python线程同步
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python线程同步相关的知识,希望对你有一定的参考价值。
一 概念线程同步,线程间协同,通过某种技术,让一个线程访问某些数据时,其他线程不能访问这个数据,直到该线程完成对数据的操作为止。
临界区(critical section 所有碰到的都不能使用,等一个使用完成),互斥量(Mutex一个用一个不能用),信号量(semaphore),事件event
二 event
1 概念
event 事件。是线程间通信机制中最简单的实现,使用一个内部标记的flag,通过flag的True或False的变化来进行操作。
2 参数详解
| 名称 | 含义 |
|---|---|
| set() | 标记设置为True,用于后面wait执行和is_set检查 |
| clear() | 标记设置为False |
| is_set() | 标记是否为True |
| wait(timeout=None) | 设置等待标记为True的时长,None为无限等待,等到返回为True,未等到了超时返回为False |
3 相关实例
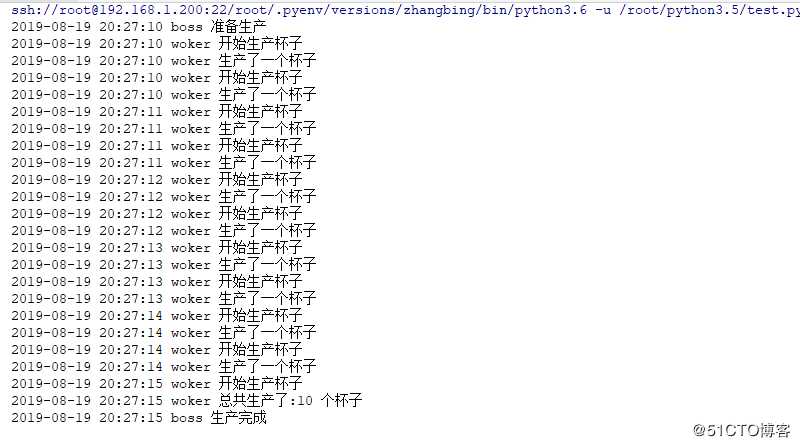
老板雇佣了一个工人,让他生产杯子,老板一直等着工人。直到生成了10个杯子
import logging
import threading
import time
event=threading.Event()
FORMAT="%(asctime)s %(threadName)s %(message)s"
logging.basicConfig(level=logging.INFO,format=FORMAT,datefmt="%Y-%m-%d %H:%M:%S")
def boss(event:threading.Event):
logging.info("准备生产")
event.wait()
logging.info("生产完成")
def woker(event:threading.Event,count:int=10):
cups=[]
while True:
logging.info("开始生产杯子")
if len(cups) >= count:
event.set()
break
logging.info("生产了一个杯子")
cups.append(1)
time.sleep(0.5)
logging.info("总共生产了: 个杯子".format(len(cups)))
b=threading.Thread(target=boss,args=(event,),name=‘boss‘)
w=threading.Thread(target=woker,args=(event,10),name=‘woker‘)
b.start()
w.start()结果如下
4 wait 使用
import logging
import threading
import datetime
event=threading.Event()
FORMAT="%(asctime)s %(threadName)s %(message)s"
logging.basicConfig(level=logging.INFO,format=FORMAT,datefmt="%Y-%m-%d %H:%M:%S")
def do(event:threading.Event,interval:int):
while not event.wait(interval): # 此处需要的结果是返回False或True
logging.info(‘do sth.‘)
e=threading.Event()
start=datetime.datetime.now()
threading.Thread(target=do,args=(e,3)).start()
e.wait(10)
e.set()
print ("整体运行时间为:".format((datetime.datetime.now()-start).total_seconds()))
print (‘main exit‘)结果如下

wait 优于sleep,wait 会主动让出时间片,其他线程可以被调度,而sleep会占用时间片不让出。
5 Timer 实现
import logging
import threading
import datetime
import time
event=threading.Event()
FORMAT="%(asctime)s %(threadName)s %(message)s"
logging.basicConfig(level=logging.INFO,format=FORMAT,datefmt="%Y-%m-%d %H:%M:%S")
def add(x:int,y:int):
return x+y
class Timer:
def __init__(self,interval,fn,*args,**kwargs):
self.interval=interval
self.fn=fn
self.args=args
self.kwargs=kwargs
self.event=threading.Event()
def __run(self):
start=datetime.datetime.now()
logging.info(‘开始启动步骤‘)
event.wait(self.interval) #在此处等待此时间后返回为False
if not self.event.is_set(): # 此处返回为False 为正常
self.fn(*self.args,**self.kwargs)
logging.info("函数执行成功,执行时间为".format((datetime.datetime.now()-start).total_seconds()))
def start(self):
threading.Thread(target=self.__run()).start()
def cancel(self):
self.event.set()
t=Timer(3,add,10,20)
t.start()结果如下

6 总结:
使用同一个event对象标记flag
谁wait就是等待flag变为True,或者等到超时返回False,不限制等待的个数。
三 线程同步之lock
1 简介
lock: 锁,凡是在共享资源争抢的地方都可以使用,从而保证只有一个使用者可以完全使用这个资源。一旦线程获取到锁,其他试图获取的锁的线程将被阻塞。
2 参数详解
| 名称 | 含义 |
|---|---|
| acquire(blocking=True,timeout=1) | 默认阻塞,阻塞可以设置超时时间,非阻塞时,timeout禁止设置,成功获取锁后,返回True,否则返回False |
| release() | 释放锁,可以从任何线程调用释放。已上锁的锁,会被重置为unlocked,未上锁的锁上调用,抛出RuntimeError异常 |
3 示例讲解
1 阻塞相关性质
#!/usr/bin/poython3.6
#conding:utf-8
import threading
import time
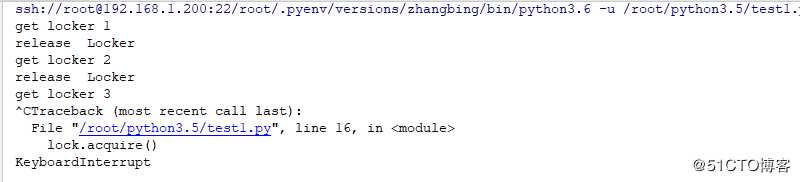
lock=threading.Lock() # 实例化锁对象
lock.acquire() # 加锁处理,默认是阻塞,阻塞时间可以设置,非阻塞时,timeout禁止设置,成功获取锁,返回True,否则返回False
print (‘get locker 1‘)
lock.release() # 释放锁,可以从任何线程调用释放,已上锁的锁,会被重置为unlocked未上锁的锁上调用,抛出RuntimeError异常。
print (‘release Locker‘)
lock.acquire()
print (‘get locker 2‘)
lock.release()
print (‘release Locker‘)
lock.acquire()
print (‘get locker 3‘)
lock.acquire() # 此处未进行相关的释放操作,因此其下面的代码将不能被执行,其会一直阻塞
print (‘get locker 4‘)结果如下
#!/usr/bin/poython3.6
#conding:utf-8
import threading
lock=threading.Lock()
lock.acquire()
print (‘1‘)
lock.release()
print (‘2‘)
lock.release() # 此处二次调用释放,导致的结果是抛出异常。
print (‘3‘)结果如下

2 阻塞总结
锁释放后资源一定会出现争抢情况,锁一定要支持上下文,否则所有的线程都将等待。
锁的注意事项是最好不要出现死锁的情况。
解不开的锁就是死锁。
此处是没有退出的情况的
4 实例
1 题目
订单要求生成100个杯子,组织10人生产
不加锁的情况下
2 通过flag 来进行相关的控制操作
import logging
import threading
import time
FORMAT="%(asctime)s %(threadName)s %(message)s"
logging.basicConfig(level=logging.INFO,format=FORMAT,datefmt="%Y-%m-%d %H:%M:%S")
cups=[]
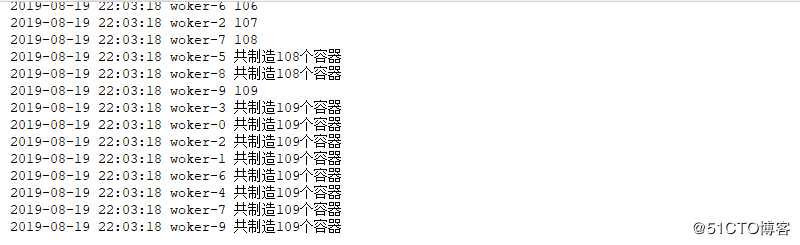
def worker(task=100):
flag=False
while True:
count = len(cups)
logging.info(len(cups))
if count >= task:
flag=True
time.sleep(0.001)
if not flag:
cups.append(1)
if flag:
break
logging.info("共制造个容器".format(len(cups)))
for i in range(10): #此处起10个线程,表示10个工人
threading.Thread(target=worker,args=(100,),name="woker-".format(i)).start()结果如下
3 通过直接判断的方式进行处理
import logging
import threading
FORMAT="%(asctime)s %(threadName)s %(message)s"
logging.basicConfig(level=logging.INFO,format=FORMAT,datefmt="%Y-%m-%d %H:%M:%S")
cups=[]
def worker(task=100):
while True:
count = len(cups)
logging.info(len(cups))
if count >= task:
break
cups.append(1)
logging.info("".format(threading.current_thread().name))
logging.info("共制造个容器".format(len(cups)))
for i in range(10): #此处起10个线程,表示10个工人
threading.Thread(target=worker,args=(100,),name="woker-".format(i)).start()结果如下
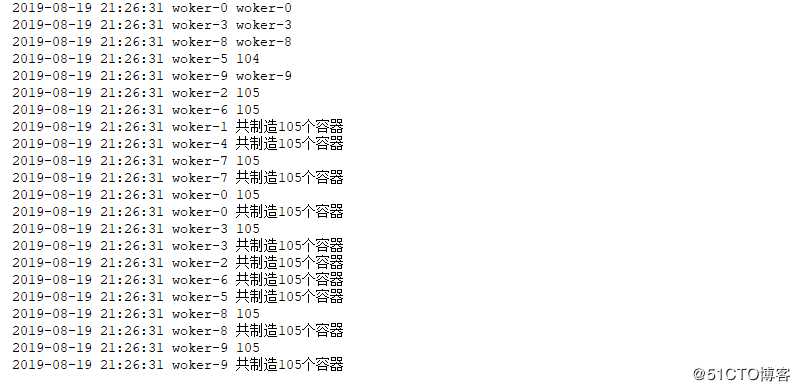
使用上述方式会导致多线程数据同步产生问题,进而导致产生的数据不准确。
4 加锁的情况处理
import logging
import threading
FORMAT="%(asctime)s %(threadName)s %(message)s"
logging.basicConfig(level=logging.INFO,format=FORMAT,datefmt="%Y-%m-%d %H:%M:%S")
cups=[]
Lock=threading.Lock()
def worker(lock:threading.Lock,task=100):
while True:
lock.acquire()
count = len(cups)
logging.info(len(cups))
if count >= task:
break # 此处保证每个线程执行完成会自动退出,否则会阻塞其他线程的继续执行
cups.append(1)
lock.release() # 释放锁
logging.info("".format(threading.current_thread().name))
logging.info("共制造个容器".format(len(cups)))
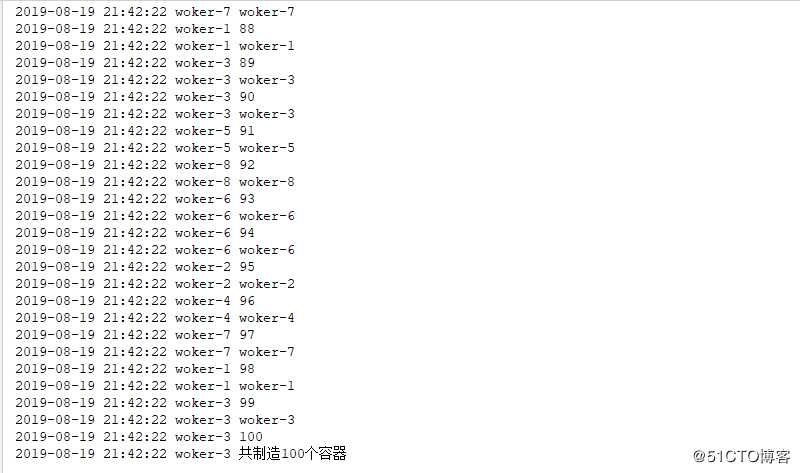
for i in range(10): #此处起10个线程,表示10个工人
threading.Thread(target=worker,args=(Lock,100,),name="woker-".format(i)).start()结果如下
5 线程换和CPU时间片
import logging
import threading
import time
FORMAT="%(asctime)s %(threadName)s %(message)s"
logging.basicConfig(level=logging.INFO,format=FORMAT,datefmt="%Y-%m-%d %H:%M:%S")
class Counter:
def __init__(self):
self.__x=0
def add(self):
self.__x+=1
def sub(self):
self.__x-=1
@property
def value(self):
return self.__x
def run(c:Counter,count=100): # 此处的100是执行100次,
for _ in range(count):
for i in range(-50,50):
if i<0:
c.sub()
else:
c.add()
c=Counter()
c1=1000
c2=10
for i in range(c1):
t=threading.Thread(target=run,args=(c,c2,))
t.start()
time.sleep(10)
print (c.value)结果如下

import logging
import threading
import time
FORMAT="%(asctime)s %(threadName)s %(message)s"
logging.basicConfig(level=logging.INFO,format=FORMAT,datefmt="%Y-%m-%d %H:%M:%S")
class Counter:
def __init__(self):
self.__x=0
def add(self):
self.__x+=1
def sub(self):
self.__x-=1
@property
def value(self):
return self.__x
def run(c:Counter,count=100): # 此处的100是执行100次,
for _ in range(count):
for i in range(-50,50):
if i<0:
c.sub()
else:
c.add()
c=Counter()
c1=10
c2=10000
for i in range(c1):
t=threading.Thread(target=run,args=(c,c2,))
t.start()
time.sleep(10)
print (c.value) #此处可能在未执行完成就进行了打印操作,可能造成延迟问题。结果如下

总结如下:
如果修改线程多少,则效果不明显,因为其函数执行时长和CPU分配的时间片相差较大,因此在时间片的时间内,足够完成相关的计算操作,但若是增加执行的循环次数,则可能会导致一个线程在一个时间片内未执行完成相关的计算,进而导致打印结果错误。
5 加锁和解锁:
1 加锁的必要性
一般来说加锁后还有一些代码实现,在释放锁之前还可能抛出一些异常,一旦出现异常,锁是无法释放的,但是当前线程可能因为这个异常被终止了,就会产生死锁,可通过上下文对出现异常的锁进行关闭操作。
2 加锁,解锁常用语句
1 使用try...finally语句保证锁的释放
2 with上下文管理,锁对象支持上下文管理源码如下:
其类中是支持enter和exit的,因此其是可以通过上下文管理来进行相关的锁关闭操作的。

3 使用try..finally 处理
import logging
import threading
import time
FORMAT="%(asctime)s %(threadName)s %(message)s"
logging.basicConfig(level=logging.INFO,format=FORMAT,datefmt="%Y-%m-%d %H:%M:%S")
class Counter:
def __init__(self):
self.__x=0
self.__lock=threading.Lock()
def add(self):
try:
self.__lock.acquire()
self.__x+=1
finally:
self.__lock.release() # 此处不管是否上述异常,此处都会执行
def sub(self):
try:
self.__lock.acquire()
self.__x-=1
finally:
self.__lock.release()
@property
def value(self):
return self.__x
def run(c:Counter,count=100): # 此处的100是执行100次,
for _ in range(count):
for i in range(-50,50):
if i<0:
c.sub()
else:
c.add()
c=Counter()
c1=10
c2=1000
for i in range(c1):
t=threading.Thread(target=run,args=(c,c2,))
t.start()
time.sleep(10)
print (c.value)结果如下

import logging
import threading
import time
FORMAT="%(asctime)s %(threadName)s %(message)s"
logging.basicConfig(level=logging.INFO,format=FORMAT,datefmt="%Y-%m-%d %H:%M:%S")
class Counter:
def __init__(self):
self.__x=0
self.__lock=threading.Lock()
def add(self):
try:
self.__lock.acquire()
self.__x+=1
finally:
self.__lock.release() # 此处不管是否上述异常,此处都会执行
def sub(self):
try:
self.__lock.acquire()
self.__x-=1
finally:
self.__lock.release()
@property
def value(self):
return self.__x
def run(c:Counter,count=100): # 此处的100是执行100次,
for _ in range(count):
for i in range(-50,50):
if i<0:
c.sub()
else:
c.add()
c=Counter()
c1=100
c2=10
for i in range(c1):
t=threading.Thread(target=run,args=(c,c2,))
t.start()
time.sleep(10)
print (c.value)结果如下

4 使用with上下文管理方式处理
import logging
import threading
import time
FORMAT="%(asctime)s %(threadName)s %(message)s"
logging.basicConfig(level=logging.INFO,format=FORMAT,datefmt="%Y-%m-%d %H:%M:%S")
class Counter:
def __init__(self):
self.__x=0
self.__lock=threading.Lock()
def add(self):
with self.__lock:
self.__x+=1
def sub(self):
with self.__lock:
self.__x-=1
@property
def value(self):
return self.__x
def run(c:Counter,count=100): # 此处的100是执行100次,
for _ in range(count):
for i in range(-50,50):
if i<0:
c.sub()
else:
c.add()
c=Counter()
c1=100
c2=10
for i in range(c1):
t=threading.Thread(target=run,args=(c,c2,))
t.start()
time.sleep(10)
print (c.value)结果如下

5 处理执行结果
通过存活线程数进行判断
import logging
import threading
import time
FORMAT="%(asctime)s %(threadName)s %(message)s"
logging.basicConfig(level=logging.INFO,format=FORMAT,datefmt="%Y-%m-%d %H:%M:%S")
class Counter:
def __init__(self):
self.__x=0
self.__lock=threading.Lock()
def add(self):
with self.__lock:
self.__x+=1
def sub(self):
with self.__lock:
self.__x-=1
@property
def value(self):
return self.__x
def run(c:Counter,count=100): # 此处的100是执行100次,
for _ in range(count):
for i in range(-50,50):
if i<0:
c.sub()
else:
c.add()
c=Counter()
c1=10
c2=1000
for i in range(c1):
t=threading.Thread(target=run,args=(c,c2,))
t.start()
while True:
time.sleep(1)
if threading.active_count()==1:
print (threading.enumerate())
print (c.value)
break
else:
print (threading.enumerate())结果如下 
5 非阻塞锁使用
1 简介
不阻塞,timeout没啥用,False表示不使用锁
非阻塞锁能提高效率,但可能导致数据不一致
2 示例
#!/usr/bin/poython3.6
#conding:utf-8
import threading
lock=threading.Lock()
lock.acquire()
print (‘1‘)
ret=lock.acquire(blocking=False)
print (ret)结果如下

3 相关实例
import logging
import threading
import time
FORMAT="%(asctime)s %(threadName)s %(message)s"
logging.basicConfig(level=logging.INFO,format=FORMAT,datefmt="%Y-%m-%d %H:%M:%S")
cups=[]
lock=threading.Lock()
def worker(lock:threading.Lock,task=100):
while True:
if lock.acquire(False): # 此处返回为False,则表示未成功获取到锁
count=len(cups)
logging.info(count)
if count >=task:
lock.release()
break
cups.append(1)
lock.release()
logging.info(" make1 ".format(threading.current_thread().name))
logging.info("".format(len(cups)))
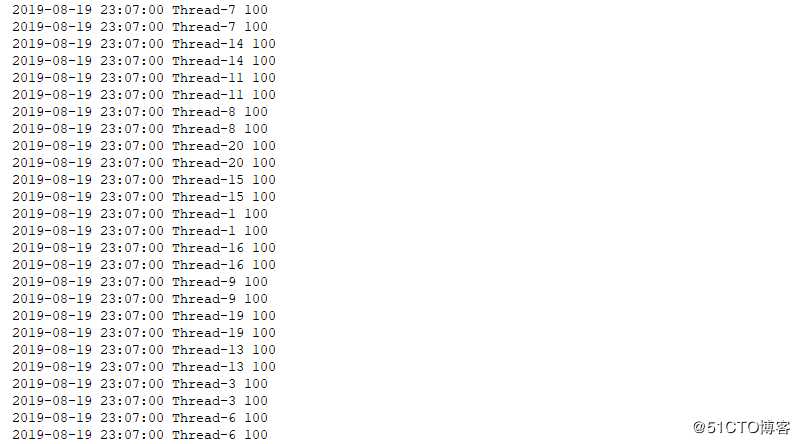
for x in range(20):
threading.Thread(target=worker,args=(lock,100)).start()结果如下
6 锁的应用场景
锁适用于访问和修改同一个共享资源的时候,及就是读取同一个资源的时候。
如果全部都是读取同一个资源,则不需要锁,因为读取不会导致其改变,因此没必要所用锁的注意事项:
少用锁,必要时用锁,多线程访问被锁定的资源时,就成了穿行访问,要么排队执行,要么争抢执行加锁的时间越短越好,不需要就立即释放锁
一定要避免死锁多线程运行模型(ATM机)
跟锁无关的尽量排列在后面,和锁区分开
四 线程同步之Rlock
1 简介
可重入锁,是线程相关的锁,线程A获得可重入锁,并可以多次成功获取,不会阻塞,最后在线程A 中做和acquire次数相同的release即可。
2 相关属性
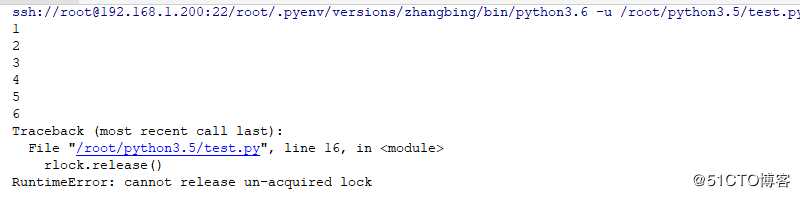
import threading
rlock=threading.RLock() #初始化可重用锁
rlock.acquire() #进行阻塞处理
print (‘1‘)
rlock.acquire()
print (‘2‘)
rlock.acquire(False) # 此处设置为非阻塞
print (‘3‘)
rlock.release()
print (‘4‘)
rlock.release()
print (‘5‘)
rlock.release()
print (‘6‘)
rlock.release() # 此处表示不能释放多余的锁,只能释放和加入锁相同次数
print (‘7‘)结果如下
不同线程对Rlock操作的结果
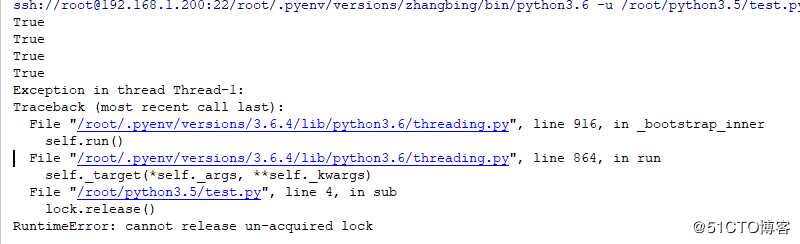
import threading
rlock=threading.RLock() #初始化可重用锁
def sub(lock:threading.RLock):
lock.release()
ret=rlock.acquire()
print (ret)
ret=rlock.acquire(timeout=5)
print (ret)
ret=rlock.acquire(False)
print (ret)
ret=rlock.acquire(False)
print (ret)
threading.Thread(target=sub,args=(rlock,)).start() # 此处是启用另一个线程来完成对上述的开启的锁的关闭,因为其是基于线程的,
#因此其必须在该线程中进行相关的处理操作,而不是在另外一个线程中进行解锁操作结果如下
3 总结:
跨线程的Rlock就没用了,必须使用Lock,Rlock是线程级别的,其他的锁都是可以在当前进程的另一个线程中进行加锁和解锁的。
五 线程同步之condition
1 简介
构造方法condition(lock=None),可传入一个Lock或Rlock,默认是Rlock。其主要应用于生产者消费者模型,为了解决生产者和消费者速度匹配的问题。
2 相关参数解析及相关源码
| 名称 | 含义 |
|---|---|
| acquire(*args) | 获取锁 |
| wait(self,timeout=None) | 等待或超时 |
| notify(n=1) | 唤醒至少指定数目个数的等待的线程,没有等待线程就没有任何操作 |
| notify_all() | 唤醒所有等待的线程 |
3 相关源码
def __init__(self, lock=None):
if lock is None:
lock = RLock() # 此处默认使用的是Rlock
self._lock = lock
# Export the lock‘s acquire() and release() methods
self.acquire = lock.acquire # 进行相关处理
self.release = lock.release
# If the lock defines _release_save() and/or _acquire_restore(),
# these override the default implementations (which just call
# release() and acquire() on the lock). Ditto for _is_owned().
try:
self._release_save = lock._release_save
except AttributeError:
pass
try:
self._acquire_restore = lock._acquire_restore
except AttributeError:
pass
try:
self._is_owned = lock._is_owned
except AttributeError:
pass
self._waiters = _deque()
def __enter__(self): # 此处定义了上下文管理的内容
return self._lock.__enter__()
def __exit__(self, *args): # 关闭锁操作
return self._lock.__exit__(*args)
def __repr__(self): # 此处实现了可视化相关的操作
return "<Condition(%s, %d)>" % (self._lock, len(self._waiters))其内部存储使用了_waiter 进行相关的处理,来对线程进行集中的放置操作。
def wait(self, timeout=None):
if not self._is_owned():
raise RuntimeError("cannot wait on un-acquired lock")
waiter = _allocate_lock()
waiter.acquire()
self._waiters.append(waiter) # 此处使用此方式存储锁
saved_state = self._release_save()
gotit = False
try: # restore state no matter what (e.g., KeyboardInterrupt)
if timeout is None:
waiter.acquire()
gotit = True
else:
if timeout > 0:
gotit = waiter.acquire(True, timeout)
else:
gotit = waiter.acquire(False)
return gotit
finally:
self._acquire_restore(saved_state)
if not gotit:
try:
self._waiters.remove(waiter)
except Value唤醒一个release
def notify(self, n=1):
if not self._is_owned(): # 此处是用于判断是否有锁
raise RuntimeError("cannot notify on un-acquired lock")
all_waiters = self._waiters
waiters_to_notify = _deque(_islice(all_waiters, n))
if not waiters_to_notify:
return
for waiter in waiters_to_notify:
waiter.release()
try:
all_waiters.remove(waiter)
except ValueError:
pass唤醒所有的所等待
def notify_all(self):
"""Wake up all threads waiting on this condition.
If the calling thread has not acquired the lock when this method
is called, a RuntimeError is raised.
"""
self.notify(len(self._waiters))
notifyAll = notify_all4 实现方式:
1 通过event进行相关处理
import threading
import random
import logging
logging.basicConfig(level=logging.INFO,format="%(asctime)s %(threadName)s %(message)s",datefmt="%Y-%m-%d %H:%M:%S")
class Dispather:
def __init__(self,x):
self.data=x
self.event=threading.Event()
def produce(self):# 生产者
for i in range(10):
data=random.randint(1,100)
self.data=data # 产生数据
self.event.wait(1) #此处用于一秒产生一个数据
def custom(self): # 消费者,消费者可能有多个
while True:
logging.info(self.data) # 获取生产者生产的数据
self.event.wait(0.5) # 此处用于等待0.5s产生一个数据
d=Dispather(0)
p=threading.Thread(target=d.produce,name=‘produce‘)
c=threading.Thread(target=d.custom,name=‘custom‘)
p.start()
c.start()

此处会使得产生的数据只有一个,而消费者拿到的数据却有两份,此处是由消费者来控制其拿出的步骤的。
2 使用Condition 处理方式
import threading
import random
import logging
logging.basicConfig(level=logging.INFO,format="%(asctime)s %(threadName)s %(message)s",datefmt="%Y-%m-%d %H:%M:%S")
class Dispather:
def __init__(self,x):
self.data=x
self.event=threading.Event()
self.conition=threading.Condition()
def produce(self):# 生产者
for i in range(10):
data=random.randint(1,100)
with self.conition: #此处用于先进行上锁处理,然后最后释放锁
self.data=data # 产生数据
self.conition.notify_all() #通知,此处表示有等待线程就通知处理
self.event.wait(1) #此处用于一秒产生一个数据
def custom(self): # 消费者,消费者可能有多个
while True:
with self.conition:
self.conition.wait() # 此处用于等待notify产生的数据
logging.info(self.data) # 获取生产者生产的数据
self.event.wait(0.5) # 此处用于等待0.5s产生一个数据
d=Dispather(0)
p=threading.Thread(target=d.produce,name=‘produce‘)
c=threading.Thread(target=d.custom,name=‘custom‘)
p.start()
c.start()
此处是由生产者产生数据,通知给消费者,然后消费者再进行拿取,
有时候可能需要多一点的消费者,来保证生产者无库存
import threading
import random
import logging
logging.basicConfig(level=logging.INFO,format="%(asctime)s %(threadName)s %(message)s",datefmt="%Y-%m-%d %H:%M:%S")
class Dispather:
def __init__(self,x):
self.data=x
self.event=threading.Event()
self.conition=threading.Condition()
def produce(self):# 生产者
for i in range(10):
data=random.randint(1,100)
with self.conition: #此处用于先进行上锁处理,然后最后释放锁
self.data=data # 产生数据
self.conition.notify_all() #通知,通知处理产生的数据
self.event.wait(1) #此处用于一秒产生一个数据
def custom(self): # 消费者,消费者可能有多个
while True:
with self.conition:
self.conition.wait() # 此处用于等待notify产生的数据
logging.info(self.data) # 获取生产者生产的数据
self.event.wait(0.5) # 此处用于等待0.5s产生一个数据
d=Dispather(0)
p=threading.Thread(target=d.produce,name=‘produce‘)
c1=threading.Thread(target=d.custom,name=‘custom-1‘)
c2=threading.Thread(target=d.custom,name=‘custom-2‘)
p.start()
c1.start()
c2.start()结果如下
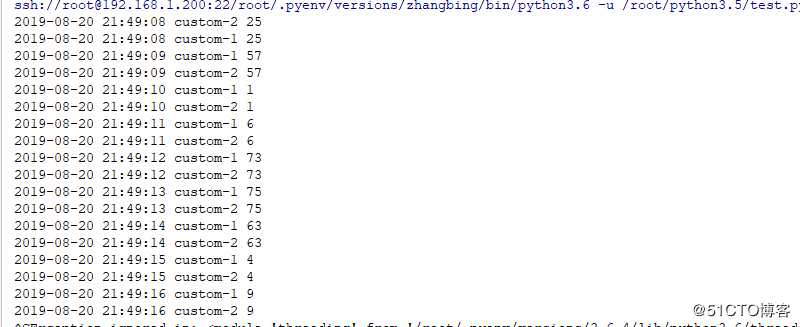
因为此默认是基于线程的锁,因此其产生另一个消费者并不会影响当前消费者的操作,因此可以拿到两份生产得到的数据。
import threading
import random
import logging
logging.basicConfig(level=logging.INFO,format="%(asctime)s %(threadName)s %(message)s",datefmt="%Y-%m-%d %H:%M:%S")
class Dispather:
def __init__(self,x):
self.data=x
self.event=threading.Event()
self.conition=threading.Condition()
def produce(self):# 生产者
for i in range(10):
data=random.randint(1,100)
with self.conition: #此处用于先进行上锁处理,然后最后释放锁
self.data=data # 产生数据
self.conition.notify(2) #通知两个线程来处理数据
self.event.wait(1) #此处用于一秒产生一个数据
def custom(self): # 消费者,消费者可能有多个
while True:
with self.conition:
self.conition.wait() # 此处用于等待notify产生的数据
logging.info(self.data) # 获取生产者生产的数据
self.event.wait(0.5) # 此处用于等待0.5s产生一个数据
d=Dispather(0)
p=threading.Thread(target=d.produce,name=‘produce‘)
p.start()
for i in range(5): # 此处用于配置5个消费者,
threading.Thread(target=d.custom,name="c-".format(i)).start()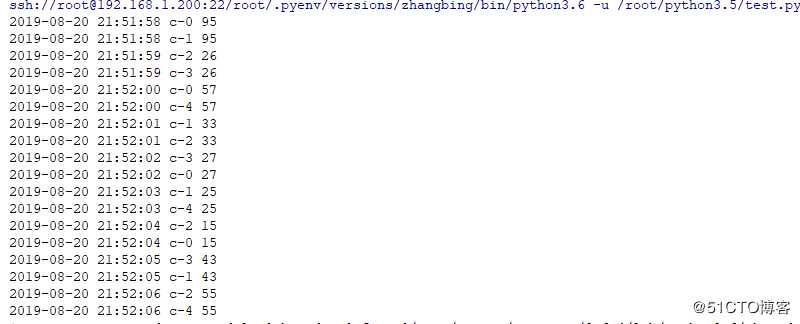
import threading
import random
import logging
logging.basicConfig(level=logging.INFO,format="%(asctime)s %(threadName)s %(message)s",datefmt="%Y-%m-%d %H:%M:%S")
class Dispather:
def __init__(self,x):
self.data=x
self.event=threading.Event()
self.conition=threading.Condition()
def produce(self):# 生产者
for i in range(10):
data=random.randint(1,100)
with self.conition: #此处用于先进行上锁处理,然后最后释放锁
self.data=data # 产生数据
self.conition.notify(5) #通知全部线程来处理数据
self.event.wait(1) #此处用于一秒产生一个数据
def custom(self): # 消费者,消费者可能有多个
while True:
with self.conition:
self.conition.wait() # 此处用于等待notify产生的数据
logging.info(self.data) # 获取生产者生产的数据
self.event.wait(0.5) # 此处用于等待0.5s产生一个数据
d=Dispather(0)
p=threading.Thread(target=d.produce,name=‘produce‘)
p.start()
for i in range(5): # 此处用于配置5个消费者,
threading.Thread(target=d.custom,name="c-".format(i)).start()结果如下
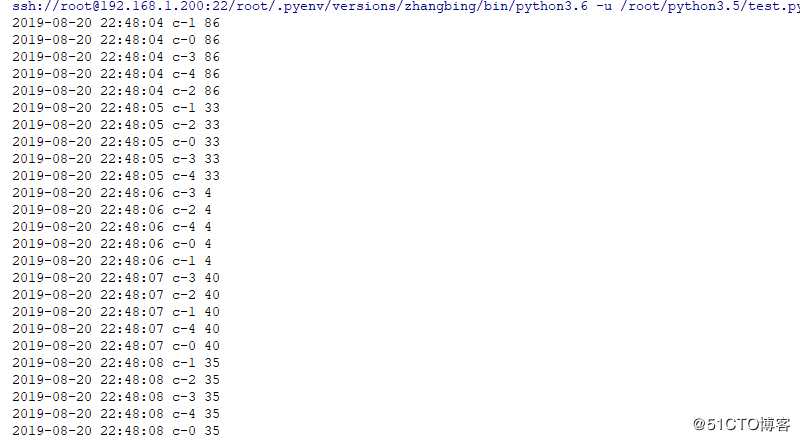
注: 上述实例中。程序本身不是线程安全的,程序逻辑有很多瑕疵,但是可以很好的帮助理解condition的使用,和生产者消费者模式
轮循太消耗CPU时间了
5 Condition 总结
condition 用于生产者消费者模型中,解决生产者消费者速度匹配的问题
采用了通知机制,非常有效率
使用方式
使用condition,必须先acquire,用完了要release,因为内部使用了锁,默认是Rlock,最好的方式使用with上下文。消费者wait,等待通知
生产者生产好消息,对消费者发送消息,可以使用notifiy或者notify_all方法。
六 线程同步之 barrier
1 简介
赛马模式,并行初始化,多线程并行初始化
有人翻译为栅栏,有人称为屏障,可以想象为路障,道闸
python3.2 中引入的新功能
2 相关参数详解
| 名称 | 含义 |
|---|---|
| Barrier(parties,action=None,timeout=None) | 构建 barrier对象,指定参与方数目,timeout是wait方法未指定超时的默认值 |
| n_waiting | 当前在屏障中等待的线程数 |
| parties | 各方数,需要多少等待 |
| wait(timeout=None) | 等待通过屏障,返回0到线程-1的整数,每个线程返回不同,如果wait方法设置了超时,并超时发送,屏障将处于broken状态 |
3 相关参数详解
import threading
import random
import logging
logging.basicConfig(level=logging.INFO,format="%(asctime)s %(threadName)s %(message)s",datefmt="%Y-%m-%d %H:%M:%S")
def worker(barrier:threading.Barrier):
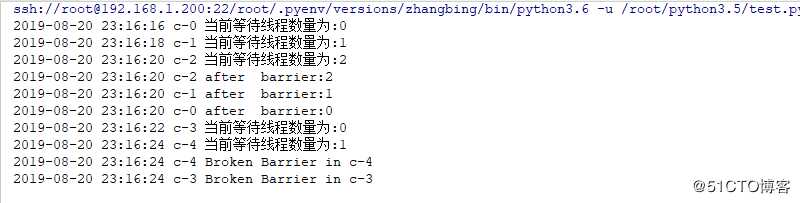
logging.info("当前等待线程数量为:".format(barrier.n_waiting))
# 此处一旦到了第三个线程,则其会直接向下执行,而可能不是需要重新等待第一个等待的线程顺序执行
try:
bid=barrier.wait() # 此处只有3个线程都存在的情况下才会直接执行下面的,否则会一直等待
logging.info("after barrier:".format(bid))
except threading.BrokenBarrierError:
logging.info("Broken Barrier in ".format(threading.current_thread().name))
barrier=threading.Barrier(parties=3) # 三个线程释放一次
for x in range(3): # 此处表示产生3个线程
threading.Event().wait(2)
threading.Thread(target=worker,args=(barrier,),name="c-".format(x)).start()结果如下

产生的线程不是等待线程的倍数
import threading
import random
import logging
logging.basicConfig(level=logging.INFO,format="%(asctime)s %(threadName)s %(message)s",datefmt="%Y-%m-%d %H:%M:%S")
def worker(barrier:threading.Barrier):
logging.info("当前等待线程数量为:".format(barrier.n_waiting))
# 此处一旦到了第三个线程,则其会直接向下执行,而可能不是需要重新等待第一个等待的线程顺序执行
try:
bid=barrier.wait() # 此处只有3个线程都存在的情况下才会直接执行下面的,否则会一直等待
logging.info("after barrier:".format(bid))
except threading.BrokenBarrierError:
logging.info("Broken Barrier in ".format(threading.current_thread().name))
barrier=threading.Barrier(parties=3) # 三个线程释放一次
for x in range(4): # 此处表示产生4个线程,则会有一个一直等待
threading.Event().wait(2)
threading.Thread(target=worker,args=(barrier,),name="c-".format(x)).start()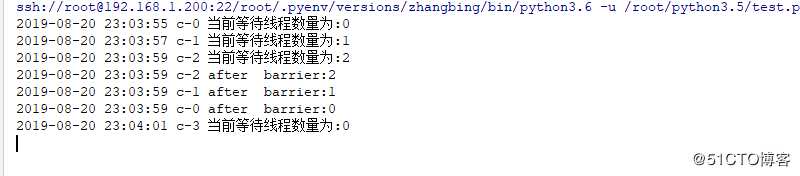
其第4个线程会一直等待下去,直到有3个线程在等待的同时才进行下一步操作。
从运行结果来看,所有线程冲到了barrier前等待,直到parties的数目,屏障将会打开,所有线程停止等待,继续执行
再有wait,屏障就就绪等待达到参数数目时再放行
4 barrier 实例的相关属性
| 参数 | 含义 |
|---|---|
| broken | 如果屏障处于打破状态,则返回True |
| abort() | 将屏障处于broken状态,等待中的线程或调用等待方法的线程都会抛出BrokenbarrierError异常,直到reset方法来恢复屏障 |
| reset() | 恢复屏障,重新开始拦截 |
import threading
import logging
logging.basicConfig(level=logging.INFO,format="%(asctime)s %(threadName)s %(message)s",datefmt="%Y-%m-%d %H:%M:%S")
def worker(barrier:threading.Barrier):
logging.info("当前等待线程数量为:".format(barrier.n_waiting))
# 此处一旦到了第三个线程,则其会直接向下执行,而可能不是需要重新等待第一个等待的线程顺序执行
try:
bid=barrier.wait() # 此处只有3个线程都存在的情况下才会直接执行下面的,否则会一直等待
logging.info("after barrier:".format(bid))
except threading.BrokenBarrierError:
logging.info("Broken Barrier in ".format(threading.current_thread().name))
barrier=threading.Barrier(parties=3) # 三个线程释放一次
for x in range(5): # 此处表示产生5个线程
threading.Event().wait(2)
threading.Thread(target=worker,args=(barrier,),name="c-".format(x)).start()
if x==4:
barrier.abort() # 打破屏障,前三个没问题,后两个会导致屏障打破一起走出结果如下
import threading
import logging
logging.basicConfig(level=logging.INFO,format="%(asctime)s %(threadName)s %(message)s",datefmt="%Y-%m-%d %H:%M:%S")
def worker(barrier:threading.Barrier):
logging.info("当前等待线程数量为:".format(barrier.n_waiting))
# 此处一旦到了第三个线程,则其会直接向下执行,而可能不是需要重新等待第一个等待的线程顺序执行
try:
bid=barrier.wait() # 此处只有3个线程都存在的情况下才会直接执行下面的,否则会一直等待
logging.info("after barrier:".format(bid))
except threading.BrokenBarrierError:
logging.info("Broken Barrier in ".format(threading.current_thread().name))
barrier=threading.Barrier(parties=3) # 三个线程释放一次
for x in range(9): # 此处表示产生5个线程
if x==2: #此处第一个和第二个等到,等到了第三个直接打破,前两个和第三个一起都是打破输出
barrier.abort() # 打破屏障,前三个没问题,后两个会导致屏障打破一起走出
elif x==6: #x=6表示第7个,直到第6个,到第7个,第8个,第9个,刚好3个直接栅栏退出
barrier.reset()
threading.Event().wait(2)
threading.Thread(target=worker,args=(barrier,)).start()结果如下

5 barrier 应用
并发初始化
所有的线程都必须初始化完成后,才能继续工作,例如运行加载数据,检查,如果这些工作没有完成,就开始运行,则不能正常工作
10个线程做10种不同的工作准备,每个线程负责一种工作,只有这10个线程都完成后,才能继续工作,先完成的要等待后完成的线程。
如 启动了一个线程,需要先加载磁盘,缓存预热,初始化链接池等工作,这些工作可以齐头并进,只不过只有都满足了,程序才能继续向后执行,假设数据库链接失败,则初始化工作就会失败,就要about,屏蔽broken,所有线程收到异常后直接退出。
七 semaphore 信号量
1 简介
和Lock 很像,信号量对象内部维护一个倒计数器,每一次acquire都会减1,当acquire方法发现计数为0时就会阻塞请求的线程,直到其他线程对信号量release后,计数大于0,恢复阻塞的线程。
2 参数详解
| 名称 | 含义 |
|---|---|
| Semaphore(value=1) | 构造方法,value小于0,抛出ValueError异常 |
| acquire(blocking=True,timeout=None) | 获取信号量,计数器减1,获取成功返回为True |
| release() | 释放信号量,计数器加1 |
semaphore 默认值是1,表示只能去一个后就等待着,其相当于初始化一个值。
计数器中的数字永远不可能低于0
import threading
import logging
import time
logging.basicConfig(level=logging.INFO,format="%(asctime)s %(threadName)s %(message)s",datefmt="%Y-%m-%d %H:%M:%S")
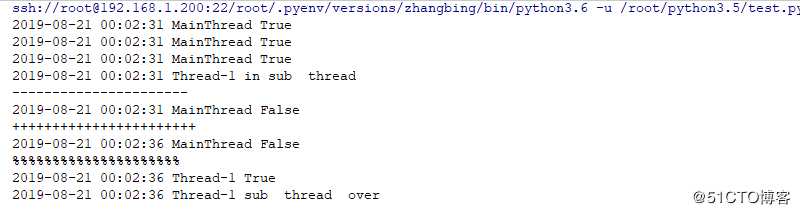
def woker(sem:threading.Semaphore):
logging.info("in sub thread")
logging.info(sem.acquire())
logging.info("sub thread over")
s=threading.Semaphore(3) # 初始化3个信号量
logging.info(s.acquire()) # 取出三个信号量
logging.info(s.acquire())
logging.info(s.acquire())
threading.Thread(target=woker,args=(s,)).start() # 此处若再想取出,则不能成功,则会阻塞
print (‘----------------------‘)
logging.info(s.acquire(False)) #此处表示不阻塞
print (‘+++++++++++++++++++++++‘)
time.sleep(2)
logging.info(s.acquire(timeout=3)) # 此处表示阻塞超时3秒后释放
print (‘%%%%%%%%%%%%%%%%%%%%%‘)
s.release() # 此处用于对上述线程中的调用的函数中的内容进行处理结果如下
都是针对同一个对象进行的处理
3 应用举例
1 连接池
import logging
logging.basicConfig(level=logging.INFO,format="%(asctime)s %(threadName)s %(message)s",datefmt="%Y-%m-%d %H:%M:%S")
class Name:
def __init__(self,name):
self.name=name
class Pool:
def __init__(self,count=3):
self.count=count
self.pool=[ Name("conn-".format(i)) for i in range(3)] # 初始化链接
def get_conn(self):
if len(self.pool)>0:
data=self.pool.pop() # 从尾部拿出来一个
logging.info(data)
else:
return None
def return_conn(self,name:Name): # 此处添加一个
self.pool.append(name)
pool=Pool(3)
pool.get_conn()
pool.get_conn()
pool.get_conn()
pool.return_conn(Name(‘aaa‘))
pool.get_conn()结果如下

2 锁机制进行处理链连接池
import logging
import threading
import random
logging.basicConfig(level=logging.INFO,format="%(asctime)s %(threadName)s %(message)s",datefmt="%Y-%m-%d %H:%M:%S")
class Name:
def __init__(self,name):
self.name=name
class Pool:
def __init__(self,count=3):
self.count=count
self.sem=threading.Semaphore(count)
self.event=threading.Event()
self.pool=[ Name("conn-".format(i)) for i in range(count)]
def get_conn(self):
self.sem.acquire()
data=self.pool.pop()
return data
def return_conn(self,name:Name): # 此处添加一个
self.pool.append(name)
self.sem.release()
def woker(pool:Pool):
conn=pool.get_conn()
logging.info(conn)
threading.Event().wait(random.randint(1,4))
pool.return_conn(conn)
pool=Pool(3)
for i in range(8):
threading.Thread(target=woker,name="worker-".format(i),args=(pool,)).start()结果如下

上述实例中,使用信号量解决资源有限的问题,如果池中有资源,请求者获取资源时信号量减1,请求者只能等待,当使用者完全归资源后信号量加1,等待线程就可以唤醒拿走资源。
4 BoundedSemaphore
有界信号量,不允许使用release超出初始值范围,否则,抛出ValueError异常,这个用有界信号修改源代码,保证如果多return_conn 就会抛出异常,保证了归还链接抛出异常。
信号量一直release会一直向上加,其会将信号量和链接池都扩容了此处便产生了BoundedSemaphore
import logging
import threading
import random
logging.basicConfig(level=logging.INFO,format="%(asctime)s %(threadName)s %(message)s",datefmt="%Y-%m-%d %H:%M:%S")
s=threading.BoundedSemaphore(3) # 边界
s.acquire() # 此处需要拿取,否则不能直接向其中加
print (1)
s.release()
print (2)
s.release()
print (3)结果如下

应用如下
import logging
import threading
import time
logging.basicConfig(level=logging.INFO,format="%(asctime)s %(threadName)s %(message)s ")
class Conn:
def __init__(self,name):
self.name=name
class Pool:
def __init__(self,count=3):
self.count=count # 初始化链接池
self.sema=threading.BoundedSemaphore(count)
self.pool=[Conn("conn-".format(i)) for i in range(count)] # 初始化链接
def get_conn(self):
self.sema.acquire() # 当拿取的时候,减一
data=self.pool.pop() # 从尾部拿出一个
print (data)
def return_conn(self,conn:Conn): #此处返回一个连接池
self.pool.append(conn) # 必须保证其在拿的时候有 # 使用try 可以进行处理,下面的必须执行,加成功了,下面的一定要成功的,
self.sema.release()
pool=Pool(3)
con=Conn(‘a‘)
conn=pool.get_conn()
conn=pool.get_conn()
conn=pool.get_conn()结果如下

5 使用信号量的利端和弊端
如果使用了信号量,还是没有用完
self.pool.append(conn)
self.sem.release()
一种极端的情况下,计数器还差1就满了,有3个线程A,B,C都执行了第一句,都没有来得release,这时候轮到线程A release,正常的release,然后轮到线程C先release,一定出现问题,超界了,一定出现问题。
很多线程用完了信号量
没有获取信号量的线程都会阻塞,没有线程和归还的线程争抢,当append后才release,这时候才能等待的线程被唤醒,才能Pop,也就是没有获取信号量就不能pop,这是安全的。
以上是关于python线程同步的主要内容,如果未能解决你的问题,请参考以下文章