服务器线上问题排查研究
Posted myseries
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了服务器线上问题排查研究相关的知识,希望对你有一定的参考价值。
线上问题诸如:
1、线上服务器CPU占用率高如何排查?
2、线上服务器Load飙高如何排查?
3、线上服务器频繁发生Full GC如何排查?
4、线上服务器发生死锁如何排查?
一:线上服务器CPU占用率高如何排查?
问题发现:
在每次大促之前,我们的测试人员都会对网站进行压力测试,这个时候会查看服务的cpu、内存、load、rt、qps等指标。
在一次压测过程中,测试人员发现我们的某一个接口,在qps上升到500以后,CPU使用率急剧升高。
CPU利用率,又称CPU使用率。顾名思义,CPU利用率是来描述CPU的使用情况的,表明了一段时间内CPU被占用的情况。使用率越高,说明你的机器在这个时间上运行了很多程序,反之较少。
问题定位:
定位进程:登录服务器,执行top命令,查看CPU占用情况:

top命令是Linux下常用的性能分析工具,能够实时显示系统中各个进程的资源占用状况,类似于Windows的任务管理器。
通过以上命令,我们可以看到,进程ID为1893的Java进程的CPU占用率达到了181%,基本可以定位到是我们的Java应用导致整个服务器的CPU占用率飙升。
定位线程
我们知道,Java是单进程多线程的,那么,我们接下来看看PID=1893的这个Java进程中的各个线程的CPU使用情况,同样是用top命令:

通过top -Hp 1893命令,我们可以发现,当前1893这个进程中,ID为4519的线程占用CPU最高。
定位代码
通过top命令,我们目前已经定位到导致CPU使用率较高的具体线程, 那么我么接下来就定位下到底是哪一行代码存在问题。
首先,我们需要把4519这个线程转成16进制:

接下来,通过jstack命令,查看栈信息:
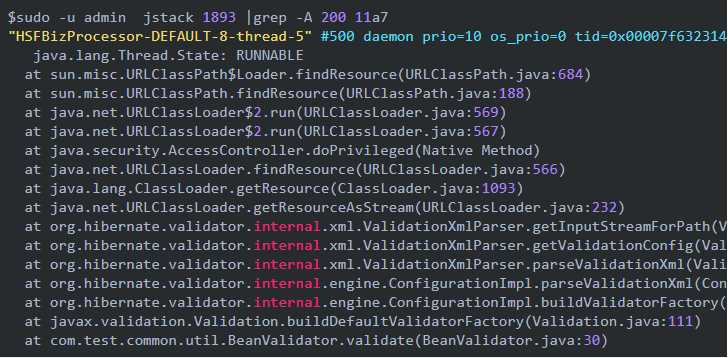
通过以上代码,我们可以清楚的看到,BeanValidator.java的第30行是有可能存在问题的。
问题解决
接下来就是通过查看代码来解决问题了,我们发现,我们自定义了一个BeanValidator,封装了Hibernate的Validator,然后在validate方法中,通过Validation.buildDefaultValidatorFactory().getValidator()初始化一个Validator实例,通过分析发现这个实例化的过程比较耗时。
我们重构了一下代码,把Validator实例的初始化提到方法外,在类初始化的时候创建一次就解决了问题。
总结
以上,展示了一次比较完成的线上问题定位过程。主要用到的命令有:top 、printf 和 jstack
另外,线上问题排查还可以使用Alibaba开源的工具Arthas进行排查,以上问题,可以使用一下命令定位:

以上,本文介绍了如何排查线上服务器CPU使用率过高的问题,如果大家感兴趣,后面可以再介绍一些关于LOAD飙高、频繁GC等问题的排查手段。
二、线上服务器Load飙高如何排查?
什么是负载
负载(load)是linux机器的一个重要指标,直观了反应了机器当前的状态。
来看下负载的定义是怎样的:
In UNIX computing, the system load is a measure of the amount of computational work that a computer system performs. The load average represents the average system load over a period of time. It conventionally appears in the form of three numbers which represent the system load during the last one-, five-, and fifteen-minute periods.(wikipedia)
简单解释一下:在UNIX系统中,系统负载是对当前CPU工作量的度量,被定义为特定时间间隔内运行队列中的平均线程数。load average 表示机器一段时间内的平均load。这个值越低越好。负载过高会导致机器无法处理其他请求及操作,甚至导致死机。
Linux的负载高,主要是由于CPU使用、内存使用、IO消耗三部分构成。任意一项使用过多,都将导致服务器负载的急剧攀升。
查看机器负载。
在Linux机器上,有多个命令都可以查看机器的负载信息。其中包括uptime、top、w等。
uptime命令
uptime命令能够打印系统总共运行了多长时间和系统的平均负载。uptime命令可以显示的信息显示依次为:现在时间、系统已经运行了多长时间、目前有多少登陆用户、系统在过去的1分钟、5分钟和15分钟内的平均负载。

这行信息的后半部分,显示”load average”,它的意思是”系统的平均负荷”,里面有三个数字,我们可以从中判断系统负荷是大还是小。
1.74 1.87 1.97 这三个数字的意思分别是1分钟、5分钟、15分钟内系统的平均负荷。我们一般表示为load1、load5、load15。
w命令
w命令的主要功能其实是显示目前登入系统的用户信息。但是与who不同的是,w命令功能更加强大,w命令还可以显示:当前时间,系统启动到现在的时间,登录用户的数目,系统在最近1分钟、5分钟和15分钟的平均负载。然后是每个用户的各项数据,项目显示顺序如下:登录帐号、终端名称、远 程主机名、登录时间、空闲时间、JCPU、PCPU、当前正在运行进程的命令行。
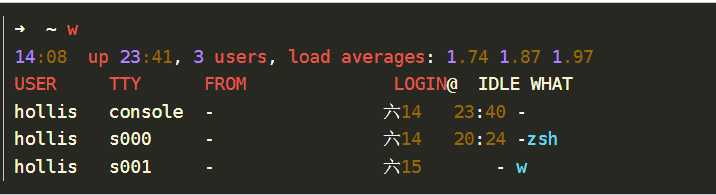
从上面的w命令的结果可以看到,当前系统时间是14:08,系统启动到现在经历了23小时41分钟,共有3个用户登录。系统在近1分钟、5分钟和15分钟的平均负载分别是1.74 1.87 1.97。这和uptime得到的结果相同。 下面还打印了一些登录的用户的各项数据,不详细介绍了。
top命令
top命令是Linux下常用的性能分析工具,能够实时显示系统中各个进程的资源占用状况,类似于Windows的任务管理器。
机器正常负载范围
对于机器的Load到底多少算正常的问题,一直都是很有争议的,不同人有着不同的理解。对于单个CPU,有人认为如果Load超过0.7就算是超出正常范围了。也有人认为只要不超过1都没问题。也有人认为,单个CPU的负载在2以下都可以接受。
为什么会有这么多不同的理解呢,是因为不同的机器除了CPU影响之外还有其他因素的影响,运行的程序、机器内存、甚至是机房温度等都有可能有区别。
比如,有些机器用于定时执行大量的跑批任务,这个时间段内,Load可能会飙的比较高。而其他时间可能会比较低。那么这段飙高时间我们要不要去排查问题呢?
我的建议是,最好根据自己机器的实际情况,建立一个指标的基线(如近一个月的平均值),只要日常的load在基线上下范围内不太大都可以接收,如果差距太多可能就要人为介入检查了。
但是,总要有个建议的阈值吧,关于这个值。阮一峰在自己的博客中有过以下建议:
当系统负荷持续大于0.7,你必须开始调查了,问题出在哪里,防止情况恶化。
当系统负荷持续大于1.0,你必须动手寻找解决办法,把这个值降下来。
当系统负荷达到5.0,就表明你的系统有很严重的问题,长时间没有响应,或者接近死机了。你不应该让系统达到这个值。
以上指标都是基于单CPU的,但是现在很多电脑都是多核的。所以,对一般的系统来说,是根据cpu数量去判断系统是否已经过载(Over Load)的。如果我们认为0.7算是单核机器负载的安全线的话,那么四核机器的负载最好保持在3(4*0.7 = 2.8)以下。
还有一点需要提一下,在Load Avg的指标中,有三个值,1分钟系统负荷、5分钟系统负荷,15分钟系统负荷。我们在排查问题的时候也是可以参考这三个值的。
一般情况下,1分钟系统负荷表示最近的暂时现象。15分钟系统负荷表示是持续现象,并非暂时问题。如果load15较高,而load1较低,可以认为情况有所好转。反之,情况可能在恶化。
如何降低负载
导致负载高的原因可能很复杂,有可能是硬件问题也可能是软件问题。
如果是硬件问题,那么说明机器性能确实就不行了,那么解决起来很简单,直接换机器就可以了。
前面我们提过,CPU使用、内存使用、IO消耗都可能导致负载高。如果是软件问题,有可能由于Java中的某些线程被长时间占用、大量内存持续占用等导致。建议从以下几个方面排查代码问题:
1、是否有内存泄露导致频繁GC
2、是否有死锁发生
3、是否有大字段的读写
4、会不会是数据库操作导致的,排查SQL语句问题。
这里还有个建议,如果发现线上机器Load飙高,可以考虑先把堆栈内存dump下来后,进行重启,暂时解决问题,然后再考虑回滚和排查问题。
Java Web应用Load飙高排查思路
1、使用uptime查看当前load,发现load飙高。

2、使用top命令,查看占用CPU较高的进程ID。、

发现PID为1893的进程占用CPU 181%。而且是一个Java进程,基本断定是软件问题。
3、使用 top命令 (top -Hp 进程id),查看具体是哪个线程占用率较高

4、使用printf命令查看这个线程的16进制

5、使用jstack命令查看当前线程正在执行的方法 (jstack 进程id | grep 线程id的16进制)。(Java命令学习系列(二)——Jstack)
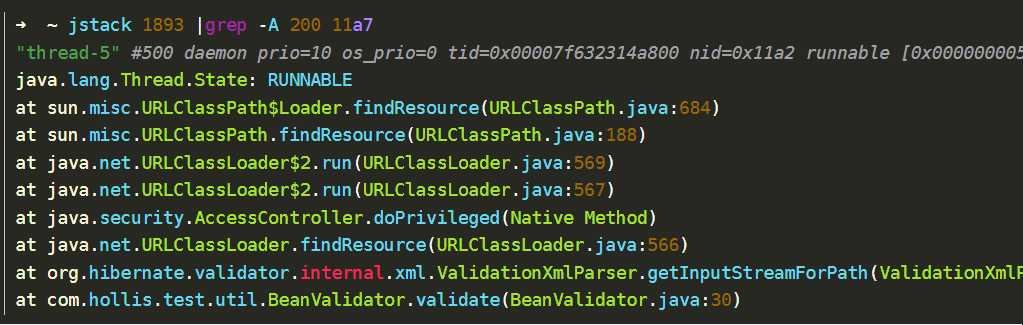
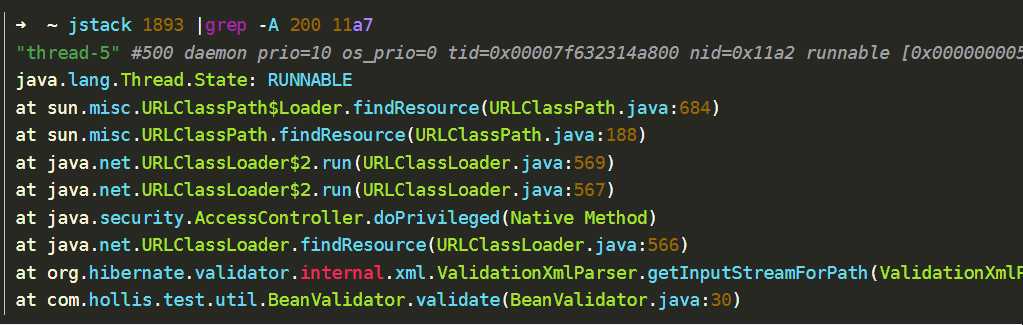
从上面的线程的栈日志中,可以发现,当前占用CPU较高的线程正在执行我代码的com.hollis.test.util.BeanValidator.validate(BeanValidator.java:30)类。那么就可以去排查这个类是否用法有问题了。
网上有牛人写了一个脚本能自动帮我们大致定位到现场导致LOAD飙升的JVM线程,脚本大概如下
#!/bin/ksh typeset top=$1:-10 typeset pid=$2:-$(pgrep -u $USER java) typeset tmp_file=/tmp/java_$pid_$$.trace $JAVA_HOME/bin/jstack $pid > $tmp_file ps H -eo user,pid,ppid,tid,time,%cpu --sort=%cpu --no-headers | tail -$top | awk -v "pid=$pid" ‘$2==pidprint $4"\\t"$6‘ | while read line; do typeset nid=$(echo "$line"|awk ‘printf("0x%x",$1)‘) typeset cpu=$(echo "$line"|awk ‘print $2‘) awk -v "cpu=$cpu" ‘/nid=‘"$nid"‘/,/^$/print $0"\\t"(isF++?"":"cpu="cpu"%");‘ $tmp_file done rm -f $tmp_file
现在我们就来拆解其中的原理,以及说明下类似脚本的适用范围。
1.使用top命令查看飙高的java进程,记录pid
2.通过jstack命令将java的线程栈输出,保留现场 jstack -l 30142 > 30142.stack
3.找到当前CPU使用占比高的线程,通过 ps H -eo user,pid,ppid,tid,time,%cpu –sort=%cpu
USER:进程归属用户,PID:进程号,PPID:父进程号,TID:线程号
%CPU:线程使用CPU占比(这里要提醒下各位,这个CPU占比是通过/proc计算得到,存在时间差)
4.合并相关信息,通过PS拿到了TID,可以通过进制换算10-16得到jstack出来的JVM线程号?
typeset nid=”0x”(echo"(echo"line”|awk ‘print $1’|xargs -I echo “obase=16;”|bc|tr ‘A-Z’ ‘a-z’)
5.最后再将ps和jstack出来的信息进行一个匹配与合并。终于,得到我们最想要的信息

出处:
https://mp.weixin.qq.com/s/aZ2Otci6TntXdsoyMcwBVw
https://blog.csdn.net/huangyimo/article/details/80401638
以上是关于服务器线上问题排查研究的主要内容,如果未能解决你的问题,请参考以下文章