弱监督学习
Posted jiangkejie
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了弱监督学习相关的知识,希望对你有一定的参考价值。
南京大学周志华教授综述论文:弱监督学习
转自机器之心:https://www.jiqizhixin.com/articles/2018-03-05
在《国家科学评论》(National Science Review, NSR) 2018 年 1 月份出版的机器学习专题期刊中,介绍了南京大学周志华教授发表的一篇论文《A brief introduction to weakly supervised learning》。机器之心经授权对此论文部分内容做了编译介绍,更完整内容可查看英文论文原文。
摘要:监督学习技术通过学习大量训练样本来构建预测模型,其中每个训练样本都有一个标签标明其真值输出。尽管当前的技术已经取得了巨大的成功,但是值得注意的是,由于数据标注过程的高成本,很多任务很难获得如全部真值标签这样的强监督信息。因此,能够使用弱监督的机器学习技术是可取的。本文综述了弱监督学习的一些研究进展,主要关注三种弱监督类型:不完全监督:只有一部分训练数据具备标签;不确切监督:训练数据只具备粗粒度标签;以及不准确监督:给出的标签并不总是真值。
机器学习在各种任务中取得了巨大成功,特别是在分类和回归等监督学习任务中。预测模型是从包含大量训练样本的训练数据集中学习,每个训练样本对应一个事件或对象。训练样本由两部分组成:一个描述事件/对象的特征向量(或示例),以及一个表示真值输出的标签。在分类任务中,标签表示训练样本所属的类别;在回归任务中,标签是一个与样本对应的实数值。大多数成功的技术,如深度学习 [1],都需要含有真值标签的大规模训练数据集,然而,在许多任务中,由于数据标注过程的成本极高,很难获得强监督信息。因此,研究者十分希望获得能够在弱监督前提下工作的机器学习技巧。
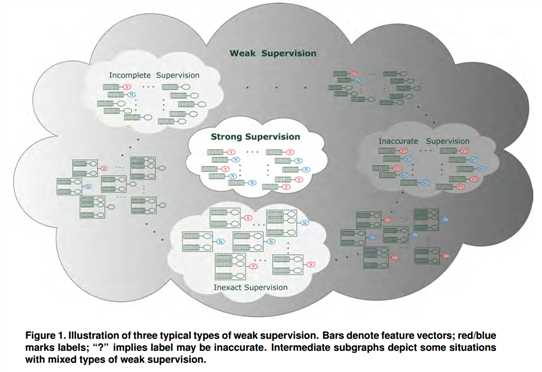
通常来说,弱监督可以分为三类。第一类是不完全监督(incomplete supervision),即,只有训练集的一个(通常很小的)子集是有标签的,其他数据则没有标签。这种情况发生在各类任务中。例如,在图像分类任务中,真值标签由人类标注者给出的。从互联网上获取巨量图片很容易,然而考虑到标记的人工成本,只有一个小子集的图像能够被标注。第二类是不确切监督(inexact supervision),即,图像只有粗粒度的标签。第三种是不准确的监督(inaccurate supervision),模型给出的标签不总是真值。出现这种情况的常见原因有,图片标注者不小心或比较疲倦,或者某些图片就是难以分类。
弱监督学习是一个总括性的术语,涵盖了尝试通过较弱的监督来学习并构建预测模型的各种研究。在本文中,我们将讨论这一研究领域的一些进展,重点放在以不完整、不确切和不准确的监督进行学习的研究。我们将把不同类型的弱监督分开,但值得一提的是,在实际操作中,几种弱监督经常同时发生。为简单起见,在本文中我们以包含两个可交换类 Y 和 N 的二元分类为例。形式化表达为,在强监督学习条件下,监督学习的任务是从训练数据集![]() 中学习
中学习![]() ,其中
,其中![]() 是特征空间,
是特征空间,![]() ,
,![]() ,以及
,以及![]() 。
。
我们假设![]() 是根据未知的独立同分布 D 生成的;换言之,
是根据未知的独立同分布 D 生成的;换言之,![]() 是 i.i.d. 样本。图 1 提供了我们将在本文中讨论的三种弱监督类型的示例。
是 i.i.d. 样本。图 1 提供了我们将在本文中讨论的三种弱监督类型的示例。
不完全监督
不完全监督考虑那些我们只拥有少量有标注数据的情况,这些有标注数据并不足以训练出好的模型,但是我们拥有大量未标注数据可供使用。形式化表达为,模型的任务是从训练数据集![]() 中学习
中学习![]() ,其中训练集中有 l 个有标注训练样本(即给出
,其中训练集中有 l 个有标注训练样本(即给出 ![]() 的样本)和 u = m - l 个未标注样本;其他条件与具有强监督的监督学习相同,如摘要最后的定义。为便于讨论,我们也将 l 个有标注示例称为「标注数据」,将 u 个未标注示例称为「未标注数据」。
的样本)和 u = m - l 个未标注样本;其他条件与具有强监督的监督学习相同,如摘要最后的定义。为便于讨论,我们也将 l 个有标注示例称为「标注数据」,将 u 个未标注示例称为「未标注数据」。
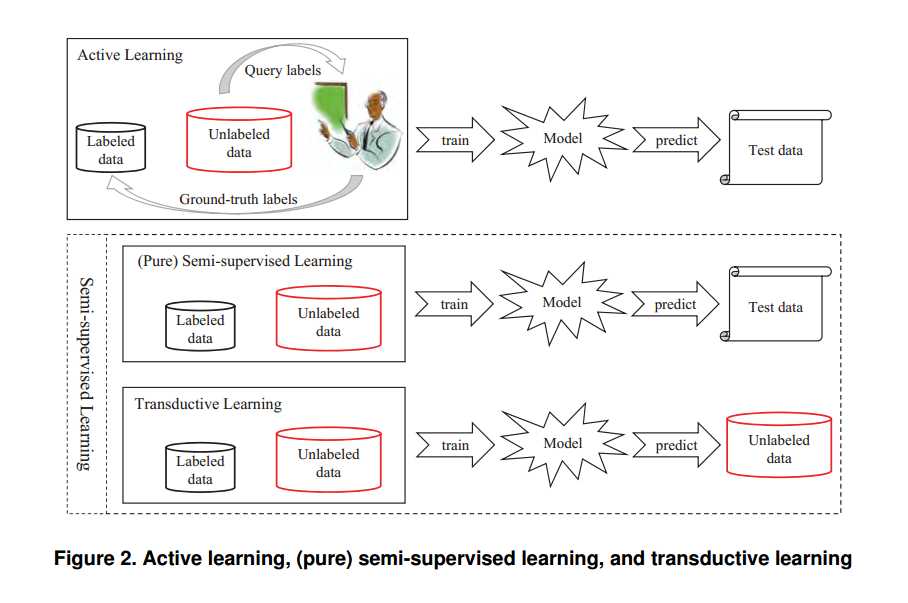
能够实现此目标的主要两类技巧,即,主动学习 [2] 和半监督学习 [3-5]。
主动学习假设存在一个「神谕」(oracle),比如一位人类专家,能够向他查询选定的未标注示例的真值标签。
相比之下,半监督式学习试图在有标注数据之外,自动开发无标注数据以提高学习效果,这个过程不需要人工干预。存在一种特殊的半监督学习,称为直推式学习(transductive learning);直推式学习和(纯)半监督学习的主要区别在于,它们对测试数据,即训练过的模型需要进行预测的数据,假设有所不同。直推式学习持有「封闭世界」假设,即,测试数据是事先给出的、目标是优化测试数据的性能;换言之,未标注数据正是测试数据。纯半监督式学习则持有「开放世界」假设,即,测试数据是未知的,未标注数据不一定是测试数据。图 2 直观地表示了主动学习、(纯)半监督学习和直推式学习之间的差异。
不确切监督
不确切监督关注于给定了监督信息,但信息不够精确的场景。一个典型的场景是仅有粗粒度的标签信息可用。例如,在药物活性预测 [40] 的问题中,其目标是建立一个模型学习已知分子的知识,来预测一个新的分子是否适合制造一种特定药物。一个分子可以有很多的低能量形状,而这些分子是否能用于制药取决于这些分子是否具有某些特殊的形状。然而即使对于已知的分子,人类专家也仅知道该分子是否适合制药,而不知道其中决定性的分子形状是什么。
形式化表达为,该任务是从训练数据集![]() 中学习
中学习![]() ,其中
,其中![]() 被称为一个包。
被称为一个包。
![]() ,
,![]() 是一个示例,m_i 是示例 X_i 的数量,
是一个示例,m_i 是示例 X_i 的数量,![]() 。
。
X_i 是一个 positive 包,即 y_i=Y,如果存在 x_ip 是正的,同时![]() 是未知的。其目标是为未见过的包预测标签。该方法被称为多示例学习 [40,41]。
是未知的。其目标是为未见过的包预测标签。该方法被称为多示例学习 [40,41]。
已经有许多有效的算法被开发出来并应用于多示例学习。实际上,几乎所有的有监督学习算法都有对等的多示例算法。大多数算法试图调整单示例监督学习算法,使其适配多示例表示,主要是将其关注点从对示例的识别转移到对包的识别 [42];一些其他算法试图通过表示变换,调整多示例表示使其适配单示例算法 [43,44]。还有一种类型 [45],将算法分为三类:一个整合了示例级响应的示例空间范式,一个把 包 视作一个整体的 包 空间范式,以及一个在嵌入特征空间中进行学习的嵌入空间范式中。请注意,这些示例通常被视为 i.i.d. 样本,然而,[46] 表明,多示例学习中的示例不应该被认为是独立的,尽管这些包可以被视为 i.i.d. 样本,并且已经有一些有效的算法是基于此见解进行开发的 [47]。
多示例学习已成功应用于各种任务,如图像分类/检索/注释 [48-50],文本分类 [51,52],垃圾邮件检测 [53],医学诊断 [54],面部/对象检测 [55,56],对象类别发现 [57],对象跟踪 [58] 等。在这些任务中,将真实对象(例如一幅图像或一个文本文档)视为一个包是很自然的。然而,不同于药物活性预测这类包中包含天然示例(分子的各种形状)的例子,需要为每个包生成示例。包生成器制定如何生成示例来构成包。通常情况下,可以从图像中提取许多小的图像块作为其示例,而章节/段落甚至句子可以用作文本文档的示例。尽管包生成器对学习效果有重要影响,但最近才出现关于图像包生成器的全面研究 [59],研究揭示了一些简单的密集取样包生成器比一些复杂的生成器性能更好。图 5 显示了两个简单而有效的图像包生成器。

多示例学习的初始目标是为未见过的包预测标签;然而,已有研究尝试识别那些之所以让正包变正的关键示例(key instance)[31,60]。这在诸如没有细粒度标记训练数据的感兴趣区域定位的任务中特别有用。值得注意的是,标准的多示例学习 [40] 假定每一个正包必须包含一个关键示例,而还有其它研究假定不存在关键示例,每一个示例都对包标签有贡献 [61,62];甚至假定存在多个概念,而仅当一个包包含满足所有概念的示例时,该包才是正的 [63]。可以在文献 [41] 中找到更多的变体。
早期的理论结果 [64-66] 表明多示例学习对于包中每个示例都由不同的规则分类的异质(heterogeneous)案例来说,是很难的,对于以相同的规则分类所有示例的同质性(homogeneous)案例就是可学习的。幸运的是,几乎所有的实际多示例任务都属于同质性案例。这些分析假定 bag 中的示例是独立的。而不假定示例的独立性的分析更具挑战性,这类研究也出现得较晚,其揭示了在同质性类中,至少存在某些可以用包间的任意分布来学习的案例 [67]。尽管如此,与其在算法和应用上的繁荣发展相反,多示例学习的理论研究成果非常少,因为分析的难度太大。
某些在包中任意分布的示例是可学习的 [67]。尽管如此,与在算法和应用上的繁荣发展相反,多示例学习的理论研究成果非常少,因为分析的难度太大。
不准确监督关注于监督信息不总是真值的场景,也就是说,有部分信息会出现错误。其形式基本和引言最后部分的表示相同,除了训练数据集中的 y_i 可能是不准确的。
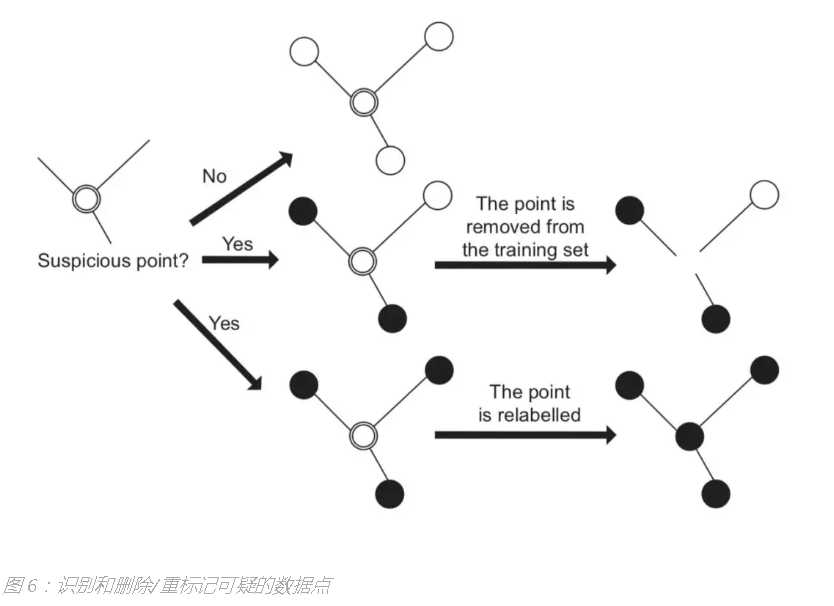
一个典型的场景是在有标签噪声的情况下进行学习 [68]。目前已有很多理论研究 [69-71],其中大多数假定存在随机的分类噪声,即标签受随机噪声影响。在实践中,基本的思想是识别潜在的误分类样本 [72],然后尝试进行修正。例如,数据编辑(data-editing)方法 [73] 构建了相对邻域图(relative neighborhood graph),其中每一个节点对应一个训练样本,而连接两个不同标签的节点的边被称为切边(cut edge)。然后,测量 一个切边的权重统计量,直觉上,如果一个示例连接了太多的切边,则该示例是可疑的。可疑的示例要么被删除,要么被重新标记,如图 6 所示。值得注意的是,这种方法通常依赖于咨询邻域信息;由于当数据很稀疏时,邻域识别将变得更不可靠,因此,在高维特征空间中该方法的可靠性将变弱。
近期出现的有趣的不准确监督的场景是众包模式 [74],这是一种流行的将工作外包给个人的范式。对于机器学习来说,用众包模式为训练数据收集标签是一种经济的方式。具体来说,未标记的数据被外包给大量的工人来标记。在著名的众包系统 Amazon Mechanical Turk 上,用户可以提交一项任务,例如将图片标注为「树」或「非树」,然后职工完成工作以获取少量报酬。通常这些工人来自世界各地,每个人都可以执行多个任务。这些职工通常互相独立,报酬不高,并通过自己的判断标记数据。这些职工的标记质量参差不齐,但标记质量信息对于用户来说是不可见的,因为工人的身份是保密的。在这些职工中可能存在「垃圾制造者」,几乎用随机的标签来标记数据(例如,用机器替代人类赚取报酬),或「反抗者」,故意给出错误的标签。此外,某些任务可能对一些人来说太难而无法完成。使用众包返回的不准确监督信息来保证学习性能是非常困难的。
很多研究尝试用众包标签推断真值标签。多数人投票策略得到了集成方法 [35] 的理论支持,在实践中得到了广泛使用并有很好的表现 [75,76],因此通常作为基线标准。如果预期可以对工人质量和任务难度建模,那么通过为不同的工人在不同的任务上设置权重,则可以获得更好的效果。为此,一些方法尝试构建概率模型然后使用 EM 算法进行评估 [77,78]。人们也使用了极小极大熵方法 [35]。概率模型可以用于移除垃圾制造者 [79]。近期人们给出了移除低质量工人的一般理论条件 [80]。
在机器学习中,众包通常用于收集标签,在实践中,模型的最终性能,而不是这些标签的质量,才是更重要的。目前已有很多关于从低能老师和众包标签学习的研究 [81,82],这和用带噪声标签学习是很接近的。但其中的区别在于,对于众包设定而言,人们可以方便地、重复地对某个示例提取众包标签。因此,在众包数据学习中,考虑经济性和最小化众包标签的充分数量是很重要的,即有效众包学习的最小代价 [83]。很多研究专注于任务分配和预算分配,尝试在准确率和标注开销之间取得平衡。为此,非适应性的任务分配机制(离线分配任务 [84,85])和适应性机制(在线分配任务 [86,87])都得到了在理论支持下的研究。需要注意的是,多数研究采用了 Dawid–Skene 模型 [88],其假设不同任务的潜在成本是相同的,而没有探索更复杂的成本设置。
设计一个有效的众包协议也是很重要的。在文献 [89] 中提供了「不确定」选项,从而使工人在不确定的时候不被迫使给出确定的标签。该选项可以帮助标记的可靠性获得有理论支持 [90] 的提升。在文献 [91] 中提出了一种「double or nothing」的激励兼容机制,以确保工人能提供基于其自己的信心的标注,诚实地工作。在假定每位工人都希望最大化他们的报酬的前提下,该协议被证实可以避免垃圾制造者的出现。
结论
监督学习技术在具备强监督信息(如大量具备真值标签的训练样本)的情况中取得了很大成功。然而,在实际任务中,收集监督信息需要大量成本,因此,使用弱监督学习通常是更好的方式。
本文主要介绍三种典型的弱监督:不完全、不确切和不准确监督。尽管三者可以分开讨论,但是实践中它们通常同时出现,如图 1 所示,以往研究中也讨论过此类「混合」案例 [52,92,93]。此外,还存在其他类型的弱监督。例如,主要通过强化学习方法解决 [94] 的延时监督也属于弱监督。由于篇幅限制,本文实际上扮演了更多文献索引而非文献综述的角色。对细节感兴趣的读者请阅读对应参考文献。近期越来越多的研究者关注弱监督学习,如部分监督学习主要关注不完全监督学习 [95],同时也有很多关于弱监督的其他讨论 [96,97]。
为了简化讨论,本文主要关注二分类,尽管大部分讨论经过稍微改动就可以扩展到多类别或回归学习。注意,多类别任务中可能会出现更复杂的情景 [98]。如果考虑到多标签学习 [99],即每个样本同时关联到多个标签的任务,则情况更加复杂。以不完全监督为例,除了标注/非标注示例以外,多标签任务可能遇到部分标注示例,即训练示例中,只有部分标签是真值 [100]。即使只考虑标注/未标注数据,其设计选项也比单标签设置多。如对于积极学习而言,给出一个非标注示例,在多标签任务中可以要求给出该示例的所有标签 [101]、特定标签 [102],或一对标签的相关性排序 [103]。然而,不管是哪种数据和任务,弱监督学习都变得越来越重要。
英文原文 2017 年 8 月发表于《国家科学评论》(National Science Review, NSR),原标题为「A brief introduction to weakly supervised learning」。《国家科学评论》是科学出版社旗下期刊,与牛津大学出版社联合出版。机器之心经《国家科学评论》和牛津大学出版社授权刊发该论文文中文翻译。
原文英文链接:https://doi.org/10.1093/nsr/nww086
以上是关于弱监督学习的主要内容,如果未能解决你的问题,请参考以下文章
A brief introduction to weakly supervised learning(简要介绍弱监督学习)