记一次线上机器CPU飙高的排查过程
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了记一次线上机器CPU飙高的排查过程相关的知识,希望对你有一定的参考价值。
参考技术A 公司如今把小贷机器都整理回收了,访问量不大,基本都是用户来查看账户进行还款操作。现在情况是,我们把很多服务都放在了一台服务器上,那天线上环境改了auth的salt,本地这边是写死的,自动上线已经关闭了通道,没辙,手动替包手动上线,结果没多久运维就喊了,表示cpu飙高到300%。
难得的机会,先用top找出cpu占用最多进程
如果想细看进程信息可以使用ll proc
其实运行完这里的时候,我比较吃惊的是,真正占CPU的并不是部署的几个服务,而是resin容器本身,飚到了99%,从这个角度来讲,其实大部分性能问题都是垃圾回收的锅。
然后利用ps查看到的进程pid找cpu最高线程
然后拿着线程tid在jstack找,结果在里面找不到,然后上网查JAVA线程无法在jstack里找到的原因
以上大概意思是没找到线程的跟踪栈有三种情况,就是线程启动前的预启动,以及线程退出后的cleanup,第三种就是,利用JVM TI agent运行的线程,这个线程是用来跑本地code的。
******这里面都提到了JVM TI技术,这个技术主要是用来提供虚拟机调用本地方法的接口,可以获取jvm运行情况和提供本地方法的后门一样的接口工具,一些调试和诊断工具都是基于JVM TI来实现的,很多JVM都有自己的TI实现。
当然,这个Stack Over Flow的答案针对的Java线程,我所知道的是,如果导致我们CPU飙高的并不是java线程,那么jstack -F就打不出来。
而这个jstack -m模式,在官方文档里是说,可以打印出所有Java线程和native frames的所有线程。其实到这里是不是隐隐感觉到什么了~~没错,最后真的是垃圾回收的锅。
然后jdk8利用jstack -m找到了,发现里面使用的方法是CMS垃圾回收器的方法
讲真,平时只负责上下线,JVM配置只要不出问题很少留意,这个年代了,还在使用CMS吗?嗯,jmap看了下,是CMS。而占用大多CPU也是CMS的特性之一:最小化GC中断,付出的代价便是高CPU负荷。
既然定位到了垃圾回收,那就接着排查垃圾回收吧,pid是18637
就去jstat -gc 18637 5000
jstat -gcold 18637
jstat -gcoldcapacity 18637
发现full gc非常频繁(每五秒输出,发现触发fullGC13次)
(复盘这次的排查问题,发现图片保存少之又少。。)
如此频繁,顺带gccause一下看看最近一次回收的原因
结果长这样
从这个结果来看最近一次是Metadata的GC,而触发原因是因为达到了阈值。再细看当前元空间使用率已经接近98%。
到这里不能等了,找运维拿来了jvm参数,有三个参数很亮眼
老年代的配置属于默认配置,占整个堆内存的2/3,CMS回收要达到80%才会触发,我们还没有达到这个值。
那么根据图1中的显示,metaspace我们已经达到了阈值。
这种情况产生也没毛病,想想一台机器部署了5个web服务和5个微服务的场景吧,虽然没什么人访问,但加载的class信息也足够多了。
主要就是metadata的配置,而有关metadata的配置并没有oracle的官方指导,官方指导上的意思是说metaspace的配置,主要是避免首次启动时对加载的类信息做回收,取决于应用本身,够用就行了,不要太频繁触发full gc就好
其实调大这metaspace的配置能够大概解决问题,但是最终我选择了切换为G1垃圾回收。
官方文档是这样写的
首先戳我的点的主要原因是g1最终的目的是要取代cms垃圾回收器,它的回收范围是整个堆,紧跟潮流总不会错的。其次g1取代cms的情况官方也建议了以下几点:
1. 一个是要管理的堆内存大于6g
2. 一个是服务已使用的堆内存超过了50%
3. 一个是对象分配率过高或对象从新生代晋升到老年代速率过快(这里我查了一下资料,意思是对象分配率过高的话其实会导致Minor GC频繁,而这种情况会使对象更快地晋升到老年代,而老年代如果过快地被填充,又会触发FullGC。从设计角度来讲,之所以分代回收,是为了应对对象存活时间而使用不同的回收策略,老年代可不是为了频繁回收而产生的)
4. 垃圾回收导致服务中断时长超过0.5-1s。
这种时候官方就建议把cms换成g1了。
最终cpu骤降,从99%降至一般运行状态下的2%左右。好了。就这样吧,虽然不希望线上出现这种问题,但一旦出问题了,搞一遍还蛮带感的。期待下一次的摸排:DDDDD
后记:
最近在复盘这次垃圾回收,因为这次jvm排查的经历让我对垃圾回收机制和分代回收这一块加深了印象。复盘的时候发现自己思考地还欠缺深入。这次的问题有两个地方值得深思,一个是为什么metaspace会超?如果正常进行GC,为何会超出阈值?其次是没有调大metaspace的前提下,换成G1为什么就没有再频繁FullGC过?
为什么metaspace会超,我经过比对当时留下CMS的jstat数据和G1当前的数据,发现新生代CMS划分区域非常大,是现在G1的十倍。G1是不建议设定新老年代比例的,这样它就可以动态调整新老年代比例,达到最优实践。首先说明metaspace是存储类描述信息的,当堆上分配了对象,就会关联到metaspace里面的类信息,如果堆上的对象不回收,那么metaspace里面的类信息也不会回收。
在配置cms时,我们会设置新生代老年代比例,新生代空间是固定的,如果新生代的空间比较大,回收间隔时间长,那就会导致metaspace里的class信息无法被释放,最终导致未进行youngGC而率先因为metaspace超了跑了FullGC。但G1的新生代空间是根据使用情况动态分配的,它的算法会去回收最有回收价值的region。
就这次修改参数而言,使用G1比CMS时间短很多,就已经执行了717次youngGC,而CMS用了那么久,才52次,侧面也能佐证这个猜测的正确性,解释了为何在相同metaspace的配置下,G1没有产生频繁FullGC的原因:新生代对象回收加快,metaspace空间得到了尽快释放,没有达到阈值,于是不会触发FullGC。
参考文献:
* https://www.oracle.com/java/technologies/javase/hotspot-garbage-collection.html
* https://www.oracle.com/java/technologies/javase/gc-tuning-6.html
* https://docs.oracle.com/javase/8/docs/technotes/guides/vm/gctuning/sizing.html
* https://plumbr.io/blog/garbage-collection/what-is-allocation-rate
* https://plumbr.io/blog/garbage-collection/what-is-promotion-rate
记一次 JVM CPU 使用率飙高问题的排查过程
点击关注公众号,Java干货及时送达👇
 来源:guobinhit.blogp.csdn.net/article/details/70823903
来源:guobinhit.blogp.csdn.net/article/details/70823903
问题现象
排查过程
问题现象
首先,我们一起看看通过 VisualVM 监控到的机器 CPU 使用率图:

如上图所示,在 下午3:45 分之前,CPU 的使用率明显飙高,最高飙到近 100%,为什么会出现这样的现象呢?
排查过程
Step 1: 使用top命令,查询资源占用情况:

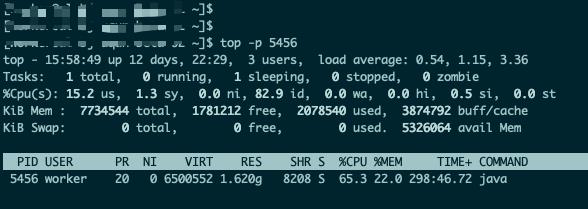
如上图所示,显示了服务器当前的资源占用情况,其中PID为5456的进程占用的资源最多。
在这里,我们也使用top -p PID命令,查询指定PID的资源占用情况:
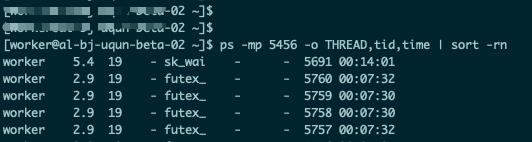
Step 2: 使用ps -mp PID -o THREAD,tid,time命令,查询该进程的线程情况:

在这里,我们也使用ps -mp PID -o THREAD,tid,time | sort -rn命令,将该进程下的线程按资源使用情况倒序展示:
Step 3: 使用printf "%x\\n" PID命令,将PID转为十六进制的TID:
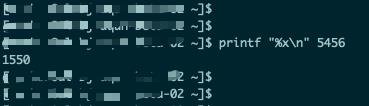
在这里,我们之所以需要将PID转为十六进制是因为在堆栈信息中,PID是以十六进制形式存在的。
Step 4: 使用jstack PID | grep TID -A 100命令,查询堆栈信息:
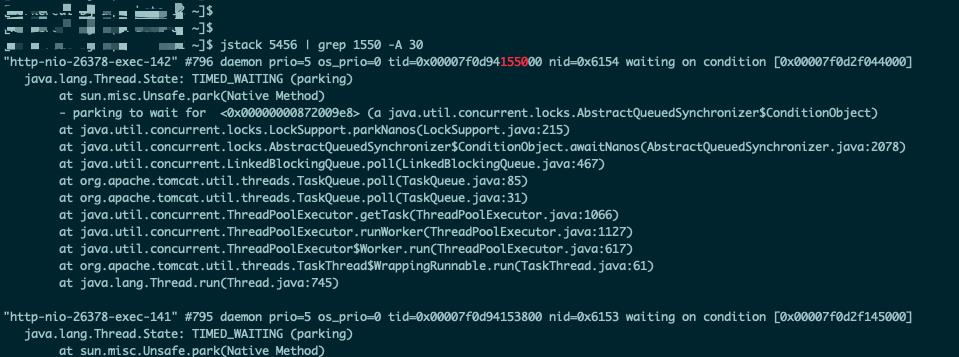
如上图所示,显示该进程下多个线程均处于TIMED_WAITING状态。
虽然线程处于WAITING或者TIMED_WAITING状态都不会消耗 CPU,但是线程频繁的挂起和唤醒却会消耗 CPU,而且代价高昂。
而上面之所以会出现 CPU 使用率飙高的情况,则是因为有人在做压测。
特别地,在 mock 底层接口的时候,使用了类似TimeUnit.SECONDS.sleep(1)这样的语句。
至于为何在 下午3:45 分之后,CPU 的使用率降下来了,则是因为停止了压测。
除此之外,我们还可以使用jinfo和jstat命令来查询 Java 进程的启动参数以及 GC 情况:
使用jinfo PID命令,查询启动参数:
如上图所示,使用该命令我们主要是为了查询启动参数,如初始化堆大小、垃圾回收器等配置。
使用jstat -gcutil PID 1000命令,查询 GC 情况:

如上图所示,显示了PID为20567的 Java 进程每秒的 GC 情况,其中1000表示 GC 状态的更新频率,单位为毫秒。
(完)码农突围资料链接1、卧槽!字节跳动《算法中文手册》火了,完整版 PDF 开放下载!
2、计算机基础知识总结与操作系统 PDF 下载
3、艾玛,终于来了!《LeetCode Java版题解》.PDF
4、Github 10K+,《LeetCode刷题C/C++版答案》出炉.PDF
欢迎添加鱼哥个人微信:smartfish2020,进粉丝群或围观朋友圈以上是关于记一次线上机器CPU飙高的排查过程的主要内容,如果未能解决你的问题,请参考以下文章
记一次线上Java程序导致服务器CPU占用率过高的问题排除过程
记一次线上Java程序导致服务器CPU占用率过高的问题排除过程