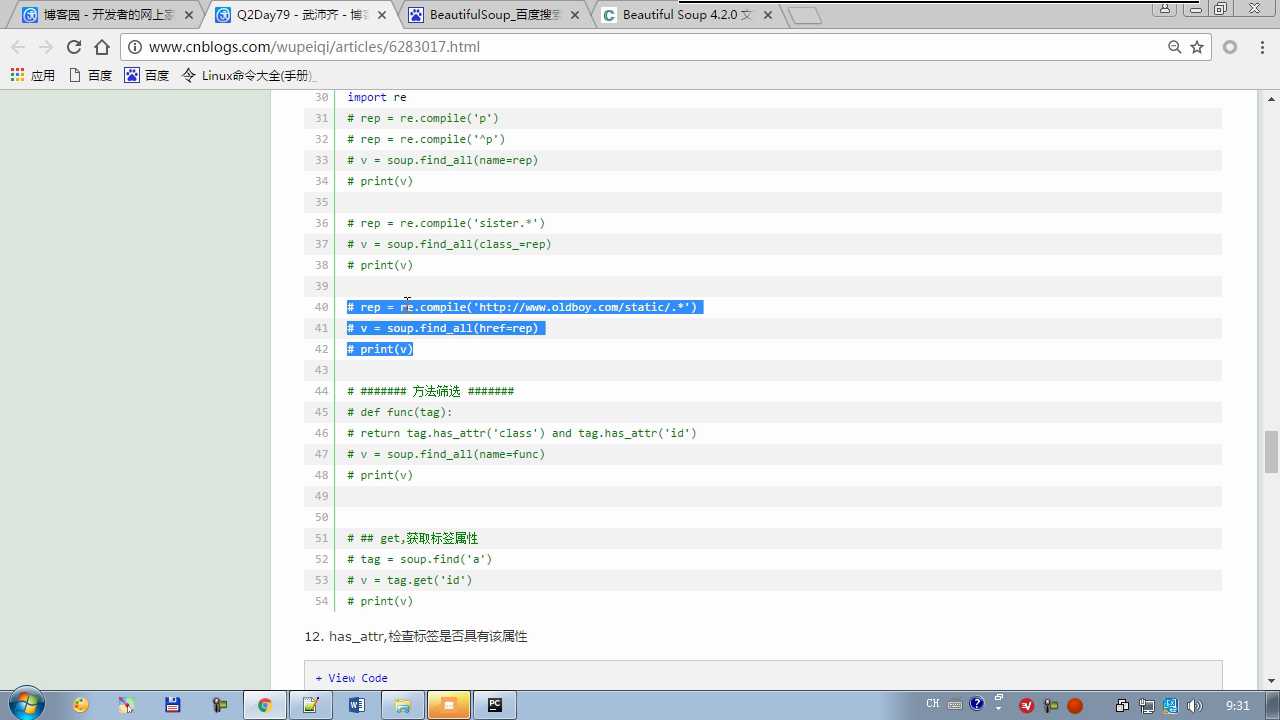
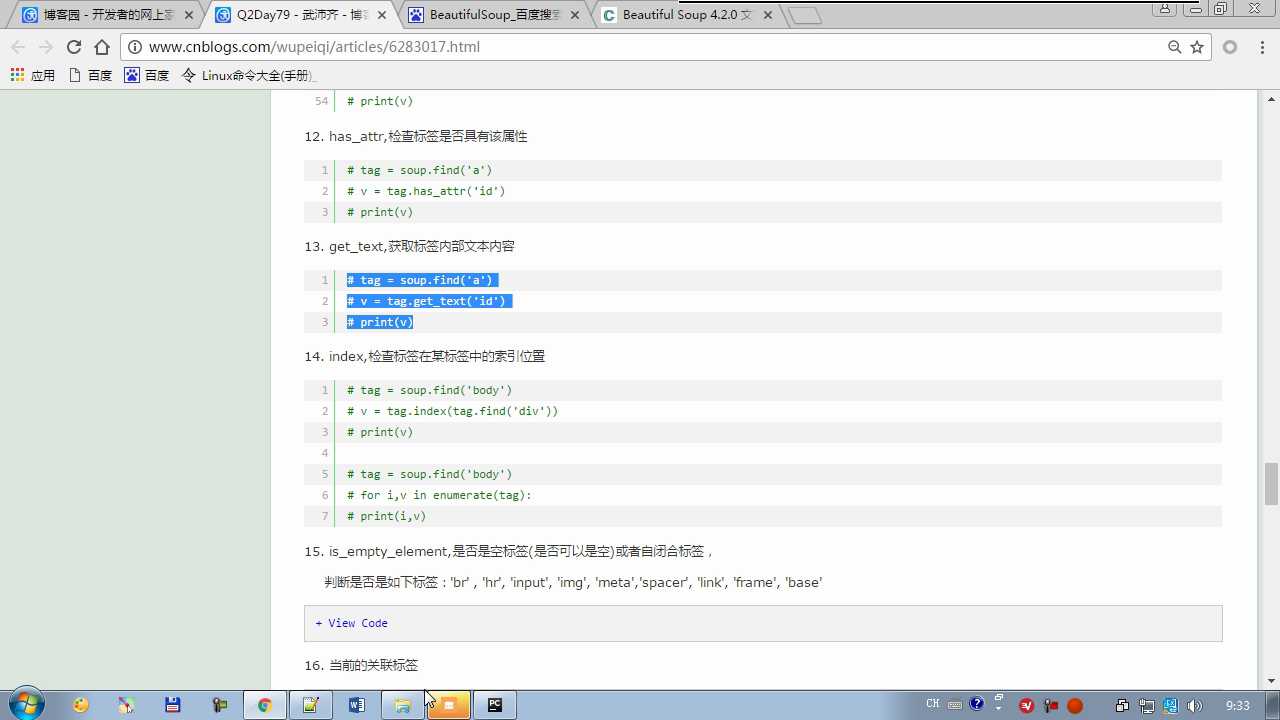
tag.get(‘ id ‘) 获取标签属性
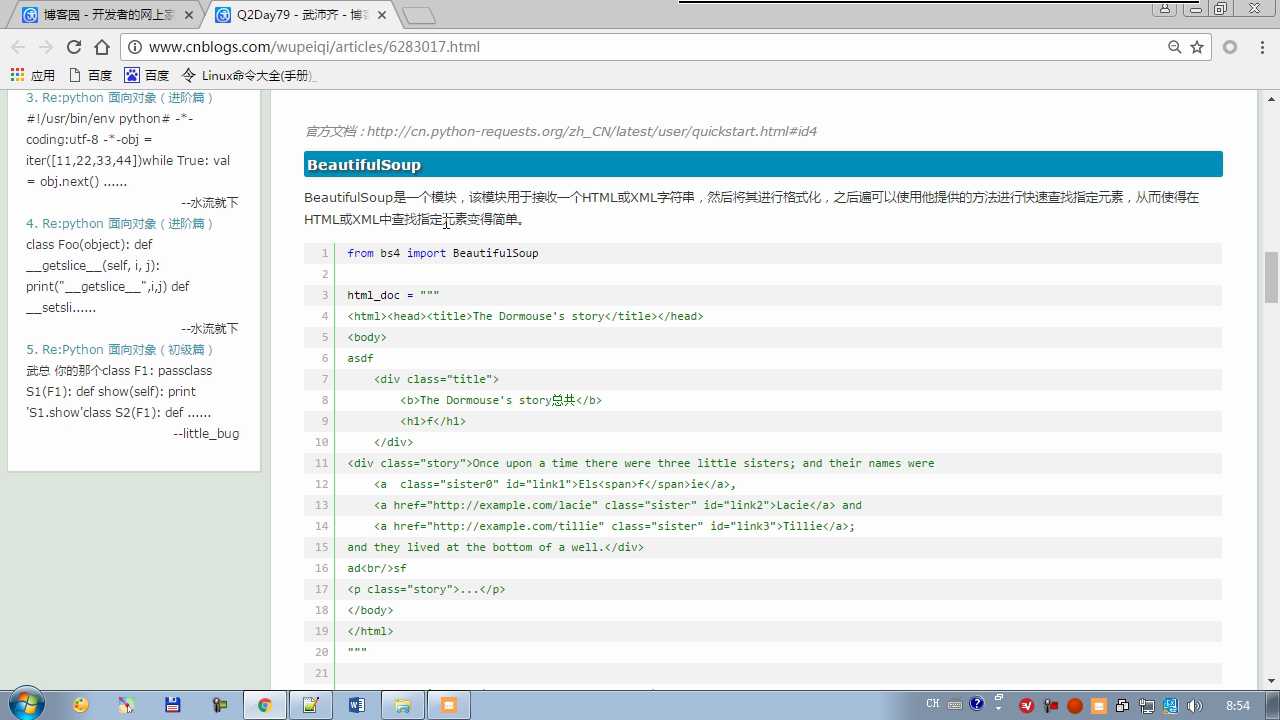
www.cnblogs.com/wupeiqi/articles/6283017.html
is_empty_element 是否空标签或自闭合标签
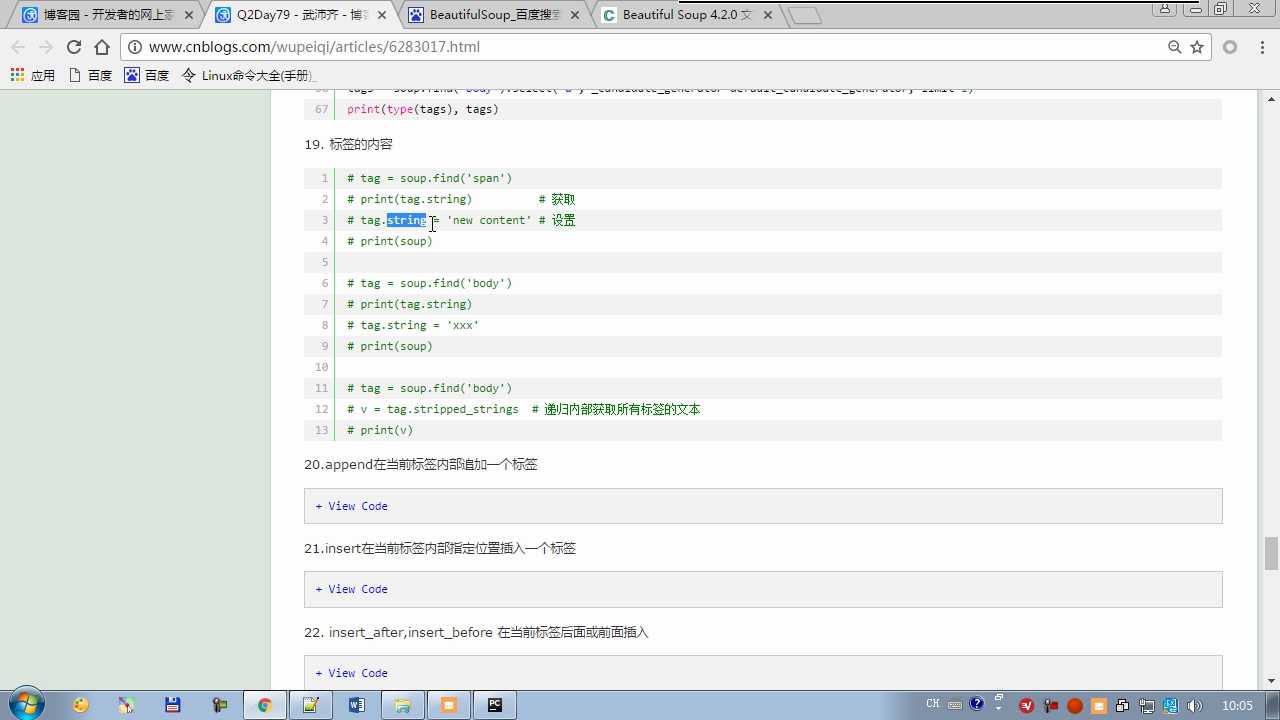
tag.string 不仅可以获取还能修改,标签内容
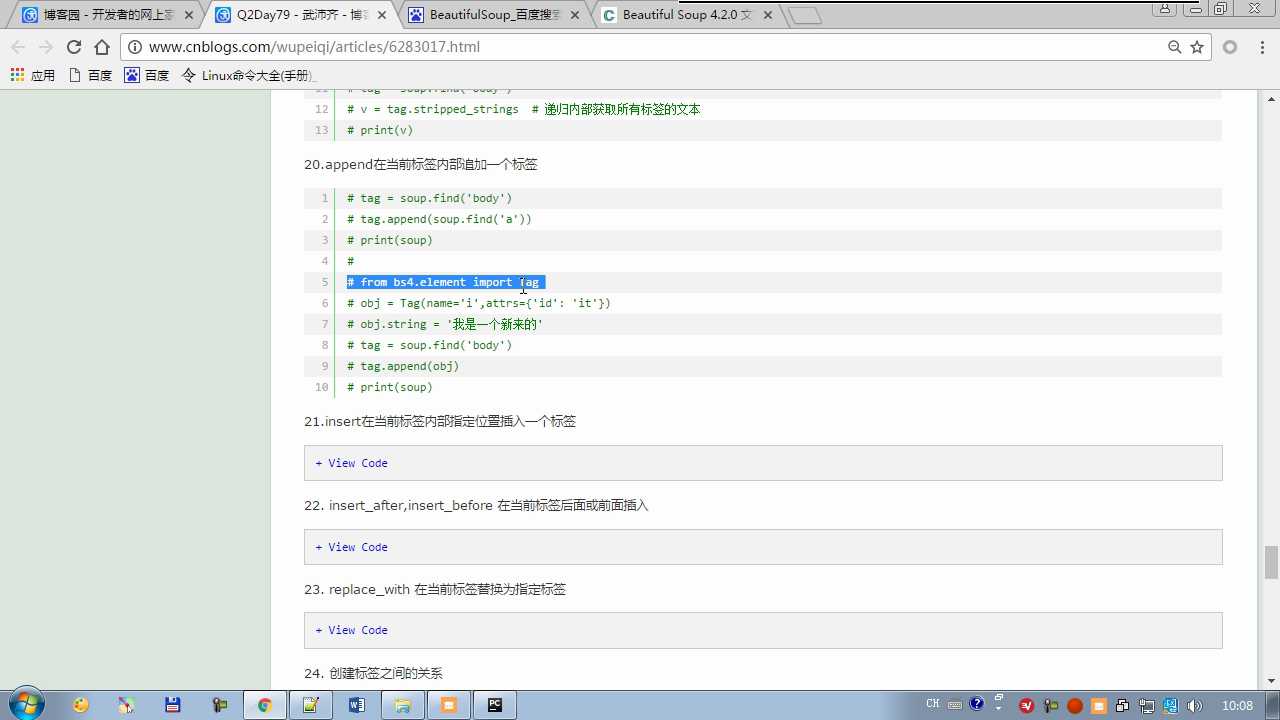
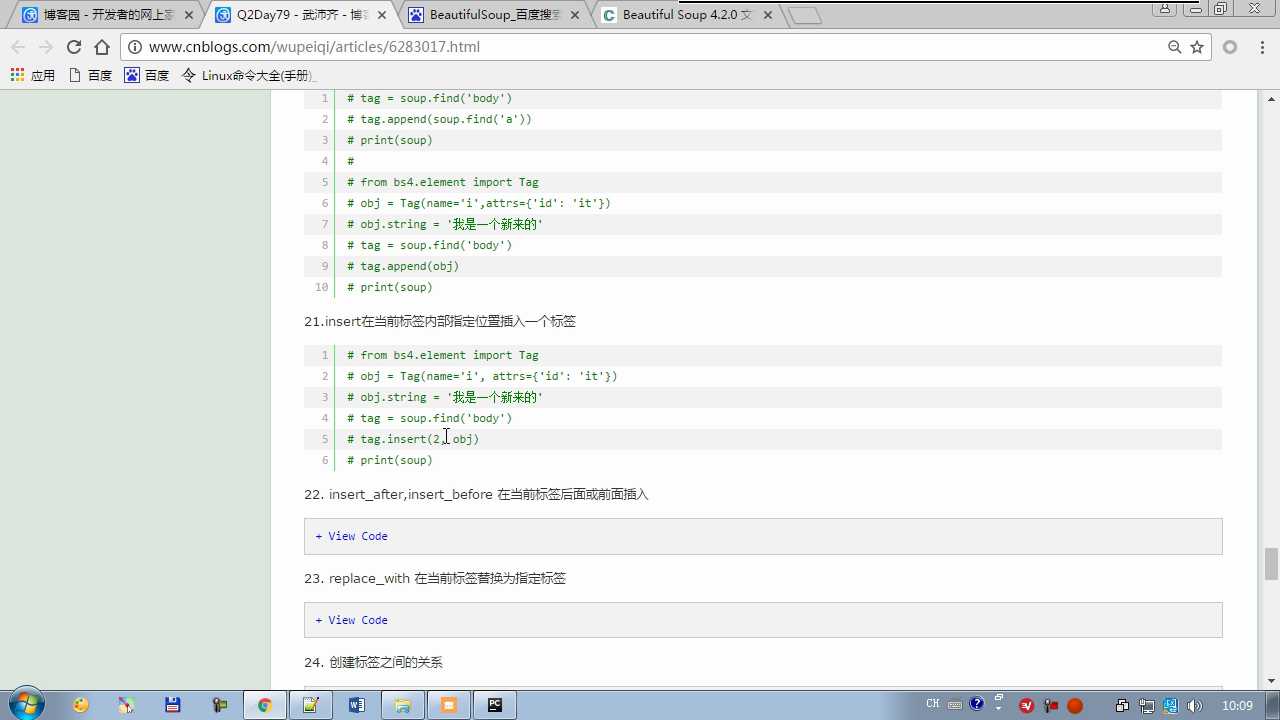
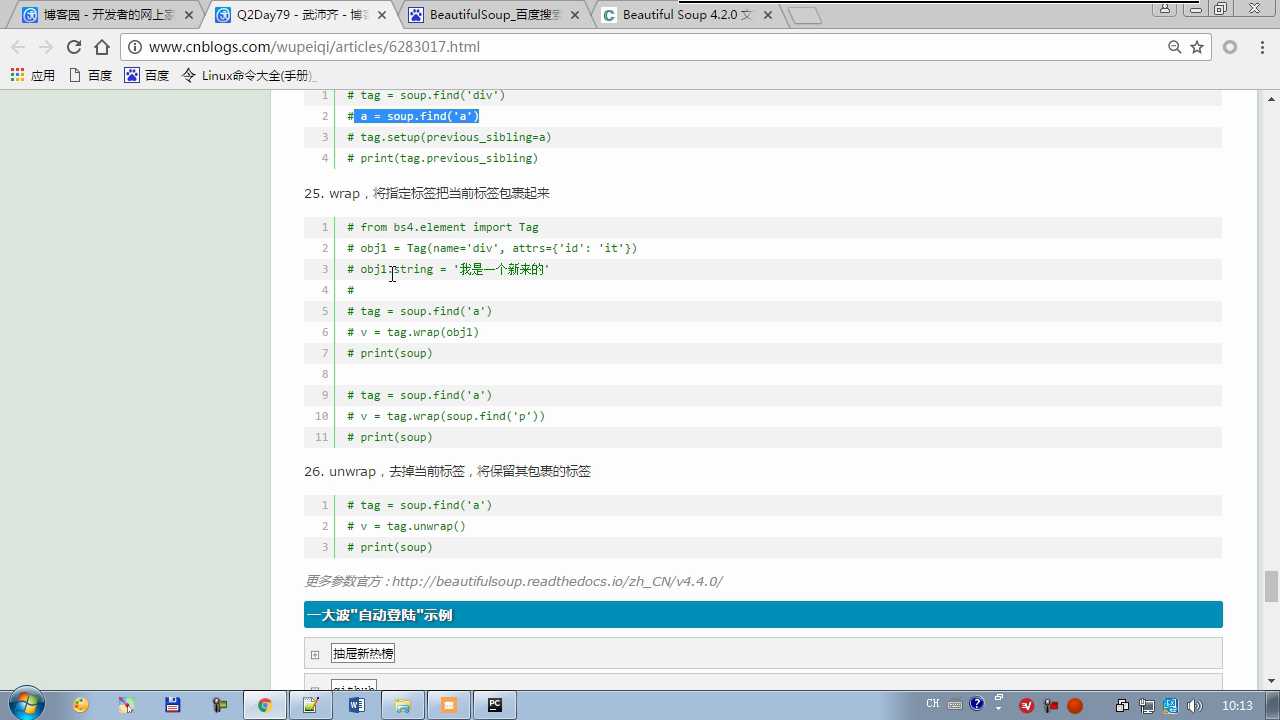
创建标签:obj=Tag(name=‘div‘,attrs=‘id‘:‘it‘)
jquery.cuishifeng.cn jquery方法大全
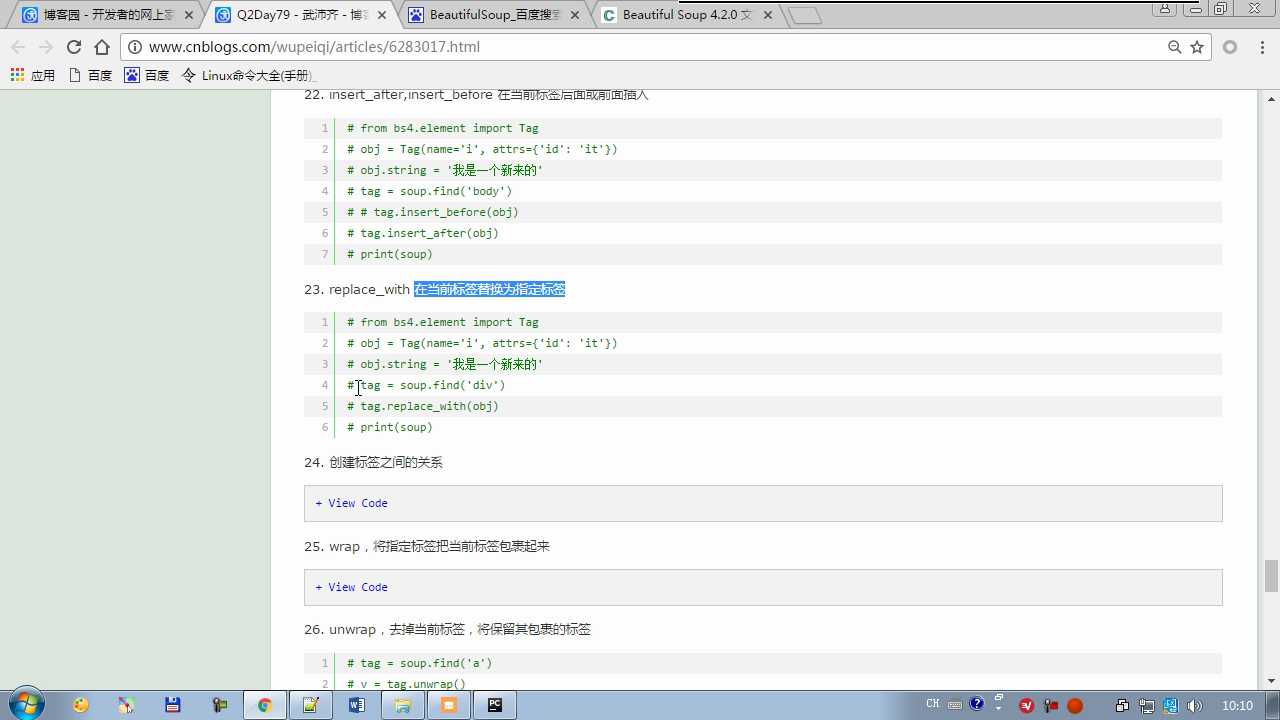
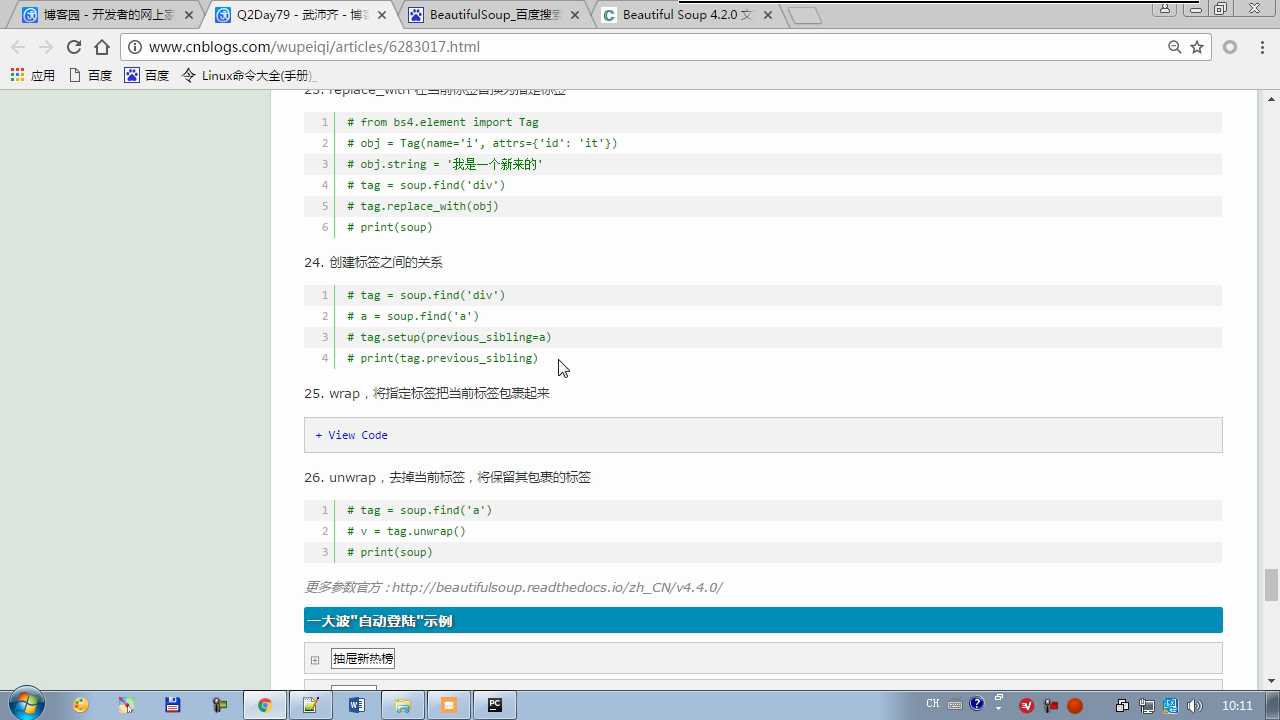
tag.wrap(obj) 将obj把tag标签包裹起来
tag.unwrap() 去掉当前标签,保留其包裹的标签
以上是关于BeautifulSoup模块详细介绍的主要内容,如果未能解决你的问题,请参考以下文章