Web基础之Mybatis
Posted lixin-link
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Web基础之Mybatis相关的知识,希望对你有一定的参考价值。
Web基础之Mybatis
??对比JdbcTempalte,mybatis才能称得上是框架,JdbcTempalte顶多算是工具类,同时,对比Hibernate,Mybatis又有更多的灵活性,算是一种折中方案。
特点:
- 支持自定义SQL、存储过程、及高级映射
- 实现自动对SQL的参数设置
- 实现自动对结果集进行解析和封装
- 通过XML或者注解进行配置和映射,大大减少代码量
- 数据源的连接信息通过配置文件进行配置
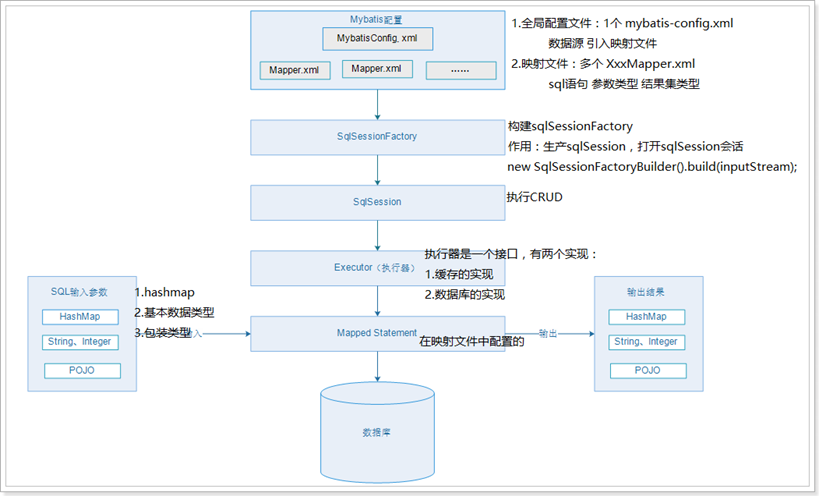
mybatis整体结构:
主配置文件
mybatis-config.xml
依赖
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.4.6</version>
</dependency>主配置文件
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<!-- 环境:说明可以配置多个,default:指定生效的环境 -->
<environments default="development">
<!-- id:环境的唯一标识 -->
<environment id="development">
<!-- 事务管理器,type:类型 -->
<transactionManager type="JDBC" />
<!-- 数据源:type-池类型的数据源 -->
<dataSource type="POOLED">
<property name="driver" value="com.mysql.jdbc.Driver" />
<property name="url" value="jdbc:mysql://127.0.0.1:3306/mybatis" />
<property name="username" value="root" />
<property name="password" value="root" />
</dataSource>
</environment>
</environments>
<!-- 映射文件 -->
<mappers>
<mapper resource="UserMapper.xml"/>
</mappers>
</configuration>
映射文件:
UserMapper.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!-- namespace(命名空间):映射文件的唯一标识 -->
<mapper namespace="UserMapper">
<!-- 查询的statement,id:在同一个命名空间下的唯一标识,resultType:sql语句的结果集封装类型,这里需要全名 -->
<select id="queryUserById" resultType="cn.bilibili.mybatis.pojo.User">
select * from tb_user where id = #id
</select>
</mapper>
使用slf4j12记录日志:
log4j.properties
依赖
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.6.4</version>
</dependency>配置文件
log4j.rootLogger=DEBUG,A1
log4j.logger.org.apache=DEBUG
log4j.appender.A1=org.apache.log4j.ConsoleAppender
log4j.appender.A1.Target=System.err
log4j.appender.A1.layout=org.apache.log4j.PatternLayout
log4j.appender.A1.layout.ConversionPattern=%-dyyyy-MM-dd HH:mm:ss,SSS [%t] [%c]-[%p] %m%n测试方法:
@Test
SqlSession sqlSession = null;
try
// 指定mybatis的全局配置文件
String resource = "mybatis-config.xml";
// 读取mybatis-config.xml配置文件
InputStream inputStream = Resources.getResourceAsStream(resource);
// 构建sqlSessionFactory
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
// 获取sqlSession会话
sqlSession = sqlSessionFactory.openSession();
// 执行查询操作,获取结果集。参数:1-命名空间(namespace)+“.”+statementId,2-sql的占位符参数
User user = sqlSession.selectOne("UserMapper.queryUserById", 1L);
System.out.println(user);
finally
// 关闭连接
if (sqlSession != null)
sqlSession.close();
??大致就是通过SqlSessionFactoryBuilder类获得sql会话工厂,通过sqlSession执行sql语句,而要执行的语句及其映射bean都已经配置在xml里面。需要注意的是mybatis默认开启事务,所以执行增删改时需要手动提交。
Dao接口映射
??mybatis可以直接映射Dao接口,而不必写其实现类(其实是mybatis帮我们实现了啦)
Dao接口:
UserMapper
public interface UserMapper
public User queryUserById(Long id);
public List<User> queryUserList();
public void insertUser(User user);
public void updateUser(User user);
public void deleteUserById(Long id);
映射配置文件
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!-- 这里命名空间需要和映射的接口对应 -->
<mapper namespace="UserMapper">
<!-- id和方法名对应,并且唯一,因此不能有重载方法;返回类型和resultType对应; -->
<select id="queryUserById" resultType="cn.bilibili.mybatis.pojo.User">
select * from tb_user where id = #id
</select>
...
</mapper>Tips:在IDEA中可以使用Ctrl + Shift + T快速创建测试用例
数据库字段和Bean属性名称不一致问题
- sql语句查询使用别名
- 在主配置文件中开启驼峰匹配:
- 自定义resultMap映射
<settings>
<!-- 开启驼峰匹配 -->
<setting name="mapUnderscoreToCamelCase" value="true"/>
</settings>mybatis主配置
配置文档的顶层结构如下:

具体可以参考官方文档
这里介绍几个常用的属性。
properties
属性:properties,可以定义变量,然后使用$变量名来取得其值,如:
<properties resource = "jdbc.properties" />jdbc.properties内容:
driverClass = com.mysql.jdbc.Driver
url = jdbc:mysql://127.0.0.1:3306/mybatis?useUnicode=true&characterEncoding=utf8
username = root
password = 1234然后便可以通过$driverClass来配置驱动了。
settings
包含<setting>标签,有name和value属性
mapUnderscoreToCamelCase
驼峰匹配(默认关闭)
<setting name="mapUnderscoreToCamelCase" value="true"/>lazyLoadingEnabled
延迟加载(默认关闭)
<setting name="lazyLoadingEnabled" value="true"/>cacheEnabled
二级缓存(默认开启)
<setting name="cacheEnabled" value="true"/>autoMappingBehavior
自动映射规则:
| name属性 | 描述 | value属性 | 默认value |
|---|---|---|---|
| autoMappingBehavior | 指定 MyBatis 应如何自动映射列到字段或属性。 NONE 表示取消自动映射;PARTIAL 只会自动映射没有定义嵌套结果集映射的结果集。 FULL 会自动映射任意复杂的结果集(无论是否嵌套)。 | NONE, PARTIAL, FULL | PARTIAL |
什么沙雕排版??
typeAliases
??类型别名是为 Java 类型设置一个短的名字。 它只和 XML 配置有关,存在的意义仅在于用来减少类完全限定名的冗余。
<typeAliases>
<!-- 第一种 -->
<typeAlias alias="User" type="com.bilibili.pojo.User"/>
<!-- 第二种 -->
<package name="com.bilibili.pojo"/>
</typeAliases>??第一种是直接配置一个类的别名,第二种是配置扫描一个包下的所有类
或者注解方式配置别名:
@Alias("User")
public class User
...
以及数据类型的别名(不区分大小写,基本数据类型特殊命名):
数据类型别名
| 别名 | 映射的类型 |
|---|---|
| _byte | byte |
| _long | long |
| _short | short |
| _int | int |
| _integer | int |
| _double | double |
| _float | float |
| _boolean | boolean |
| string | String |
| byte | Byte |
| long | Long |
| short | Short |
| int | Integer |
| integer | Integer |
| double | Double |
| float | Float |
| boolean | Boolean |
| date | Date |
| decimal | BigDecimal |
| bigdecimal | BigDecimal |
| object | Object |
| map | Map |
| hashmap | HashMap |
| list | List |
| arraylist | ArrayList |
| collection | Collection |
| iterator | Iterator |
environments
Mybatis可以配置多个环境,但是一个SQLSessionFactory只对应一个环境
<!-- 可以配置多个环境,并设置默认环境 -->
<environments default="development">
<!-- 配置环境,id:环境的唯一标识 -->
<environment id="development">
<!-- 事务管理器,type:使用jdbc的事务管理器 -->
<transactionManager type="JDBC">
<property name="..." value="..."/>
</transactionManager>
<!-- 数据源,type:池类型的数据源 -->
<dataSource type="POOLED">
<property name="driver" value="$driver"/>
<property name="url" value="$url"/>
<property name="username" value="$username"/>
<property name="password" value="$password"/>
</dataSource>
</environment>
</environments>可以通过build方法的重载指定环境:
SqlSessionFactory factory = new SqlSessionFactoryBuilder().build(reader, environmentID);
//reader为主配置文件流,environment为environmentID,properties为读取的变量文件,三个参数的任一改变都能改变环境
SqlSessionFactory factory = new SqlSessionFactoryBuilder().build(reader, environmentID, properties);如果忽略了环境参数,那么默认环境将会被加载,如下所示:
SqlSessionFactory factory = new SqlSessionFactoryBuilder().build(reader);
SqlSessionFactory factory = new SqlSessionFactoryBuilder().build(reader, properties);mappers
mapper的作用是告诉mybatis去哪里照执行的SQL语句,可以通过下面四种方式:
相对路径的xml文件引用(resources目录):
<!-- 使用相对于类路径的资源引用,相对的是resources目录 -->
<mappers>
<mapper resource="UserMapper.xml"/>
</mappers>绝对路径的xml文件引用(不推荐):
<!-- 使用完全限定资源定位符(URL) -->
<mappers>
<mapper url="file:///D:/UserMapper.xml"/>
</mappers>通过接口路径:
<!-- 使用映射器接口实现类的完全限定类名 -->
<mappers>
<mapper class="com.bilibili.mapper.UserMapper"/>
</mappers>此方式条件:
- 映射文件和mapper接口在同一个目录下(或者resources下的同目录)
- 文件名一致
- 映射文件的namespace必须和mapper接口的全路径保持一致
通过接口所在包的路径
<!-- 将包内的映射器接口实现全部注册为映射器 -->
<mappers>
<package name="com.bilibili.mapper"/>
</mappers>注意事项
??使用动态代理的方式实现接口映射时,mapper.xml文件的命名空间必须是接口的全限定名,并且不能使用typeAliases别名,因为别名是针对Java Bean的
??前两种为直接指定xml文件位置,因此对xml路径没有什么要求。
??后两种为指定接口然后寻找xml文件,因此xml需要在和接口相同的路径(相对resources),并且!idea中resources目录不能使用.(点)来建立多级目录,需要使用/或者\来建立多级目录!!!
mapper xml 映射文件
映射文件的结构:
- cache – 对给定命名空间的缓存配置。
- cache-ref – 对其他命名空间缓存配置的引用。
- resultMap – 是最复杂也是最强大的元素,用来描述如何从数据库结果集中来加载对象。
parameterMap – 已被废弃!老式风格的参数映射。更好的办法是使用内联参数,此元素可能在将来被移除。文档中不会介绍此元素。- sql – 可被其他语句引用的可重用语句块。
- insert – 映射插入语句
- update – 映射更新语句
- delete – 映射删除语句
- select – 映射查询语句
select
示例:
<select id="queryUserById" resultType="User">
SELECT * FROM user WHERE ID = #id
</select>- id:在命名空间中唯一的标识符,可以被用来引用这条语句。
- resultType:返回类型
- parameterType:参数类型,可以省略
- resultMap:结果映射,mybatis最强大的特性,不可以和resultType同时使用
insert
示例:
<insert id = "addUser" useGeneratedKeys = "true" keyColumn = "id" keyProperty = "id" parameterType = "User">
INSERT INTO user (
id,
username,
password
) VALUES (
NULL,
#userName,
#password
)
</insert>- id:唯一标识符
- useGeneratedKeys:开启主键自增回显,将自增长的主键值回显到形参中(即封装到User对象中)[可选]
- keyColumn:数据库中主键的字段名称 [可选]
- keyProperty:pojo中主键对应的属性 [可选]
- parameterType:参数类型 [可选]
update & delete
示例:
<update id = "updateUserById" parameterType = "User">
UPDATE
user
SET
username = #username,
password = #password
WHERE
id = #id
</update>
<delete id = "deleteUserById" parameterType = "long">
DELETE FROM user WHERE id = #id
</delete>parameterType属性
CRUD都有个parameterType标签,用来指定接受的参数类型。
接收参数有两种方式:
#预编译,类似占位符$非预编译,直接sql拼接,不能防止SQL注入,一般用来接收表名等属性
参数类型有三种:
- 基本数据类型
- HashMap(使用方式和pojo类似)
- Pojo自定义包装类
基本数据类型
当sql方法的参数是多个时:
例如queryUserByUserNameAndPassword(String username, String password)这种两个参数时,可以这样接收参数:
<select id="queryUserByUserNameAndPassword" resultType="User">
SELECT * FROM user WHERE username = #0/#arg0/#param1 AND password = #1/#arg1/#param2
</select>不能见名知意的变量不是好方法,所以我们的解决方案是添加@Param注解:
queryUserByUserNameAndPassword(@Param(username) String username, @Param(password)String password)<select id="queryUserByUserNameAndPassword" resultType="User">
SELECT * FROM user WHERE username = #username AND password = #password
</select>这样就可以见名知意了。
HashMap参数
示例:
User loginMap(Map<String,String> map);
/****************************************/
Map<String, String> map = new HashMap<>();
map.put("userName","zhangsan");
map.put("password","123456");
User user = userMapper.loginMap(map);xml中和注解用法类似:
<select id="loginMap" resultType="User">
SELECT * FROM user WHERE username = #userName AND password = #password
</select>Pojo
mapper.xml用法不变,xml是通过Getter方法来获取值的。
$的用法
一个参数时,默认情况下使用$value接收数据。但是这样不能见名知意。
同样使用@Param()注解。
$ 和#
#- 预编译
- 编译成占位符
- 可以防止sql注入
- 自动判断数据类型(参数时字符串时会自动加字符串)
- 一个参数时,可以使用任意参数名称进行接收(即#xxx)
$SQL拼接(不能防止SQL注入)- 非预编译
- sql的直接拼接
- 不能防止sql注入
- 需要判断数据类型,如果是字符串,需要手动添加引号。
- 一个参数时,参数名称必须是value,才能接收参数。
??$还有一个问题是,在主配置文件中,使用$driver获取资源文件的驱动或者url等数据,如果用户的password属性和资源文件中的password属性同名时,此时会读取资源文件中的password而不会使用传入的参数password,解决方法是在资源文件中的属性都加入前缀:
jdbc.driverClass = com.mysql.jdbc.Driver
jdbc.url = jdbc:mysql://127.0.0.1:3306/mybatis?useUnicode=true&characterEncoding=utf8
jdbc.username = root
jdbc.password = 1234当然,主配置文件里面的引用也要修改。
ResultMap
resultMap是mybatis中最强大的特性,可以很方便的解决下面两个问题:
- Pojo属性名和表结构字段名不一致(有时候不只是驼峰格式)
- 高级查询(主要是这个)
简单映射示例:
在映射文件中配置自定义ResultMap:
<resultMap id="userResultMap" type="User" autoMapping="true">
<!--配置主键映射关系,配置主键可以增加查询效率-->
<id column="id" property="id"></id>
<!--配置普通字段的映射关系-->
<result column="user_name" property="userName"></result>
</resultMap>autoMapping属性:
- 为true时:resultMap中的没有配置的字段会自动对应。如果不配置,则默认为true。
- 为false时:只针对resultMap中已经配置的字段作映射。
在查询语句中使用自定义映射:
<!-- resultMap属性:引用自定义结果集作为数据的封装方式 -->
<select id="queryUserById" resultMap="userResultMap">
select * from tb_user where id = #id
</select>高级查询
一对一映射:
??当订单(Order)对象内有用户(User)属性时,之前的情况我们是不能一次查询出来的,但是有了映射便可以很方便的查询:
<!-- id:唯一标识,type:返回类型,autoMapping:自动映射 -->
<resultMap id="orderResultMapper" type="Order" autoMapping="true">
<!-- 主键映射 -->
<id column="id" property="id"/>
<!-- 一般属性映射 -->
<result column="order_number" property="orderNumber"/>
<result column="user_id" property="userId"/>
<!-- 一对一映射,property:属性,javaType:属性类型 -->
<association property="user" javaType="User" autoMapping="true">
<!-- 主键映射,写法和resultMap一样 -->
<id column="user_id" property="id"/>
</association>
</resultMap>
<select id="queryOrderByOrderNumber" resultMap="orderResultMapper">
SELECT *
FROM tb_order o,
tb_user u
WHERE o.user_id = u.id
AND o.order_number = #orderNumber
</select>一对多映射
??当一个订单内有多个信息时,即Order类中持有List<OrderDetail>,便可以进行一对多映射。
??这里的订单可以理解为多个商品一次下单,这一订单中有多个OrderDetail,每个OrderDetail对应一个商品
<resultMap id="orderResultMapper2" type="Order" autoMapping="true">
<!-- 主键的字段使用SQL语句的中的别名 -->
<id column="oid" property="id"/>
<association property="user" javaType="User" autoMapping="true">
<id column="uid" property="id"/>
</association>
<!-- 一对多映射,property:类中的属性,javaType:该属性对应的Java类型,ofType:该属性存储的类型,也就是泛型 -->
<collection property="orderDetailList" javaType="list" ofType="OrderDetail" autoMapping="true">
<id column="did" property="id"/>
</collection>
</resultMap>
<select id="queryOrderAndUserAndOrderDetailsByOrderNumber" resultMap="orderResultMapper2">
<!-- 当表数量较多时,需要指定不同表主键的别名来区分 -->
SELECT *, o.id oid, detail.id did, u.id uid
FROM tb_order o,
tb_orderdetail detail,
tb_user u
where o.order_number = #orderNumber
AND o.user_id = u.id
AND detail.order_id = o.id;
</select>注意,当表数量较多时,需要指定不同表主键的别名来区分。
多对多映射
每个OrderDetail对应一个商品,这时便可以添加映射:
<resultMap id="orderResultMapper3" type="Order" autoMapping="true">
<id column="oid" property="id"/>
<association property="user" javaType="User" autoMapping="true">
<id column="uid" property="id"/>
</association>
<collection property="orderDetailList" javaType="list" ofType="OrderDetail" autoMapping="true">
<id column="did" property="id"/>
<!-- 添加一对一映射 -->
<association property="item" javaType="Item" autoMapping="true">
<id column="iid" property="id"/>
</association>
</collection>
</resultMap>
<select id="queryOrderAndUserAndOrderDetailAndItemByOrderNumber" resultMap="orderResultMapper3">
SELECT *, o.id oid, detail.id did, u.id uid, item.id iid
FROM tb_order o,
tb_user u,
tb_orderdetail detail,
tb_item item
where o.order_number = #orderNumber
and o.user_id = u.id
and detail.order_id = o.id
and detail.item_id = item.id
</select>继承
从上面的代码可以看出这样映射虽然很方便,但是代码存在冗余的情况:

??图中的代码我们已经在其他映射中配置过了,当后面的映射需要这一段时,我们便可以使用继承。
??修改后的第三个映射的resultMap为:
<!-- 添加extends属性,便可以映射重用 -->
<resultMap id="orderResultMapper3" type="Order" autoMapping="true" extends="orderResultMapper">
<collection property="orderDetailList" javaType="list" ofType="OrderDetail" autoMapping="true">
<id column="did" property="id"/>
<association property="item" javaType="Item" autoMapping="true">
<id column="iid" property="id"/>
</association>
</collection>
</resultMap>延迟加载
??延迟加载是指当我们需要哪部分数据时,然后再去查。
??上面的几个映射,每次查询时会一股脑将数据全部查询出来,即使不需要的数据也会查询(因为只有一条语句)。当我们查询订单时,需要用户信息的时候再去查,因此SQL语句需要拆成两条。
主配置文件中开启延迟加载:
<settings>
<!-- 开启延迟加载(默认关闭) -->
<setting name="lazyLoadingEnabled" value="true" />
<!-- 关闭使用任意属性,就加载延迟对象的功能。(在3.4.1及之前的版本默认值为 true,3.4.1之后的版本不需要配置此项) -->
<setting name="aggressiveLazyLoading" value="false"/>
</settings>延迟加载示例:
<resultMap id="orderLazyUser" type="Order" autoMapping="true">
<id column="id" property="id"/>
<!-- property:属性,select:延迟加载对象依赖的SQL语句,column:传进去的参数 -->
<association property="user" select="queryUserById" column="user_id" autoMapping="true">
<id column="id" property="id"/>
</association>
</resultMap>
<select id="queryOrderLazyUser" resultMap="orderLazyUser">
SELECT * FROM tb_order where order_number = #orderNumber
</select>
<select id="queryUserById" resultType="User">
SELECT * FROM tb_user WHERE id = #id
</select>如果报错需要添加cglib依赖(3.3以上不需要添加此依赖):
<dependency>
<groupId>cglib</groupId>
<artifactId>cglib</artifactId>
<version>3.1</version>
</dependency>SQL 片段
对于使用很频繁的SQL语句,可以单独抽离出来进行复用。
在同一个mapper.xml中:
<sql id = "testSql">
id,
username,
password,
...
</sql>
<select id = "queryAllUser" resultType = "User">
SELECT <include refid = "testSql"></include> FROM user
</select>但是这样只能在一个mapper文件中使用,因此我们可以把经常使用的写入在一个mapper文件中:
CommonSQL.xml文件:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="CommonSQL">
<sql id="testSql">
id,
user_name,
password,
...
</sql>
</mapper>在主配置中引入:
<mappers>
<mapper resource = "CommonSQL" />
</mappers>然后就可以在mapper中使用:
<select id = "queryAllUser" resultType = "User">
SELECT <include refid = "CommonSQL.testSql"></include> FROM user
</select>即refid = "namespace.sqlID"变一下即可。
XML 特殊字符
感觉这个好麻烦啊,因为这些字符在SQL中出现的频率太高了
| 符号 | 转义 |
|---|---|
| < | < |
| > | > |
| & | & |
| ‘ | ' |
| " | " |
或者使用CDATA:<![CDATA[]]>
真是反人类。。。
动态SQL
??mybatis中也可以动态拼接SQL语句(但是在xml中写SQL太难受了),支持ognl表达式(Struts不就是因为这东西才被黑客利用爆出漏洞死掉的么,还用。。。)
if
示例:
<select id="queryMaleUserByUserNameOrId" resultType="User" >
select * from tb_user where sex = 1
<!-- if标签,条件判断,test属性编写ognl表达式 -->
<if test="userName != null and userName.trim() != ''" >
and user_name like #userName
</if>
<if test="id != null and id.trim() != '' " >
and id like #id
</if>
</select>上面的SQL可以通过用户名或者ID来查询。
choose, when, otherwise
??相当于switch, case, default,只不过自动break,一旦有一个when成立,后续的when都不再执行。
示例:
<select id="queryMaleUserByIdOrUserName" resultType="User">
select * from tb_user where sex = 1
<choose>
<when test="id != null and id.trim()!='' " >
and id like #id
</when>
<when test="userName != null and userName.trim()!=''" >
and user_name like #userName
</when>
<otherwise>
and active = 1
</otherwise>
</choose>
</select>??上面的SQL意思是如果提供了id就用id查询,没提供id就用用户名查询,都没有的话则查询所有的激活用户。
where, set, trim
第一个查询如果把性别也改为动态的:
<select id="queryUserByUserNameOrId" resultType="User" >
select * from tb_user where
<if test = "sex != null and id.trim() != '' " >
sex = #sex
</if>
<if test = "userName != null and userName.trim() != '' " >
and user_name like #userName
</if>
<if test = "id != null and id.trim() != '' " >
and id like #id
</if>
</select>如果sex参数为空的话这条SQL语句就变成了这样:
select * from tb_user where
and user_name like #userName
and id like #id有点逗比是不是,此时<where>标签的作用就体现出来了:
<select id="queryUserByUserNameOrId" resultType="User" >
select * from tb_user
<where>
<if test = "sex != null and id.trim() != '' " >
sex = #sex
</if>
<if test = "userName != null and userName.trim() != '' ">
and user_name like #userName
</if>
<if test = "id != null and id.trim() != '' " >
and id like #id
</if>
</where>
</select>??where 元素只会在至少有一个子元素的条件返回 SQL 子句的情况下才去插入“WHERE”子句。而且,若语句的开头为“AND”或“OR”,where 元素也会将它们去除。
??如果 where 元素没有按正常套路出牌,我们可以通过自定义 trim 元素来定制 where 元素的功能。比如,和 where 元素等价的自定义 trim 元素为:
<trim prefix="WHERE" prefixOverrides="AND | OR ">
...
</trim><set>标签和where类似:
<update id = "changePasswordOrUserName">
UPDATE user
<set>
<if test = "password != null">
password = #password,
</if>
<if test = "username != null">
username = #username
</if>
</set>
WHERE id = #id
</update>??set 元素会动态前置 SET 关键字,同时也会删掉无关的逗号,因为用了条件语句之后很可能就会在生成的 SQL 语句的后面留下这些逗号。
上面的句子就相当于:
<trim prefix = "SET" suffixOverrides = ",">
...
</trim>foreach
动态 SQL 的另外一个常用的操作需求是对一个集合进行遍历,通常是在构建 IN 条件语句的时候。比如:
<select id="selectUserIn" resultType="User">
SELECT *
FROM user
WHERE id in
<foreach item="item" index="index" collection="list"
open="(" separator="," close=")">
#item
</foreach>
</select>可以迭代Collection、数组、Map,当参数为Map时,index为键,item为值。
缓存
一级缓存:
??缓存是sqlSession级别,默认开启(无法关闭?),可以使用session.clearCache()方法清除缓存。对于同一条数据再次查询会查询缓存里的数据。需要注意的是增、删、改语句都会清除缓存,即使是不同数据。
二级缓存:
??二级缓存需要Pojo对象实现Serializable接口,可以实现不同sqlSession间公用缓存。当第一个sqlSession查询一条数据后调用sqlSession.close()方法会将数据添加到二级缓存,第二个sqlSession再次查询同一数据时会使用缓存。(数据增删改同样会情况二级缓存)
开启二级缓存:
<settings>
<!-- 开启二级缓存,默认是开启的 -->
<setting name="cacheEnabled" value="true"/>
</settings>注解方式使用Mybatis
@Param
给参数添加别名(估计是因为反射不能获取接口中声明的局部变量名称)
示例:
User queryUserById(@Param("id") Integer id);@Select、@Delete、@Update、@Insert
@Select("select * from tb_user where id = #id")
User queryUserById(@Param("id") Integer id);
@Delete("DELETE FROM tb_user WHERE id = #id")
int deleteUserById(@Param("id") Integer id);
@Update("UPDATE tb_user SET name = #name WHERE id = #id")
int updateNameById(@Param("name") String name, @Param("id") Integer id);
/*
@Options:参数配置
useGeneratedKeys:主键回写(默认false)
keyColumn:主键字段名
keyProperty:主键属性(默认id)
*/
@Insert("insert into tb_user(user_name,password,name) values (#userName, #password, #name) ")
@Options(useGeneratedKeys = true,keyColumn = "id")
int addUser(User user);@Results注解别名映射
@Select("select id uid,user_name,password pwd from tb_user where id=#id")
/*
Results:定义结果集,内部是一个Result注解的数组
Result:结果集映射关系
column:列名
property:属性名
*/
@Results(
@Result(column = "uid",property = "id"),
@Result(column = "user_name",property = "userName"),
@Result(column = "pwd",property = "password")
)
public User findUserByIdResultMap(@Param("id") Long id);注解高级查询
一对一映射
@Select("select * from tb_order where order_number = #orderNumber")
@Results(
/*
一对一映射调用其他接口的方法
column:传入的参数
property:返回对应的属性
one代表一对一,值为@One注解
@One:一对一注解
select:引用的查询方法
*/
@Result(column = "user_id",property = "user", one = @One(select = "com.bilibili.mybatis.mapper.UserMapper.queryUserById"))
)
Order queryOrderAndUserByOrderNumber(@Param("orderNumber") String orderNumber);UserMapper接口:
//被调用的方法
public interface UserMapper
@Select("select * from tb_user where id = #id")
User queryUserById(@Param("id") Integer id);
一对多映射
@Select("select * from tb_order where order_number = #orderNumber")
@Results(
@Result(column = "id", property = "id"),
//一对一映射
@Result(column = "user_id",property = "user",one = @One(select = "com.bilibili.mybatis.mapper.UserMapper.queryUserById")),
/*
一对多映射
many代表一对多,值为@Many注解
@Many:一对多注解
select:引用的方法
*/
@Result(column = "id", property = "orderDetailList", many = @Many(select = "com.bilibili.mybatis.mapper.OrderDetailMapper.queryOrderDetailsByOrderId"
))
)
Order queryOrderAndUserAndOrderDetailsByOrderNumber(@Param("orderNumber") String orderNumber);OrderDetailMapper接口:
//引用的方法
public interface OrderDetailMapper
@Select("select * from tb_orderdetail where order_id = #oid")
@Results(
@Result(column = "id",property = "id"),
)
List<OrderDetail> queryOrderDetailsByOrderId(@Param("oid") Integer oid);
多对多映射
多对多只需要在被引用的一对多方法里添加一对一即可:
public interface OrderDetailMapper
@Select("select * from tb_orderdetail where id = #id")
OrderDetail queryOrderDetailById(@Param("id") Integer id);
@Select("select * from tb_orderdetail where order_id = #oid")
@Results(
@Result(column = "id",property = "id"),
//添加一对一
@Result(column = "item_id", property = "item", one = @One(select = "com.bilibili.mybatis.mapper.ItemMapper.queryItemById"))
)
List<OrderDetail> queryOrderDetailsByOrderId(@Param("oid") Integer oid);
注解延迟加载
在@One注解里添加fetchType属性:
@Select("select * from tb_order where order_number = #orderNumber")
@Results(@Result(column = "user_id", property = "user", one = @One(
select = "com.bilibili.mybatis.mapper.UserMapper.queryUserById",
//添加延迟加载属性
fetchType = FetchType.LAZY
))
)
Order queryOrderAndUserByOrderNumber(@Param("orderNumber") String orderNumber);fetchType属性会覆盖全局属性,可选值有:
- FetchType.LAZY:延迟加载
- FetchType.EAGER:立即加载
- FetchType.DEFAULT:默认属性(即全局属性)
注解动态SQL
注解方式使用动态SQL的话需要一个类来专门构建SQL语句:
//用来构建SQL语句的类
public class UserSqlBuilder
//想要在匿名内部类中访问需要将变量声明为为final
public String queryUserByConditions(final User user)
//第一种方式,直接SQL拼接
StringBuilder sqlSb = new StringBuilder("SELECT * FROM tb_user WHERE 1=1 ");
if (user.getUserName() != null && user.getUserName().trim().length() > 0)
sqlSb.append(" AND user_name like #userName ");
if (user.getSex() != null)
sqlSb.append(" AND sex = #sex ");
return sqlSb.toString();
//第二种方式,使用mybatis提供的类
//注意下面的SELECT、FROM等都是方法,并且是写在构造代码块里的(猛地一看还真没看明白)
String sql = new SQL()
SELECT("*");
FROM("tb_user");
if (user.getUserName() != null && user.getUserName().trim().length() > 0)
WHERE("user_name like #userName");
if (user.getSex() != null)
WHERE("sex = #sex ");
.toString();
return sql;
接口中的方法为:
public interface UserMapper
//只需将@Select()注解替换为@SelectProvider()即可
//type:提供SQL语句的类,method:提供SQL的方法
@SelectProvider(type = UserSqlBuilder.class,method = "queryUserByConditions")
List<User> queryUserByConditions(final User user);
除了SelectProvider还有:
- @InsertProvider
- @UpdateProvider
- @DeleteProvider
- @SelectProvider
按需添加即可。
??如果@SelectProvider描述的抽象方法没有使用@Param给变量添加别名,并且声明了多个变量,那么提供SQL的类的方法参数需要和接口中的方法一样,也就是声明出所有的变量:
public interface UserMapper
@SelectProvider(type = UserSqlBuilder.class,method = "queryUserByConditions")
List<User> queryUserByConditions(final User user, final String name);
提供SQL的类的方法也需要声明为接口同样的参数:
public class UserSqlBuilder
//提供SQL的方法也需要声明两个变量
public String queryUserByConditions(final User user, final String name)
...
??如果接口中的抽象方法使用了@Param参数,那么类中提供SQL的方法便可以用哪个参数声明哪个参数:
//接口
public interface UserMapper
@SelectProvider(type = UserSqlBuilder.class,method = "queryUserByConditions")
List<User> queryUserByConditions(@Param("user") final User user, @Param("user") final String name);
提供SQL的类中的方法便可以这样写:
public class UserSqlBuilder
//只需要声明自己需要的类便可以了
public String queryUserByConditions(@Param("user") final User user)
...
如果Mybatis的版本在3.5.1以后,可以将这样简化:
映射的接口:
public interface UserMapper
@SelectProvider(UserSqlProvider.class)
List<User> queryUserByConditions(final User user);
提供SQL的类:
//提供类继承一个超类:ProviderMethodResolver
class UserSqlProvider implements ProviderMethodResolver
//这里的方法名需要和接口中的方法名一样
public static String queryUserByConditions(final User user)
...
还是直接看官方的文档比较好??:Mybatis 官方中文文档
以上是关于Web基础之Mybatis的主要内容,如果未能解决你的问题,请参考以下文章