百度OCR文字识别API使用心得===com.baidu.ocr.sdk.exception.SDKError[283604]
Posted upuptop
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了百度OCR文字识别API使用心得===com.baidu.ocr.sdk.exception.SDKError[283604]相关的知识,希望对你有一定的参考价值。
异常com.baidu.ocr.sdk.exception.SDKError[283604]App identifier unmatch.错误的packname或bundleId.logId::30309247
https://download.csdn.net/download/pyfysf/10406761
最终实现的效果(识别的有些慢,是由于我的网速原因。-_-)
![]() ?
?
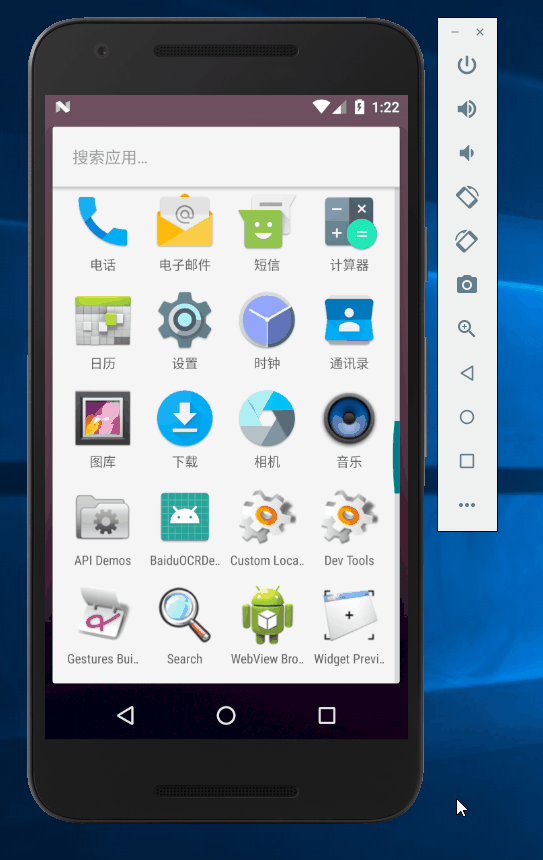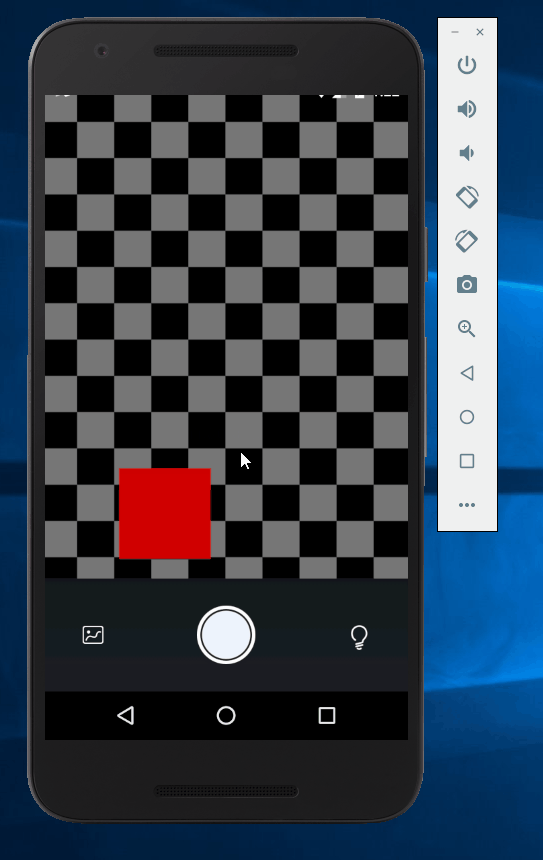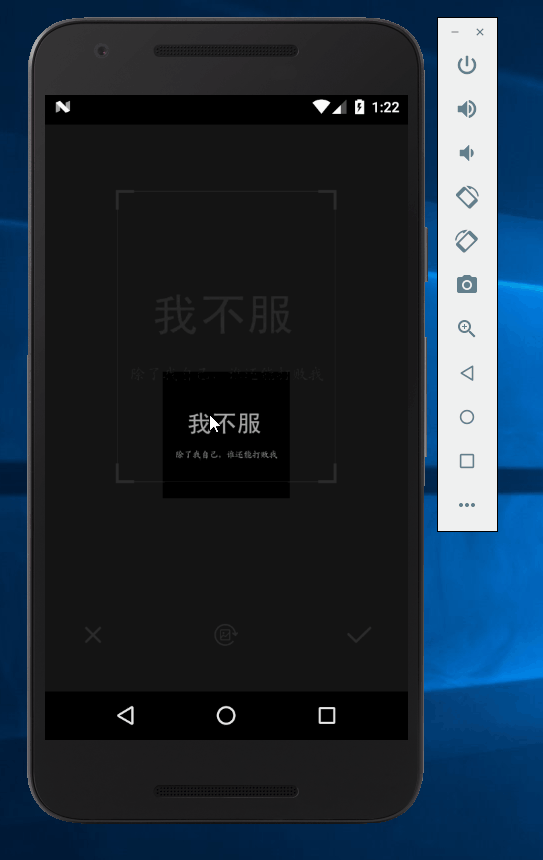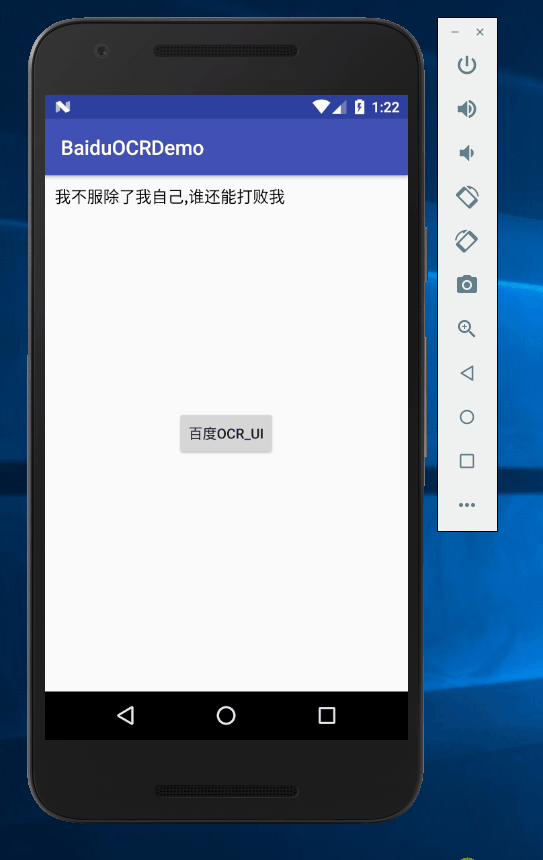
最近有个小项目使用到了OCR技术,顺便到网上搜索了一下,大家都在使用百度的API。所以我就调用了百度的接口。在使用的过程中也是遇到了各种各样的错误。
比如TOKEN ERROR了。等等。
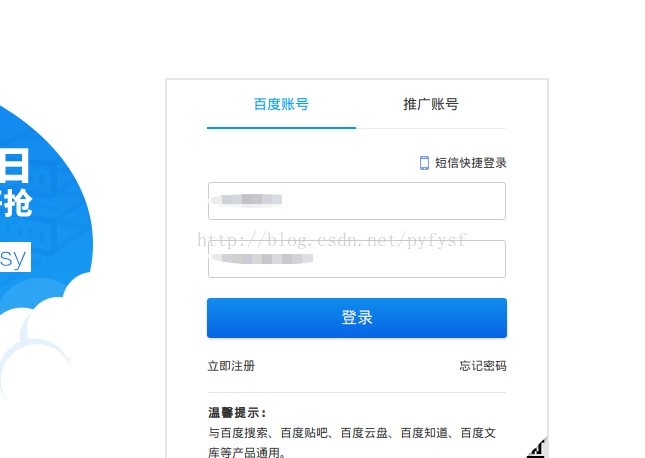
注册登录百度云平台
首先注册百度账号,点击这里跳转到百度API接口首页
![]() ?
?

点击控制台进行登录注册。
![]() ?
?
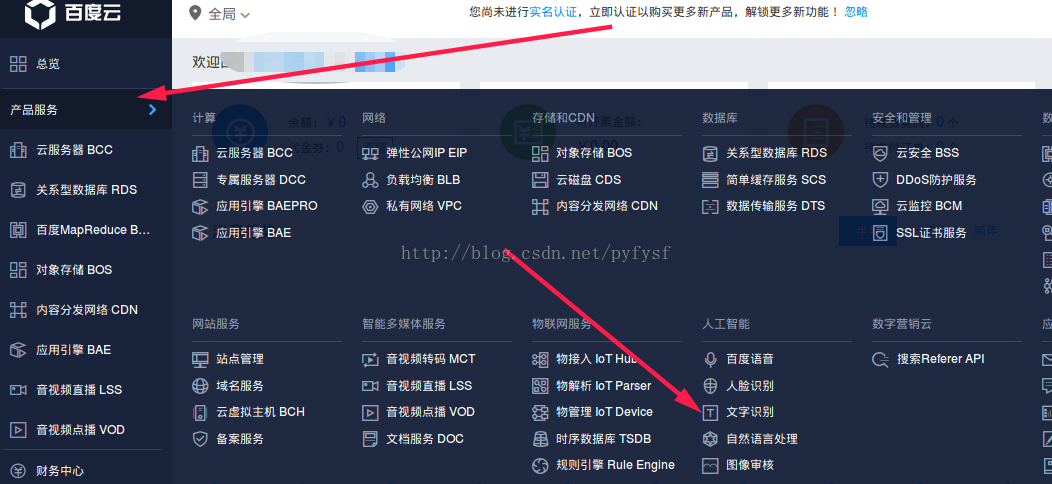
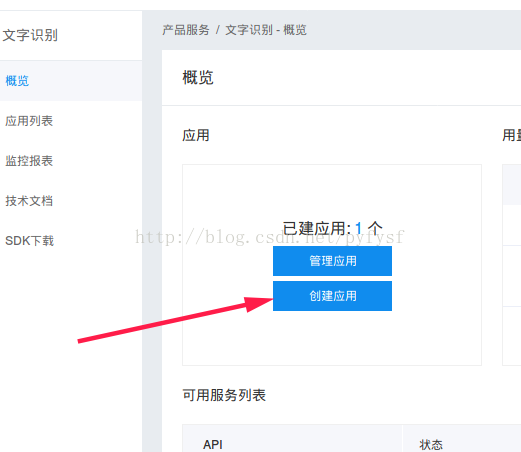
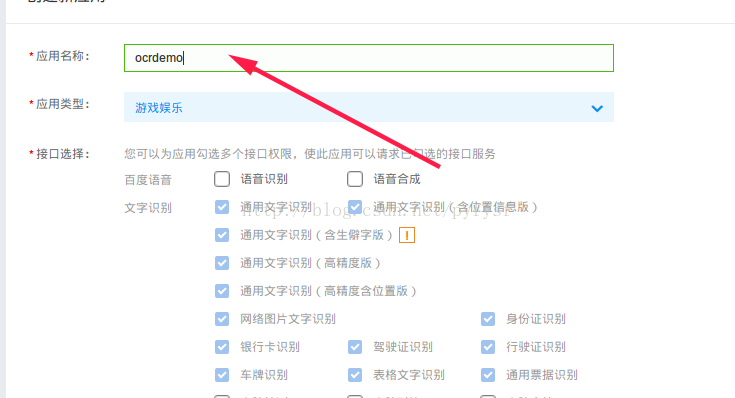
选择服务,创建应用
![]() ?
?
![]() ?
?
![]() ?
?
![]() ?
?
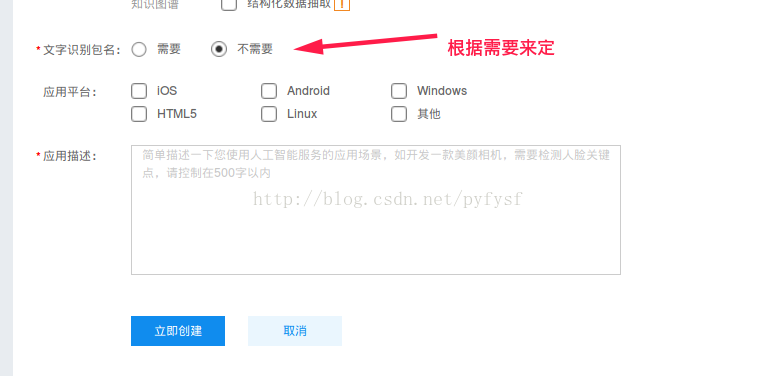
选择需要包名的朋友看过来 >>>>> https://blog.csdn.net/pyfysf/article/details/86438769
这个AK和SK是需要在代码中使用到的
![]() ?
?

配置SDK,查看文档调用接口。
点击这里进入API文档;
![]() ?
?
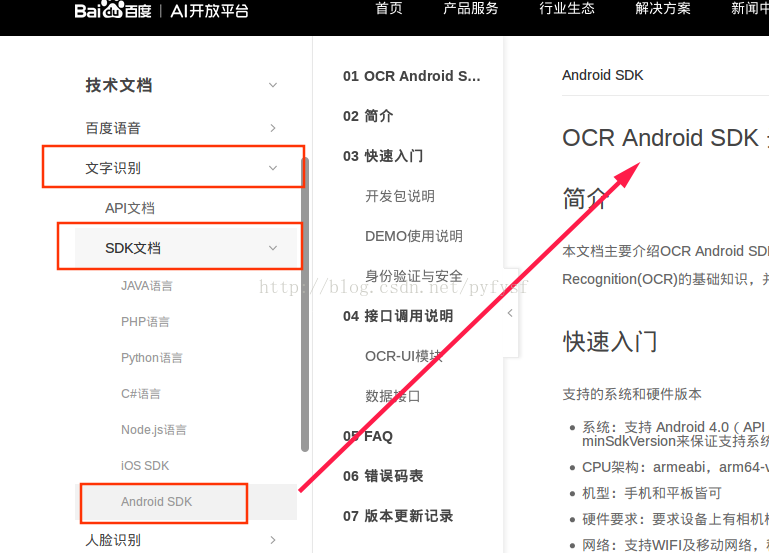
博主使用的是android平台的SDK。
根据步骤进行SDK工程配置。
配置完工程之后博主就很惊喜的去调用方法进行写代码了。但是,logcat总是报错。说获取token失败,packname错误或者AK和SK错误。
这里我就很是纳闷。我根本没有设置项目的包名,并且我的AK和SK是正确的。大家有知道解决方法,求大神在评论区指教博主。博主在这里叩谢。
然后经过我查询资料,我选择请求API,从而不去调用百度封装的方法。
查阅API文档。
![]() ?
?
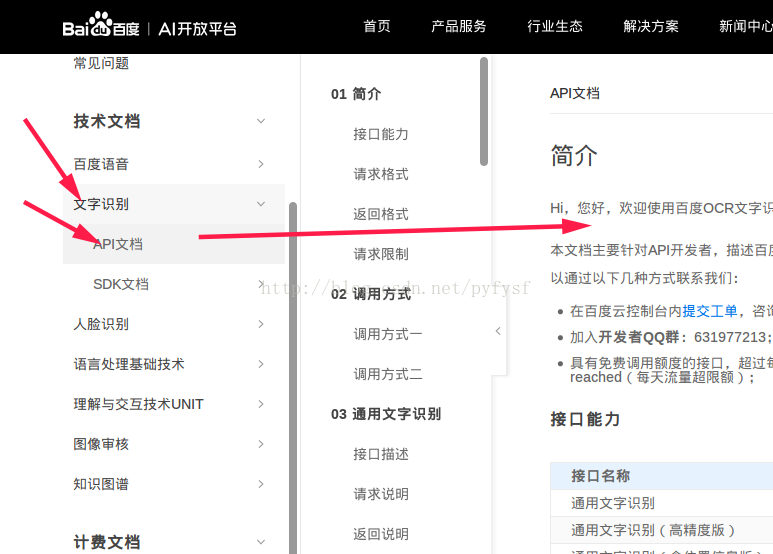
实现代码片段(不提供xml布局文件)
下面将贴一些代码片段。
博主是打开相机拍一张照片进行扫描实现OCR识别文字。百度的API可以接受本地图片的路径,或者网络上的图片URL也可以进行OCR文字扫描。
我用到了百度提供的UI,在SDK里面导入到项目里面就可以了。
拍照之后获取照片的保存路径。
核心代码在这里!!
请求百度文字识别API,进行图片OCR识别。我用的是xutils3.0请求的网络。可以使用HTTPConnection发起get请求。
/** * 请求百度API接口,进行获取数据 * * @param filePath */ private void checkData(String filePath) try //把图片文件转换为字节数组 byte[] imgData = FileUtil.readFileByBytes(filePath); //对字节数组进行Base64编码 String imgStr = Base64Util.encode(imgData); final String params = URLEncoder.encode("image", "UTF-8") + "=" + URLEncoder.encode(imgStr, "UTF-8"); RequestParams entiry = new RequestParams(ConstantValue.BAIDU_TOKEN_URL); x.http().get(entiry, new Callback.CommonCallback<String>() @Override public void onSuccess(final String result) Gson gson = new Gson(); TokenInfo tokenInfo = gson.fromJson(result, TokenInfo.class); final String access_token = tokenInfo.getAccess_token(); new Thread() public void run() // public static final String BAIDU_TOKEN_URL = "https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=" + 你在百度控制台创建的AK+ "&client_secret=" + 你在百度控制台创建的SK; String resultStr = HttpUtil.post(ConstantValue.BAIDU_INTER_URL, access_token, params); Log.e("MainActivity", "MainActivity onSuccess()" + resultStr); Message msg = Message.obtain(); msg.obj = resultStr; msg.what = PRESER_IMG_OK; handler.sendMessage(msg); .start(); @Override public void onError(Throwable ex, boolean isOnCallback) @Override public void onCancelled(CancelledException cex) @Override public void onFinished() ); catch (UnsupportedEncodingException e) e.printStackTrace(); catch (IOException e) e.printStackTrace();
解析数据,官方返回的是一个json串。所以我们进行解析数据
FileUtil和HttpUtils
public static File getSaveFile(Context context)
File file = new File(context.getFilesDir(), "pic.jpg");
return file;
/**
* 根据文件路径读取byte[] 数组
*/
public static byte[] readFileByBytes(String filePath) throws IOException
File file = new File(filePath);
if (!file.exists())
throw new FileNotFoundException(filePath);
else
ByteArrayOutputStream bos = new ByteArrayOutputStream((int) file.length());
BufferedInputStream in = null;
try
in = new BufferedInputStream(new FileInputStream(file));
short bufSize = 1024;
byte[] buffer = new byte[bufSize];
int len1;
while (-1 != (len1 = in.read(buffer, 0, bufSize)))
bos.write(buffer, 0, len1);
byte[] var7 = bos.toByteArray();
return var7;
finally
try
if (in != null)
in.close();
catch (IOException var14)
var14.printStackTrace();
bos.close();
/**
* http 工具类
*/
public class HttpUtil
public static String post(String requestUrl, String accessToken, String params)
try
String generalUrl = requestUrl + "?access_token=" + accessToken;
URL url = new URL(generalUrl);
// 打开和URL之间的连接
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
connection.setRequestMethod("POST");
// 设置通用的请求属性
connection.setRequestProperty("Content-Type", "application/x-www-form-urlencoded");
connection.setRequestProperty("Connection", "Keep-Alive");
connection.setUseCaches(false);
connection.setDoOutput(true);
connection.setDoInput(true);
// 得到请求的输出流对象
DataOutputStream out = new DataOutputStream(connection.getOutputStream());
out.writeBytes(params);
out.flush();
out.close();
// 建立实际的连接
connection.connect();
// 获取所有响应头字段
Map<String, List<String>> headers = connection.getHeaderFields();
// 遍历所有的响应头字段
for (String key : headers.keySet())
System.out.println(key + "--->" + headers.get(key));
// 定义 BufferedReader输入流来读取URL的响应
BufferedReader in = null;
if (requestUrl.contains("nlp"))
in = new BufferedReader(new InputStreamReader(connection.getInputStream(), "GBK"));
else
in = new BufferedReader(new InputStreamReader(connection.getInputStream(), "UTF-8"));
String result = "";
String getLine;
while ((getLine = in.readLine()) != null)
result += getLine;
in.close();
System.out.println("result:" + result);
return result;
catch (Exception e)
throw new RuntimeException(e);
Base64Util
这样就可以实现了。
https://download.csdn.net/download/pyfysf/10406761
有问题可以加博主QQ哦。337081267
https://download.csdn.net/download/pyfysf/10406761
以上是关于百度OCR文字识别API使用心得===com.baidu.ocr.sdk.exception.SDKError[283604]的主要内容,如果未能解决你的问题,请参考以下文章