Hbase的安装和配置
Posted dcl-snow
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hbase的安装和配置相关的知识,希望对你有一定的参考价值。
Hbase简介
Hbase概述
Hbase原型是Google的BigTable论文,受到了改论文思想的启发,目前作为Hadoop的子项目来开发维护,用于支持结构化的数据存储。
Hbase是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用Hbase技术可以在廉价的服务器上搭建起大规模的结构化存储集群。
Hbase的目标是存储并处理大型的数据,更具体来说是仅需使用普通的硬件配置,就能处理由成千上万的行和列所组成的大型数据。
Hbase的核心是能够实现在HDFS中数据的随机读写。
Hbase的特点:
海量存储、列式存储(列族存储)、极易扩展、高并发、稀疏(列族中可以制定任意多的列,列数据可以为空,并且该情况下不会占用存储空间)
1.没有真正的索引:行是顺序存储的,每行中的列也是,所以不存在索引膨胀的问题,而且插入性能和表的大小无关。
2.自动分区:在表增长的时候,表会自动分裂成区域,并分布到可用的节点上。
3.线性扩展和对于新节点的自动处理:增加一个节点,把它指向现有集群并运行regionserver。区域自动重新进行平衡,负载均匀分布。
4.普通商用硬件支持:集群可以用1000~5000美金的单个节点搭建,而不需要使用单个5万美金的节点。RDBMS需要支持大量I/O,因此要求更昂贵的硬件。
5.容错:大量节点意味着每个节点的重要性并不突出。不用担心单个节点失效。
6.批处理 MapReduce集成功能使我们可用全并行的分布式作业根据“数据的位置”来批处理它们。
Hbase结构
DataNode是管理存储数据的进程,并不是实质的存储节点。
使用Hbase必须先启动Hadoop和ZooKeeper,用来支持HDFS存储数据和高可用,高可用是NameNode做集群并将元数据存储在ZooKeeper中。
Hbase的分布式安装部署
集群规划:三台服务器上部署Hbase集群,基于前面的文章中已经部署的Hadoop、ZooKeeper环境的三台虚拟机。
选择版本进行下载,此处选择的是hbase-2.0.5
将压缩包使用Xftp上传hadoop-1的/usr目录下:
进入/usr目录,使用tar命令将压缩包进行解压,执行命令:
1 # tar zxvf hbase-2.0.5-bin.tar.gz
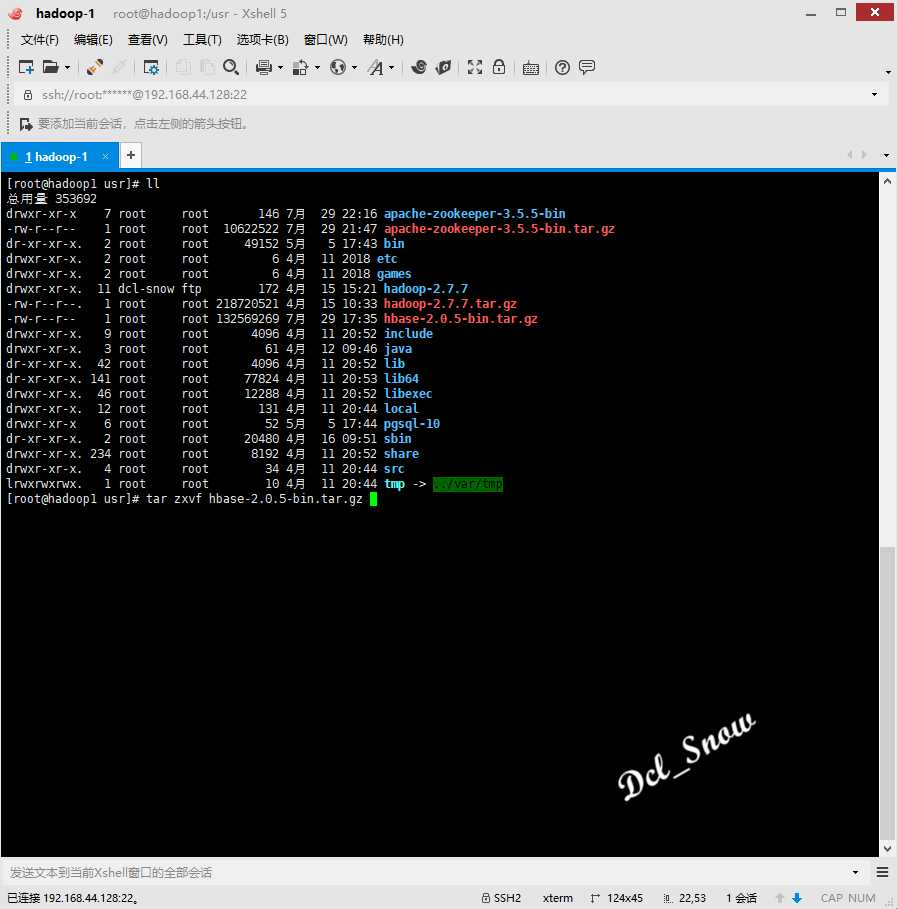
解压完成后会在/usr目录下生成hbase-2.0.5目录:
进入Hbase的配置文件目录,并查看该目录下的文件:
1 # cd hbase-2.0.5/conf/ 2 # ll
使用vim编辑配置文件hbase-env.sh,更改内容如下: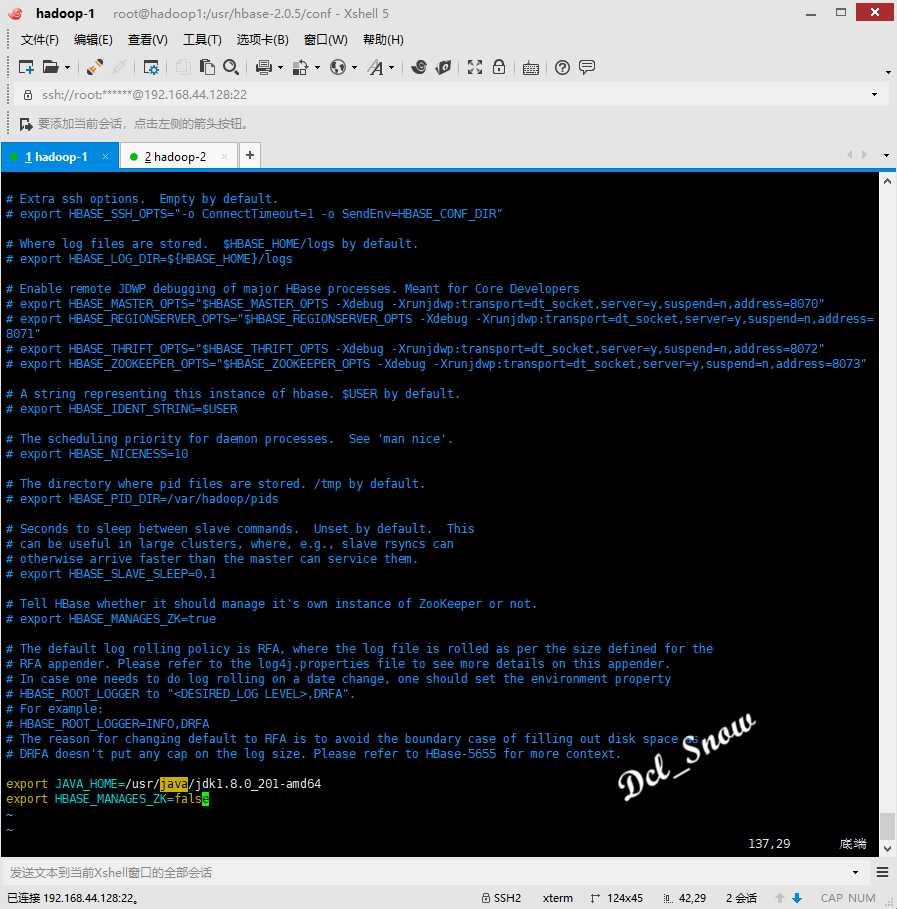
使用vim编辑配置文件hbase-site.xml,更改内容如下: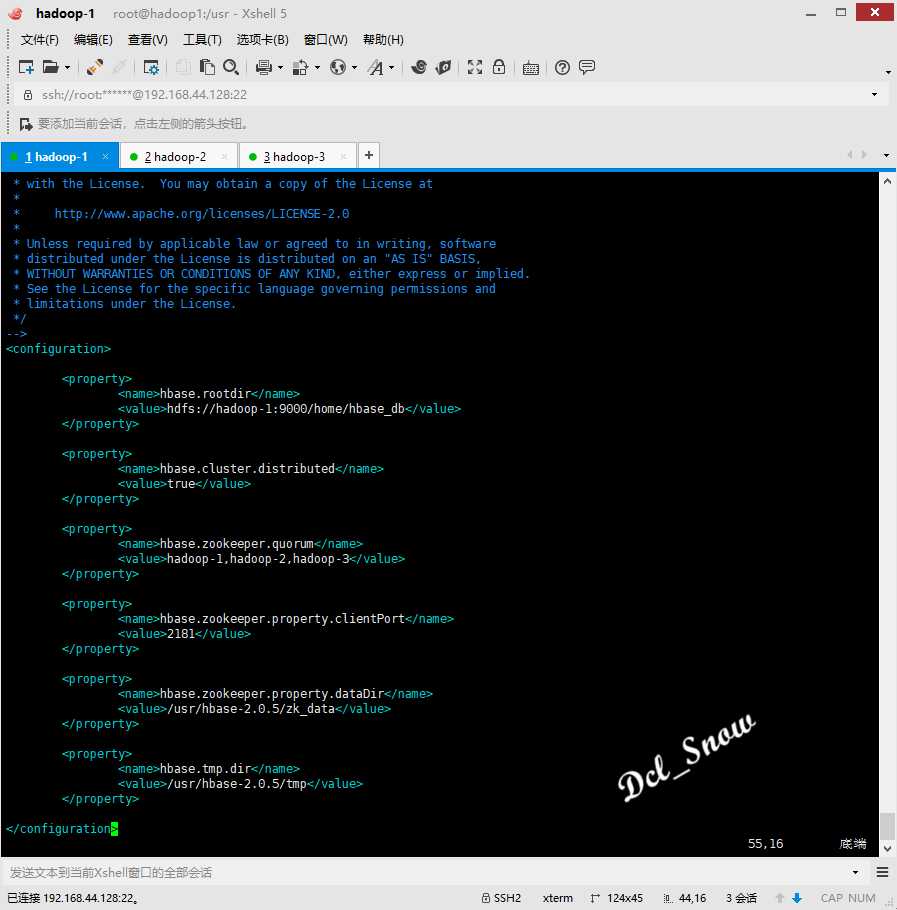
配置文件参数说明:
| 配置项 | 值 | 说明 |
| hbase.rootdir | hdfs://hadoopnn:9000/hbase_db | region servers共享的目录 |
| hbase.cluster.distributed | true | 值为true则是分布式模式 |
| hbase.zookeeper.quorum | hadoopnn,hadoopdn1,hadoopdn2 | 使用逗号分隔的ZooKeeper集合中的服务器列表 |
| hbase.zookeeper.property.clientPort | 2181 | 客户端将连接的端口 |
| hbase.zookeeper.property.dataDir | /usr/hbase-2.0.5/zk_data | 快照存储的目录 |
| hbase.tmp.dir | /usr/hbase-2.0.5/tmp | 本地文件系统上的临时目录 |
使用vim编辑配置文件regionservers,更改内容如下: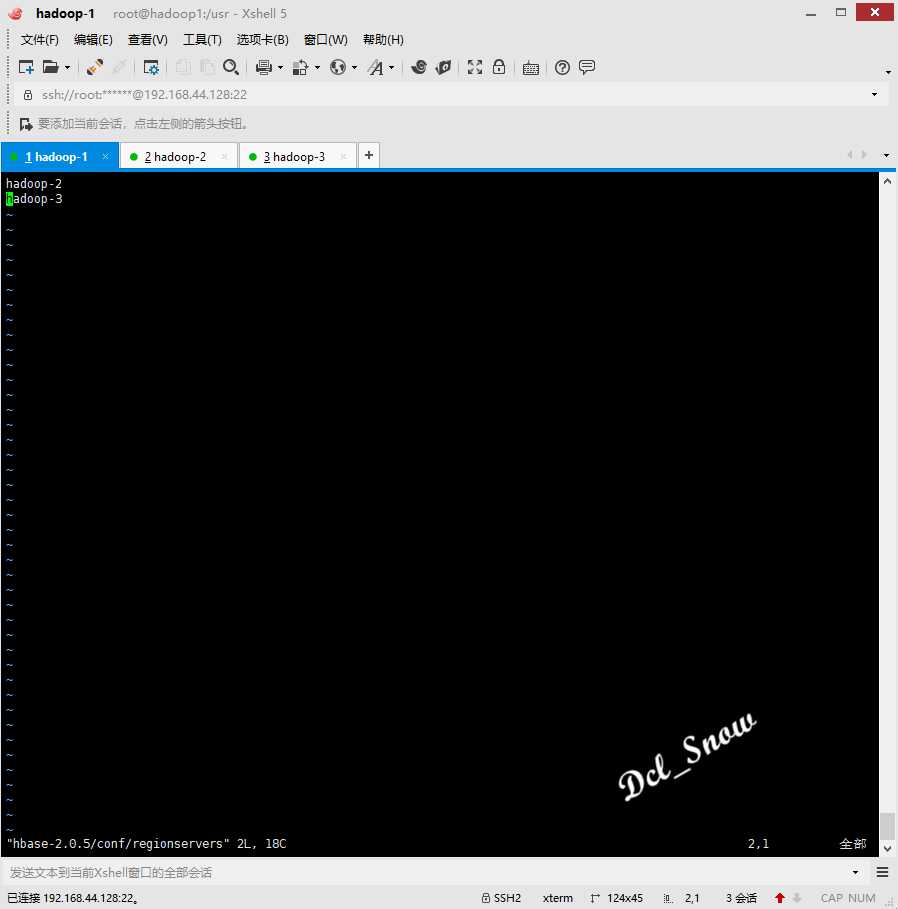
然后将/usr目录下的hbase-2.0.5远程拷贝到hadoop-2和hadoop-3主机的/usr目录下:
1 # scp -r /usr/hbase-2.0.5 hadoop-2:/usr 2 # scp -r /usr/hbase-2.0.5 hadoop-3:/usr
在hadoop-1主机上执行start-all.sh启动hadoop集群,jps命令查看hadoop-1上的启动了NameNode等进程: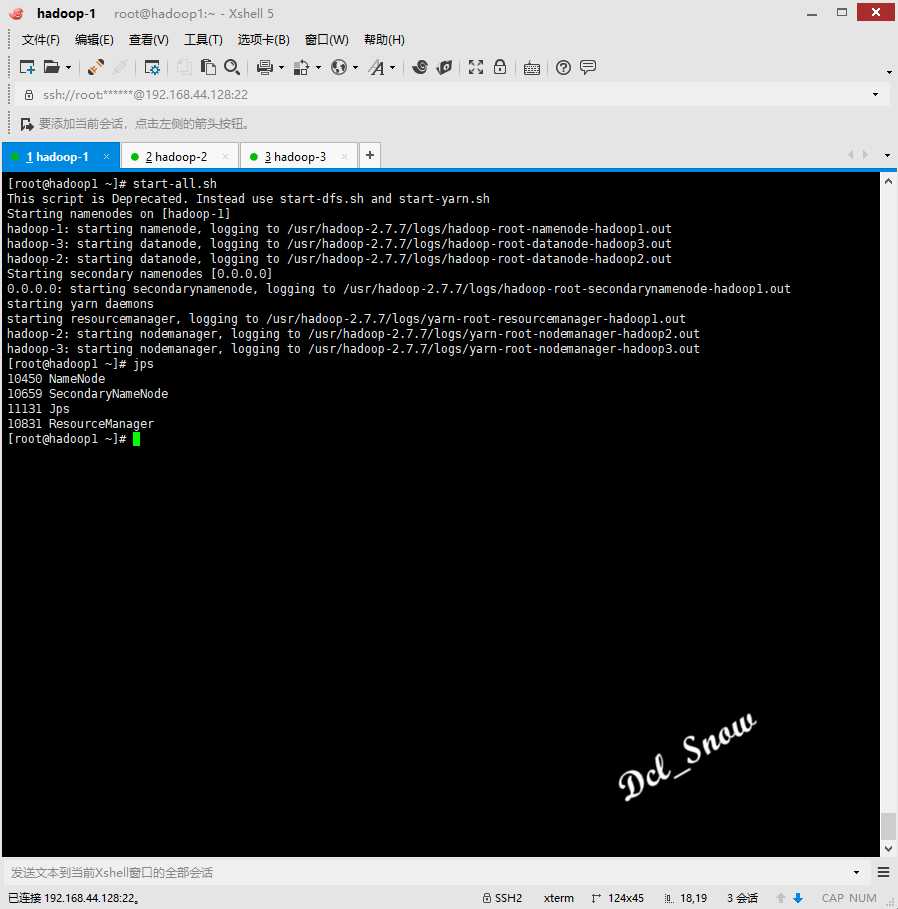
hadoop-2和hadoop-3上启动了DataNode等进程: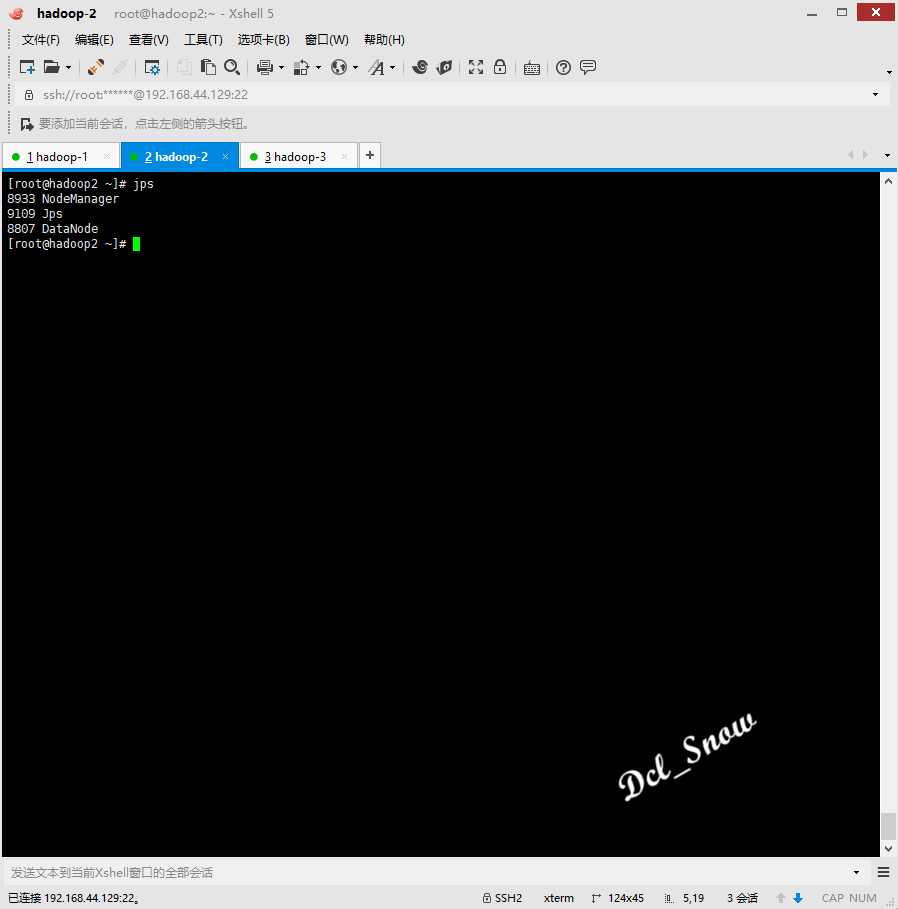
分别在三台主机上按照顺序启动ZooKeeper集群:
1 # zkServer.sh start
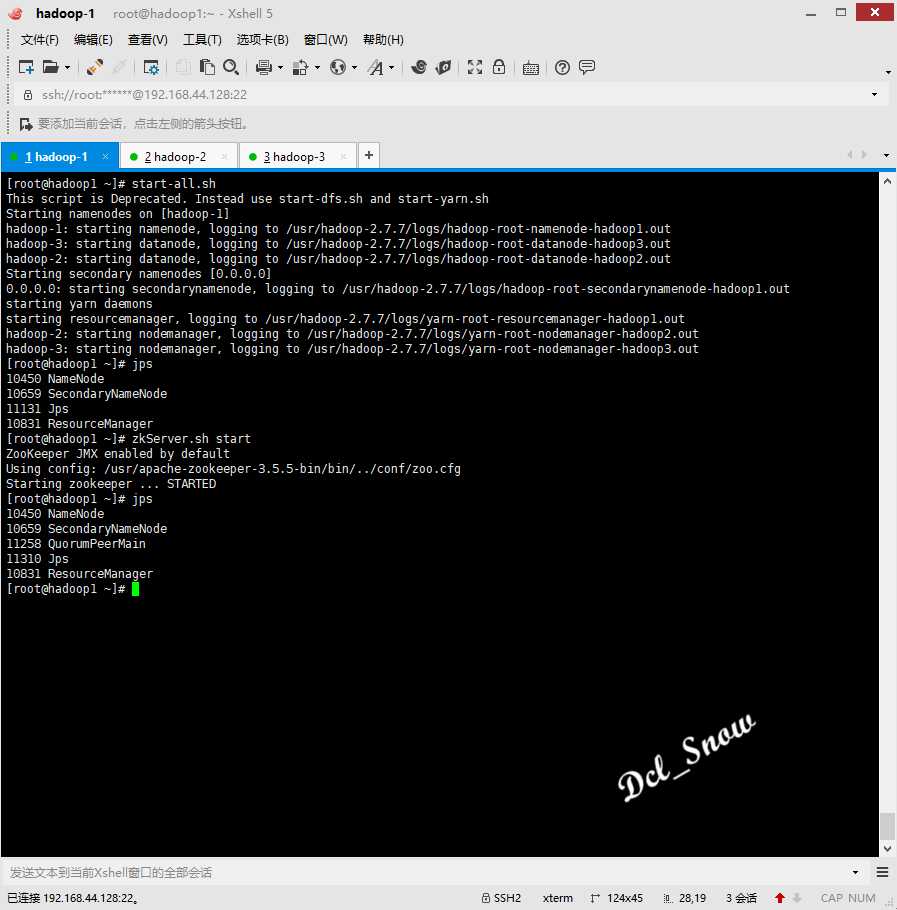
并使用jps命令查看ZooKeeper集群启动成功。
在三台主机上分别使用vim编辑环境变量,更改内容如下:
1 # vim /etc/profile
保存退出,执行命令是修改生效:
1 # source /etc/profile
执行start-hbase.sh启动hbase集群:
1 # start-hbase.sh
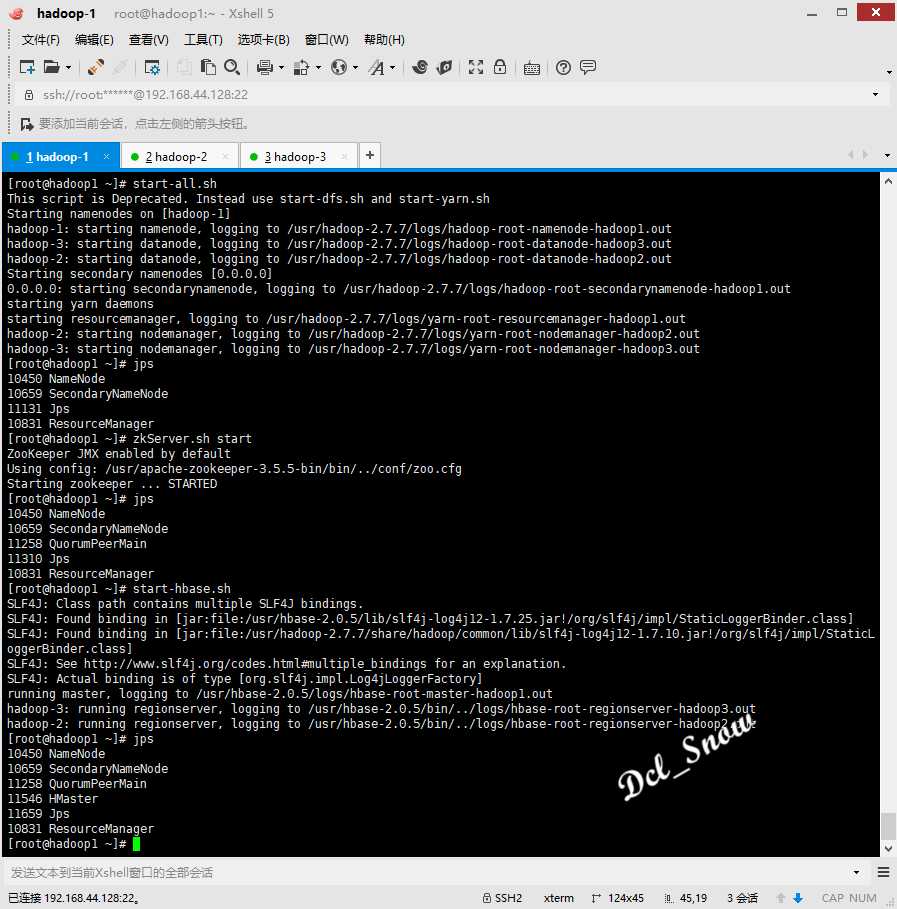
并使用jps查看进程,hadoop-1中启动了HMaster进程,hadoop-2和hadoop-3中启动了HRegionServer进程,hbase集群启动成功。
在浏览器中输入:[http://192.168.44.128:16010](http://192.168.44.128:16010/),即可打开Hbase的web页面: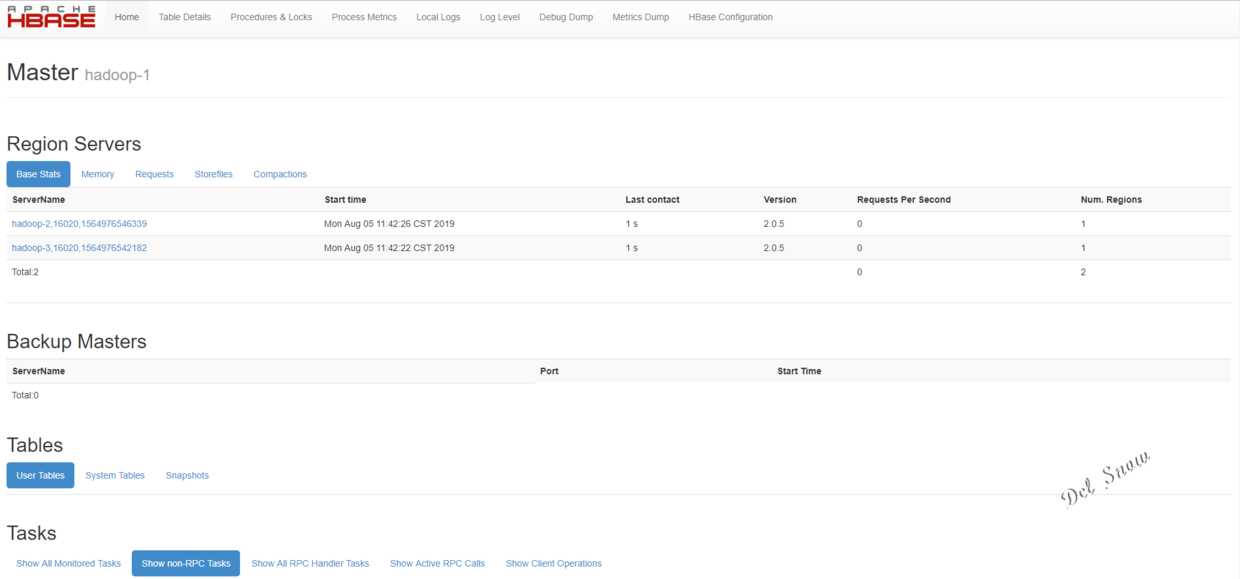
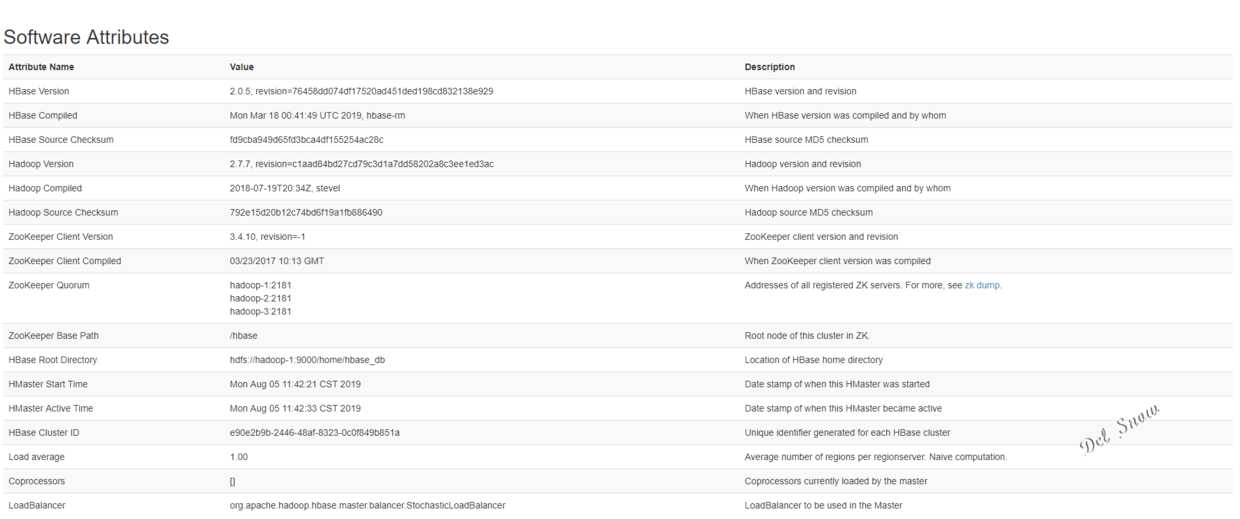
注意:Hbase集群是HMaster管理整个集群,为了实现HMaster的高可用,可以在集群的其他主机上启用备份HMaster服务,每个集群最多可以启动9个备份HMaster服务:
1 # local-master-backup.sh start 2
2为默认端口的偏移量,每个HMaster使用两个端口(默认为16000和16010),例如在hadoop-2执行该命令,则备份HMaster服务的端口为16012。
此时在浏览器中打开备份服务的ip:16012,即可看到集群中的HMaster的状态信息。
若要终止备份HMaster服务,需要查看该备份服务的PID,然后使用kill -9杀死该进程即可。
以上是关于Hbase的安装和配置的主要内容,如果未能解决你的问题,请参考以下文章