scikit-learn决策树算法类库内部实现是使用了调优过的CART树算法,既可以做分类,又可以做回归。分类决策树的类对应的是DecisionTreeClassifier,而回归决策树的类对应的是DecisionTreeRegressor。两者的参数定义几乎完全相同,但是意义不全相同。下面就对DecisionTreeClassifier和DecisionTreeRegressor的重要参数做一个总结,重点比较两者参数使用的不同点和调参的注意点。
|参数|DecisionTreeClassifier|DecisionTreeRegressor|
特征选择标准criterion
可以使用"gini"或者"entropy",前者代表基尼系数,后者代表信息增益。一般说使用默认的基尼系数"gini"就可以了,即CART算法。除非你更喜欢类似ID3, C4.5的最优特征选择方法。?
|?可以使用"mse"或者"mae",前者是均方差,后者是和均值之差的绝对值之和。推荐使用默认的"mse"。一般来说"mse"比"mae"更加精确。除非你想比较二个参数的效果的不同之处。|
特征划分点选择标准splitter
可以使用"best"或者"random"。前者在特征的所有划分点中找出最优的划分点。后者是随机的在部分划分点中找局部最优的划分点。
默认的"best"适合样本量不大的时候,而如果样本数据量非常大,此时决策树构建推荐"random"?
划分时考虑的最大特征数max_features
可以使用很多种类型的值,默认是"None",意味着划分时考虑所有的特征数;如果是"log2"意味着划分时最多考虑\\(log_2N\\)个特征;如果是"sqrt"或者"auto"意味着划分时最多考虑\\(\\sqrtN\\)个特征。如果是整数,代表考虑的特征绝对数。如果是浮点数,代表考虑特征百分比,即考虑(百分比xN)取整后的特征数。其中N为样本总特征数。
一般来说,如果样本特征数不多,比如小于50,我们用默认的"None"就可以了,如果特征数非常多,我们可以灵活使用刚才描述的其他取值来控制划分时考虑的最大特征数,以控制决策树的生成时间。
决策树最大深max_depth
|?决策树的最大深度,默认可以不输入,如果不输入的话,决策树在建立子树的时候不会限制子树的深度。一般来说,数据少或者特征少的时候可以不管这个值。如果模型样本量多,特征也多的情况下,推荐限制这个最大深度,具体的取值取决于数据的分布。常用的可以取值10-100之间。|
内部节点再划分所需最小样本数min_samples_split
|这个值限制了子树继续划分的条件,如果某节点的样本数少于min_samples_split,则不会继续再尝试选择最优特征来进行划分。?默认是2.如果样本量不大,不需要管这个值。如果样本量数量级非常大,则推荐增大这个值。我之前的一个项目例子,有大概10万样本,建立决策树时,我选择了min_samples_split=10。可以作为参考。|
叶子节点最少样本数min_samples_leaf
|?这个值限制了叶子节点最少的样本数,如果某叶子节点数目小于样本数,则会和兄弟节点一起被剪枝。?默认是1,可以输入最少的样本数的整数,或者最少样本数占样本总数的百分比。如果样本量不大,不需要管这个值。如果样本量数量级非常大,则推荐增大这个值。之前的10万样本项目使用min_samples_leaf的值为5,仅供参考。|
叶子节点最小的样本权重和min_weight_fraction_leaf
|这个值限制了叶子节点所有样本权重和的最小值,如果小于这个值,则会和兄弟节点一起被剪枝。?默认是0,就是不考虑权重问题。一般来说,如果我们有较多样本有缺失值,或者分类树样本的分布类别偏差很大,就会引入样本权重,这时我们就要注意这个值了。|
最大叶子节点数max_leaf_nodes
|?通过限制最大叶子节点数,可以防止过拟合,默认是"None”,即不限制最大的叶子节点数。如果加了限制,算法会建立在最大叶子节点数内最优的决策树。如果特征不多,可以不考虑这个值,但是如果特征分成多的话,可以加以限制,具体的值可以通过交叉验证得到。|
类别权重class_weight
|指定样本各类别的的权重,主要是为了防止训练集某些类别的样本过多,导致训练的决策树过于偏向这些类别。这里可以自己指定各个样本的权重,或者用“balanced”,如果使用“balanced”,则算法会自己计算权重,样本量少的类别所对应的样本权重会高。当然,如果你的样本类别分布没有明显的偏倚,则可以不管这个参数,选择默认的"None"|?不适用于回归树|
节点划分最小不纯度min_impurity_split
|?这个值限制了决策树的增长,如果某节点的不纯度(基尼系数,信息增益,均方差,绝对差)小于这个阈值,则该节点不再生成子节点。即为叶子节点?。|
数据是否预排序presort
|这个值是布尔值,默认是False不排序。一般来说,如果样本量少或者限制了一个深度很小的决策树,设置为true可以让划分点选择更加快,决策树建立的更加快。如果样本量太大的话,反而没有什么好处。问题是样本量少的时候,我速度本来就不慢。所以这个值一般懒得理它就可以了。|
除了这些参数要注意以外,其他在调参时的注意点有:
1)当样本少数量但是样本特征非常多的时候,决策树很容易过拟合,一般来说,样本数比特征数多一些会比较容易建立健壮的模型
2)如果样本数量少但是样本特征非常多,在拟合决策树模型前,推荐先做维度规约,比如主成分分析(PCA),特征选择(Losso)或者独立成分分析(ICA)。这样特征的维度会大大减小。再来拟合决策树模型效果会好。
3)推荐多用决策树的可视化(下节会讲),同时先限制决策树的深度(比如最多3层),这样可以先观察下生成的决策树里数据的初步拟合情况,然后再决定是否要增加深度。
4)在训练模型先,注意观察样本的类别情况(主要指分类树),如果类别分布非常不均匀,就要考虑用class_weight来限制模型过于偏向样本多的类别。
5)决策树的数组使用的是numpy的float32类型,如果训练数据不是这样的格式,算法会先做copy再运行。
6)如果输入的样本矩阵是稀疏的,推荐在拟合前调用csc_matrix稀疏化,在预测前调用<code class="docutils literal">csr_matrix稀疏化。
三、scikit-learn决策树结果的可视化
决策树可视化化可以方便我们直观的观察模型,以及发现模型中的问题。这里介绍下scikit-learn中决策树的可视化方法。
完整代码见我的github: https://github.com/ljpzzz/machinelearning/blob/master/classic-machine-learning/decision_tree_classifier.ipynb
3.1 决策树可视化环境搭建
scikit-learn中决策树的可视化一般需要安装graphviz。主要包括graphviz的安装和python的graphviz插件的安装。
第一步是安装graphviz。下载地址在:http://www.graphviz.org/。如果你是linux,可以用apt-get或者yum的方法安装。如果是windows,就在官网下载msi文件安装。无论是linux还是windows,装完后都要设置环境变量,将graphviz的bin目录加到PATH,比如我是windows,将C:/Program Files (x86)/Graphviz2.38/bin/加入了PATH
第二步是安装python插件graphviz:?pip install graphviz
第三步是安装python插件pydotplus。这个没有什么好说的: pip install pydotplus
这样环境就搭好了,有时候python会很笨,仍然找不到graphviz,这时,可以在代码里面加入这一行:
os.environ["PATH"] += os.pathsep + ‘C:/Program Files (x86)/Graphviz2.38/bin/‘
注意后面的路径是你自己的graphviz的bin目录。
3.2 决策树可视化的三种方法
这里我们有一个例子讲解决策树可视化。
首先载入类库:
from sklearn.datasets import load_iris
from sklearn import tree
import sys
import os
os.environ["PATH"] += os.pathsep + 'C:/Program Files (x86)/Graphviz2.38/bin/'
接着载入sciki-learn的自带数据,有决策树拟合,得到模型:
iris = load_iris()
clf = tree.DecisionTreeClassifier()
clf = clf.fit(iris.data, iris.target)
现在可以将模型存入dot文件iris.dot。
with open("iris.dot", 'w') as f:
f = tree.export_graphviz(clf, out_file=f)
这时候我们有3种可视化方法,第一种是用graphviz的dot命令生成决策树的可视化文件,敲完这个命令后当前目录就可以看到决策树的可视化文件iris.pdf.打开可以看到决策树的模型图。
#注意,这个命令在命令行执行
dot -Tpdf iris.dot -o iris.pdf
第二种方法是用pydotplus```生成iris.pdf。这样就不用再命令行去专门生成pdf文件了。
import pydotplus
dot_data = tree.export_graphviz(clf, out_file=None)
graph = pydotplus.graph_from_dot_data(dot_data)
graph.write_pdf("iris.pdf")
第三种办法是个人比较推荐的做法,因为这样可以直接把图产生在ipython的notebook。代码如下:
from IPython.display import Image
dot_data = tree.export_graphviz(clf, out_file=None,
feature_names=iris.feature_names,
class_names=iris.target_names,
filled=True, rounded=True,
special_characters=True)
graph = pydotplus.graph_from_dot_data(dot_data)
Image(graph.create_png())
在ipython的notebook生成的图如下:
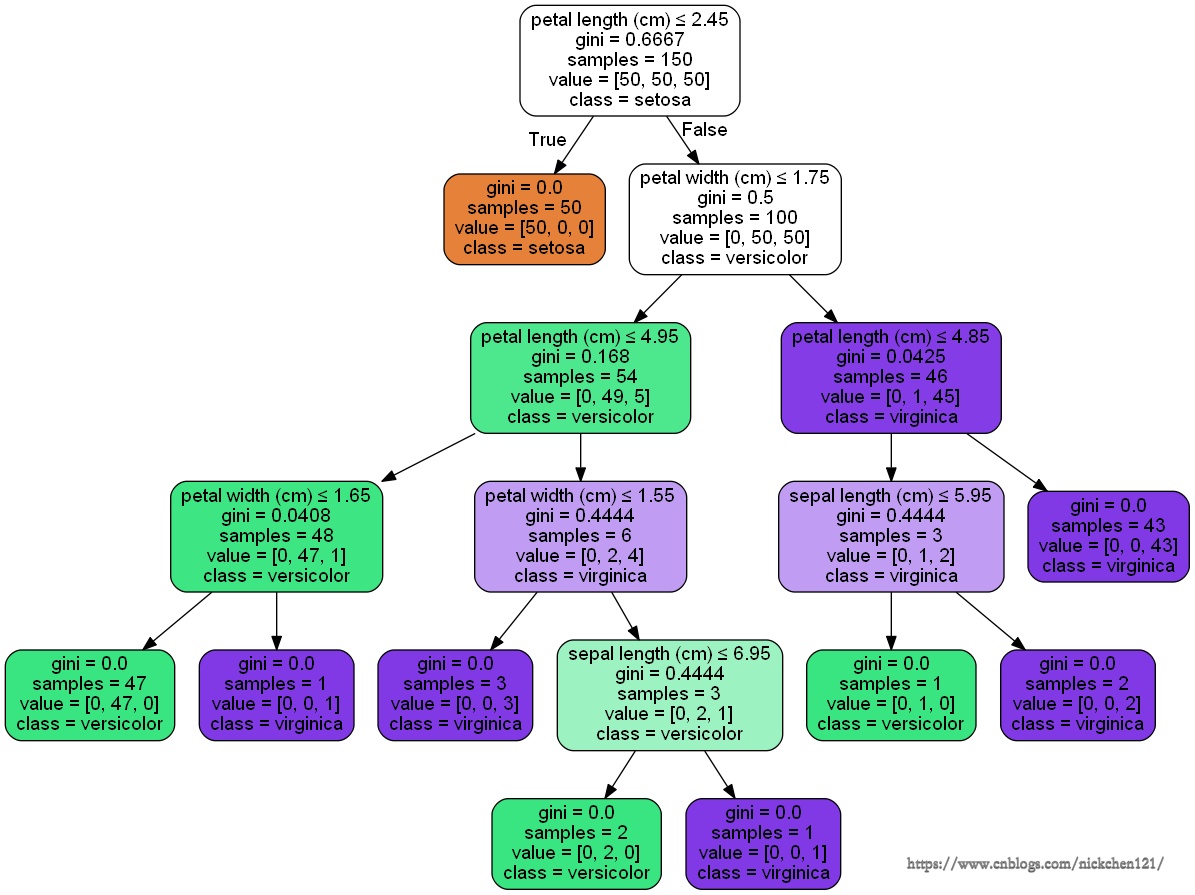
四、4.?DecisionTreeClassifier实例
这里给一个限制决策树层数为4的DecisionTreeClassifier例子。
完整代码见我的github: https://github.com/ljpzzz/machinelearning/blob/master/classic-machine-learning/decision_tree_classifier_1.ipynb
from itertools import product
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.tree import DecisionTreeClassifier
# 仍然使用自带的iris数据
iris = datasets.load_iris()
X = iris.data[:, [0, 2]]
y = iris.target
# 训练模型,限制树的最大深度4
clf = DecisionTreeClassifier(max_depth=4)
#拟合模型
clf.fit(X, y)
# 画图
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.1),
np.arange(y_min, y_max, 0.1))
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, alpha=0.4)
plt.scatter(X[:, 0], X[:, 1], c=y, alpha=0.8)
plt.show()
得到的图如下:
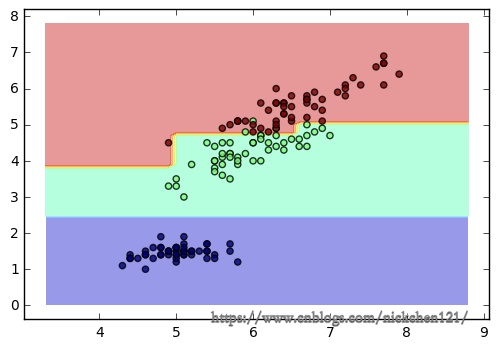
接着我们可视化我们的决策树,使用了推荐的第三种方法。代码如下:
from IPython.display import Image
from sklearn import tree
import pydotplus
dot_data = tree.export_graphviz(clf, out_file=None,
feature_names=iris.feature_names,
class_names=iris.target_names,
filled=True, rounded=True,
special_characters=True)
graph = pydotplus.graph_from_dot_data(dot_data)
Image(graph.create_png())
生成的决策树图如下:
?
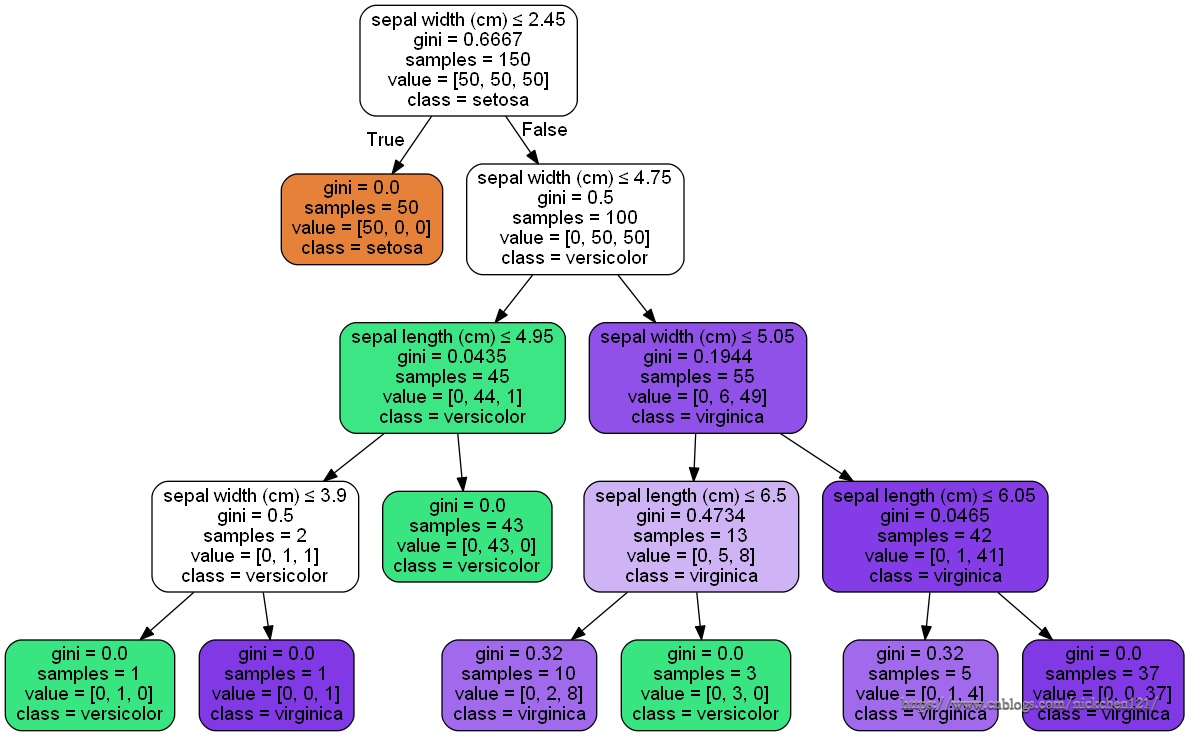
以上就是scikit-learn决策树算法使用的一个总结,希望可以帮到大家。
?
(欢迎转载,转载请注明出处。欢迎沟通交流: 微信:nickchen121)?
以上是关于scikit-learn决策树算法类库使用小结的主要内容,如果未能解决你的问题,请参考以下文章
scikit-learn 朴素贝叶斯类库使用小结
决策树实践
scikit-learn 默认使用哪种决策树算法?
如何控制scikit-learn决策树算法的精度
python中使用scikit-learn的决策树算法运行错误
[机器学习与scikit-learn-15]:算法-决策树-分类问题代码详解