深度学习文字识别
Posted 5211314jackrose
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习文字识别相关的知识,希望对你有一定的参考价值。
Blog:https://blog.csdn.net/implok/article/details/95041472
步骤:
文字识别是AI的一个重要应用场景,文字识别过程一般由图像输入、预处理、文本检测、文本识别、结果输出等环节组成。

分类:文字识别可根据待识别的文字特点采用不同的识别方法,一般分为定长文字、不定长文字两大类别。
- 定长文字(例如手写数字识别、验证码),由于字符数量固定,采用的网络结构相对简单,识别也比较容易;
- 不定长文字(例如印刷文字、广告牌文字等),由于字符数量是不固定的,因此需要采用比较复杂的网络结构和后处理环节,识别也具有一定的难度。
一、定长文字识别
定长文字的识别相对简单,应用场景也比较局限,最典型的场景就是验证码的识别。由于字符数量是已知的、固定的,因此,网络结构比较简单,一般构建3层卷积层,2层全连接层便能满足“定长文字”的识别。
手写数字识别
MNIST是一个经典的手写数字数据集,来自美国国家标准与技术研究所,由不同人手写的0至9的数字构成,由60000个训练样本集和10000个测试样本集构成,每个样本的尺寸为28x28,以二进制格式存储,如下图所示:
MNIST手写数字识别模型的主要任务是:输入一张手写数字的图像,然后识别图像中手写的是哪个数字。
该模型的目标明确、任务简单,数据集规范、统一,数据量大小适中,在普通的PC电脑上都能训练和识别,算是深度学习领域的“Hello World”。
0、AI建模主要步骤
在构建AI模型时,一般有以下主要步骤:准备数据、数据预处理、划分数据集、配置模型、训练模型、评估优化、模型应用,如下图所示:
1、准确数据
准备数据是训练模型的第一步,基础数据可以是网上公开的数据集,也可以是自己的数据集。视觉、语音、语言等各种类型的数据在网上都能找到相应的数据集。
(1)使用MNIST数据
MNIST数据集由于非常经典,已集成在tensorflow里面,可以直接加载使用,也可以从MNIST的官网上(http://yann.lecun.com/exdb/mnist/) 直接下载数据集,代码如下:
from tensorflow.examples.tutorials.mnist import input_data # 数据集路径 data_dir=‘/home/roger/data/work/tensorflow/data/mnist‘ # 自动下载 MNIST 数据集 mnist = input_data.read_data_sets(data_dir, one_hot=True) # 如果自动下载失败,则手工从官网上下载 MNIST 数据集,然后进行加载 # 下载地址 http://yann.lecun.com/exdb/mnist/ #mnist=input_data.read_data_sets(data_dir,one_hot=True)
集成或下载的MNIST数据集已经是打好标签了,直接使用就行。
(2)使用自己的数据
如果是使用自己的数据集,在准备数据时的重要工作是“标注数据”,也就是对数据进行打标签,主要的标注方式有:
① 整个文件打标签。例如MNIST数据集,每个图像只有1个数字,可以从0至9建10个文件夹,里面放相应数字的图像;也可以定义一个规则对图像进行命名,如按标签+序号命名;还可以在数据库里面创建一张对应表,存储文件名与标签之间的关联关系。如下图:
② 圈定区域打标签。例如ImageNet的物体识别数据集,由于每张图片上有各种物体,这些物体位于不同位置,因此需要圈定某个区域进行标注,目前比较流行的是VOC2007、VOC2012数据格式,这是使用xml文件保存图片中某个物体的名称(name)和位置信息(xmin,ymin,xmax,ymax)。
如果图片很多,一张一张去计算位置信息,然后编写xml文件,实在是太耗时耗力了。所幸,有一位大神开源了一个数据标注工具labelImg(https://github.com/tzutalin/labelImg),只要在界面上画框标注,就能自动生成VOC格式的xml文件了,非常方便,如下图所示: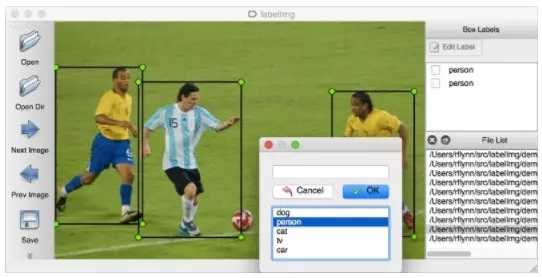
③ 数据截段打标签。针对语音识别、文字识别等,有些是将数据截成一段一段的语音或句子,然后在另外的文件中记录对应的标签信息。
2、数据预处理
在准备好基础数据之后,需要根据模型对基础数据进行相应的预处理。
(1)使用MNIST数据
由于MNIST数据集的尺寸统一,只有黑白两种像素,无须再进行额外的预处理,直接拿来建模型就行。
(2)使用自己的数据
而如果是要训练自己的数据,根据模型需要一般要进行以下预处理:
a. 统一格式:即统一基础数据的格式,例如图像数据集,则全部统一为jpg格式;语音数据集,则全部统一为wav格式;文字数据集,则全部统一为UTF-8的纯文本格式等,方便模型的处理;
b. 调整尺寸:根据模型的输入要求,将样本数据全部调整为统一尺寸。例如LeNet模型是32x32,AlexNet是224x224,VGG是224x224等;
c. 灰度化:根据模型需要,有些要求输入灰度图像,有些要求输入RGB彩色图像;
d. 去噪平滑:为提升输入图像的质量,对图像进行去噪平滑处理,可使用中值滤波器、高斯滤波器等进行图像的去噪处理。如果训练数据集的图像质量很好了,则无须作去噪处理;
e. 其它处理:根据模型需要进行直方图均衡化、二值化、腐蚀、膨胀等相关的处理;
f. 样本增强:有一种观点认为神经网络是靠数据喂出来的,如果能够增加训练数据的样本量,提供海量数据进行训练,则能够有效提升算法的质量。常见的样本增强方式有:水平翻转图像、随机裁剪、平移变换,颜色、光照变换等,如下图所示:

3、划分数据集
在训练模型之前,需要将样本数据划分为训练集、测试集,有些情况下还会划分为训练集、测试集、验证集。
(1)使用MNIST数据
本案例要训练模型的MNIST数据集,已经提供了训练集、测试集,代码如下:
# 提取训练集、测试集 train_xdata = mnist.train.images test_xdata = mnist.test.images # 提取标签数据 train_labels = mnist.train.labels test_labels = mnist.test.labels
(2)使用自己的数据
如果是要划分自己的数据集,可使用scikit-learn工具进行划分,代码如下:
from sklearn.cross_validation import train_test_split # 随机选取75%的数据作为训练样本,其余25%的数据作为测试样本 # X_data:数据集 # y_labels:数据集对应的标签 X_train,X_test,y_train,y_test=train_test_split(X_data,y_labels,test_size=0.25,random_state=33)
4、配置模型
接下来是选择模型、配置模型参数。
(1)选择模型
本案例将采用LeNet模型来训练MNIST手写数字模型,LeNet是一个经典卷积神经网络模型,结构简单,针对MNIST这种简单的数据集可达到比较好的效果,网络结构图如下: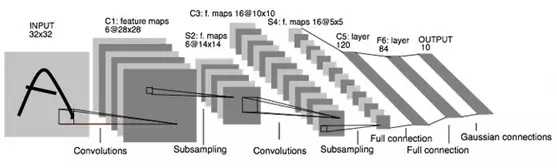
(2)设置参数
在训练模型时,一般要设置的参数有:
step_cnt=10000 # 训练模型的迭代步数 batch_size = 100 # 每次迭代批量取样本数据的量 learning_rate = 0.001 # 学习率
除此之外还有卷积层权重和偏置、池化层权重、全联接层权重和偏置、优化函数等等,根据模型需要进行设置。
5、训练模型
接下来便是根据选择好的模型,构建网络,然后开始训练。
(1)构建模型
本案例按照LeNet的网络模型结构,构建网络模型,网络结果如下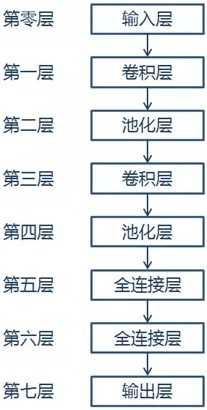
代码如下:
# 训练数据,占位符 x = tf.placeholder("float", shape=[None, 784]) # 训练的标签数据,占位符 y_ = tf.placeholder("float", shape=[None, 10]) # 将样本数据转为28x28 x_image = tf.reshape(x, [-1, 28, 28, 1]) # 保留概率,用于 dropout 层 keep_prob = tf.placeholder(tf.float32) # 第一层:卷积层 # 卷积核尺寸为5x5,通道数为1,深度为32,移动步长为1,采用ReLU激励函数 conv1_weights = tf.get_variable("conv1_weights", [5, 5, 1, 32], initializer=tf.truncated_normal_initializer(stddev=0.1)) conv1_biases = tf.get_variable("conv1_biases", [32], initializer=tf.constant_initializer(0.0)) conv1 = tf.nn.conv2d(x_image, conv1_weights, strides=[1, 1, 1, 1], padding=‘SAME‘) relu1 = tf.nn.relu(tf.nn.bias_add(conv1, conv1_biases)) # 第二层:最大池化层 # 池化核的尺寸为2x2,移动步长为2,使用全0填充 pool1 = tf.nn.max_pool(relu1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding=‘SAME‘) # 第三层:卷积层 # 卷积核尺寸为5x5,通道数为32,深度为64,移动步长为1,采用ReLU激励函数 conv2_weights = tf.get_variable("conv2_weights", [5, 5, 32, 64], initializer=tf.truncated_normal_initializer(stddev=0.1)) conv2_biases = tf.get_variable("conv2_biases", [64], initializer=tf.constant_initializer(0.0)) conv2 = tf.nn.conv2d(pool1, conv2_weights, strides=[1, 1, 1, 1], padding=‘SAME‘) relu2 = tf.nn.relu(tf.nn.bias_add(conv2, conv2_biases)) # 第四层:最大池化层 # 池化核尺寸为2x2, 移动步长为2,使用全0填充 pool2 = tf.nn.max_pool(relu2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding=‘SAME‘) # 第五层:全连接层 fc1_weights = tf.get_variable("fc1_weights", [7 * 7 * 64, 1024], initializer=tf.truncated_normal_initializer(stddev=0.1)) fc1_baises = tf.get_variable("fc1_baises", [1024], initializer=tf.constant_initializer(0.1)) pool2_vector = tf.reshape(pool2, [-1, 7 * 7 * 64]) fc1 = tf.nn.relu(tf.matmul(pool2_vector, fc1_weights) + fc1_baises) # Dropout层(即按keep_prob的概率保留数据,其它丢弃),以防止过拟合 fc1_dropout = tf.nn.dropout(fc1, keep_prob) # 第六层:全连接层 fc2_weights = tf.get_variable("fc2_weights", [1024, 10], initializer=tf.truncated_normal_initializer(stddev=0.1)) # 神经元节点数1024, 分类节点10 fc2_biases = tf.get_variable("fc2_biases", [10], initializer=tf.constant_initializer(0.1)) fc2 = tf.matmul(fc1_dropout, fc2_weights) + fc2_biases # 第七层:输出层 y_conv = tf.nn.softmax(fc2)
(2)训练模型
在训练模型时,需要选择优化器,也就是说要告诉模型以什么策略来提升模型的准确率,一般是选择交叉熵损失函数,然后使用优化器在反向传播时最小化损失函数,从而使模型的质量在不断迭代中逐步提升。
代码如下:
# 定义交叉熵损失函数 # y_ 为真实标签 cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y_conv), reduction_indices=[1])) # 选择优化器,使优化器最小化损失函数 train_step = tf.train.AdamOptimizer(learning_rate).minimize(cross_entropy) # 返回模型预测的最大概率的结果,并与真实值作比较 correct_prediction = tf.equal(tf.argmax(y_conv, 1), tf.argmax(y_, 1)) # 用平均值来统计测试准确率 accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32)) # 训练模型 saver=tf.train.Saver() with tf.Session() as sess: tf.global_variables_initializer().run() for step in range(step_cnt): batch = mnist.train.next_batch(batch_size) if step % 100 == 0: # 每迭代100步进行一次评估,输出结果,保存模型,便于及时了解模型训练进展 train_accuracy = accuracy.eval(feed_dict=x: batch[0], y_: batch[1], keep_prob: 1.0) print("step %d, training accuracy %g" % (step, train_accuracy)) saver.save(sess,model_dir+‘/my_mnist_model.ctpk‘,global_step=step) train_step.run(feed_dict=x: batch[0], y_: batch[1], keep_prob: 0.8) # 使用测试数据测试准确率 print("test accuracy %g" % accuracy.eval(feed_dict=x: mnist.test.images, y_: mnist.test.labels, keep_prob: 1.0))
训练的结果如下,由于MNIST数据集比较简单,模型训练很快就达到99%的准确率,如下图所示: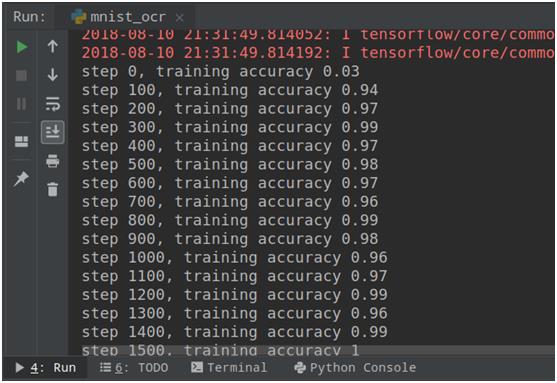
模型训练后保存的结果如下图所示:
6、评估优化
在使用训练数据完成模型的训练之后,再使用测试数据进行测试,了解模型的泛化能力,代码如下:
# 使用测试数据测试准确率 test_acc=accuracy.eval(feed_dict=x: test_xdata, y_: test_labels, keep_prob: 1.0) print("test accuracy %g" %test_acc)
模型测试结果如下: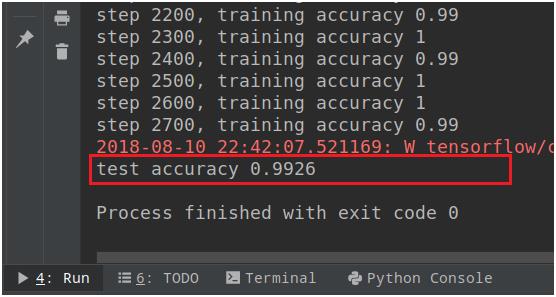
7、模型应用
模型训练完成后,将模型保存起来,当要实际应用时,则通过加载模型,输入图像进行应用。代码如下:
# 加载 MNIST 模型 saver = tf.train.Saver() with tf.Session() as sess: saver.restore(sess, tf.train.latest_checkpoint(model_dir)) # 随机提取 MNIST 测试集的一个样本数据和标签 test_len=len(mnist.test.images) test_idx=random.randint(0,test_len-1) x_image=mnist.test.images[test_idx] y=np.argmax(mnist.test.labels[test_idx]) # 跑模型进行识别 y_conv = tf.argmax(y_conv,1) pred=sess.run(y_conv,feed_dict=x:[x_image], keep_prob: 1.0) print(‘正确:‘,y,‘,预测:‘,pred[0])
使用模型进行测试的结果如下图: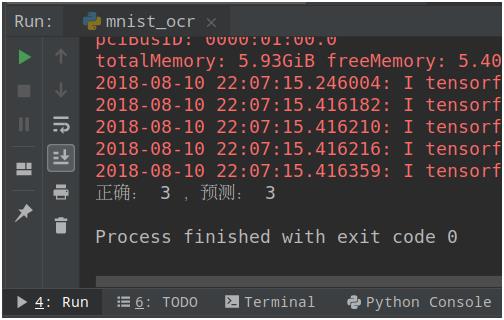
验证码
验证码在手机APP、Web网站中非常普遍,主要是为了防止恶意登录、刷票、灌水、爬虫等异常行为,也可能是为了缓解系统的后台压力(例如在秒杀、抢票时,强制要求输入验证码)。本文主要介绍文本型验证码的识别,文本型验证码由数字、英文大小写字母,甚至中文随机组成,再进行变形扭曲、加干扰线、加背景噪音等操作,主要是为了防止被光学字符识别(OCR)之类的程序自动识别出图片上的文字而失去效果,如下图:

由于存在着比较强的干扰信息,因此,直接使用OCR进行识别,效果很不理想,而通过AI可很好地实现这种复杂信息的识别。目前百度等AI开放平台,也提供了验证码识别的开放接口,但由于验证码可由各APP、网站根据任意自定的规则随机组合生成,因此,这些AI平台的验证码识别开放接口在某些场景下效果很好,在某些场景下可能就失灵了。针对具体的场景,我们通过自己训练验证码识别的AI模型,能很好地解决该场景下的验证码识别问题。
下面开始介绍使用Tensorflow构建验证码的识别模型,主要步骤如下:
- step 1. 获取验证码图片
- step 2. 图片标注
- step 3. 训练模型
- step 4. 模型应用
1、获取验证码图片
(1)如果是自己练习的,可直接随机生成验证码图片作为基础数据集。在python里面使用captcha库来快速生成验证码图片,通过pip install captcha进行安装,或者手动下载captcha-0.3-py3-none-any.whl文件进行安装。(注:anaconda无法通过conda install 直接安装captcha,但可使用anaconda里面的pip来安装captcha),核心代码如下:
from captcha.image import ImageCaptcha import random # 生成验证码的字符集 CHAR_SET = [‘0‘,‘1‘,‘2‘,‘3‘,‘4‘,‘5‘,‘6‘,‘7‘,‘8‘,‘9‘] CHAR_SET_LEN = len(CHAR_SET) # 验证码长度 CAPTCHA_LEN = 4 for i in range(CHAR_SET_LEN): for j in range(CHAR_SET_LEN): for k in range(CHAR_SET_LEN): for l in range(CHAR_SET_LEN): captcha_text = CHAR_SET[i] + CHAR_SET[j] + CHAR_SET[k] + CHAR_SET[l] image = ImageCaptcha() image.write(captcha_text, ‘/tmp/mydata/‘ + captcha_text + ‘.jpg‘)
生成的效果如下图

(2)如果是要针对某个网站的验证码进行识别的,则可使用一些工具将对应的验证码下载下来。一般网站登录的界面如下:
其中,通常可直接点击验证码图片,或旁边的“换一张”按钮,更换验证码图片。这时,可使用像“按键精灵”之类的模拟鼠标操作的软件,录制一段脚本,然后在验证码图片处模拟右键鼠标保存图片,再点击验证码图片更换新的验证码,如此反复,即可下载该网站的大量验证码图片,用于训练模型。
2、图片标注
如果第1步是自己随机生成验证码图片的,那么在保存图片时,文件名便是该验证码图片的文本内容,无须再进行标注。
如果第1步是下载了某个网站的验证码图片的,那么需要先人工对验证码图片的文本内容进行标注,以方便接下来的模型训练。可通过观察,将验证码图片的文本信息记在文件名中(重命名),通过这种方式进行图片标注,也可以单独记录在文本文件中。
3、训练模型
(1)标签one-hot编码
为了能够将验证码图片的文本信息输入到卷积神经网络模型里面去训练,需要将文本信息向量化编码。在这里使用“热独编码”(one-hot),即使用01编码表示文本信息。本项目的验证码文本长度为4位,验证码编码由0至9的数字组成,例如验证码文本信息为“1086”,则one-hot编码时在相应的位置标为1,其余为0,如下图:
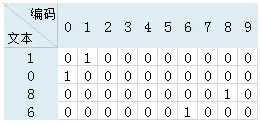
则“1086”经one-hot编码后变为[0 1 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 1 0 0 0] 。将验证码文本信息进行one-hot编码的核心代码如下:
def text2label(text): label = np.zeros(CAPTCHA_LEN * CHAR_SET_LEN) for i in range(len(text)): idx = i * CHAR_SET_LEN + CHAR_SET.index(text[i]) label[idx] = 1 return label
(2)读取图片文件
读取验证码图片、验证码文本内容(保存在文件名中),并编写获取下个批量数据的方法,主要函数如下:
# 获取验证码图片路径及文本内容 def get_image_file_name(img_path): img_files = [] img_labels = [] for root, dirs, files in os.walk(img_path): for file in files: if os.path.splitext(file)[1] == ‘.jpg‘: img_files.append(root+‘/‘+file) img_labels.append(text2label(os.path.splitext(file)[0])) return img_files,img_labels # 批量获取数据 def get_next_batch(img_files,img_labels,batch_size): batch_x = np.zeros([batch_size, IMAGE_WIDTH*IMAGE_HEIGHT]) batch_y = np.zeros([batch_size, CAPTCHA_LEN * CHAR_SET_LEN]) for i in range(batch_size): idx = random.randint(0, len(img_files) - 1) file_path = img_files[idx] image = cv2.imread(file_path) image = cv2.resize(image, (IMAGE_WIDTH, IMAGE_HEIGHT)) image = image.astype(np.float32) image = np.multiply(image, 1.0 / 255.0) batch_x[i, :] = image batch_y[i, :] = img_labels[idx] return batch_x,batch_y
(3)构建CNN模型
由于验证码的识别相对比较简单,借鉴LeNet的网络结构构建CNN模型,由3个卷积层和1个全连接层组成,网络结构图如下:
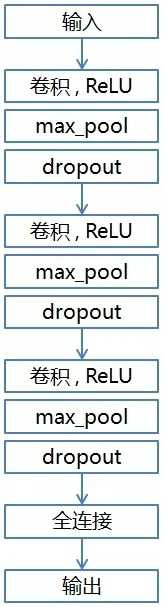
核心代码如下:
# 图像尺寸 IMAGE_HEIGHT = 60 IMAGE_WIDTH = 160 # 网络相关变量 X = tf.placeholder(tf.float32, [None, IMAGE_HEIGHT * IMAGE_WIDTH]) Y = tf.placeholder(tf.float32, [None, CAPTCHA_LEN * CHAR_SET_LEN]) keep_prob = tf.placeholder(tf.float32) # dropout # 验证码 CNN 网络 def crack_captcha_cnn_network (w_alpha=0.01, b_alpha=0.1): x = tf.reshape(X, shape=[-1, IMAGE_HEIGHT, IMAGE_WIDTH, 1]) w_c1 = tf.Variable(w_alpha * tf.random_normal([3, 3, 1, 32])) b_c1 = tf.Variable(b_alpha * tf.random_normal([32])) conv1 = tf.nn.relu(tf.nn.bias_add(tf.nn.conv2d(x, w_c1, strides=[1, 1, 1, 1], padding=‘SAME‘), b_c1)) conv1 = tf.nn.max_pool(conv1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding=‘SAME‘) conv1 = tf.nn.dropout(conv1, keep_prob) w_c2 = tf.Variable(w_alpha * tf.random_normal([3, 3, 32, 64])) b_c2 = tf.Variable(b_alpha * tf.random_normal([64])) conv2 = tf.nn.relu(tf.nn.bias_add(tf.nn.conv2d(conv1, w_c2, strides=[1, 1, 1, 1], padding=‘SAME‘), b_c2)) conv2 = tf.nn.max_pool(conv2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding=‘SAME‘) conv2 = tf.nn.dropout(conv2, keep_prob) w_c3 = tf.Variable(w_alpha * tf.random_normal([3, 3, 64, 64])) b_c3 = tf.Variable(b_alpha * tf.random_normal([64])) conv3 = tf.nn.relu(tf.nn.bias_add(tf.nn.conv2d(conv2, w_c3, strides=[1, 1, 1, 1], padding=‘SAME‘), b_c3)) conv3 = tf.nn.max_pool(conv3, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding=‘SAME‘) conv3 = tf.nn.dropout(conv3, keep_prob) w_d = tf.Variable(w_alpha * tf.random_normal([8 * 20 * 64, 1024])) b_d = tf.Variable(b_alpha * tf.random_normal([1024])) dense = tf.reshape(conv3, [-1, w_d.get_shape().as_list()[0]]) dense = tf.nn.relu(tf.add(tf.matmul(dense, w_d), b_d)) dense = tf.nn.dropout(dense, keep_prob) w_out = tf.Variable(w_alpha * tf.random_normal([1024, CAPTCHA_LEN * CHAR_SET_LEN])) b_out = tf.Variable(b_alpha * tf.random_normal([CAPTCHA_LEN * CHAR_SET_LEN])) out = tf.add(tf.matmul(dense, w_out), b_out) return out
(4)训练模型
通过设置好模型训练的迭代轮次、批量获取样本数量、学习率等参数,读取验证码图片集,并随机划分出训练集、测试集,再加载本项目的网络模型进行训练,每100步评估一次准确率和保存模型文件。核心代码如下:
# 模型的相关参数 step_cnt = 200000 # 迭代轮数 batch_size = 16 # 批量获取样本数量 learning_rate = 0.0001 # 学习率 # 读取验证码图片集 img_path = ‘/tmp/mydata/‘ img_files, img_labels = get_image_file_name(img_path) # 划分出训练集、测试集 x_train,x_test,y_train,y_test=train_test_split(img_files,img_labels,test_size=0.2,random_state=33) # 加载网络结构 output = crack_captcha_cnn_network() # 损失函数、优化器 loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=output, labels=Y)) optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(loss) # 评估准确率 predict = tf.reshape(output, [-1, CAPTCHA_LEN, CHAR_SET_LEN]) max_idx_p = tf.argmax(predict, 2) max_idx_l = tf.argmax(tf.reshape(Y, [-1, CAPTCHA_LEN, CHAR_SET_LEN]), 2) correct_pred = tf.equal(max_idx_p, max_idx_l) accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32)) with tf.Session() as sess: sess.run(tf.global_variables_initializer()) saver = tf.train.Saver(tf.global_variables(), max_to_keep=5) for step in range(step_cnt): # 训练模型 batch_x, batch_y = get_next_batch(x_train, y_train,batch_size) _, loss_ = sess.run([optimizer, loss], feed_dict=X: batch_x, Y: batch_y, keep_prob: 0.75) print(‘step:‘,step, ‘loss:‘,loss_) # 每100步评估一次准确率 if step % 100 == 0: batch_x_test, batch_y_test = get_next_batch(x_test, y_test,batch_size) acc = sess.run(accuracy, feed_dict=X: batch_x_test, Y: batch_y_test, keep_prob: 1.) print(‘step:‘,step,‘acc:‘,acc) # 保存模型 saver.save(sess, ‘/tmp/mymodel/crack_captcha.ctpk‘, global_step=step) step += 1
训练的过程如下图所示:
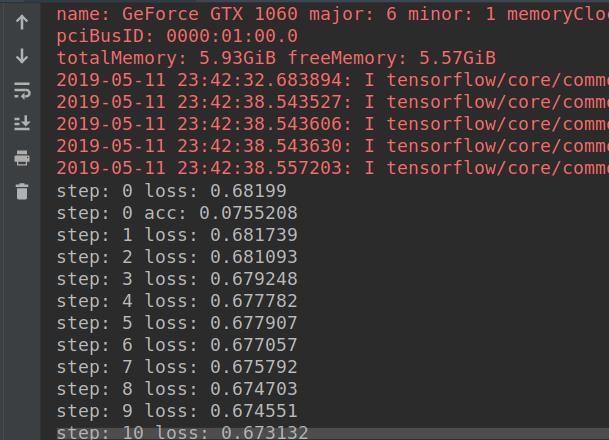
经过一段时间的训练后,评估的准确率可达到99%以上,能非常准确地识别出验证码。
4、模型应用
通过加载训练好后的模型文件,即可输入图片进行验证码识别,核心代码如下:
# 加载网络结构 output = crack_captcha_cnn_network() saver = tf.train.Saver() with tf.Session() as sess: model_path = ‘/tmp/mymodel/‘ saver.restore(sess, tf.train.latest_checkpoint(model_path)) output_rate=tf.reshape(output, [-1, CAPTCHA_LEN, CHAR_SET_LEN]) predict = tf.argmax(output_rate, 2) text_list,rate_list = sess.run([predict,output_rate], feed_dict=X: [captcha_image], keep_prob: 1) # captcha_image 为待识别的验证码图片 tmptext = text_list[0].tolist() text=‘‘ for i in range(len(tmptext)): text = text + CHAR_SET[tmptext[i]] print(‘识别结果:‘,text)
二、不定长文字识别
不定长文字在现实中大量存在,例如印刷文字、广告牌文字等,由于字符数量不固定、不可预知,因此,识别的难度也较大,这也是目前研究文字识别的主要方向。下面介绍不定长文字识别的常用方法:LSTM+CTC、CRNN、ChinsesOCR。
1、LSTM+CTC方法
(1)什么是LSTM
为了实现对不定长文字的识别,就需要有一种能力更强的模型,该模型具有一定的记忆能力,能够按时序依次处理任意长度的信息,这种模型就是“循环神经网络(Recurrent Neural Networks/RNN)”。
LSTM(Long Short Term Memory,长短期记忆网络)是一种特殊结构的RNN(循环神经网络),用于解决RNN的长期依赖问题,也即随着输入RNN网络的信息的时间间隔不断增大,普通RNN就会出现“梯度消失”或“梯度爆炸”的现象,这就是RNN的长期依赖问题,而引入LSTM即可以解决这个问题。LSTM单元由输入门(Input Gate)、遗忘门(Forget Gate)和输出门(Output Gate)组成,LSTM的结构如下图所示: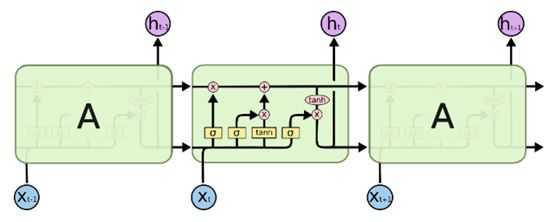
(2)什么是CTC
CTC(Connectionist Temporal Classifier,联接时间分类器),主要用于解决输入特征与输出标签的对齐问题。例如下图,由于文字的不同间隔或变形等问题,导致同个文字有不同的表现形式,但实际上都是同一个文字。在识别时会将输入图像分块后再去识别,得出每块属于某个字符的概率(无法识别的标记为特殊字符”-”),如下图:
由于字符变形等原因,导致对输入图像分块识别时,相邻块可能会识别为同个结果,字符重复出现。因此,通过CTC来解决对齐问题,模型训练后,对结果中去掉间隔字符、去掉重复字符(如果同个字符连续出现,则表示只有1个字符,如果中间有间隔字符,则表示该字符出现多次),如下图所示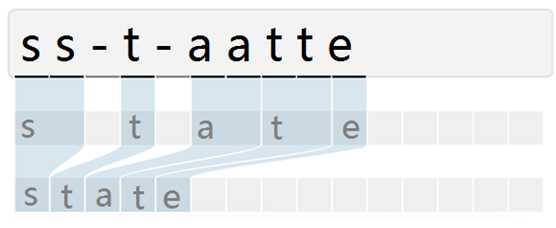
(3)LSTM+CTC实现:常量定义
定义一些常量,在模型训练和预测中使用,定义如下:
# 数据集,可根据需要增加英文或其它字符 DIGITS = [‘0‘, ‘1‘, ‘2‘, ‘3‘, ‘4‘, ‘5‘, ‘6‘, ‘7‘, ‘8‘, ‘9‘] # 分类数量 num_classes = len(DIGITS) + 1 # 数据集字符数+特殊标识符 # 图片大小,32 x 256 OUTPUT_SHAPE = (32, 256) # 学习率 INITIAL_LEARNING_RATE = 1e-3 DECAY_STEPS = 5000 REPORT_STEPS = 100 LEARNING_RATE_DECAY_FACTOR = 0.9 MOMENTUM = 0.9 # LSTM网络层次 num_hidden = 128 num_layers = 2 # 训练轮次、批量大小 num_epochs = 50000 BATCHES = 10 BATCH_SIZE = 32 TRAIN_SIZE = BATCHES * BATCH_SIZE # 数据集目录、模型目录 data_dir = ‘/tmp/lstm_ctc_data/‘ model_dir = ‘/tmp/lstm_ctc_model/‘
(4)LSTM+CTC实现:随机生成不定长图片数据
为了训练和测试LSTM+CTC识别模型,先要准备好基础数据,可根据需要准备好已标注的文本图片集。在这里,为了方便训练和测试模型,随机生成10000张不定长的图片数据集。通过使用Pillow生成图片和绘上文字,并对图片随机叠加椒盐噪声,以更加贴近现实场景。核心代码如下:
# 生成椒盐噪声 def img_salt_pepper_noise(src,percetage): NoiseImg=src NoiseNum=int(percetage*src.shape[0]*src.shape[1]) for i in range(NoiseNum): randX=random.randint(0,src.shape[0]-1) randY=random.randint(0,src.shape[1]-1) if random.randint(0,1)==0: NoiseImg[randX,randY]=0 else: NoiseImg[randX,randY]=255 return NoiseImg # 随机生成不定长图片集 def gen_text(cnt): # 设置文字字体和大小 font_path = ‘/data/work/tensorflow/fonts/arial.ttf‘ font_size = 30 font=ImageFont.truetype(font_path,font_size) for i in range(cnt): # 随机生成1到10位的不定长数字 rnd = random.randint(1, 10) text = ‘‘ for j in range(rnd): text = text + DIGITS[random.randint(0, len(DIGITS) - 1)] # 生成图片并绘上文字 img=Image.new("RGB",(256,32)) draw=ImageDraw.Draw(img) draw.text((1,1),text,font=font,fill=‘white‘) img=np.array(img) # 随机叠加椒盐噪声并保存图像 img = img_salt_pepper_noise(img, float(random.randint(1,10)/100.0)) cv2.imwrite(data_dir + text + ‘_‘ + str(i+1) + ‘.jpg‘,img)
随机生成的不定长数据效果如下:
执行 gen_text(10000) 后生成的图片集如下,文件名由序号和文字标签组成:

(5)LSTM+CTC实现:标签向量化(稀疏矩阵)
由于文字是不定长的,因此,如果读取图片并获取标签,然后将标签存放在一个紧密矩阵中进行向量化,那将会出现大量的零元素,很浪费空间。因此,使用稀疏矩阵对标签进行向量化。所谓“稀疏矩阵”就是矩阵中的零元素远远多于非零元素,采用这种方式存储可有效节约空间。
稀疏矩阵有3个属性,分别是:
- indices:二维矩阵,代表非零的坐标点
- values:二维tensor,代表indice位置的数据值
- dense_shape:一维,代表稀疏矩阵的大小(取行数和列的最大长度)
例如读取了以下图片和相应的标签,那么存储为稀疏矩阵的结果如下: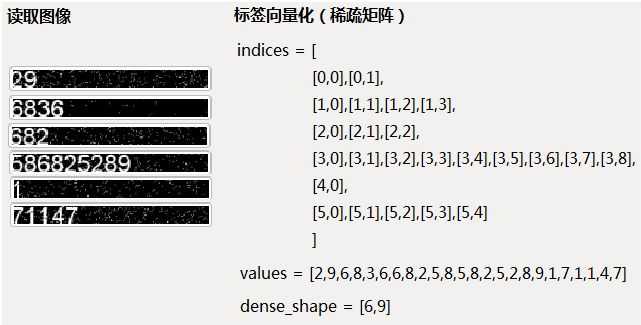
将标签转为稀疏矩阵,对标签进行向量化,核心代码如下:
# 序列转为稀疏矩阵 # 输入:序列 # 输出:indices非零坐标点,values数据值,shape稀疏矩阵大小 def sparse_tuple_from(sequences, dtype=np.int32): indices = [] values = [] for n, seq in enumerate(sequences): indices.extend(zip([n] * len(seq), range(len(seq)))) values.extend(seq) indices = np.asarray(indices, dtype=np.int64) values = np.asarray(values, dtype=dtype) shape = np.asarray([len(sequences), np.asarray(indices).max(0)[1] + 1], dtype=np.int64) return indices, values, shape
将稀疏矩阵转为标签,用于输出结果,核心代码如下:
# 稀疏矩阵转为序列 # 输入:稀疏矩阵 # 输出:序列 def decode_sparse_tensor(sparse_tensor): decoded_indexes = list() current_i = 0 current_seq = [] for offset, i_and_index in enumerate(sparse_tensor[0]): i = i_and_index[0] if i != current_i: decoded_indexes.append(current_seq) current_i = i current_seq = list() current_seq.append(offset) decoded_indexes.append(current_seq) result = [] for index in decoded_indexes: result.append(decode_a_seq(index, sparse_tensor)) return result # 序列编码转换 def decode_a_seq(indexes, spars_tensor): decoded = [] for m in indexes: str = DIGITS[spars_tensor[1][m]] decoded.append(str) return decoded
(6)LSTM+CTC实现:读取数据
读取图像数据以及进行标签向量化,以便于输入到模型进行训练,核心代码如下:
# 将文件和标签读到内存,减少磁盘IO def get_file_text_array(): file_name_array=[] text_array=[] for parent, dirnames, filenames in os.walk(data_dir): file_name_array=filenames for f in file_name_array: text = f.split(‘_‘)[0] text_array.append(text) return file_name_array,text_array # 获取训练的批量数据 def get_next_batch(file_name_array,text_array,batch_size=64): inputs = np.zeros([batch_size, OUTPUT_SHAPE[1], OUTPUT_SHAPE[0]]) codes = [] # 获取训练样本 for i in range(batch_size): index = random.randint(0, len(file_name_array) - 1) image = cv2.imread(data_dir + file_name_array[index]) image = cv2.resize(image, (OUTPUT_SHAPE[1], OUTPUT_SHAPE[0]), 3) image = cv2.cvtColor(image,cv2.COLOR_RGB2GRAY) text = text_array[index] # 矩阵转置 inputs[i, :] = np.transpose(image.reshape((OUTPUT_SHAPE[0], OUTPUT_SHAPE[1]))) # 标签转成列表 codes.append(list(text)) # 标签转成稀疏矩阵 targets = [np.asarray(i) for i in codes] sparse_targets = sparse_tuple_from(targets) seq_len = np.ones(inputs.shape[0]) * OUTPUT_SHAPE[1] return inputs, sparse_targets, seq_len
(7)LSTM+CTC实现:构建网络
利用tensorflow内置的LSTM单元构建网络,核心代码如下:
def get_train_model(): # 输入 inputs = tf.placeholder(tf.float32, [None, None, OUTPUT_SHAPE[0]]) # 稀疏矩阵 targets = tf.sparse_placeholder(tf.int32) # 序列长度 [batch_size,] seq_len = tf.placeholder(tf.int32, [None]) # 定义LSTM网络 cell = tf.contrib.rnn.LSTMCell(num_hidden, state_is_tuple=True) stack = tf.contrib.rnn.MultiRNNCell([cell] * num_layers, state_is_tuple=True) # old outputs, _ = tf.nn.dynamic_rnn(cell, inputs, seq_len, dtype=tf.float32) shape = tf.shape(inputs) batch_s, max_timesteps = shape[0], shape[1] outputs = tf.reshape(outputs, [-1, num_hidden]) W = tf.Variable(tf.truncated_normal([num_hidden, num_classes], stddev=0.1), name="W") b = tf.Variable(tf.constant(0., shape=[num_classes]), name="b") logits = tf.matmul(outputs, W) + b logits = tf.reshape(logits, [batch_s, -1, num_classes]) # 转置矩阵 logits = tf.transpose(logits, (1, 0, 2)) return logits, inputs, targets, seq_len, W, b
(8)LSTM+CTC实现:模型训练
在训练之前,先定义好准确率评估方法,以便于在训练过程中不断评估模型的准确性,核心代码如下:
# 准确性评估 # 输入:预测结果序列 decoded_list ,目标序列 test_targets # 返回:准确率 def report_accuracy(decoded_list, test_targets): original_list = decode_sparse_tensor(test_targets) detected_list = decode_sparse_tensor(decoded_list) # 正确数量 true_numer = 0 # 预测序列与目标序列的维度不一致,说明有些预测失败,直接返回 if len(original_list) != len(detected_list): print("len(original_list)", len(original_list), "len(detected_list)", len(detected_list), " test and detect length desn‘t match") return # 比较预测序列与结果序列是否一致,并统计准确率 print("T/F: original(length) <-------> detectcted(length)") for idx, number in enumerate(original_list): detect_number = detected_list[idx] hit = (number == detect_number) print(hit, number, "(", len(number), ") <-------> ", detect_number, "(", len(detect_number), ")") if hit: true_numer = true_numer + 1 accuracy = true_numer * 1.0 / len(original_list) print("Test Accuracy:", accuracy) return accuracy
接着开始对模型进行训练,核心代码如下:
def train(): # 获取训练样本数据 file_name_array, text_array = get_file_text_array() # 定义学习率 global_step = tf.Variable(0, trainable=False) learning_rate = tf.train.exponential_decay(INITIAL_LEARNING_RATE, global_step, DECAY_STEPS, LEARNING_RATE_DECAY_FACTOR, staircase=True) # 获取网络结构 logits, inputs, targets, seq_len, W, b = get_train_model() # 设置损失函数 loss = tf.nn.ctc_loss(labels=targets, inputs=logits, sequence_length=seq_len) cost = tf.reduce_mean(loss) # 设置优化器 optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(loss, global_step=global_step) decoded, log_prob = tf.nn.ctc_beam_search_decoder(logits, seq_len, merge_repeated=False) acc = tf.reduce_mean(tf.edit_distance(tf.cast(decoded[0], tf.int32), targets)) init = tf.global_variables_initializer() config = tf.ConfigProto() config.gpu_options.allow_growth = True with tf.Session() as session: session.run(init) saver = tf.train.Saver(tf.global_variables(), max_to_keep=10) for curr_epoch in range(num_epochs): train_cost = 0 train_ler = 0 for batch in range(BATCHES): # 训练模型 train_inputs, train_targets, train_seq_len = get_next_batch(file_name_array, text_array, BATCH_SIZE) feed = inputs: train_inputs, targets: train_targets, seq_len: train_seq_len b_loss, b_targets, b_logits, b_seq_len, b_cost, steps, _ = session.run( [loss, targets, logits, seq_len, cost, global_step, optimizer], feed) # 评估模型 if steps > 0 and steps % REPORT_STEPS == 0: test_inputs, test_targets, test_seq_len = get_next_batch(file_name_array, text_array, BATCH_SIZE) test_feed = inputs: test_inputs,targets: test_targets,seq_len: test_seq_len dd, log_probs, accuracy = session.run([decoded[0], log_prob, acc], test_feed) report_accuracy(dd, test_targets) # 保存识别模型 save_path = saver.save(session, model_dir + "lstm_ctc_model.ctpk",global_step=steps) c = b_cost train_cost += c * BATCH_SIZE train_cost /= TRAIN_SIZE # 计算 loss train_inputs, train_targets, train_seq_len = get_next_batch(file_name_array, text_array, BATCH_SIZE) val_feed = inputs: train_inputs,targets: train_targets,seq_len: train_seq_len val_cost, val_ler, lr, steps = session.run([cost, acc, learning_rate, global_step], feed_dict=val_feed) log = " Epoch /, steps = , train_cost = :.3f, val_cost = :.3f" print(log.format(curr_epoch + 1, num_epochs, steps, train_cost, val_cost))
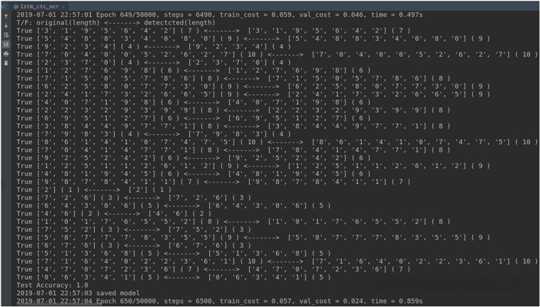
经过一段时间的训练,执行了600多步后,评估的准确性已全部预测正确,如下图:
(9)LSTM+CTC实现:能力封装
为了方便其它程序调用LSTM+CTC的识别能力,对识别能力进行封装,只需要输入一张图片,即可识别后返回结果。核心代码如下:
# LSTM+CTC 文字识别能力封装 # 输入:图片 # 输出:识别结果文字 def predict(image): # 获取网络结构 logits, inputs, targets, seq_len, W, b = get_train_model() decoded, log_prob = tf.nn.ctc_beam_search_decoder(logits, seq_len, merge_repeated=False) saver = tf.train.Saver() with tf.Session() as sess: # 加载模型 saver.restore(sess, tf.train.latest_checkpoint(model_dir)) # 图像预处理 image = cv2.resize(image, (OUTPUT_SHAPE[1], OUTPUT_SHAPE[0]), 3) image = cv2.cvtColor(image, cv2.COLOR_RGB2GRAY) pred_inputs = np.zeros([1, OUTPUT_SHAPE[1], OUTPUT_SHAPE[0]]) pred_inputs[0, :] = np.transpose(image.reshape((OUTPUT_SHAPE[0], OUTPUT_SHAPE[1]))) pred_seq_len = np.ones(1) * OUTPUT_SHAPE[1] # 模型预测 pred_feed = inputs: pred_inputs,seq_len: pred_seq_len dd, log_probs = sess.run([decoded[0], log_prob], pred_feed) # 识别结果转换 detected_list = decode_sparse_tensor(dd)[0] detected_text = ‘‘ for d in detected_list: detected_text = detected_text + d return detected_text
2、CRNN 方法
CRNN(Convolutional Recurrent Neural Network,卷积循环神经网络)是目前比较流行的文字识别模型,不需要对样本数据进行字符分割,可识别任意长度的文本序列,模型速度快、性能好。网络结构如下图所示,主要由卷积层、循环层、转录层3部分组成: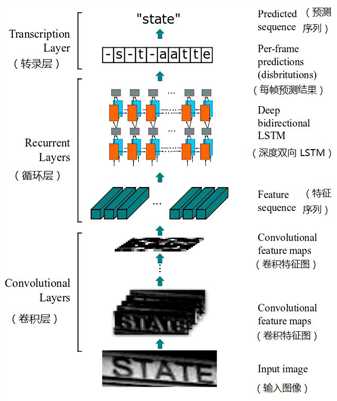
(1)下载源代码 - https://github.com/Belval/CRNN(git clone https://github.com/Belval/CRNN.git)
(2)准备基础数据
使用第1节LSTM+CTC介绍的方法随机生成10000张不定长图片+椒盐噪声作为基础数据集,具体详见第1节的生成基础数据代码,在此不再重复。注意,由于该CRNN源代码在读取图片时默认文件名第1位为标签(以下划线 ”_” 隔开),于是注意按照文件命名规则生成图片。
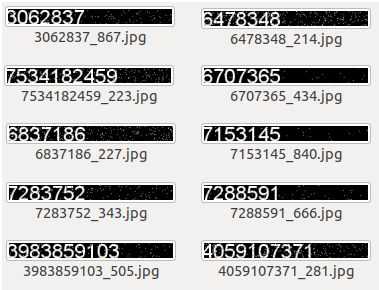
(3)训练模型
参考CRNN/run.py里面的代码,编写模型训练的调用代码如下:
# 模型训练 def train(): # 设置基本属性 batch_size=32 # 批量大小 max_image_width=400 # 最大图片宽度 train_test_ratio=0.75 # 训练集、测试集划分比例 restore=True # 是否恢复加载模型,可用于多次加载训练 iteration_count=1000 # 迭代次数 # 初始化调用CRNN crnn = CRNN( batch_size, model_dir, data_dir, max_image_width, train_test_ratio, restore ) # 模型训练 crnn.train(iteration_count)
经过了5个小时左右,迭代训练了263次,使得loss(损失值)已降低至接近1,模型也已基本上可用。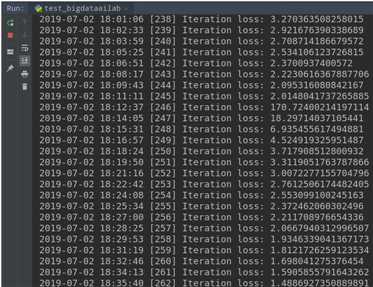
CRNN的训练过程很长,本案例随机生成的文字还是比较简单的,但每步的迭代就已耗时很长。如果是实际应用中,需要使用背景更加复杂、文字形态更加多样的数据集,对训练loss的要求也更高,这时会使得整个训练过程更长。因此,一般会采用“迁移学习”的方式来提升训练效率和模型效果。
(4)模型测试
参考CRNN/run.py里面的代码,编写模型测试的代码,可输出测试结果,代码如下:
# 模型测试 def test(): # 设置基本属性 batch_size=32 max_image_width=400 restore=True # 初始化CRNN crnn = CRNN( batch_size, model_dir, data_dir, max_image_width, 0, restore ) # 测试模型 crnn.test()
测试的结果如下,程序会批量读入数据后,输入原始结果(第一行)和预测结果(第二行),便于比较两者是否一致。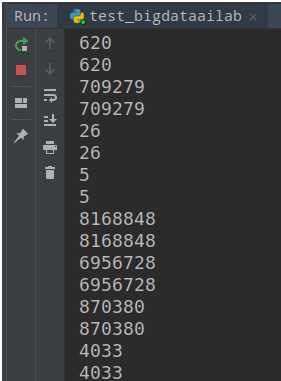
作者提供的这种测试方式太考验人眼了,我们可将CRNN里面的test函数进行个小修改,自动计算准确率,将会方便很多。修改的代码如下:
def test(self): with self.__session.as_default(): print(‘Testing‘) for batch_y, _, batch_x in self.__data_manager.test_batches: decoded = self.__session.run( self.__decoded, feed_dict= self.__inputs: batch_x, self.__seq_len: [self.__max_char_count] * self.__data_manager.batch_size ) # 修改,统计准确率 true_cnt = 0 for i, y in enumerate(batch_y): if batch_y[i] == ground_truth_to_word(decoded[i]): true_cnt = true_cnt + 1 else: # 预测结果不一致的,才显示出来 print(‘target:‘,batch_y[i]) print(‘predict:‘,ground_truth_to_word(decoded[i])) print(‘acc:‘,float(true_cnt)/float(len(batch_y))) return None
(5)能力封装
为了方便将CRNN识别能力提供给其它程序调用,在CRNN/crnn.py代码的基础上进行修改,对CRNN识别能力进行封装,即只需输入指定的图片,即可返回识别结果。
首先是重写crnn.py里面加载CRNN网络结构的方式,由于原先的代码在初始化时只支持批量的图片进行训练和测试,为了实现对指定的某张图片进行识别,对网络模型的初始化和调用方式进行修改,核心代码如下:
# CRNN 网络结构 def crnn_network(max_width, batch_size): # 双向RNN def BidirectionnalRNN(inputs, seq_len): # rnn-1 with tf.variable_scope(None, default_name="bidirectional-rnn-1"): # Forward lstm_fw_cell_1 = rnn.BasicLSTMCell(256) # Backward lstm_bw_cell_1 = rnn.BasicLSTMCell(256) inter_output, _ = tf.nn.bidirectional_dynamic_rnn(lstm_fw_cell_1, lstm_bw_cell_1, inputs, seq_len, dtype=tf.float32) inter_output = tf.concat(inter_output, 2) # rnn-2 with tf.variable_scope(None, default_name="bidirectional-rnn-2"): # Forward lstm_fw_cell_2 = rnn.BasicLSTMCell(256) # Backward lstm_bw_cell_2 = rnn.BasicLSTMCell(256) outputs, _ = tf.nn.bidirectional_dynamic_rnn(lstm_fw_cell_2, lstm_bw_cell_2, inter_output, seq_len, dtype=tf.float32) outputs = tf.concat(outputs, 2) return outputs # CNN,用于提取特征 def CNN(inputs): # 64 / 3 x 3 / 1 / 1 conv1 = tf.layers.conv2d(inputs=inputs, filters = 64, kernel_size = (3, 3), padding = "same", activation=tf.nn.relu) # 2 x 2 / 1 pool1 = tf.layers.max_pooling2d(inputs=conv1, pool_size=[2, 2], strides=2) # 128 / 3 x 3 / 1 / 1 conv2 = tf.layers.conv2d(inputs=pool1, filters = 128, kernel_size = (3, 3), padding = "same", activation=tf.nn.relu) # 2 x 2 / 1 pool2 = tf.layers.max_pooling2d(inputs=conv2, pool_size=[2, 2], strides=2) # 256 / 3 x 3 / 1 / 1 conv3 = tf.layers.conv2d(inputs=pool2, filters = 256, kernel_size = (3, 3), padding = "same", activation=tf.nn.relu) # Batch normalization layer bnorm1 = tf.layers.batch_normalization(conv3) # 256 / 3 x 3 / 1 / 1 conv4 = tf.layers.conv2d(inputs=bnorm1, filters = 256, kernel_size = (3, 3), padding = "same", activation=tf.nn.relu) # 1 x 2 / 1 pool3 = tf.layers.max_pooling2d(inputs=conv4, pool_size=[2, 2], strides=[1, 2], padding="same") # 512 / 3 x 3 / 1 / 1 conv5 = tf.layers.conv2d(inputs=pool3, filters = 512, kernel_size = (3, 3), padding = "same", activation=tf.nn.relu) # Batch normalization layer bnorm2 = tf.layers.batch_normalization(conv5) # 512 / 3 x 3 / 1 / 1 conv6 = tf.layers.conv2d(inputs=bnorm2, filters = 512, kernel_size = (3, 3), padding = "same", activation=tf.nn.relu) # 1 x 2 / 2 pool4 = tf.layers.max_pooling2d(inputs=conv6, pool_size=[2, 2], strides=[1, 2], padding="same") # 512 / 2 x 2 / 1 / 0 conv7 = tf.layers.conv2d(inputs=pool4, filters = 512, kernel_size = (2, 2), padding = "valid", activation=tf.nn.relu) return conv7 # 定义输入、输出、序列长度 inputs = tf.placeholder(tf.float32, [batch_size, max_width, 32, 1]) targets = tf.sparse_placeholder(tf.int32, name=‘targets‘) seq_len = tf.placeholder(tf.int32, [None], name=‘seq_len‘) # 卷积层提取特征 cnn_output = CNN(inputs) reshaped_cnn_output = tf.reshape(cnn_output, [batch_size, -1, 512]) max_char_count = reshaped_cnn_output.get_shape().as_list()[1] # 循环层处理序列 crnn_model = BidirectionnalRNN(reshaped_cnn_output, seq_len) logits = tf.reshape(crnn_model, [-1, 512]) # 转录层预测结果 W = tf.Variable(tf.truncated_normal([512, config.NUM_CLASSES], stddev=0.1), name="W") b = tf.Variable(tf.constant(0., shape=[config.NUM_CLASSES]), name="b") logits = tf.matmul(logits, W) + b logits = tf.reshape(logits, [batch_size, -1, config.NUM_CLASSES]) logits = tf.transpose(logits, (1, 0, 2)) # 定义损失函数、优化器 loss = tf.nn.ctc_loss(targets, logits, seq_len) cost = tf.reduce_mean(loss) optimizer = tf.train.AdamOptimizer(learning_rate=0.0001).minimize(cost) decoded, log_prob = tf.nn.ctc_beam_search_decoder(logits, seq_len, merge_repeated=False) dense_decoded = tf.sparse_tensor_to_dense(decoded[0], default_value=-1) acc = tf.reduce_mean(tf.edit_distance(tf.cast(decoded[0], tf.int32), targets)) # 初始化 init = tf.global_variables_initializer() return inputs, targets, seq_len, logits, dense_decoded, optimizer, acc, cost, max_char_count, init # CRNN 识别文字 # 输入:图片路径 # 输出:识别文字结果 def predict(img_path): # 定义模型路径、最长图片宽度 batch_size = 1 model_path = ‘/tmp/crnn_model/‘ max_image_width = 400 # 创建会话 __session = tf.Session() with __session.as_default(): ( __inputs, __targets, __seq_len, __logits, __decoded, __optimizer, __acc, __cost, __max_char_count, __init ) = crnn_network(max_image_width, batch_size) __init.run() # 加载模型 with __session.as_default(): __saver = tf.train.Saver() ckpt = tf.train.latest_checkpoint(model_path) if ckpt: __saver.restore(__session, ckpt) # 读取图片作为输入 arr, initial_len = utils.resize_image(img_path,max_image_width) batch_x = np.reshape( np.array(arr), (-1, max_image_width, 32, 1) ) # 利用模型识别文字 with __session.as_default(): decoded = __session.run( __decoded, feed_dict= __inputs: batch_x, __seq_len: [__max_char_count] * batch_size ) pred_result = utils.ground_truth_to_word(decoded[0]) return pred_result
将CRNN能力封装后,便能很方便地进行调用识别,如下:
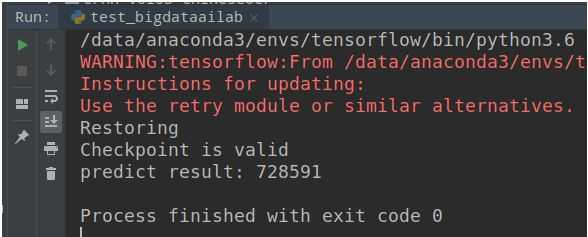
img_path = ‘/tmp/crnn_data/728591_532.jpg‘ pred_result = predict(img_path) print(‘predict result:‘,pred_result)
调用结果如下图
3、ChineseOCR项目
(1)下载源代码 - https://github.com/chineseocr/chineseocr(git clone https://github.com/chineseocr/chineseocr.git)
基于yolo3(用于文字检测)、crnn(用于文字识别)的自然场景文字识别项目。该项目支持darknet / opencv dnn / keras 的文字检测,支持0、90、180、270度的方向检测,支持不定长的英文、中英文识别,同时支持通用OCR、身份证识别、火车票识别等多种场景。
该模型功能完善,使用简单,入手容易,非常适合于新手或者比较通用的场景使用。
(2)下载darknet
ChineseOCR项目默认使用keras yolo3进行文字检测,该项目同时支持opencv dnn、darknet进行文字检测。
① 下载源代码
如果要使用darknet来进行文字检测,那么就需要再下载darknet源代码(如直接使用项目默认的keras yolo3检测方法,则跳过该步骤),在GitHub上下载ChineseOCR源代码(https://github.com/pjreddie/darknet),可直接下载成zip压缩包或者git克隆(git clone https://github.com/pjreddie/darknet.git)
② 放置目录
下载后,将darknet的源代码放到chineseocr项目中的darknet目录中(mv darknet chineseocr/)
③ 编译
然后修改Makefile,增加对GPU、cudnn的支持
#GPU=1 #CUDNN=1 #OPENCV=0 #OPENMP=0 执行 make 进行编译
④ 指定libdarknet.so路径
修改 darknet/python/darknet.py 的第48行,指定libdarknet.so所在的目录
lib = CDLL(root+"chineseocr/darknet/libdarknet.so", RTLD_GLOBAL) # 其中root表示chineseocr所在的路径
(3)准备基础环境
在源代码文件中的setup.md中列举了该项目依赖的基础环境,如果是在cpu上运行则查看setup-cpu.md文件。
① 创建虚拟环境
# 创建虚拟环境 conda create -n chineseocr python=3.6 pip scipy numpy jupyter ipython # 激活虚拟环境 source activate chineseocr
② 安装依赖包
git submodule init && git submodule update pip install easydict opencv-contrib-python==4.0.0.21 Cython h5py lmdb mahotas pandas requests bs4 matplotlib lxml pip install -U pillow pip install keras==2.1.5 tensorflow==1.8 tensorflow-gpu==1.8 pip install web.py==0.40.dev0 conda install pytorch torchvision -c pytorch pip install torch torchvision
(4)下载模型文件
在百度网盘上面下载预训练好的模型文件,并将所有文件复制到models目录中,下载地址为 https://pan.baidu.com/s/1gTW9gwJR6hlwTuyB6nCkzQ
(5)启动web服务
通过执行app.py启动web服务,启动后便能直接上传图片进行文字识别,执行命令为
ipython app.py 8080 # 8080为端口号,可根据实际需要进行修改。
启动后的界面如下,界面中提供了是否进行文字方向检测、是否作单行文字识别,以及通用OCR(默认)、火车票、身份证的识别类型。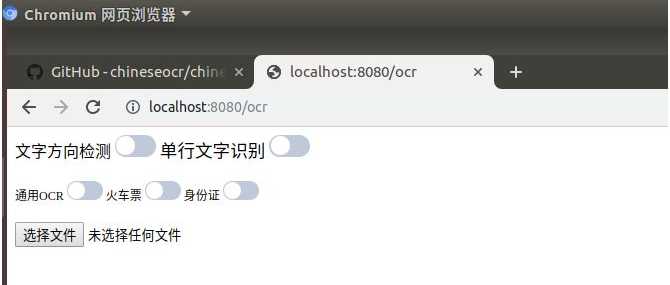
在chineseocr项目中的test目录里面自带了一些测试图片,通过上传一些图片测试识别效果,如下图: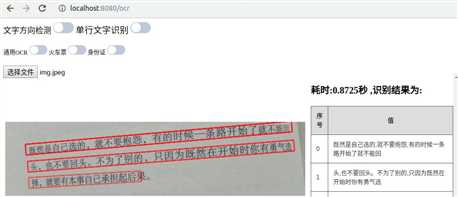
从识别效果上看还不错,接下来试一下火车票、身份证类型的识别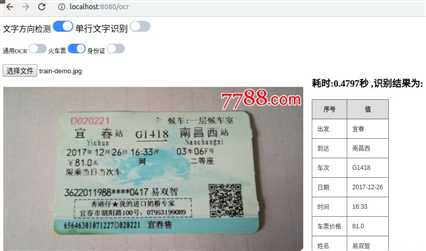
从上图可看出,对火车票的识别结果进行了处理,将出发地点、到达地点、车次、时间、价格、姓名等信息提取了出来。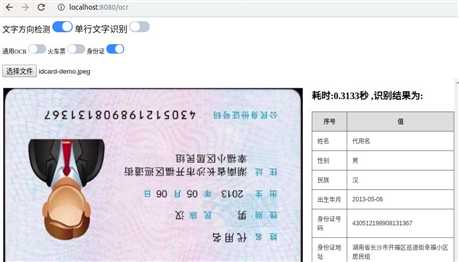
身份证的识别也是将姓名、性别、民族、出生年月、身份证号、住址这些信息提取了出来。
我们再比较一下,有使用文字方向检测和没有使用文字方向检测时的识别效果区别,如下图: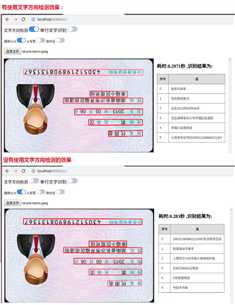
从识别的结果可以看出,对于一张颠倒的图片(或者具有一定的旋转角度),如果没有加上文字方向检测,则识别出来的结果文字会出现很大的偏差,而加上方向检测后则会正确地识别出来。
(6)识别能力封装
chineseocr项目支持多种方式的文字检测与识别,提供了多种模型可供选择,导致整个项目比较庞大。如果要将该项目的检测与识别能力抽离出来,提供给其它项目使用,则需根据实际业务场景进行简化,将识别能力进行封装。
例如我们选择keras yolo3进行文字检测,选择pytorch进行文字识别,去掉文字方向检测(假定输入的图片绝大多数是方向正确的),那么即可对chineseocr的源代码进行大幅精简。在model.py代码的基础上进行修改,去繁存简,对识别能力进行封装,方便提供给其它应用程序使用。修改后的核心代码如下:
# 文字检测 def text_detect(img,MAX_HORIZONTAL_GAP=30,MIN_V_OVERLAPS=0.6,MIN_SIZE_SIM=0.6,TEXT_PROPOSALS_MIN_SCORE=0.7,TEXT_PROPOSALS_NMS_THRESH=0.3,TEXT_LINE_NMS_THRESH=0.3,): boxes, scores = detect.text_detect(np.array(img)) boxes = np.array(boxes, dtype=np.float32) scores = np.array(scores, dtype=np.float32) textdetector = TextDetector(MAX_HORIZONTAL_GAP, MIN_V_OVERLAPS, MIN_SIZE_SIM) shape = img.shape[:2] boxes = textdetector.detect(boxes,scores[:, np.newaxis],shape,TEXT_PROPOSALS_MIN_SCORE,TEXT_PROPOSALS_NMS_THRESH,TEXT_LINE_NMS_THRESH,) text_recs = get_boxes(boxes) newBox = [] rx = 1 ry = 1 for box in text_recs: x1, y1 = (box[0], box[1]) x2, y2 = (box[2], box[3]) x3, y3 = (box[6], box[7]) x4, y4 = (box[4], box[5]) newBox.append([x1 * rx, y1 * ry, x2 * rx, y2 * ry, x3 * rx, y3 * ry, x4 * rx, y4 * ry]) return newBox # 文字识别 def crnnRec(im, boxes, leftAdjust=False, rightAdjust=False, alph=0.2, f=1.0): results = [] im = Image.fromarray(im) for index, box in enumerate(boxes): degree, w, h, cx, cy = solve(box) partImg, newW, newH = rotate_cut_img(im, degree, box, w, h, leftAdjust, rightAdjust, alph) text = crnnOcr(partImg.convert(‘L‘)) if text.strip() != u‘‘: results.append(‘cx‘: cx * f, ‘cy‘: cy * f, ‘text‘: text, ‘w‘: newW * f, ‘h‘: newH * f, ‘degree‘: degree * 180.0 / np.pi) return results # 文字检测、文字识别的能力封装 def ocr_model(img, leftAdjust=True, rightAdjust=True, alph=0.02): img, f = letterbox_image(Image.fromarray(img), IMGSIZE) img = np.array(img) config = dict(MAX_HORIZONTAL_GAP=50, ##字符之间的最大间隔,用于文本行的合并 MIN_V_OVERLAPS=0.6, MIN_SIZE_SIM=0.6, TEXT_PROPOSALS_MIN_SCORE=0.1, TEXT_PROPOSALS_NMS_THRESH=0.3, TEXT_LINE_NMS_THRESH=0.7, ##文本行之间测iou值 ) config[‘img‘] = img text_recs = text_detect(**config) ##文字检测 newBox = sort_box(text_recs) ##行文本识别 result = crnnRec(np.array(img), newBox, leftAdjust, rightAdjust, alph, 1.0 / f) return result
经过以上重新改造封装后,只需要调用ocr_model函数,输入图片,即可调用chineseocr项目的检测与识别能力。调用结果如下图:

以上方法为LSTM+CTC、CRNN、ChineseOCR三种文字识别方法,在实际生产中一般会根据业务场景,对识别方法进行改造或增加预处理、后处理环节。
以上是关于深度学习文字识别的主要内容,如果未能解决你的问题,请参考以下文章
[Python人工智能] 三十.Keras深度学习构建CNN识别阿拉伯手写文字图像