hadoop详解HDFS Federation(联邦)详解及优劣势分析
Posted 知否Tech
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hadoop详解HDFS Federation(联邦)详解及优劣势分析相关的知识,希望对你有一定的参考价值。
本文概述了HDFS联邦及优势和局限性分析。
背景
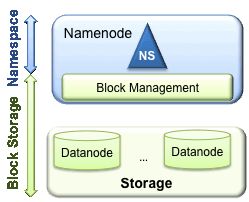
HDFS有两个主要层:
命名空间(namespace)
由目录,文件和块组成。
它支持所有与名称空间相关的文件系统操作,例如创建,删除,修改和列出文件和目录。
块存储服务( Block Storage Service),包括两个部分:
块管理(在Namenode中执行)
通过处理注册和定期心跳来提供Datanode群集成员身份。
处理块报告并维护块的位置。
支持与块相关的操作,例如创建,删除,修改和获取块位置。
管理副本放置,针对未完全复制的块进行块复制,并删除过度复制的块。
存储-由Datanodes通过在本地文件系统上存储块并允许读/写访问来提供。
单组Namenode的局限性:
扩展性:Namenode内存使用和元数据量正相关。180GB堆内存配置下,元数据量红线约为7亿,而随着集群规模和业务的发展,即使经过小文件合并与数据压缩,仍然无法阻止元数据量逐渐接近红线。
可用性:随着元数据量越来越接近7亿,CMS GC频率也越来越高,期间也曾发生过一次在CMS GC过程中由于大文件“get Block location”并发过高导致的promotion fail。
性能:随着集群规模增长,Namenode响应的RPC QPS也在逐渐提高。越来越高并发的读写,与Namenode的粗粒度元数据锁,使Namenode RPC响应延迟和平均RPC队列长度都在慢慢提高。
隔离性:由于Namenode没有隔离性设计,单一对Namenode负载过高的应用,会影响到整个集群的服务能力。
先前的HDFS体系结构仅允许整个集群使用单个名称空间。在该配置中,单个Namenode管理名称空间。HDFS联邦会通过向HDFS添加对多个Namenode /命名空间的支持来解决此限制。
通常情况下,单组Namenode能够满足集群大部分需求,单点故障问题可以通过启用HA解决,单组Namenode包含一主一备两个Namenode,通过Zookeeper保障及控制Failover,而Zookeeper本身具有高可用特性,好像完全不用担心单点故障造成集群不可用的问题,一切看起来似乎非常完美。然而,随着集群规模不断的增长,似乎又不是那么完美了。
单组Namenode只允许整个集群有一个活动的Namenode,管理所有的命名空间。随着集群规模的增长,在1000个节点以上的大型Hadoop集群中,单组Namenode的局限性越发的明显,主要表现在以下几个方面:
既然单组Namenode存在上述局限性,那么为什么要通过Federation的方式横向拓展Namenode,纵向拓展Namenode为什么不行?不选择纵向拓展Namenode的原因主要体现在以下三个方面:
启动时间长:Namenode启动需要将元数据加载到内存中,具有128 GB Java Heap的Namenode启动一次大概需要40分钟到1个小时,那512GB呢?
调试困难:对大JVM Heap进行调试比较困难,优化Namenode的内存使用性价比比较低。
集群易宕机:Namenode在Full GC时,如果发生错误将会导致整个集群宕机。
hadoop2.x
增加了Federation的概念
为什么要引入Federation
采用Federation的最主要的原因是简单,Federation能够快速的解决大部分单Namenode的问题。
Federation是简单鲁棒的设计,由于联邦中各个Namenode之间是相互独立的。Federation整个核心设实现大概用了3.5个月。大部分改变是在Datanode、Config和Tools,而Namenode本身的改动非常少,这样Namenode的原先的鲁棒性不会受到影响。比分布式的Namenode简单,虽然这种事先的扩展性比起真正的分布式的Namenode要小些,但是可以迅速满足需求。
Federation良好的向后兼容性,已有的单Namenode的部署配置不需要进行太大的改变就可以继续工作。
多个namenode/namespace
为了水平扩展名称服务,联邦会使用多个独立的Namenodes /命名空间。 在HDFS Federation中的Namenode之间是联盟关系; 他们之间相互独立且不需要相互协调。 HDFS Federation中的Namenode提供了提供了命名空间和块管理功能。HDFS Federation中的datanode被所有的Namenode用作公共存储块的地方。每一个datanode都会向所在集群中所有的Namenode注册,并且会周期性的发送心跳和块信息报告,同时处理来自Namenode的指令。
HDFS2.X当时引入Federation的改进:
当前HDFS只有一个命名空间(Namespace),它使用全部的块。而Federation HDFS中有多个独立的命名空间(Namespace),并且每一个命名空间使用一个块池(block pool)。
当前HDFS中只有一组块。而Federation HDFS中有多组独立的块。块池(block pool)就是属于同一个命名空间的一组块。
当前HDFS由一个Namenode和一组datanode组成。而Federation HDFS由多个Namenode和一组datanode,每一个datanode会为多个块池(block pool)存储块。
1.Block Pool(块池)
所谓Block pool(块池)就是属于单个命名空间的一组block(块)。每一个datanode为所有的block pool存储块。Datanode是一个物理概念,而block pool是一个重新将block划分的逻辑概念。同一个datanode中可以存着属于多个block pool的多个块。Block pool允许一个命名空间在不通知其他命名空间的情况下为一个新的block创建Block ID。同时,一个Namenode失效不会影响其下的datanode为其他Namenode的服务。当datanode与Namenode建立联系并开始会话后自动建立Block pool。每个block都有一个唯一的标识,这个标识我们称之为扩展的块ID(Extended Block ID)= BlockID+BlockID。这个扩展的块ID在HDFS集群之间都是唯一的,这为以后集群归并创造了条件。
Datanode中的数据结构都通过块池ID(BlockPoolID)索引,即datanode中的BlockMap,storage等都通过BPID索引。在HDFS中,所有的更新、回滚都是以Namenode和BlockPool为单元发生的。即同一HDFS Federation中不同的Namenode/BlockPool之间没有什么关系。Hadoop V0.23版本中Block Pool的管理功能依然放在了Namenode中,将来的版本中会将Block Pool的管理功能移动的新的功能节点中。
2.Datanode的改进
在datanode中,对应于每个Namnode都有一条相应的线程。每个datanode会去每一个Namenode注册,并且周期性的给所有的Namenode发送心跳及datanode的使用报告。Datanode还会给Namenode发送其所在的block pool的block report(块报告)。由于有多个Namenode同时存在,因此任何一个Namenode都可以随时动态加入、删除和更新。
3.Federation中的其他方面的改进
提供了工具,对于Namenode的初始化和退役的监控和管理。允许在datanode级别或者block pool级别的负载均衡。Datanode的后台守护进程,为Federation所做的磁盘和目录扫描。提供了显示Namenode的Block pool的使用状态的Web UI。还提供了对全部集群存储使用状态的UI展示。在Web UI中列出了所有的Namenode及其细节,如Namenode-BlockPoolID和存储的使用状态,失去联系的、活的和死的块信息。还有前往各个Namenode Web UI的链接。Datanode退役状态的展示。
4.多命名空间的管理问题
在一个集群中需要唯一的命名空间还是多个命名空间,核心问题命名空间中数据的共享和访问的问题。使用全局唯一的命名空间是解决数据共享和访问的一种方法。在多命名空间下,我们还可以使用Client Side Mount Table方式做到数据共享和访问。
5.Namespace Volume(命名空间卷)
一个Namespace和它的Block Pool合在一起称作Namespace Volume。Namespace Volume是一个独立完整的管理单元。当一个Namenode/Namespace被删除,与之相对应的Block Pool也也被删除。在升级时每一个Namespace Volume也会整体作为一个单元。
6.ClusterID
在HDFS Federation中添加了Cluster ID用来区分集群中的每个节点。当格式化一个Namenode时,这个ClusterID会自动生成或者手动提供。在格式化同一集群中其他Namenode时会用到这个ClusterID。
7.HDFS Federation对老版本的HDFS是兼容的
这种兼容性可以使得已有的Namenode配置不需要任何改变继续工作。
用户可以使用ViewFs创建个性化的名称空间视图。ViewFs类似于某些Unix / Linux系统中的客户端挂载表。
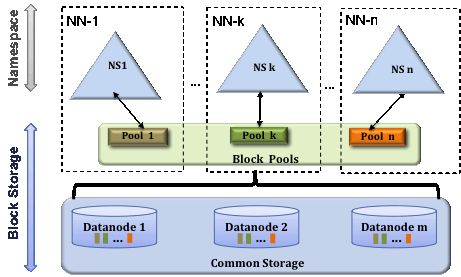
区块池( Block Pool)
块池是属于单个名称空间的一组块的集合。数据节点存储集群中所有块池的块。每个块池都是独立管理的。这允许命名空间为新块生成块ID,而无需与其他命名空间进行协调。名称节点故障不会阻止数据节点为群集中的其他名称节点提供服务。
命名空间及其块池一起称为“命名空间卷”。它是一个独立的管理部门。删除名称节点/名称空间后,将删除数据节点上的相应块池。在群集升级期间,每个名称空间卷都作为一个单元升级。
ClusterID
一个ClusterID用于识别该集群中的所有节点。格式化Namenode时,将提供此标识符或自动生成该标识符。该ID应该用于将其他Namenode格式化为集群。
Federation优势:
命名空间可伸缩性-联邦添加了命名空间水平可伸缩性。大型部署或使用大量小文件的部署可通过允许将更多的Namenode添加到群集中而受益于命名空间扩展。
性能-文件系统吞吐量不受单个Namenode的限制。向群集添加更多Namenodes可以扩展文件系统的读/写吞吐量。
隔离-单个Namenode在多用户环境中不提供隔离。例如,实验性应用程序可能会使Namenode过载,并减慢生产关键型应用程序的速度。通过使用多个Namenode,可以将不同类别的应用程序和用户隔离到不同的名称空间
Federation局限性:
在解决NameNode扩展能力方面,社区虽然提供了Federation,但这个方案有很强的局限性:
HDFS路径Scheme需要变为ViewFs,ViewFs路径和其他Scheme路径互不兼容,比如DistributedFileSystem无法处理ViewFs为Scheme的路径,也就是说如果启用,则需要将Hive meta、ETL脚本、MR/Spark作业中的所有HDFS路径的scheme均改为viewfs。
如果将fs.defaultFS的配置从hdfs://ns1/变为viewfs://ns/,将导致旧代码异常,通过脚本对用户上万个源码文件的分析,常用的HDFS路径风格多样,包括hdfs:///user、hdfs://ns1/user、/user等,如果fs.defaultFS有所更改,hdfs:///user将会由于缺失nameservice变为非法HDFS路径。
ViewFs路径的挂载方式与Linux有所区别:
如果一个路径声明了挂载,那么其同级目录都需要进行挂载,比如/user/path_one挂载到了hdfs://ns1/user/path_one上,那么/user/path_two也需要在配置中声明其挂载到哪个具体的路径上。
如果一个路径声明了挂载,那么其子路径不能再声明挂载,比如/user/path_one挂载到了hdfs://ns1/user/path_one上,那么其子路径也自动并且必须挂载到hdfs://ns1/user/path_one上。
一次路径请求不能跨多个挂载点:
由于HDFS客户端原有的机制,一个DFSClient只对应一个nameservice,所以一次路径处理不能转为多个nameservice的多次RPC。
对于跨挂载点的读操作,只根据挂载配置返回假结果。
对于跨挂载点的rename(move路径)操作,会抛出异常。
Federation架构中,NameNode相互独立,NameNode元数据、DataNode中块文件都没有进行共享,如果要进行拆分,需要使用DistCp,将数据完整的拷贝一份,存储成本较高;数据先被读出再写入三备份的过程,也导致了拷贝效率的低效。
Federation是改造了客户端的解决方案,重度依赖客户端行为。方案中NameNode相互独立,对Federation没有感知。另外HDFS为Scheme的路径,不受Federation挂载点影响,也就是说如果对路径进行了namespace拆分后,如果因为代码中的路径或客户端配置没有及时更新,导致流程数据写入老数据路径,那么请求依然是合法但不符合预期的。
小结:
1、由于单组Namenode在大规模集群中存在较大的局限性,Hadoop开源社区提供了Federation的方案,由多组Namenode在一个集群中共同提供服务,每个Namenode拥有一部分Namespace,工作互相独立,互不影响。
2、在Federation中,Datanode被用作通用的数据块存储设备,每个DataNode要向集群中所有的Namenode注册,且周期性的向所有Namenode发送心跳和块报告,并执行来自所有Namenode的命令。
3、任何事物都存在两面性,Federation在解决单组Namenode的局限性的同时,又带来了新的局限性;

以上是关于hadoop详解HDFS Federation(联邦)详解及优劣势分析的主要内容,如果未能解决你的问题,请参考以下文章
干货:如何通过Federation将Hadoop存储容量提升4倍?