图像分类算法优化技巧
Posted yumoye
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了图像分类算法优化技巧相关的知识,希望对你有一定的参考价值。
图像分类算法优化技巧
论文:Bag of Tricks for Image Classification with Convolutional Neural Networks
论文链接:https://arxiv.org/abs/1812.01187
论文复现对很多人而言难度都比较大,因为常常涉及很多细节,部分细节对于模型效果影响很大,但是却很少有文章介绍这些细节,前段时间正好看到这篇文章,再加上之前就有关注GluonCV,因此就抽空看了下这篇文章。这篇文章是亚马逊科学家介绍CNN网络调优的细节,许多实验是在图像分类算法做的,比如ResNet,作者不仅复现出原论文的结果,在许多网络结构上甚至超出原论文的效果,而且对于目标检测、图像分割算法同样有提升作用。目前这些复现结果都可以在GluonCV中找到:https://github.com/dmlc/gluon-cv,GluonCV是亚马逊推出的深度学习库,除了提供许多图像任务的论文复现结果,还提供了非常多常用的数据读取、模型构建的接口,大大降低了入门深度学习的门槛。因此这篇文章可以看作是一群经验丰富的工程师介绍炼丹技巧,帮助广大读者炼出更好的丹药,个人感觉非常实用。
首先可以先来看看作者训练的ResNet50网络的效果。在Table1中对比了目前几个常用分类网络的效果,最后一行是作者通过添加各种训练技巧后复现的ResNet-50效果,和原论文的结果对比提升非常明显(top-1准确率从75.3提升到79.29)。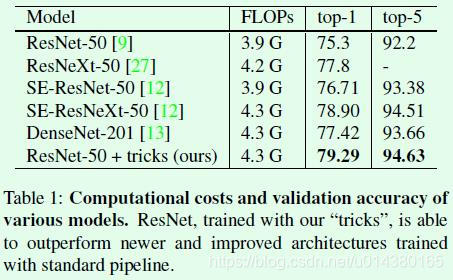
既然要做对比实验,那么首先要有一个baseline,这个baseline就是作者复现相关算法的结果,这个baseline的复现细节可以参考论文2.1节内容,包括数据预处理的方式和顺序、网络层参数初始化方式、迭代次数、学习率变化策略等,这里不再赘述。Table2是作者采用baseline方式复现的3个常用分类网络的结果,可以看出来效果基本上和原论文差不多,这里的baseline也将作为后续实验的对比对象。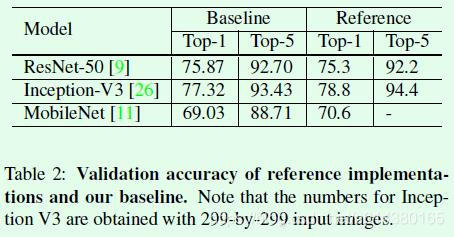
介绍完baseline后,接下来就是这篇论文的重点:怎么优化?整篇论文主要从加快模型训练、网络结构优化和训练调优3个部分分别介绍如何提升模型效果,接下来分别介绍。
一、加快模型训练部分:
这部分主要有2块内容,一块是选用更大的batch size,另一块是采用16位浮点型进行训练。
选用更大的batch size能够在整体上加快模型的训练,但是一般而言如果只增大batch size,效果不会太理想,这部分目前有比较多的研究论文,比如Facebook的这篇:Accurate, Large Minibatch SGD:
Training ImageNet in 1 Hour,作者也总结了主要的几个解决方案:
1、增大学习率,因为更大的batch size意味着基于每个batch数据计算得到的梯度更加贴近整个数据集(数学上来讲就是方差更小),因此当更新方向更加准确后,迈的步子也可以更大了,一般而言将batch size修改为原来的几倍,那么初始学习率也需要修改为原来的几倍。
2、用一个小的学习率先训几个epoch(warmup),因为网络的参数是随机初始化的,假如一开始就采用较大的学习率容易出现数值不稳定,这是使用warmup的原因。等到训练过程基本稳定了就可以使用原先设定的初始学习率进行训练了。作者在实现warmup的过程中采用线性增加的策略,举例而言,假设warmup阶段的初始学习率是0,warmup阶段共需要训练m个batch的数据(实现中m个batch共5个epoch),假设训练阶段的初始学习率是L,那么在batch i的学习率就设置为i*L/m。
3、每个残差块的最后一个BN层的γ参数初始化为0,我们知道BN层的γ、β参数是用来对标准化后的输入做线性变换的,也就是γx^+β,一般γ参数都会初始化为1,作者认为初始化为0更有利于模型的训练。
4、不对bias参数执行weight decay操作,weight decay主要的作用就是通过对网络层的参数(包括weight和bias)做约束(L2正则化会使得网络层的参数更加平滑)达到减少模型过拟合的效果。
采用低精度(16位浮点型)训练是从数值层面来做加速。一般而言现在大部分的深度学习网络的输入、网络参数、网络输出都采用32位浮点型,现在随着GPU的迭代更新(比如V100支持16为浮点型的模型训练),如果能使用16位浮点型参数进行训练,就可以大大加快模型的训练速度,这是作者加速训练最主要的措施,不过目前来看应该只有V100才能支持这样的训练。
那么这二者的优化效果如何?Table3是采用更大的batch size和16位浮点型进行训练的结果,可以看出和原来的baseline相比训练速度提升还是比较明显的,效果上也有一定提升,尤其是MobileNet。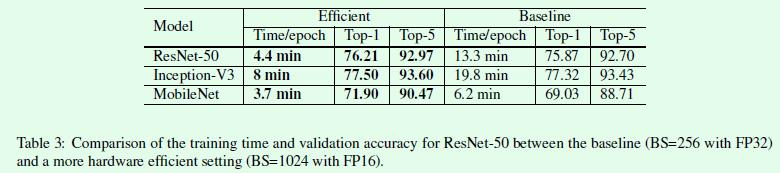
详细的对比实验可以参考Table4。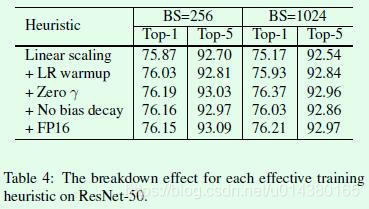
二、优化网络结构部分:
这部分的优化是以ResNet为例的,Figure1是ResNet网络的结构示意图,简单而言是一个input stem结构、4个stage和1个output部分,input stem和每个stage的内容在第二列展示,每个residual block的结构在第三列展示,整体而言这个图画得非常清晰了。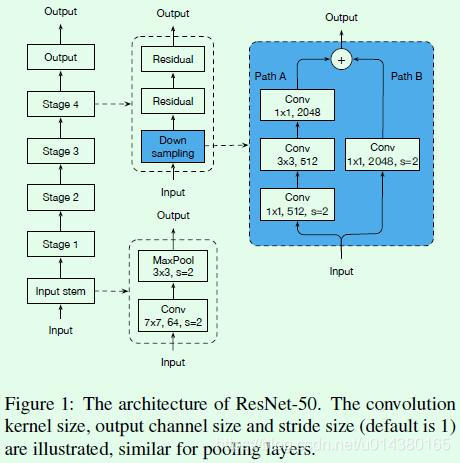
关于residual block的改进可以参考Figure2,主要有3点。
1、ResNet-B,改进部分就是将stage中做downsample的residual block的downsample操作从第一个11卷积层换成第二个33卷积层,如果downsample操作放在stride为2的11卷积层,那么就会丢失较多特征信息(默认是缩减为1/4),可以理解为有3/4的特征点都没有参与计算,而将downsample操作放在33卷积层则能够减少这种损失,因为即便stride设置为2,但是卷积核尺寸够大,因此可以覆盖特征图上几乎所有的位置。
2、ResNet-C,改进部分就是将Figure1中input stem部分的77卷积层用3个33卷积层替换。这部分借鉴了Inception v2的思想,主要的考虑是计算量,毕竟大尺寸卷积核带来的计算量要比小尺寸卷积核多不少,不过读者如果仔细计算下会发现ResNet-C中3个33卷积层的计算量并不比原来的少,这也是Table5中ResNet-C的FLOPs反而增加的原因。
3、ResNet-D,改进部分是将stage部分做downsample的residual block的支路从stride为2的11卷积层换成stride为1的卷积层,并在前面添加一个池化层用来做downsample。这部分我个人理解是虽然池化层也会丢失信息,但至少是经过选择(比如这里是均值操作)后再丢失冗余信息,相比stride设置为2的1*1卷积层要好一些。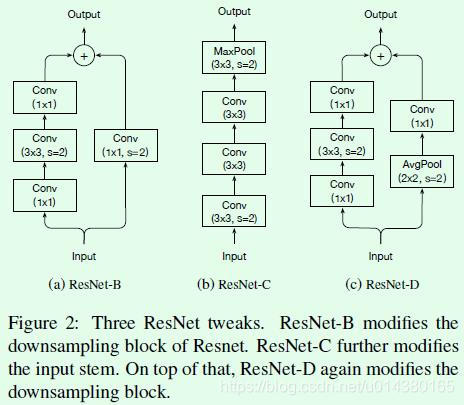
最终关于网络结构改进的效果如Table5所示,可以看出在效果提升方面还是比较明显的。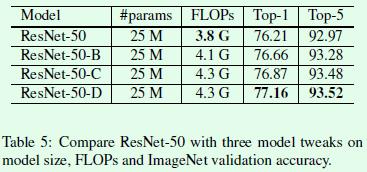
三、模型训练调优部分
这部分作者提到了4个调优技巧:
1、学习率衰减策略采用cosine函数,这部分的实验结果对比可以参考Figure3,其中(a)是cosine decay和step decay的示意图,step decay是目前比较常用的学习率衰减方式,表示训练到指定epoch时才衰减学习率。(b)是2种学习率衰减策略在效果上的对比。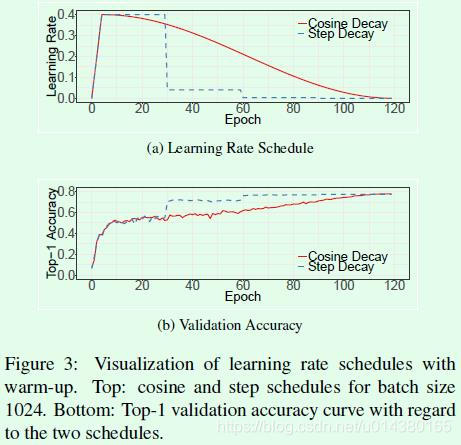
2、采用label smoothing,这部分是将原来常用的one-hot类型标签做软化,这样在计算损失值时能够在一定程度上减少过拟合。从交叉熵损失函数可以看出,只有真实标签对应的类别概率才会对损失值计算有所帮助,因此label smoothing相当于减少真实标签的类别概率在计算损失值时的权重,同时增加其他类别的预测概率在最终损失函数中的权重。这样真实类别概率和其他类别的概率均值之间的gap(倍数)就会下降一些,如下图所示。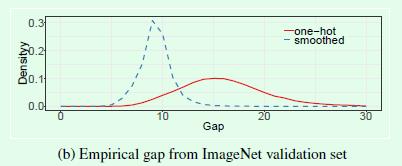
3、知识蒸馏(knowledge distillation),这部分其实是模型加速压缩领域的一个重要分支,表示用一个效果更好的teacher model训练student model,使得student model在模型结构不改变的情况下提升效果。作者采用ResNet-152作为teacher model,用ResNet-50作为student model,代码上通过在ResNet网络后添加一个蒸馏损失函数实现,这个损失函数用来评价teacher model输出和student model输出的差异,因此整体的损失函数原损失函数和蒸馏损失函数的结合: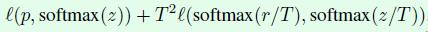
其中p表示真实标签,z表示student model的全连接层输出,r表示teacher model的全连接层输出,T是超参数,用来平滑softmax函数的输出。
4、引入mixup,mixup其实也是一种数据增强方式,假如采用mixup训练方式,那么每次读取2张输入图像,假设用(xi,yi)和(xj,yj)表示,那么通过下面这两个式子就可以合成得到一张新的图像(x,y),然后用这张新图像进行训练,需要注意的是采用这种方式训练模型时要训更多epoch。式子中的λ是一个超参数,用来调节合成的比重,取值范围是[0,1]。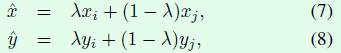
最终这4个调优技巧的实验结果对比如Table6所示。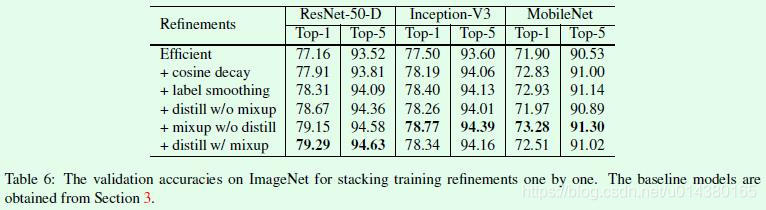
最后作者也证明了在分类算法中的这些优化点在其他图像任务中同样有效,比如目标检测任务,如Table8所示,可以看出在ImageNet数据集上表现最好的图像分类算法同样在VOC数据集上有最后的表现。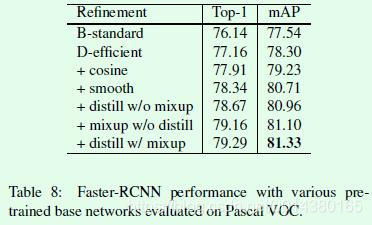
另外在语义分割任务上也有类似的迁移效果,如Table9所示。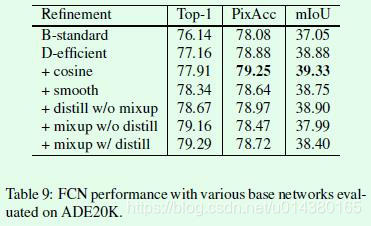
整体而言,这篇论文提供了模型优化方面的炼丹秘诀,采用作者复现的这些模型迁移到个人数据集上也能看到明显的效果提升,真的是非常实用。
以上是关于图像分类算法优化技巧的主要内容,如果未能解决你的问题,请参考以下文章