hdfs原理之四大机制
Posted zhangxiaofan
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hdfs原理之四大机制相关的知识,希望对你有一定的参考价值。
一、心跳机制
1、心跳报告概念
datanode会定时的向namenode发送心跳报告,目的是告诉namenode自己的存活状况以及可用空间。这个时间默认为3秒。

2、心跳报告具体作用
(1)向namenode汇报自己的存活状况以及可用空间
(2)向namenode发送块报告,每一个datanode上存储的块的信息向namenode做汇报。
3、namenode存储元数据的位置
(1)硬盘
/home/hadoop/data/hadoopdata/name/current
包含3部分内容:
A、抽象目录树
B、数据和块的对应关系
C、数据块的存储位置
(2)内存
真正的读写操作的时候操作的是元数据。最初的内存中的元数据信息只包含抽象目录树、数据和块的对应关系部分(/hadoop-2.7.6.tar.gz [blk01:[],blk02:[]])不包含块的存储位置的。
用户读取的时候需要块的存储位置的,块信息是datanode向namenode发送心跳报告(块报告) 的时候获取的
hdp01 blk01 blk02---> namenode
hdp03 blk01 blk02 ---> namenode
/hadoop-2.7.6.tar.gz [blk01:[hdp01,hdp03],blk02:[hdp01,hdp03]]
4、确认datanode宕机
(1)停止发送心跳报告
默认连续10次心跳接受不到即连续10*3=30s不间断。这10次中间只要有1次接受到了重新记录心跳。

(2)namenode发送检查
在连续10次namenode没有接收到datanode的心跳报告之后,namenode断定datanode可能宕机了,namenode主动向datanode发送检查 namenode会开启后台的守护(阻塞)进程 等待检查结果的。namenode检查datanode的时间:默认5min。

默认检查2次每次检查5min连续2次检查(10min)都没有反应确认datanode宕机了(发送一次等待5分钟)。namenode确认一个datanode宕机需要的总时间: 10*3s+300s*2=630s
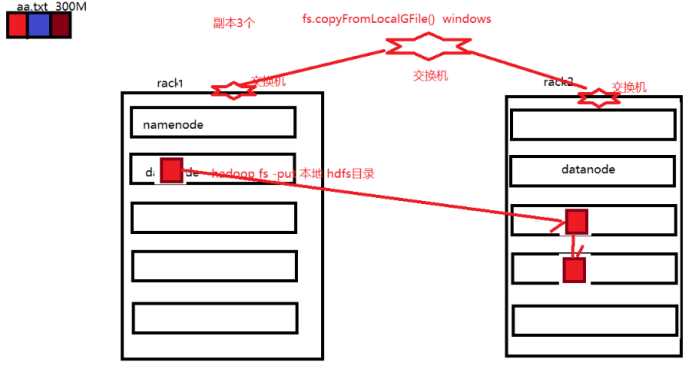
二、机架策略
1、副本存放策略
决定每一个数据块的多个副本如何存储的,hdfs默认的每一个块的副本有3个,每一个块多个副本存储在不同节点上。
2、机房服务器
u型服务器,u是一个单位,所谓“1U的PC服务器”,就是外形满足EIA规格、厚度为4.445cm的产品。
3、默认案例
默认副本3个,默认机架2个,10个节点。多个副本的放置策略:
(1)第一个副本放在客户端所在节点
目的为了防止数据块的副本上传不成功
最大程度的保证第一个副本上传成功
如果客户端不是集群中的节点 随机选择一个节点
(2)第二个副本放在与第一个副本不同机架的任意节点
目的:保证数据安全
防止机架整体断电 断网
(3)第三个副本放在和第二个副本相同机架的不同节点上
目的:便于传输 提升数据传输的效率
4、实际生产
(1)多个机架
机架可能3,4,5,6,7....
副本存放发生调整
副本3个
每一个机架存一个
(2)多个机房
数据副本,不同机房存储
不同机房,不同机架,不同节点
机架存放策略需要配置的,不配置情况下默认不同的副本存储在不同的节点。
三、负载均衡
1、概念
hadoop集群中多个datanode中每一个datanode存储的数据的占比相当负载均衡和每一个datanode的硬件相关的。
集群的总存储 60g
hdp01 50g 20G 40%
hdp02 50g 20g 40%
hdp03 50g 20g 40%
2、默认负载均衡
对于hadoop集群来说namenode会定期检查集群的负载如果发现集群中datanode节点的负载不均衡的情况下自动启动负载均衡进行负载均衡,将存储占比大的datanode节点上的数据移动到存储占比小的datanode节点上。
hdp01 50g 40G 80%
hdp02 50g 20g 20%
hdp03 50g 0g 0%
将hdp01的数据块移动hdp03上底层网络传输(因为是不同的节点间进行传输)将hdp01上的数据经过网络传输传递给hdp03再将hdp01上的删除。
默认情况下这个带宽是很小:默认带宽 1M/S

3、手动负载均衡
默认的负载均衡,如果集群中的节点很少,默认的负载均衡完全没问题的(要进行传输的东西少)。如果集群中的节点很多的时候,默认的负载均衡很难达到需求了(要进行传输的东西多),所以需要启动手动负载均衡:start-balancer.sh -t 10%。
(1)这个命令不会立即执行类似于jvm垃圾回收,提醒集群空闲的时候立即执行加快执行效率。
(2)-t 10%
代表负载均衡的最终停止的要求,没有绝对的负载均衡的只有相对的。我们讲的负载均衡都是占比差在可接受的范围-t参数指定的就是节点存储的最大-最小的占比差。
hdp01 50g 42%
hdp02 50g 40%
hdp03 50g 38%
-t 10 10% 42%-38%=4% 认为负载均衡的
(3)这个命令手动执行一定配合带宽调整,就是抽出空闲的时间尽快的执行并达到负载均衡,所以带宽一般会调大一点。

四、安全模式
1、概念
集群的一种自我保护模式,集群再安全模式下不允许用户进行相关操作。
2、进入安全模式
(1)集群启动
集群的启动顺序:
namenode---》 datanode---》 secondarynamenode集群再启动namenode和datanode的时候一直处于安全模式的。
A、启动namenode
hdfs的元数据存储:磁盘,持久化存储抽象目录树、数据和块的对应关系、数据块的存储位置;内存中,不能够持久化,即在关闭集群的时候全部清除,在开启集群的时候再从磁盘中加载进来,加载抽象目录树、数据和块的对应关系。
hdfs启动之前内存中没有元数据信息的,namenode启动的时候将磁盘中的元数据加载到内存中一份,为了快速加载只会加载抽象目录树、数据和块的对应关系的元数据信息。
B、启动datanode
每一个启动完成datanode,这个datanode立即向namenode发送心跳发送块报告信息,namenode接受datanode的心跳报告统计块报告添加上块的每一个副本的存储节点块的存储位置。
C、启动secondarynamenode
secondarynamenode启动完成向namenode发送心跳
集群启动过程中执行步骤1步骤2的时候进行namenode元数据的完善阶段这个时候集群不能对外提供服务的处于自我保护的状态安全模式。
(2)集群运行过程
集群的块的汇报率 < 99.9%
datanode节点的汇报个数小于设置
namenode的元数据的存储目录的大小 <100m
3、离开安全模式
集群处于安全模式的时候对元数据相关信息做哪一些检查
(1) 每一个数据块的最小副本个数,保证有一个可用就可用

(2)可用数据块的汇报率,保证集群中的99.9%的数据块是可用的(每一个数据块只保证1个副本)

(3)可用的最小节点个数,默认0个

(4)安全模式的停留时长(指定系统退出安全模式时需要的延迟时间,默认为30(秒))

(5)检查元数据存储的文件夹大小,默认100M

符合以下的要求 才会离开安全模式:
(1)数据块的汇报率(每一个数据块最少保证1个副本)达到>=99.9%
(2)datanode的节点个数达到配置要求的时候 默认是0个
(3)当前两个条件都满足的时候 保证安全模式30s 保证保证集群数据汇报稳定的时候
(4)保证namenode每一个元数据的文件夹的存储预留大小达到100M以上

以上4个条件全部同时满足的时候会退出安全模式。
4、手动进入安全模式
一般情况下集群升级的时候hadoop2.7—》hadoop2.8 一般将集群进入安全模式,进行集群维护。
hdfs dfsadmin -safemode get/leave/enter/wait (在hadoop2.0之前可以用hadoop来代替hdfs)
(1)hdfs dfsadmin -safemode get 获取集群的当前的安全模式的状态
Safe mode is OFF 安全模式关闭的
(2)hdfs dfsadmin -safemode enter 进入安全模式
Safe mode is ON
(3)hdfs dfsadmin -safemode leave 离开安全模式
(4)hdfs dfsadmin -safemode wait 等待安全模式离开 了解
5、安全模式下的操作
(1)可执行
hadoop fs -ls /
hadoop fs -get /hadoop6 /home/hadoop/apps
hadoop fs -cat /hdfs-site.xml
hadoop fs -tail /hdfs-site.xml
这些操作查询相关的,只要不修改元数据的操作都可以执行(元数据1)目录树 2)文件--块 3)块的位置)
(2)不可执行
只要修改元数据的操作都不能执行
hadoop fs -put 本地 hdfs
hadoop fs -mkdir /dd
hadoop fs -touchz /rr
hadoop fs -rm -r -f
....
以上是关于hdfs原理之四大机制的主要内容,如果未能解决你的问题,请参考以下文章