Spark RDD使用详解1--RDD原理
Posted guohecang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark RDD使用详解1--RDD原理相关的知识,希望对你有一定的参考价值。
RDD简介
在集群背后,有一个非常重要的分布式数据架构,即弹性分布式数据集(Resilient Distributed Dataset,RDD)。RDD是Spark的最基本抽象,是对分布式内存的抽象使用,实现了以操作本地集合的方式来操作分布式数据集的抽象实现。RDD是Spark最核心的东西,它表示已被分区,不可变的并能够被并行操作的数据集合,不同的数据集格式对应不同的RDD实现。RDD必须是可序列化的。RDD可以cache到内存中,每次对RDD数据集的操作之后的结果,都可以存放到内存中,下一个操作可以直接从内存中输入,省去了MapReduce大量的磁盘IO操作。这对于迭代运算比较常见的机器学习算法, 交互式数据挖掘来说,效率提升比较大。
(1)RDD的特点
1)创建:只能通过转换 ( transformation ,如map/filter/groupBy/join 等,区别于动作 action) 从两种数据源中创建 RDD 1 )稳定存储中的数据; 2 )其他 RDD。
2)只读:状态不可变,不能修改。
3)分区:支持使 RDD 中的元素根据那个 key 来分区 ( partitioning ) ,保存到多个结点上。还原时只会重新计算丢失分区的数据,而不会影响整个系统。
4)路径:在 RDD 中叫世族或血统 ( lineage ) ,即 RDD 有充足的信息关于它是如何从其他 RDD 产生而来的。
5)持久化:支持将会被重用的 RDD 缓存 ( 如 in-memory 或溢出到磁盘 )。
6)延迟计算: Spark 也会延迟计算 RDD ,使其能够将转换管道化 (pipeline transformation)。
7)操作:丰富的转换(transformation)和动作 ( action ) , count/reduce/collect/save 等。
执行了多少次transformation操作,RDD都不会真正执行运算(记录lineage),只有当action操作被执行时,运算才会触发。
(2)RDD的好处
1)RDD只能从持久存储或通过Transformations操作产生,相比于分布式共享内存(DSM)可以更高效实现容错,对于丢失部分数据分区只需根据它的lineage就可重新计算出来,而不需要做特定的Checkpoint。
2)RDD的不变性,可以实现类Hadoop MapReduce的推测式执行。
3)RDD的数据分区特性,可以通过数据的本地性来提高性能,这不Hadoop MapReduce是一样的。
4)RDD都是可序列化的,在内存不足时可自动降级为磁盘存储,把RDD存储于磁盘上,这时性能会有大的下降但不会差于现在的MapReduce。
5)批量操作:任务能够根据数据本地性 (data locality) 被分配,从而提高性能。
(3)RDD的内部属性
通过RDD的内部属性,用户可以获取相应的元数据信息。通过这些信息可以支持更复杂的算法或优化。
1)分区列表:通过分区列表可以找到一个RDD中包含的所有分区及其所在地址。
2)计算每个分片的函数:通过函数可以对每个数据块进行RDD需要进行的用户自定义函数运算。
3)对父RDD的依赖列表,依赖还具体分为宽依赖和窄依赖,但并不是所有的RDD都有依赖。
4)可选:key-value型的RDD是根据哈希来分区的,类似于mapreduce当中的Paritioner接口,控制key分到哪个reduce。
5)可选:每一个分片的优先计算位置(preferred locations),比如HDFS的block的所在位置应该是优先计算的位置。(存储的是一个表,可以将处理的分区“本地化”)
//只计算一次
protected def getPartitions: Array[Partition]
//对一个分片进行计算,得出一个可遍历的结果
def compute(split: Partition, context: TaskContext): Iterator[T]
//只计算一次,计算RDD对父RDD的依赖
protected def getDependencies: Seq[Dependency[_]] = deps
//可选的,分区的方法,针对第4点,类似于mapreduce当中的Paritioner接口,控制key分到哪个reduce
@transient val partitioner: Option[Partitioner] = None
//可选的,指定优先位置,输入参数是split分片,输出结果是一组优先的节点位置
protected def getPreferredLocations(split: Partition): Seq[String] = Nil (4)RDD的存储与分区
1)用户可以选择不同的存储级别存储RDD以便重用。
2)当前RDD默认是存储于内存,但当内存不足时,RDD会spill到disk。
3)RDD在需要进行分区把数据分布于集群中时会根据每条记录Key进行分区(如Hash 分区),以此保证两个数据集在Join时能高效。
RDD根据useDisk、useMemory、useOffHeap、deserialized、replication参数的组合定义了以下存储级别:
//存储等级定义:
val NONE = new StorageLevel(false, false, false, false)
val DISK_ONLY = new StorageLevel(true, false, false, false)
val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2)
val MEMORY_ONLY = new StorageLevel(false, true, false, true)
val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2)
val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false)
val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2)
val MEMORY_AND_DISK = new StorageLevel(true, true, false, true)
val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2)
val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false)
val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2)
val OFF_HEAP = new StorageLevel(false, false, true, false) (5)RDD的容错机制
RDD的容错机制实现分布式数据集容错方法有两种:数据检查点和记录更新,RDD采用记录更新的方式:记录所有更新点的成本很高。所以,RDD只支持粗颗粒变换,即只记录单个块(分区)上执行的单个操作,然后创建某个RDD的变换序列(血统 lineage)存储下来;变换序列指,每个RDD都包含了它是如何由其他RDD变换过来的以及如何重建某一块数据的信息。因此RDD的容错机制又称“血统”容错。 要实现这种“血统”容错机制,最大的难题就是如何表达父RDD和子RDD之间的依赖关系。实际上依赖关系可以分两种,窄依赖和宽依赖。窄依赖:子RDD中的每个数据块只依赖于父RDD中对应的有限个固定的数据块;宽依赖:子RDD中的一个数据块可以依赖于父RDD中的所有数据块。例如:map变换,子RDD中的数据块只依赖于父RDD中对应的一个数据块;groupByKey变换,子RDD中的数据块会依赖于多块父RDD中的数据块,因为一个key可能分布于父RDD的任何一个数据块中, 将依赖关系分类的两个特性:第一,窄依赖可以在某个计算节点上直接通过计算父RDD的某块数据计算得到子RDD对应的某块数据;宽依赖则要等到父RDD所有数据都计算完成之后,并且父RDD的计算结果进行hash并传到对应节点上之后才能计算子RDD。第二,数据丢失时,对于窄依赖只需要重新计算丢失的那一块数据来恢复;对于宽依赖则要将祖先RDD中的所有数据块全部重新计算来恢复。所以在“血统”链特别是有宽依赖的时候,需要在适当的时机设置数据检查点。也是这两个特性要求对于不同依赖关系要采取不同的任务调度机制和容错恢复机制。
(6)Spark计算工作流
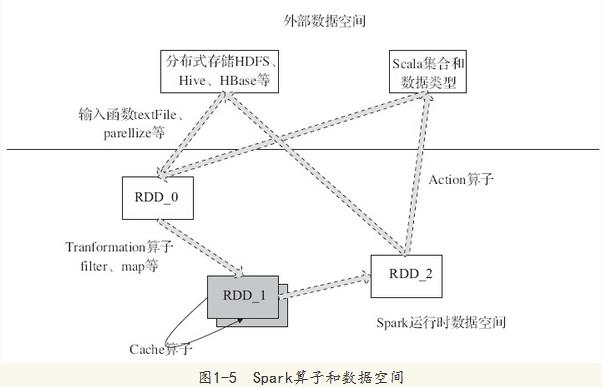
图1-5中描述了Spark的输入、运行转换、输出。在运行转换中通过算子对RDD进行转换。算子是RDD中定义的函数,可以对RDD中的数据进行转换和操作。
·输入:在Spark程序运行中,数据从外部数据空间(例如,HDFS、Scala集合或数据)输入到Spark,数据就进入了Spark运行时数据空间,会转化为Spark中的数据块,通过BlockManager进行管理。
·运行:在Spark数据输入形成RDD后,便可以通过变换算子fliter等,对数据操作并将RDD转化为新的RDD,通过行动(Action)算子,触发Spark提交作业。如果数据需要复用,可以通过Cache算子,将数据缓存到内存。
·输出:程序运行结束数据会输出Spark运行时空间,存储到分布式存储中(如saveAsTextFile输出到HDFS)或Scala数据或集合中(collect输出到Scala集合,count返回Scala Int型数据)。