最大相关 - 最小冗余(mRMR)特征选择
Posted darlewo
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了最大相关 - 最小冗余(mRMR)特征选择相关的知识,希望对你有一定的参考价值。
彭等人提出了一种特征选择方法,可以使用互信息,相关或距离/相似性分数来选择特征。目的是在存在其他所选特征的情况下通过其冗余来惩罚特征的相关性。特征集S与类c的相关性由各个特征f i和类c之间的所有互信息值的平均值定义,如下所示:
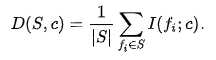
集合S中所有特征的冗余是特征f i和特征f j之间的所有互信息值的平均值:
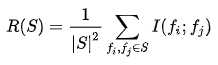
mRMR标准是上面给出的两种措施的组合,定义如下:
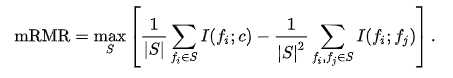
如果使用增量搜索方法(incremental search methods)可以写成优化问题:
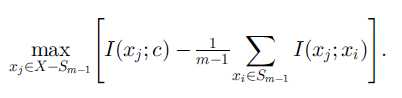
即在已选择特征的基础上,在剩下的特征空间中找到能使上式最大的那个特征。其实相当于对剩下的每个特征进行计算然后排序,因此,我认为mRMR的实质其实是用一个标准(相关性-冗余性)来对特征进行排序,只不过这个标准不是针对每个特征单独计算的,是要先有一个候选子集,然后才能计算。
mRMR算法是理论上最佳的最大依赖性( maximum-dependency)特征选择算法的近似,其最大化所选特征和分类变量的联合分布之间的互信息。这里提到最大依赖性,其实我们的目的就是找到一个特征子集,使该特征子集与标签有最大的依赖性,但是多变量的密度估计比较麻烦,要计算很大的协方差,因此难以实际应用,mRMR证明了它在使用增量搜索方法(每次添加一个特征)时,理论上和最大依赖性特征选择算法一样,论文也提到说该搜索方法为一阶增量搜索(first order incremental search)。具体证明可以参考论文。

由于mRMR用一系列小得多的问题近似于组合估计问题,每个问题只涉及两个变量,因此使用更健壮的成对联合概率。在某些情况下,算法可能低估了特征的有用性,因为它无法测量可以增加相关性的特征之间的相互作用。当特征单独无用时,这会导致性能不佳,但在组合时很有用(当类是奇偶校验功能时会发现病态情况)的特征)。总体而言,该算法比理论上最佳的最大依赖性选择更有效(就所需数据量而言),但产生具有很少成对冗余的特征集。
mRMR是一大类过滤方法的实例,它以不同的方式在相关性和冗余之间进行权衡。
这里有个问题,
比如总共有10维特征,我们现在选择了4维特征,那剩下的6维特征分别计算该特征与标签的互信息(relevance)和该特征与这4维特征的互信息均值(redundancy),然后两者做差或者算个比值,记为λ,那么这6个特征中λ最大的特征就把它添加进来,然后再继续该过程。那只能说新添加的这个特征比起剩下的5维特征要更好,但是我们不知道,现在构成的5个特征是否就要比一开始的4个特征更好?这个就很难说了。
所以作者在论文里是尝试了two-stage的方法,先用mRMR生成一个候选特征集,然后再用更复杂的wrapper的方式进行第二次特征选择。
以上是关于最大相关 - 最小冗余(mRMR)特征选择的主要内容,如果未能解决你的问题,请参考以下文章