包logginghashlib深浅拷贝
Posted gaimo
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了包logginghashlib深浅拷贝相关的知识,希望对你有一定的参考价值。
一、包:
包的本质就是一个模块
什么是包:它是一系列模块文件的结合体,表示形式就是一个文件夹,该文件夹内部通常会有一个__init__..py的文件
导入包的过程:先产生一个执行文件的名称空间
1:创建包下面的__init__.py文件的名称空间
2:执行包下面的__init__.py文件中的代码,将产生的名字放入下面的__init__.py文件的名称空间中
3:在执行文件中拿到一个指向包下面的__init__.py文件名称空间的名字
在导入的语句中.号的左边肯定是一个包(文件夹):from dir.dir1 import p 格式
需要强调的:
1、在Python3中,即使包下面没有__init__.py文件,import包也不会报错,而在Python2中一定要有__init__.py文件存在,不然会报错
2、创建包的目的不是为了运行,而是被导入使用,包只是模块的一种形式,包的本质就是一个模块
3、在删除程序不必要的文件时,务必记住不要删除带有__init__的文件,否则会导致文件或程序不能正常运行
二、为何要使用包
包的本质就是一个文件夹,那么文件夹唯一的功能就是将文件组织起来
随着功能越写越多,我们无法将所以功能都放到一个文件中,于是我们使用模块去组织功能,而随着模块越来越多,我们就需要用文件夹将模块文件组织起来,以此来提高程序的结构性和可维护性
三、包的相对路径导入和绝对路径导入:
1、站在包的开发者看,如果使用绝对路径来管理自己的模块,那么只需要永远以包的路径为基准依次导入模块
2、站在包的使用者看,必须到将包所在的那个文件夹路径添加到sys.path中(**)
四、包的使用之import和from import
1、单独导入包名称时不会导入包中所有包含的所有子模块
1 import glance.db.models 2 glance.db.models.register_models(‘mysql‘)
2、需要注意的是from后import导入的模块,必须是明确的一个不能带点,否则会有语法错误,如:from a import b.c是错误语法
1 from glance.db import models 2 models.register_models(‘mysql‘)
五、logging(日志模块):
import logging 日志的等级:critical(50级别) >error(40)>warning(30)>info(20)>debug(10)
longging.debug(debug日志‘) # 调试 longging.info(‘info日志‘) #记录数据 longging.warning(‘warning日志‘) # 警告 longging.error(‘日志’) # 错误提示 logging.critical(‘critical日志‘) # 严重的
默认的日志格式为日志日志级别:loggermin名称:用户输出的消息。
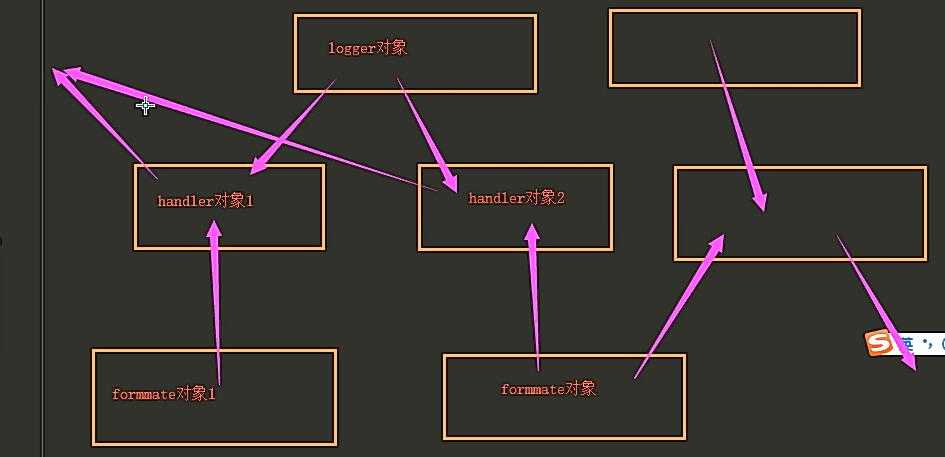
重点掌握:1、logger对象:负责产生日志
2、filter对象:过滤日志
3、handler:控制日志输出的位置(文件/终端)切割
4、formmater 对象:规定日志内容的格式


logging.basicConfig()函数中可通过具体参数来更改logging模块默认行为,可用参数有: filename:用指定的文件名创建FiledHandler,这样日志会被存储在指定的文件中。 filemode:文件打开方式,在指定了filename时使用这个参数,默认值为“a”还可指定为“w”。 format:指定handler使用的日志显示格式。 datefmt:指定日期时间格式。 level:设置rootlogger(后边会讲解具体概念)的日志级别 stream:用指定的stream创建StreamHandler。可以指定输出到sys.stderr,sys.stdout或者文件(f=open(‘test.log’,’w’)),默认为sys.stderr。若同时列出了filename和stream两个参数,则stream参数会被忽略。 format参数中可能用到的格式化串: %(name)s Logger的名字 %(levelno)s 数字形式的日志级别 %(levelname)s 文本形式的日志级别 %(pathname)s 调用日志输出函数的模块的完整路径名,可能没有 %(filename)s 调用日志输出函数的模块的文件名 %(module)s 调用日志输出函数的模块名 %(funcName)s 调用日志输出函数的函数名 %(lineno)d 调用日志输出函数的语句所在的代码行 %(created)f 当前时间,用UNIX标准的表示时间的浮 点数表示 %(relativeCreated)d 输出日志信息时的,自Logger创建以 来的毫秒数 %(asctime)s 字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒 %(thread)d 线程ID。可能没有 %(threadName)s 线程名。可能没有 %(process)d 进程ID。可能没有 %(message)s用户输出的消息
logging对象配置:
import logging logger = logging.getLogger() # 创建一个handler,用于写入日志文件 fh = logging.FileHandler(‘test.log‘,encoding=‘utf-8‘)
再创建一个handler,用于输出到控制台 ch = logging.StreamHandler() formatter = logging.Formatter(‘%(asctime)s - %(name)s - %(levelname)s - %(message)s‘) fh.setLevel(logging.DEBUG) fh.setFormatter(formatter) ch.setFormatter(formatter) logger.addHandler(fh) #logger对象可以添加多个fh和ch对象 logger.addHandler(ch)
import logging.config 字典的配置(直接复制粘贴,修改即可)
定义三种日志输出格式 开始
standard_format = ‘[%(asctime)s][%(threadName)s:%(thread)d][task_id:%(name)s][%(filename)s:%(lineno)d]‘ ‘[%(levelname)s][%(message)s]‘ #其中name为getlogger指定的名字 simple_format = ‘[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%(message)s‘
# 定义日志输出格式 结束 """ 下面的两个变量对应的值 需要你手动修改 """ logfile_dir = os.path.dirname(__file__) # log文件的目录 logfile_name = ‘a3.log‘ # log文件名 # 如果不存在定义的日志目录就创建一个 if not os.path.isdir(logfile_dir): os.mkdir(logfile_dir) # log文件的全路径 logfile_path = os.path.join(logfile_dir, logfile_name)
logger与handler之间的控制关系
重点:
1、logging.config.dictConfig(LOGGING_DIC) # 自动加载字典中的配置
2、logger1=loggong.getlogger(‘come on‘)
3、logger1.debug(‘革命尚未成功,任需努力‘)
logging日志在项目中的使用:
例子:比如在购物车中自动添加日志功能,让用户自定义生成日志记录
mport logging.config from conf import settings # 文件规范在文件中添加相应的功能模块 def get_logger(name): logging.config.dictConfig(settings.LOGGING_DIC) # 自动加载字典中的配置 logger1=logging.getLogger(name) return logger1 #封装成函数调用 让用户输入
六、hashlib 加密模块
常用的有:MD5,SHA1系列等 两种加密方式
MD5:摘要算法:又称哈希算法,通过一个函数,把任意长度的字符串转换成一个长度固定的数据串
关键字:pycharm里没有提示: update(往对象里传明文数据) hexdigest(获取明文数据对应的密文)
import hashlib md=hashlib.md5() # 生成一个帮你造密文的对象 md.update(‘come‘.encode(‘utf-8‘)) # 往对象里传明文数据 update只能接受bytes类型的数据 md.update(b‘come_on‘) print(md.hexdigest()) # 获取明文数据对应的密文 结果:dd55e5aab7c4839be5932f399638ddb1
# encode(‘utf-8‘)等价于’b‘ md.update(‘come‘.encode(‘utf-8‘)) >>md.update(b‘come‘) 这个加密的过程是无法解密的
撞库
1.不同的算法 使用方法是相同的
密文的长度越长 内部对应的算法越复杂
但是
1.时间消耗越长
2.占用空间更大
通常情况下使用md5算法,就可以足够了
以上是关于包logginghashlib深浅拷贝的主要内容,如果未能解决你的问题,请参考以下文章