Hadoop详解——HDFS的命令,执行过程,Java接口,原理详解。RPC机制
Posted LIUXUN1993728
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop详解——HDFS的命令,执行过程,Java接口,原理详解。RPC机制相关的知识,希望对你有一定的参考价值。
HDFS是Hadoop的一大核心,关于HDFS需要掌握的有:
分布式系统与HDFS、HDFS的体系架构和基本概念、HDFS的shell操作、Java接口以及常用的API、Hadoop的RPC机制、远程debug
Distributed File System
数据量越来越多,在一个操作系统管理的范围存储不了,那么就需要分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,因此迫切需要一种系统来管理多台机器上的文件,这就是所谓的分布式文件管理系统。 分布式文件管理系统是一种允许文件通过网络在多台机器主机上分享的文件系统,可以让多台机器上的多用户分享文件和存储空间。 通透性。实际上通过网络来访问文件的动作,由程序和用户看来,就像是访问本地的磁盘一般。 容错。即使系统中有些节点脱机,整体来说系统仍然可以持续运作而不会有数据丢失。 分布式文件系统有很多,HDFS只是其中的一种。适用于一次写入多次查询,不支持并发写情况,小文件不合适。 (注意:分布式文件系统不支持并发写并不是指禁止多个客户端同时写数据,而是指在写一个文件时不允许同时向多个块进行写入) 常见的分布式文件系统有很多如下所示: 常见的分布式文件系统有,GFS、HDFS、Lustre 、Ceph 、GridFS 、mogileFS、TFS、FastDFS等。各自适用于不同的领域。它们都不是系统级的分布式文件系统,而是应用级的分布式文件存储服务。Google学术论文,这是众多分布式文件系统的起源
==================================
Google File System(大规模分散文件系统)
MapReduce (大规模分散FrameWork)
BigTable(大规模分散数据库)
Chubby(分散锁服务)
一般你搜索Google_三大论文中文版(Bigtable、 GFS、 Google MapReduce)就有了。
做个中文版下载源:http://dl.iteye.com/topics/download/38db9a29-3e17-3dce-bc93-df9286081126
做个原版地址链接:
http://labs.google.com/papers/gfs.html
http://labs.google.com/papers/bigtable.html
http://labs.google.com/papers/mapreduce.html
GFS(Google File System)
Google公司为了满足本公司需求而开发的基于Linux的专有分布式文件系统。。尽管Google公布了该系统的一些技术细节,但Google并没有将该系统的软件部分作为开源软件发布。
下面分布式文件系统都是类 GFS的产品。
HDFS
Hadoop 实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。 Hadoop是Apache Lucene创始人Doug Cutting开发的使用广泛的文本搜索库。它起源于Apache Nutch,后者是一个开源的网络搜索引擎,本身也是Luene项目的一部分。Aapche Hadoop架构是MapReduce算法的一种开源应用,是Google开创其帝国的重要基石。
Ceph
是加州大学圣克鲁兹分校的Sage weil攻读博士时开发的分布式文件系统。并使用Ceph完成了他的论文。
说 ceph 性能最高,C++编写的代码,支持Fuse,并且没有单点故障依赖, 于是下载安装, 由于 ceph 使用 btrfs 文件系统, 而btrfs 文件系统需要 Linux 2.6.34 以上的内核才支持。
可是ceph太不成熟了,它基于的btrfs本身就不成熟,它的官方网站上也明确指出不要把ceph用在生产环境中。
Lustre
Lustre是一个大规模的、安全可靠的,具备高可用性的集群文件系统,它是由SUN公司开发和维护的。
该项目主要的目的就是开发下一代的集群文件系统,可以支持超过10000个节点,数以PB的数据量存储系统。
目前Lustre已经运用在一些领域,例如HP SFS产品等。
适合存储小文件、图片的分布文件系统研究
用于图片等小文件大规模存储的分布式文件系统调研
架构高性能海量图片服务器的技术要素
nginx性能改进一例(图片全部存入google的leveldb)
FastDFS分布文件系统
TFS(Taobao File System)安装方法
动态生成图片 Nginx + GraphicsMagick
MogileFS
由memcahed的开发公司danga一款perl开发的产品,目前国内使用mogielFS的有图片托管网站yupoo等。
MogileFS是一套高效的文件自动备份组件,由Six Apart开发,广泛应用在包括LiveJournal等web2.0站点上。
MogileFS由3个部分组成:
第1个部分是server端,包括mogilefsd和mogstored两个程序。前者即是 mogilefsd的tracker,它将一些全局信息保存在数据库里,例如站点domain,class,host等。后者即是存储节点(store node),它其实是个HTTP Daemon,默认侦听在7500端口,接受客户端的文件备份请求。在安装完后,要运行mogadm工具将所有的store node注册到mogilefsd的数据库里,mogilefsd会对这些节点进行管理和监控。
第2个部分是utils(工具集),主要是MogileFS的一些管理工具,例如mogadm等。
第3个部分是客户端API,目前只有Perl API(MogileFS.pm)、php,用这个模块可以编写客户端程序,实现文件的备份管理功能。
mooseFS
持FUSE,相对比较轻量级,对master服务器有单点依赖,用perl编写,性能相对较差,国内用的人比较多
MooseFS与MogileFS的性能测试对比
FastDFS
是一款类似Google FS的开源分布式文件系统,是纯C语言开发的。
FastDFS是一个开源的轻量级分布式文件系统,它对文件进行管理,功能包括:文件存储、文件同步、文件访问(文件上传、文件下载)等,解决了大容量存储和负载均衡的问题。特别适合以文件为载体的在线服务,如相册网站、视频网站等等。
官方论坛 http://bbs.chinaunix.net/forum-240-1.html
FastDfs google Code http://code.google.com/p/fastdfs/
分布式文件系统FastDFS架构剖析 http://www.programmer.com.cn/4380/
TFS
TFS(Taobao !FileSystem)是一个高可扩展、高可用、高性能、面向互联网服务的分布式文件系统,主要针对海量的非结构化数据,它构筑在普通的Linux机器 集群上,可为外部提供高可靠和高并发的存储访问。TFS为淘宝提供海量小文件存储,通常文件大小不超过1M,满足了淘宝对小文件存储的需求,被广泛地应用 在淘宝各项应用中。它采用了HA架构和平滑扩容,保证了整个文件系统的可用性和扩展性。同时扁平化的数据组织结构,可将文件名映射到文件的物理地址,简化 了文件的访问流程,一定程度上为TFS提供了良好的读写性能。
官网 : http://code.taobao.org/p/tfs/wiki/index/
GridFS文件系统
MongoDB是一种知名的NoSql数据库,GridFS是MongoDB的一个内置功能,它提供一组文件操作的API以利用MongoDB存储文件,GridFS的基本原理是将文件保存在两个Collection中,一个保存文件索引,一个保存文件内容,文件内容按一定大小分成若干块,每一块存在一个Document中,这种方法不仅提供了文件存储,还提供了对文件相关的一些附加属性(比如MD5值,文件名等等)的存储。文件在GridFS中会按4MB为单位进行分块存储。
MongoDB GridFS 数据读取效率 benchmark
http://blog.nosqlfan.com/html/730.html
nginx + gridfs 实现图片的分布式存储 安装(一年后出问题了)
http://www.cnblogs.com/zhangmiao-chp/archive/2011/05/05/2038285.html
基于MongoDB GridFS的图片存储
http://liut.cc/blog/2010/12/about-imsto_my-first-open-source-project.html
nginx+mongodb-gridfs+squid
http://1008305.blog.51cto.com/998305/885340
HDFS命令
查看使用帮助 输入hadoop ,回车会有帮助提示。提示中有jar、fs等。操作文件系统明显是使用hadoop fs 再回车 就会出现hadoop fs 的参数帮助了:Usage: hadoop fs [generic options]
[-appendToFile <localsrc> ... <dst>] 将文件追加到指定文件
[-cat [-ignoreCrc] <src> ...] 查看文件内容
[-checksum <src> ...] 获取校验格 很少用
[-chgrp [-R] GROUP PATH...] 改变HDFS中文件的所属组
[-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...] 改变文件权限
[-chown [-R] [OWNER][:[GROUP]] PATH...] 改变文件的所属用户或所属组
[-copyFromLocal [-f] [-p] [-l] <localsrc> ... <dst>] 将本地系统的文件拷贝到HDFS系统上 相当于put命令
[-copyToLocal [-p] [-ignoreCrc] [-crc] <src> ... <localdst>] 将HDFS上的文件拷贝到本地系统 相当于get命令
[-count [-q] [-h] <path> ...] 统计HDFS指定路径下文件和文件夹的数量 以及占用空间的大小
[-cp [-f] [-p | -p[topax]] <src> ... <dst>] 将HDFS的文件拷贝到另一个地方 指的将HDFS文件拷贝到HDFS的另一处
[-createSnapshot <snapshotDir> [<snapshotName>]]
[-deleteSnapshot <snapshotDir> <snapshotName>]
[-df [-h] [<path> ...]]
[-du [-s] [-h] <path> ...]
[-expunge]
[-find <path> ... <expression> ...]
[-get [-p] [-ignoreCrc] [-crc] <src> ... <localdst>] 下载文件到本地系统
[-getfacl [-R] <path>]
[-getfattr [-R] -n name | -d [-e en] <path>]
[-getmerge [-nl] <src> <localdst>]
[-help [cmd ...]] -help+命令 查看命令的使用帮助
[-ls [-d] [-h] [-R] [<path> ...]] HDFS文件查看 参数-R 表示递归查看 -H 将文件大小由字节单位转为K M等单位
[-mkdir [-p] <path> ...] 在HDFS系统上创建文件夹
[-moveFromLocal <localsrc> ... <dst>] 从本地剪切一个文件上传到HDFS系统(相当于上传文件后将本地此文件删除)
[-moveToLocal <src> <localdst>] 相当于将HDFS上的文件下载到本地 然后再将HDFS系统上的此文件删除
[-mv <src> ... <dst>] 将HDFS系统的内容从一处移动到HDFS系统上的另一位置
[-put [-f] [-p] [-l] <localsrc> ... <dst>] 将本地文件上传至HDFS系统
[-renameSnapshot <snapshotDir> <oldName> <newName>]
[-rm [-f] [-r|-R] [-skipTrash] <src> ...] 将HDFS系统上的某文件删除(不加参数只能删除文件类型 加-R可删除文件夹)
[-rmdir [--ignore-fail-on-non-empty] <dir> ...] 只能删除HDFS上的文件夹 有很大局限性
[-setfacl [-R] [-b|-k -m|-x <acl_spec> <path>]|[--set <acl_spec> <path>]]
[-setfattr -n name [-v value] | -x name <path>]
[-setrep [-R] [-w] <rep> <path> ...]
[-stat [format] <path> ...]
[-tail [-f] <file>] 查看文件尾部的内容
[-test -[defsz] <path>]
[-text [-ignoreCrc] <src> ...] 相当于-cat 查看HDFS系统上的文件内容
[-touchz <path> ...] 可以在HDFS系统上创建文件 相当于Linux系统的touch命令
[-truncate [-w] <length> <path> ...]
[-usage [cmd ...]]使用方法:hadoop fs -cat URI [URI …]
将路径指定文件的内容输出到stdout 。
示例:
hadoop fs -cat hdfs://host1:port1/file1 hdfs://host2:port2/file2
hadoop fs -cat file:///file3 /user/hadoop/file4
返回值:
成功返回0,失败返回-1。
(2) chgrp
使用方法:hadoop fs -chgrp [-R] GROUP URI [URI …] Change group association of files. With -R , make the change recursively through the directory structure. The user must be the owner of files, or else a super-user. Additional information is in the Permissions User Guide . -->
改变文件所属的组。使用-R 将使改变在目录结构下递归进行。命令的使用者必须是 文件的所有者或者超级用户。更多的信息请参见HDFS 权限用户指南 。
(3) chmod
使用方法:hadoop fs -chmod [-R] <MODE[,MODE]... | OCTALMODE> URI [URI …]
改变文件的权限。使用-R 将使改变在目录结构下递归进行。命令的使用者必须是文 件的所有者或者超级用户。更多的信息请参见HDFS 权限用户指南 。
(4) chown
使用方法:hadoop fs -chown [-R] [OWNER][:[GROUP]] URI [URI ]
改变文件的拥有者。使用-R 将使改变在目录结构下递归进行。命令的使用者必须是 超级用户。更多的信息请参见HDFS 权限用户指南 。
(5) copyFromLocal
使用方法:hadoop fs -copyFromLocal <localsrc> URI
除了限定源路径是一个本地文件外,和put 命 令相似。
(6) copyToLocal
使用方法:hadoop fs -copyToLocal [-ignorecrc] [-crc] URI <localdst>
除了限定目标路径是一个本地文件外,和get 命 令类似。
(7) cp
使用方法:hadoop fs -cp URI [URI …] <dest>
将文件从源路径复制到目标路径。这个命令允许有多个源路径,此时目标路径必须是一个目录。
示例:
hadoop fs -cp /user/hadoop/file1 /user/hadoop/file2
hadoop fs -cp /user/hadoop/file1 /user/hadoop/file2 /user/hadoop/dir
返回值:
成功返回0,失败返回-1。注意:cp命令限定输入和输出地址都必须是HDFS上的地址
(8) du
使用方法:hadoop fs -du URI [URI …]
显示目录中所有文件的大小,或者当只指定一个文件时,显示此文件的大小。
示例:
hadoop fs -du /user/hadoop/dir1 /user/hadoop/file1 hdfs://host:port/user/hadoop/dir1
返回值:
成功返回0,失败返回-1。
(9) dus
使用方法:hadoop fs -dus <args>
显示文件的大小。
(10) expunge
使用方法:hadoop fs -expunge
清空回收站。请参考HDFS 设计 文档以获取更多关于回收站特性的信息。
(11) get
使用方法:hadoop fs -get [-ignorecrc] [-crc] <src> <localdst>
复制文件到本地文件系统。可用-ignorecrc 选项复制CRC校验失败的文 件。使用-crc 选项复制文件以及CRC信息。
示例:
hadoop fs -get /user/hadoop/file localfile
hadoop fs -get hdfs://host:port/user/hadoop/file localfile
返回值:
成功返回0,失败返回-1。
(12) getmerge
使用方法:hadoop fs -getmerge <src> <localdst> [addnl]
接受一个源目录和一个目标文件作为输入,并且将源目录中所有的文件连接成本地目标文件。addnl 是 可选的,用于指定在每个文件结尾添加一个换行符。
(13) ls
使用方法:hadoop fs -ls <args>
如果是文件,则按照如下格式返回文件信息:
文件名 <副本数> 文件大小 修改日期 修改时间 权限 用户ID 组ID
如果是目录,则返回它直接子文件的一个列表,就像在Unix中一样。目录返回列表的信息如下:
目录名 <dir> 修改日期 修改时间 权限 用户ID 组ID
示例:
hadoop fs -ls /user/hadoop/file1 /user/hadoop/file2 hdfs://host:port/user/hadoop/dir1 /nonexistentfile
返回值:
成功返回0,失败返回-1。
(14) lsr
使用方法:hadoop fs -lsr <args>
ls 命令的递归版本。类似于Unix中的ls -R 。
(15) mkdir
使用方法:hadoop fs -mkdir <paths>
接受路径指定的uri作为参数,创建这些目录。其行为类似于Unix的mkdir -p,它会创建路径中的各级父目录。
示例:
hadoop fs -mkdir /user/hadoop/dir1 /user/hadoop/dir2
hadoop fs -mkdir hdfs://host1:port1/user/hadoop/dir hdfs://host2:port2/user/hadoop/dir
返回值:
成功返回0,失败返回-1。
(16) movefromLocal
使用方法:dfs -moveFromLocal <src> <dst>
输出一个”not implemented“信息。
(17) mv
使用方法:hadoop fs -mv URI [URI …] <dest>
将文件从源路径移动到目标路径。这个命令允许有多个源路径,此时目标路径必须是一个目录。不允许在不同的文件系统间移动文件。
示例:
hadoop fs -mv /user/hadoop/file1 /user/hadoop/file2
hadoop fs -mv hdfs://host:port/file1 hdfs://host:port/file2 hdfs://host:port/file3 hdfs://host:port/dir1
返回值:
成功返回0,失败返回-1。
(18) put
使用方法:hadoop fs -put <localsrc> ... <dst>
从本地文件系统中复制单个或多个源路径到目标文件系统。也支持从标准输入中读取输入写入目标文件系统。
hadoop fs -put localfile /user/hadoop/hadoopfile
hadoop fs -put localfile1 localfile2 /user/hadoop/hadoopdir
hadoop fs -put localfile hdfs://host:port/hadoop/hadoopfile
hadoop fs -put - hdfs://host:port/hadoop/hadoopfile
从标准输入中读取输入。
返回值:
成功返回0,失败返回-1。
(19) rm
使用方法:hadoop fs -rm URI [URI …]
删除指定的文件。只删除非空目录和文件。请参考rmr命令了解递归删除。
示例:
hadoop fs -rm hdfs://host:port/file /user/hadoop/emptydir
返回值:
成功返回0,失败返回-1。
(20) rmr
使用方法:hadoop fs -rmr URI [URI …]
delete的递归版本。
示例:
hadoop fs -rmr /user/hadoop/dir
hadoop fs -rmr hdfs://host:port/user/hadoop/dir
返回值:
成功返回0,失败返回-1。
(21) setrep
使用方法:hadoop fs -setrep [-R] <path>
改变一个文件的副本系数。-R选项用于递归改变目录下所有文件的副本系数。
示例:
hadoop fs -setrep -w 3 -R /user/hadoop/dir1
返回值:
成功返回0,失败返回-1。
(22) stat
使用方法:hadoop fs -stat URI [URI …]
返回指定路径的统计信息。
示例:
hadoop fs -stat path
返回值:
成功返回0,失败返回-1。
(23) tail
使用方法:hadoop fs -tail [-f] URI
将文件尾部1K字节的内容输出到stdout。支持-f选项,行为和Unix中一致。
示例:
hadoop fs -tail pathname
返回值:
成功返回0,失败返回-1。
(24) test
使用方法:hadoop fs -test -[ezd] URI
选项:
-e 检查文件是否存在。如果存在则返回0。
-z 检查文件是否是0字节。如果是则返回0。
-d 如果路径是个目录,则返回1,否则返回0。
示例:
hadoop fs -test -e filename
(25) text
使用方法:hadoop fs -text <src>
将源文件输出为文本格式。允许的格式是zip和TextRecordInputStream。
(26) touchz
使用方法:hadoop fs -touchz URI [URI …]
创建一个0字节的空文件。
示例:
hadoop -touchz pathname
HDFS 架构
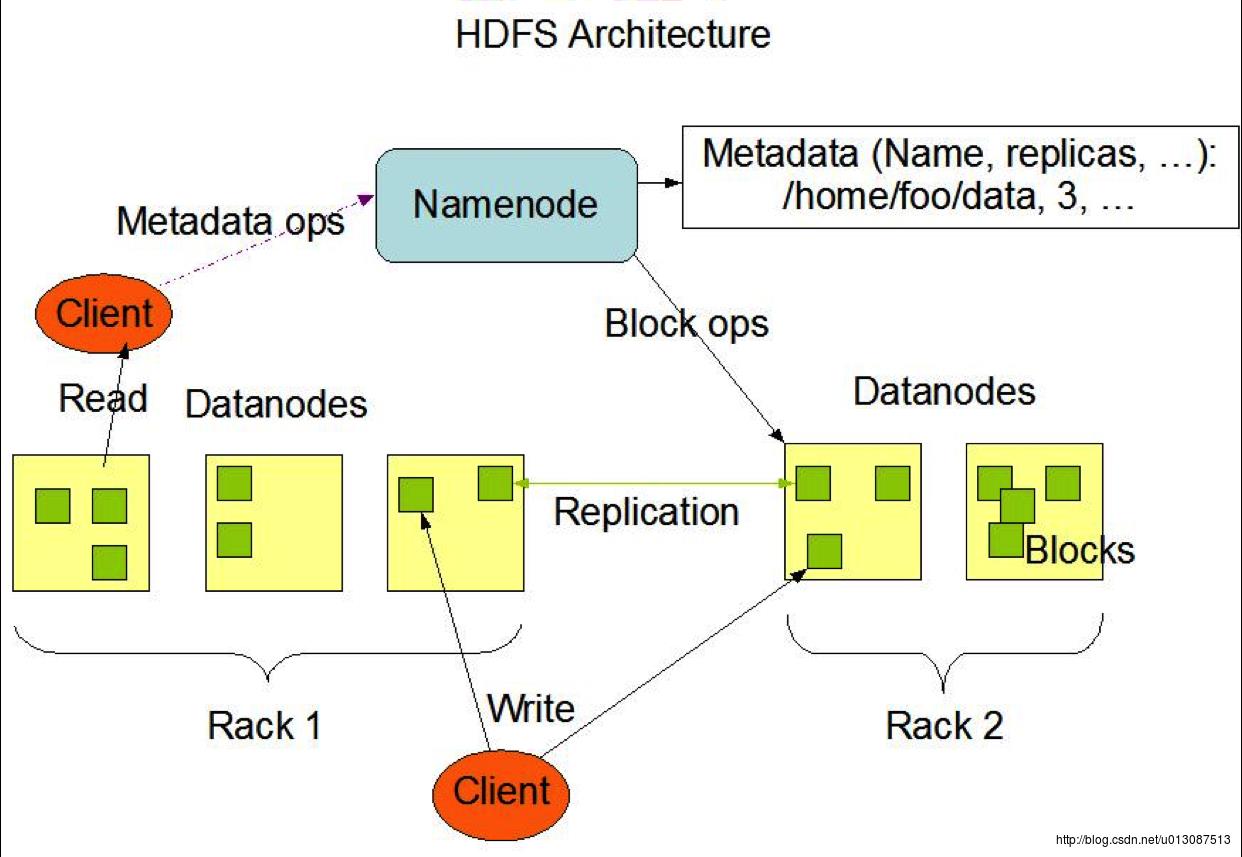
NameNode:负责管理节点 DataNode:负责存储数据 Secondary NameNode:并不是NameNode的热备,只是NameNode的助理。 Metadata元数据也称为schema 交互过程: 1. 首先客户端进行一些Metadata options与NameNode进行交互,NameNode会查询元数据信息。 2. NameNode从内存中查询元数据信息(为了快速和安全 NameNode会将元数据信息保存在内存中,并序列化一份到磁盘) 3. NameNode会将查询到的元数据信息返回给Client。 4. Client会根据元数据信息依照机架感知(就近原则)依次从DataNodes中获取数据(一个NameNode可以存储多个Block,例如客户端请求一个512M的数据 ,而这个数据可能在其中的一台机器上存储了三个Block,在另一个DataNode上存储了一个Block,client就会优先选择离自己最近 走交换机次数最少的DataNode进行获取 然再从另一个DataNode中获取) 5. 为了数据安全NameNode会让DataNode执行一些Block operations 按照配置的副本集数量对DataNode中相应的数据进行水平复制
NameNode中Metadata内容

/test/a.log 表示某文件在HDFS上的存储地址 3 表示此文件保存的副本集数量 blk_1,blk_2 表示此文件被分成了哪几个块
blk_1:[h0,h1,h3] 表示块blk_1副本集分别在DataNode为h0、h1、h3上各存放了一份
blk_2:[h0,h2,h4] 表示块blk_1副本集分别在DataNode为h0、h1、h3上各存放了一份
示例如下:假设一个客户端向NameNode发送请求获取/test/a.log NameNode就会将此文件的metadata数据信息发送给这个客户端,这个客户端就会根据元数据信息获取块数据,在获取块blk_1时 根据就近原则从h0、h1、h3中选择离自己最近的DataNode获取blk_1,在获取blk_1后,再获取blk_2块数据,仍然从h0,h2,h4中选择离自己最近的DataNode获取blk_2 假设h2离客户端最近(机架感应机制 根据请求通过交换机的数量等信息进行判定) 那么优先从h2中获取blk_2, 如果h2出现了问题和错误,那么再从h0和h4中获取。
注意:是根据校验核机制断定DataNode上的文件是否出现错误,每一个文件(块)都有一个对应的校验值,一旦文件损坏 其校验值就会改变,如果校验值与元数据中对应的校验值不一致就会认为该文件已经损坏。校验核机制常见的有MD5和CRC32校验核机制,因为MD5校验核机制比较慢,HDFS使用的是CRC32校验机制。
HDFS主要对象概述
NameNode NameNode是整个文件系统的管理节点,它维护着整个文件系统的文件目录树,文件/目录的元信息和每个文件对应的数据块列表。接收用户的请求。 文件包括: 存放地址由在hdfs-site.xml中的dfs.name.dir属性指定 ① fismage:元数据的镜像文件。存储某一时段NameNode内存的元数据信息。 ② edits:操作日志文件。 ③ fstime:保存最近一次checkpoint的时间 以上这些文件是保存在Linux文件系统之上的。 NameNode的工作特点: ① NameNode始终在内存中保存metadata,用于处理"读请求"。 ② 如果有"写请求"到来时,NameNode首先会写editlog到磁盘,即向edits文件中写日志,成功返回后,才会修改内存,并向客户端返回。 ③ Hadoop会维护一个fsimage文件,也就是NameNode中metadata的镜像,但是fsimage不会随时与NameNode内存中的metadata保持一致,而是每隔一段时间通过合并edits文件来更新内容。Secondary NameNode就是用来合并fsimage和edits文件来更新NameNode的metadata的。Secondary NameNode HA(Hadoop够可靠性)的一个解决方案,但是不支持热备。 执行过程:从NameNode上下载元数据信息(fsimage,edits),然后将两者合并,生成新的fsimage,在本地生成,并将其推送到NameNode,替换成fsimage。 Secondary NameNode默认安装在NameNode节点上,但是并不安全。 Secondary NameNode的工作流程: ① Secondary通知NameNode切换edits文件。 ② Secondary从NameNode获得fsimage和edits(通过http)。 ③ Secondary将fsimage载入内存,然后开始合并edits。 ④ Secondary 将新的fsimage返回给NameNode。 ⑤ NameNode用新的fsimage替换旧的fsimage。
合并时机checkpoint fs.checkpoint.period 指定两次checkpoint的最大时间间隔,默认3600秒。
fs.checkpoint.size 规定edits文件的最大值,一旦超过这个值则强制checkpoint,不管是否到达最大时间间隔。默认大小是64M。
DataNode 提供真实文件数据的存储服务 文件块(block):最基本的存储单位。对于文件内容而言,一个文件的长度大小是size,那么从文件的0偏移开始,按照固定的大小,顺序对文件进行划分并编号,划分好每一个块称为Block。HDFS在1.0中默认的Block大小是64MB,在2.0中默认是128MB。以一个256MB文件为例,共有256/128=2个Block。 不同于普通文件系统的是,HDFS中,如果一个文件小于一个数据块的大小,并不占用整个Block数据块的存储空间。 Replication。多副本,默认是3个。(hdfs-site.xml的dfs.replication属性) 注意:Secondary NameNode只存在于伪分布式系统中,真实集群中是不需要Secondary NameNode的。
NameNode和Secondary协作流程

(以上是hadoop1.0的合并流程,2.0已经不再使用此种方式) 第一步:client向NameNode发送请求信息,比如上传文件 NameNode查看文件信息 判断应该将此文件分配到哪些台DataNode上
第二步:NameNode将元数据信息反馈给client
第三步:client根据元数据信息向对应的DataNode里面写数据,客户端写数据的同时 NameNode会操作对应的edits文件,不管客户端上传成功还是失败 NameNode都会在对应的edits文件中添加一行记录(+1) 同时内存中的metadata信息也会改变添加一行描述信息,但是fsimage(序列化到磁盘metadata信息)中没有改变 即未同步,在满足一定的条件下Secondary NameNode发现内存中的metadatas和fsimage内容不一致,开始工作从NameNode中下载获取edits和fsimage文件,开始合并 根据edits中的操作信息向fsimage中写入metadata信息 这时fsimage信息和内存中的metadatas信息一致 即完成同步 同时删除NameNode上的edits文件, 将新生成的edits.new替换为edits。一旦Secondary NameNode合并edits和fsimage文件 就会完成内存中metadata和fsimage中元数据信息的同步。
合并的时机:
fs.checkpoint.period 按照一定的时间间隔,默认是3600秒 即一个小时。
fs.checkpoint.size 当edits文件大小达到规定的最大值,就会触发合并条件。
注意: 注意在开始合并的过程中处于数据安全的考虑(例如Secondary NameNode在合并时下载文件失败或者合并失败等各种意外),在合并的过程中不会删除NameNode上的edits和fsimage文件 为了确保数据的一致性,在合并时会生成一个新的edits文件即edits.new 。在合并的过程中如果接收到文件操作的请求(例如文件上传等) 会使用这个新的edits文件(edits.new)来存放操作文件的信息。在Secondary NameNode合并完成并成功向NameNode发送新的fsimage文件后NameNode才会将edits.new替换掉旧的edits文件,将新的fsimage替换旧的fsimage
心跳机制:所谓的心跳机制就是每隔一段时间心跳一次。就是DataNode每隔一段时间会向DataNode汇报信息,如果某个块出现了问题 NameNode通过汇报的信息检测到某个块的副本集的数量小于配置的数量,就会通知其它保存此Block副本集的DataNode向别的机器复制Block。如果DataNode很长时间没有汇报,NameNode就会认为此DataNode宕机。
RPC(Remote Procedure Call)
RPC——远程过程调用协议,它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议。RPC协议假定某些传输协议的存在,如TCP或UDP,为通信程序之间携带信息数据。在OSI网络通信模型中,RPC跨越了传输层和应用层。RPC使得开发包括网络分布式多程序在内的应用程序更加容易。一句话概括就是不同进程之间的方法调用。RPC采用客户机/服务器模式。请求程序就是一个客户机,而服务提供程序就是一个服务器。首先,客户机调用进程发送一个有进程参数的调用信息到服务进程,然后等待应答信息。在服务器端,进程保持睡眠状态直到调用信息的到达为止。当一个调用信息到达,服务器获得进程参数,计算结果,发送答复信息,然后等待下一个调用信息,最后,客户端调用进程接收答复信息,获得进程结果,然后调用执行继续进行。
hadoop的整个体系结构就是构建在RPC之上的(见org.apache.hadoop.ipc)。 RPC的底层也是socket实现的,RPC的实现原理就是定义一个协议接口,协议接口中有唯一的versionID以及服务器端要执行的方法,由服务器端程序类实现此接口,客户端程序使用动态代理对此接口进行增强便可获得服务器端的代理对象,利用代理对象调用协议接口中的方法,从而和服务器端进行通讯。示例如下: (1)自定义一个接口Bizable(由Server端进行实现)
package liuxun.test.hadoop.rpc;
public interface Bizable
public static final long versionID = 1000000L;
public String sayHello(String name);
package liuxun.test.hadoop.rpc;
import java.io.IOException;
import org.apache.hadoop.HadoopIllegalArgumentException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.ipc.RPC;
import org.apache.hadoop.ipc.RPC.Server;
public class RPCServer implements Bizable
public String sayHello(String name)
return "hello " + name;
public static void main(String[] args) throws Exception
Configuration conf = new Configuration();
Server server = new RPC.Builder(conf).setProtocol(Bizable.class).setInstance(new RPCServer()).setBindAddress("192.168.0.3")
.setPort(9988).build();
server.start();
package liuxun.test.hadoop.rpc;
import java.io.IOException;
import java.net.InetSocketAddress;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.ipc.RPC;
public class RPCClient
public static void main(String[] args) throws Exception
Bizable proxy = RPC.getProxy(Bizable.class, 1112222L, new InetSocketAddress("192.168.0.3", 9988),
new Configuration());
String result = proxy.sayHello("hadoop"); //$NON-NLS-1$
System.out.println(result);
RPC.stopProxy(proxy);
Java程序操作HDFS
程序上传时容易出现的异常rg.apache.hadoop.security.AccessControlException: Permission denied: user=liuxun, access=WRITE, inode="/":root:supergroup:drwxr-xr-x
解决方案:伪装成root
fs = FileSystem.get(new URI("hdfs://hadoop0:9000"), new Configuration(),"root");
package liuxun.test.hadoop.hdfs;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.URI;
import java.net.URISyntaxException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.junit.Before;
import org.junit.Test;
public class HDFSDemo
FileSystem fs = null;
@Before
public void init() throws Exception
// 首先创建FileSystem的实现类(工具类)
fs = FileSystem.get(new URI("hdfs://hadoop0:9000"), new Configuration(),"root");
@Test
public void testUpload() throws Exception
// 读取本地系统的文件,返回输入流
InputStream in = new FileInputStream("/Users/liuxun/Desktop/Eclipse.zip");
// 在HDFS上创建一个文件,返回输出流
OutputStream out = fs.create(new Path("/testEclipse"));
// 输入——>输出
IOUtils.copyBytes(in, out, 4096, true);
@Test
public void testDownload() throws Exception //最简洁的下载方式
fs.copyToLocalFile(new Path("/log.log"), new Path("/Users/liuxun/Downloads/log.txt"));
@Test
public void testMkdir() throws Exception
boolean flag = fs.mkdirs(new Path("/aaa/bbb/ccc"));
System.out.println(flag);
@Test
public void testDelete() throws Exception
// 第二个参数recursive boolean 表示是否递归删除所有子文件/文件夹
boolean flag = fs.delete(new Path("/aaa/bbb"), true);
System.out.println(flag);
public static void main(String[] args) throws Exception
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop0:9000"), new Configuration());
InputStream in = fs.open(new Path("/words"));
OutputStream out = new FileOutputStream("/Users/liuxun/Downloads/t.txt");
IOUtils.copyBytes(in, out , 4096,true);
断点调试分析HDFS
调试技巧 Eclipse断点快捷键:(command+t 查看当前类的继承关系 command+o查看当前类中的方法 shift+command+t 查找类)放行到下一个断点F8 跳进方法F5 单行执行F6 跳出方法F7
在断点调试时,如果一个方法有多个方法的返回值作为参数,需要多次F5跳进去,F7跳出来,反复执行方可进入到主方法。 源码分析总结: FileSystem.get --> 通过反射实例化了一个DistributedFileSystem --> new DFSCilent()把他作为自己的成员变量
在DFSClient构造方法里面,调用了createNamenode,使用了RPC机制,得到了一个NameNode的代理对象,就可以和NameNode进行通信了
FileSystem --> DistributedFileSystem --> DFSClient --> NameNode的代理
上传文件时的顺序图如下:

HDFS写过程
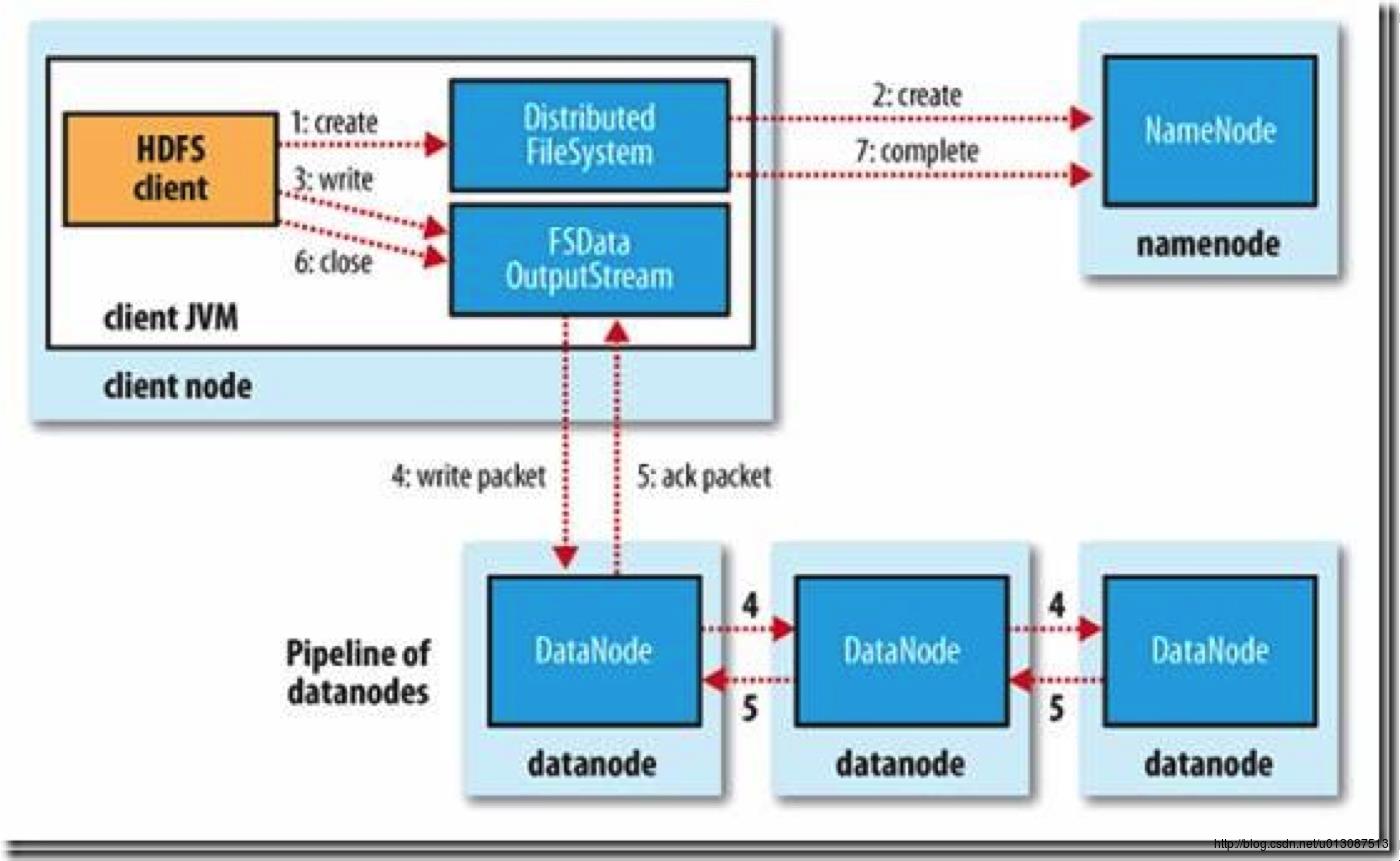
1.初始化FileSystem,客户端调用create()来创建文件
2.FileSystem用RPC调用元数据节点,在文件系统的命名空间中创建一个新的文件,元数据节点首先确定文件原来不存在,并且客户端有创建文件的权限,然后创建新文件。
3.FileSystem返回DFSOutputStream,客户端用于写数据,客户端开始写入数据。
4.DFSOutputStream将数据分成块,写入data queue。data queue由Data Streamer读取,并通知元数据节点分配数据节点,用来存储数据块(每块默认复制3块)。分配的数据节点放在一个pipeline里。Data Streamer将数据块写入pipeline中的第一个数据节点。第一个数据节点将数据块发送给第二个数据节点。第二个数据节点将数据发送给第三个数据节点。
5.DFSOutputStream为发出去的数据块保存了ack queue,等待pipeline中的数据节点告知数据已经写入成功。
6.当客户端结束写入数据,则调用stream的close函数。此操作将所有的数据块写入pipeline中的数据节点,并等待ack queue返回成功。最后通知元数据节点写入完毕。
7.如果数据节点在写入的过程中失败,关闭pipeline,将ack queue中的数据块放入data queue的开始,当前的数据块在已经写入的数据节点中被元数据节点赋予新的标示,则错误节点重启后能够察觉其数据块是过时的,会被删除。失败的数据节点从pipeline中移除,另外的数据块则写入pipeline中的另外两个数据节点。元数据节点则被通知此数据块是复制块数不足,将来会再创建第三份备份。
HDFS读过程

1.初始化FileSystem,然后客户端(client)用FileSystem的open()函数打开文件
2.FileSystem用RPC调用元数据节点,得到文件的数据块信息,对于每一个数据块,元数据节点返回保存数据块的数据节点的地址。
3.FileSystem返回FSDataInputStream给客户端,用来读取数据,客户端调用stream的read()函数开始读取数据。
4.DFSInputStream连接保存此文件第一个数据块的最近的数据节点,data从数据节点读到客户端(client)
5.当此数据块读取完毕时,DFSInputStream关闭和此数据节点的连接,然后连接此文件下一个数据块的最近的数据节点。
6.当客户端读取完毕数据的时候,调用FSDataInputStream的close函数。
7.在读取数据的过程中,如果客户端在与数据节点通信出现错误,则尝试连接包含此数据块的下一个数据节点。
8.失败的数据节点将被记录,以后不再连接。
以上是关于Hadoop详解——HDFS的命令,执行过程,Java接口,原理详解。RPC机制的主要内容,如果未能解决你的问题,请参考以下文章