HDFS Federation机制
Posted Android路上的人
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HDFS Federation机制相关的知识,希望对你有一定的参考价值。
前言
在上一篇文章HDFS自定义小文件分析功能中,提到了NameNod内存空间使用过高的问题,紧接着提到了其中一个解决方案,就是HDFS Federation.说来也是挺奇怪的,HDFS的Federation机制其实在Hadoop很早的版本中就就有了,可是从日常使用上来看,了解和真正使用这个功能的人并不多.原因可能在于目前对于绝大多数用户的使用场景,一个NameNode或一对HA的NameNode方式足够应对使用需求了吧.本文将要讲述的主题就是HDFS Federation.这里面还是有很多有用的东西可以讲的.
背景知识
估计有一部分同学可能之前没有听过HDFS Federation的概念,所以接下来我要做一些铺垫的介绍了.先来讲讲Federation这个词,这个单词的中文意思为联邦,联盟.难道HDFS Federation的大致意思是HDFS联盟,多个HDFS集群的意思?其实这里的HDFS Federation更应该是NameNode Federation,这样可能很多人就会看明白了,没错,就是多个NameNode的意思.多个NameNode的情况意味着有多个namespace(命名空间).既然说到了NameNode的命名空间的概念,这里就不得不提现有的HDFS数据管理架构,如下图所示:
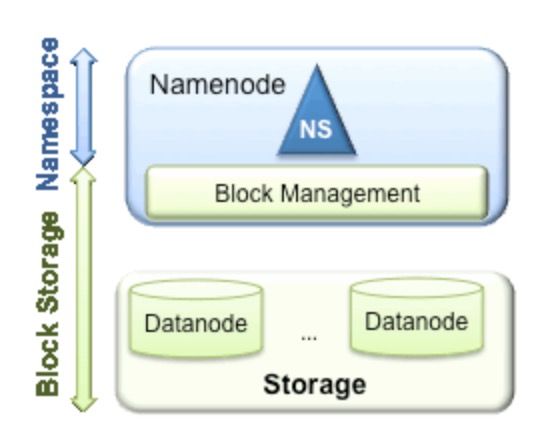
从上图中,我们可以很明显地看出数据管理,数据存储2层分层的结构.也就是说,所有关于存储数据的信息和管理是放在NameNode这边,而真实数据的存储则是在各个DataNode下.而这些隶属于同一个NameNode所管理的数据都是在同一个命名空间下的.而一个namespace对应一个block pool.Block Pool是同一个namespace下的block的集合.当然这是我们最常见的单个namespace的情况,也就是一个NameNode管理集群中所有元数据信息的时候.如果我们遇到了前言部分提到的NameNode内存使用过高的问题,这时候怎么办?元数据空间依然还是在不断增大,一味调高NameNode的jvm大小绝对不是一个持久的办法.这时候就诞生了HDFS Federation的机制.
HDFS Federation的原理结构
HDFS Federation意味着在集群中将会有多个namenode/namespace,这样的方式有什么好处呢?
多namespace的方式可以直接减轻单一NameNode的压力.
一个典型的例子就是上面提到的NameNode内存过高问题,我们完全可以将上面部分大的文件目录移到另外一个NameNode上做管理.更重要的一点在于,这些NameNode是共享集群中所有的DataNode的,它们还是在同一个集群内的.HDFS Federation原理结构图如下:
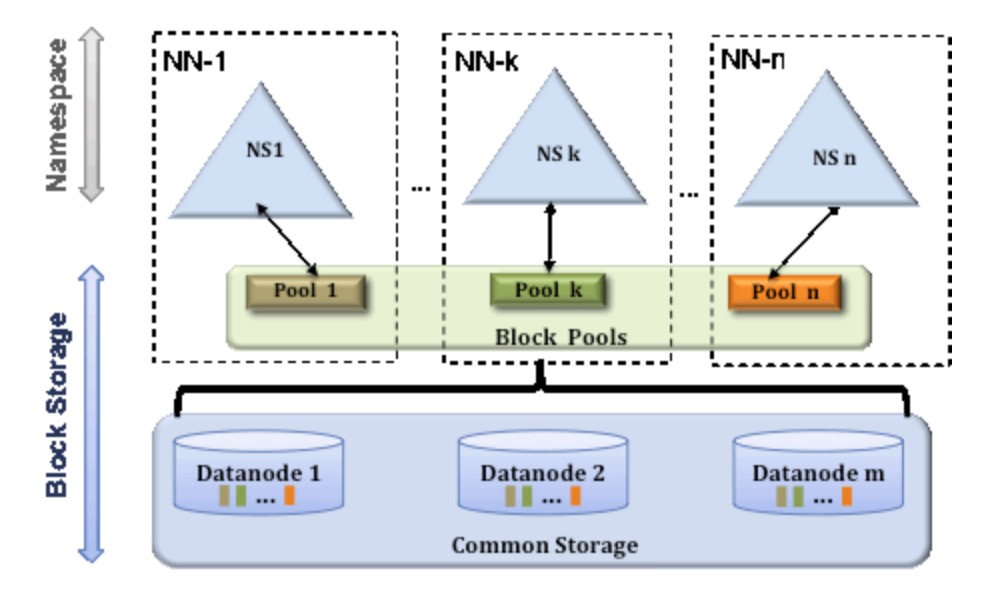
我们可以拿这种图与上一小节的图做对比,我们可以得出这样一个结论:
HDFS Federation是解决NameNode单点问题的水平横向扩展方案.
这时候在DataNode上就不仅仅存储一个Block Pool下的数据了,而是多个(大家可以在DataNode的datadir所在目录里面查看BP-xx.xx.xx.xx打头的目录).
在HDFS Federation的情况下,只有元数据的管理与存放被分隔开了,但真实数据的存储还是共用的,这与viewFs还是不一样的.之前看别的文章在讲述HDFS Federation的时候直接拿viewFs来讲,个人觉得二者还是有些许的不同的,用一句话概况应该这么说:
HDFS的viewFs是namespace完全独立(私人化)的Federation方案,可以这么说,viewFs是Federation的一个简单实现方案.
因为它们不仅仅是namespace独立,而且真实数据的存放也是独立的,也就是多个完全独立的集群.在这点上我们还是有必要做一下区分,否则让人以为HDFS Federation就是viewFs.
HDFS Federation方案的优势
下面我们来聊聊HDFS Federation的一些独特的优势,为什么我们要用这套机制,单个NameNode管理起来不是更加方便吗?下面主要从三个方面来阐述.
第一点,命名空间的扩展.因为随着集群使用时间的加长,HDFS上存放的数据也将会越来越多.这个时候如果还是将所有的数据都往一个NameNode上存放,这个文件系统会显得非常的庞大.这时候我们可以进行横向扩展,把一些大的目录分离出去.使得每个NameNode下的数据看起来更加的精简.
第二点,性能的提升.这个也很好理解.当NameNode所持有的数据量达到了一个非常大规模的量级的时候(比如超过1亿个文件),这个时候NameNode的处理效率可能就会有影响,它可能比较容易的会陷入一个繁忙的状态.而整个集群将会受限于一个单点NameNode的处理效率,从而影响集群整体的吞吐量.这个时候多NameNode机制显然可以减轻很多这部分的压力.
第三点,资源的隔离.这一点考虑的就比较深了.通过多个命名空间,我们可以将关键数据文件目录移到不同的NameNode上,以此不让这些关键数据的读写操作受到其他普通文件读写操作的影响.也就是说这些NameNode将会只处理特定的关键的任务所发来的请求,而屏蔽了其他普通任务的文件读写请求,以此做到了资源的隔离.千万不要小看这一点,当你发现NameNode正在处理某个不良任务的大规模的请求操作导致响应速度极慢时,你一定会非常的懊恼.
HDFS Federation的配置使用
前面说了这么多HDFS Federation的好处,我们当然要知道怎么去用它.HDFS Federation的配置使用并没有想象中的那么复杂.我们以下面的例子为例.
假设目前现有一集群,具体配置信息如下:
NameNode运行模式:非Federation模式,普通HA方式配置,一个Active NameNode,一个Standby NameNode.
目标:在现有基础上添加一个新的NameNode,也就是扩展一个namespace.
首先我们要想好新定义的NameNode的nameservce名,这里我们直接叫testservice.为了测试的方便,我们直接添加非HA方式的NameNode进来.
第一步,我们要更改hdfs-site.xml文件的配置,在nameservice下新增testcluster.
<property>
<name>dfs.nameservices</name>
<value>origincluster,testcluster</value>
</property>然后补充testcluster对应的NameNode ip,因为是非HA模式,所以配置十分的简单.
<property>
<name>dfs.namenode.rpc-address.testcluster</name>
<value>xx.xx.xx.81:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.testcluster</name>
<value>xx.xx.xx.81:50070</value>
</property>
<property>
<name>dfs.namenode.secondaryhttp-address.testcluster</name>
<value>xx.xx.xx.83:50070</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.testcluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>配置就主要改这么多,然后下面是新的NameNode的format操作.因为上面我们写的是81这台机器,所以我们接下来要在81的机器上执行.在操作时,一定要注意以下一点:
一定要指定与原集群相同的clusterId来format新的NameNode,代表新的NameNode隶属于原集群.
操作命令如下:
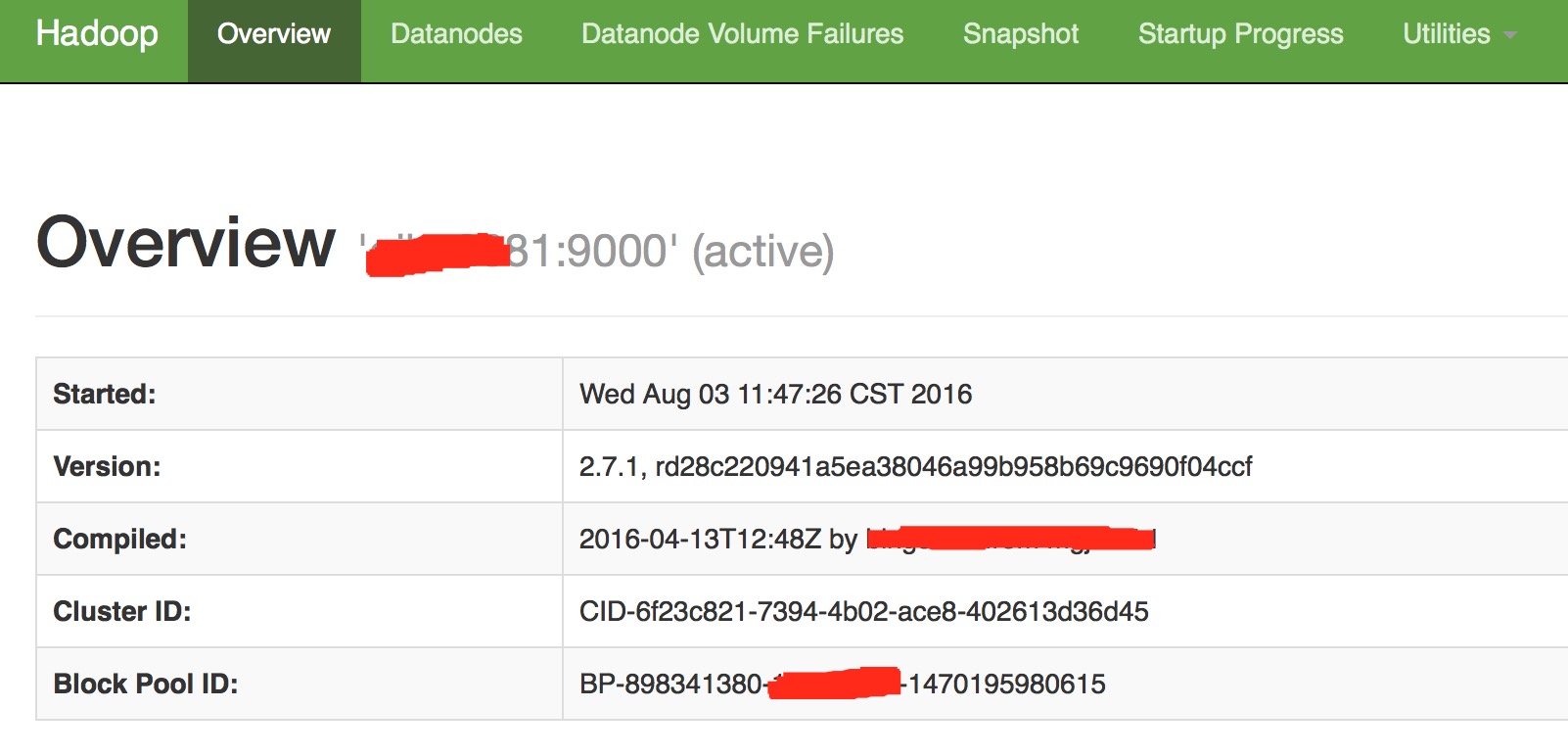
[hdfs]$ $HADOOP_PREFIX/bin/hdfs namenode -format -clusterId <cluster_id>format操作确认成功之后,就可以直接启动NameNode了.我们可以查看50070端口的web页面来看其中NameNode的信息.
新的非HA模式的81NameNode:
我们再看原集群的NameNode,重点关注这里的Cluster Id.
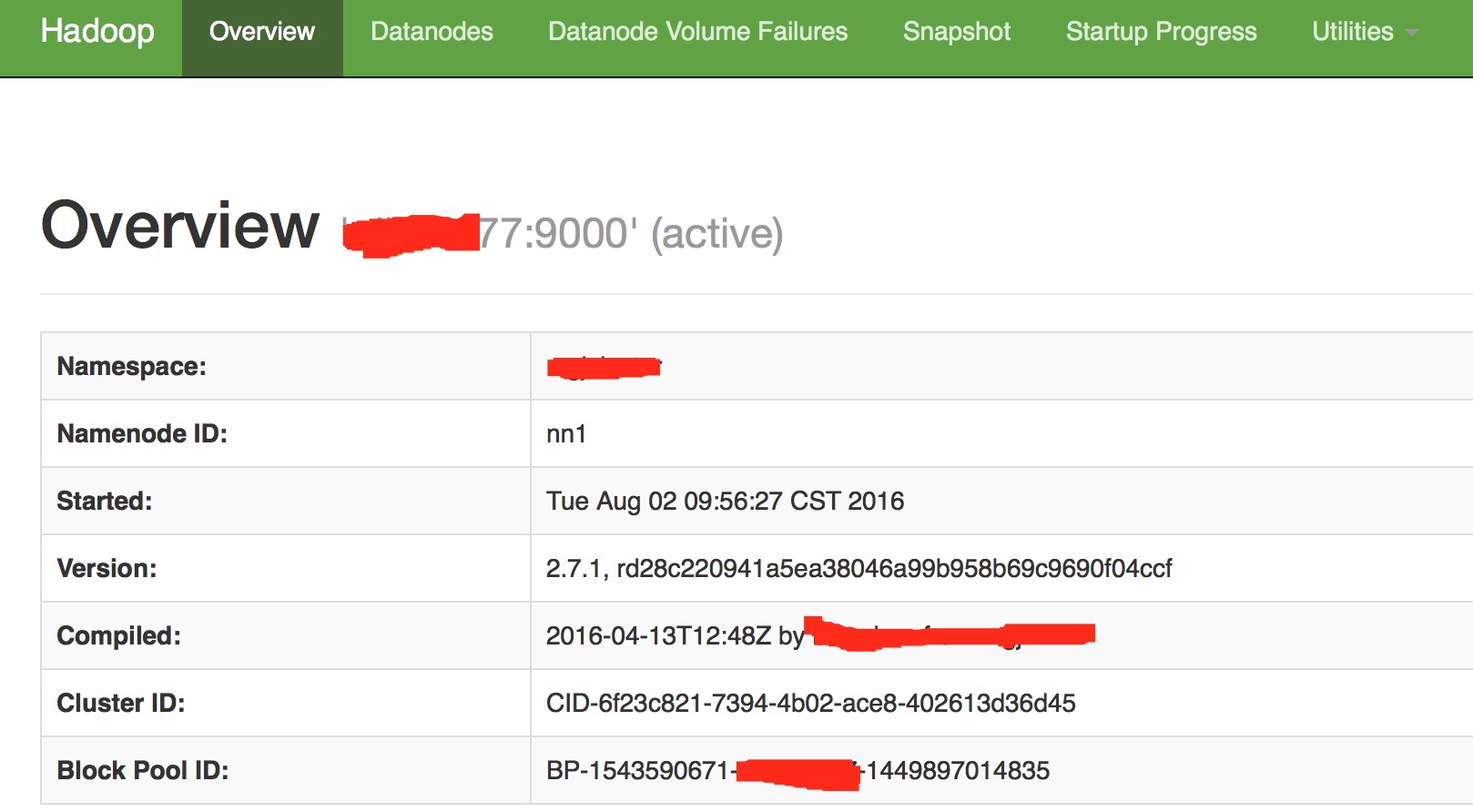
可以看到,它们的cluster Id确实是一样的,这意味着HDFS Federation的方案已经要实现一大半了,就差后面DataNode的注册操作了.
在所有的DataNode节点同步以上修改过的hdfs-site.xml配置,逐个重启DataNode即可.注册成功后,在DataNode的datadir数据存储目录下将会多出一个block pool的存储目录.如下图:

一个block pool对应一个namespace.DataNode通过建立多个block pool目录的方式实现了DataNode的存储共享.如果重启DataNode的时候,你发现DataNode启动失败了,并出现如下所示的错误
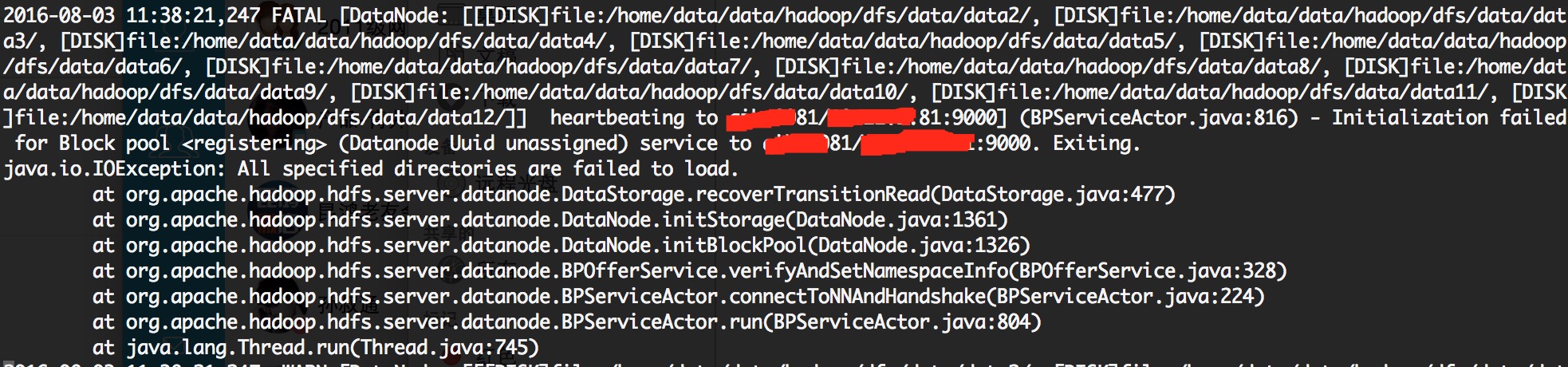
这个时候再次确认新的NameNode是否是用原集群的cluster format的.Cluster Id不匹配就会导致DataNode启动出现上图所示的错误.但是有的时候我们并不想让所有的DataNode都添加到每个NameNode,比如对于用于冷数据存储的机器我只想把它加入到77所在的原NameNode上.这个时候HDFS能支持吗?答案是确定的.添加如下配置表明目标注册的nameservice.
<property>
<name>dfs.internal.nameservices</name>
<value>origincluster</value>
</property>如果你没有配置此项,此项会采用dfs.nameservices的值,也就是向当前所有nameservice所表示的NameNode进行注册.在这里,不得不佩服HDFS设计的灵活性.
以上操作都执行完毕了之后,你就可以通过2个nameservice访问各自的文件目录了.每个nameservice代表着独立的存储空间.如果出现了unknowhost这类的异常,再确认以下此配置项是否已加上.
<property>
<name>dfs.client.failover.proxy.provider.testcluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>如果想添加一个新的HA模式的NameNode完全同理,唯一需要注意的是用同一个cluster Id做format操作.
对于HDFS Federation个人的看法
在文章的末尾,最后说说我个人的几点意见和看法:
- 如果各位有打算要新建Hadoop集群的时候,最好使用同一个cluster Id来format,以后要归并入同一个集群的话,也会很容易.当然这是为了长远考虑.
- 不要轻易以为管理多套独立的集群与HDFS Federation模式下的集群差不了多少,这个是错误的.因为在HDFS Federation下,可以统一进行节点的下线,上线,Balance等操作,完全就是在一个集群内的运维操作,而对于多套独立的集群呢,这意味着重复的多次运维操作.
- 对于HDFS Federation引入的多nameservice的问题,会让客户端程序维护多个nameservice,以及这些对应namespace所存储的具体文件目录,namespace多了,这个问题会显得比较麻烦,一个优化的做法是用viewFs来解决,在客户端配置上增加一个mount table.让客户端访问的是一个逻辑意义上的file system,无须更改目标指向的file system.这样可以同时应用HDFS Federation和viewFs的优势,无疑是一个更好的选择.
参考资料
1.http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-hdfs/Federation.html
以上是关于HDFS Federation机制的主要内容,如果未能解决你的问题,请参考以下文章