通过索引优化sql
Posted ericz2j
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了通过索引优化sql相关的知识,希望对你有一定的参考价值。
sql语句的优化最重要的一点就是要合理使用索引,下面介绍一下使用索引的一些原则:
1.最左前缀匹配原则。
mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配。所以要尽量把“=”条件放在前面,把范围查询(>、<、between、like)条件放在最后。
例:
不会用到b的索引:
where a=1 and c>0 and b=2
会用到b的索引:
where a=1 and b=2 and c>0
2.尽量选择区分度高的列作为索引。
区分度的公式是count(distinct col)/count(*),表示字段不重复的比例,比例越大我们扫描的记录数越少。
3.当取出的数据超过全表数据的20%时,不会使用索引。
4.使用like时赢注意一些规则
例:
不使用索引:
like ‘%L%‘
like ‘%L‘
使用索引:
like ‘L%‘
5.尽量将or 转换为 union all
例:
不使用索引:
select * from user where name=‘a‘ or age=‘20‘
使用索引:
select * from user where name=‘a‘ union all select * from user where age=‘20‘
6.字段加函数不会使用索引。所以尽量把函数放在数值上.
例:
不使用索引:
where truncate(price) = 1
使用索引:
where price > 1 and price < 2
7.如果使用数字作为字符,则数字需要加引号,否则mysql会自动在列上加数据类型转换函数。
例:
不使用索引
where mobile=18534874321
使用索引
where mobile=’18534874321’
8.字段加运算符不会使用索引。所以尽量把运算放在数值上
例:
不使用索引:
SELECT ACCOUNT_NAME, AMOUNT FROM TRANSACTION WHERE AMOUNT + 3000 >5000;
使用索引:
SELECT ACCOUNT_NAME, AMOUNT FROM TRANSACTION WHERE AMOUNT > 2000 ;
9.使用组合索引时,必须要包括第一个列。
例:
alter table test add index(a,b,c):
不使用索引:
where b=1,c=2
where b=1
where c=2
使用索引:
where a=1,b=1,c=2
where a=1,b=1
where a=1,c=2
10.尽量避免使用is null或is not null
例:
不使用索引:
SELECT … FROM DEPARTMENT WHERE DEPT_CODE IS NOT NULL;
使用索引:
SELECT … FROM DEPARTMENT WHERE DEPT_CODE >0;
11.不等于(!=)不会使用索引
不使用索引:
SELECT ACCOUNT_NAME FROM TRANSACTION WHERE AMOUNT !=0;
使用索引:
SELECT ACCOUNT_NAME FROM TRANSACTION WHERE AMOUNT >0;
12.ORDER BY 子句只在以下的条件下使用索引:
ORDER BY中所有的列必须包含在相同的索引中并保持在索引中的排列顺序.
ORDER BY中不能既有ASC也有DESC
例如:
alter table t1 add index(a,b);
alter table t1 add index(c);
不使用索引:
select * from t1 order by a,c; 不在一个索引中
select * from t1 order by b; 没有出现组合索引的第一列
select * from t1 order by a asc, b desc; 混合ASC和DESC
select * from t1 where a=1 order by c; where和order by用的不是同一个索引,where使用索引,order by不使用。
使用索引:
select * from t1 order by a,b;
select * from t1 order where a=1 order by b;
select * from t1 order where a=1 order by a,b;
select * from t1 order by a desc, b desc;
select * from t1 where c=1 order by c;
13.索引不是越多越好。mysql需要资源来维护索引,任何数据的变更(增删改)都会连带修改索引的值。所以,需要平衡考虑索引带来的查询加速和增删改减速。
其他注意事项:
1.尽量避免使用select *
2.尽量使用表连接(join)代替子查询select * from t1 where a in (select b from t2)
3.性能方面,表连接 > (not) exists > (not) in
1)用exists代替in
低效:
SELECT *
FROM EMP
WHERE EMPNO > 0
AND DEPTNO IN (SELECT DEPTNO
FROM DEPT
WHERE LOC = ‘MELB’)
高效:
SELECT *
FROM EMP
WHERE EMPNO > 0
AND EXISTS (SELECT ‘X’
FROM DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
AND LOC = ‘MELB’)
2)用not exists代替not in
低效:
SELECT …
FROM EMP
WHERE DEPT_NO NOT IN (SELECT DEPT_NO
FROM DEPT
WHERE DEPT_CAT=’A’);
高效:
SELECT ….
FROM EMP E
WHERE NOT EXISTS (SELECT ‘X’
FROM DEPT D
WHERE D.DEPT_NO = E.DEPT_NO
AND DEPT_CAT = ‘A’);
3)用表连接代替exists
exits:
SELECT ENAME
FROM EMP E
WHERE EXISTS (SELECT ‘X’
FROM DEPT
WHERE DEPT_NO = E.DEPT_NO
AND DEPT_CAT = ‘A’);
表连接:
SELECT ENAME
FROM DEPT D,EMP E
WHERE E.DEPT_NO = D.DEPT_NO
AND DEPT_CAT = ‘A’ ;
14.清除不必要的排序
低效:
select count(*) from (select * from user where id > 40 order by id);
高效:
select count(*) from (select * from user where id > 40);
15.having -> where
避免使用HAVING子句, HAVING 只会在检索出所有记录之后才对结果集进行过滤. 这个处理需要排序,总计等操作. 如果能通过WHERE子句限制记录的数目,那就能减少这方面的开销.
低效:
select * from user group by id having id > 40;
高效:
select * from user where id > 40 group by id;
16.除非确实需要去掉重复的行,否则尽量使用union all而不是union。因为union会自带distinct操作,代价很大.
使用explain查看sql性能
1.explain用法:在select之前加上explain即可。
例如:
explain select * from test;
注意:explain并不会真正运行语句,而是只返回执行计划。
怎么看执行计划?一个简单的优化原则:令sql读取尽可能少的行。
2.实战案例1:
问题语句运行超过5s:
SELECT `branch`.`id`, `branch`.`name`, `branch`.`registered_time`, `branch_region`.`region_id`, `user`.`username`, `user`.`mobile`, count(o.order_id) as order_num
FROM (`branch`)
LEFT JOIN `user` ON `user`.`branch_id` = `branch`.`id`
LEFT JOIN `branch_role` ON `branch_role`.`id` = `user`.`role_id`
LEFT JOIN `branch_region` ON `branch_region`.`branch_id` = `branch_role`.`branch_id`
LEFT JOIN `orders` o ON `branch`.`id` = `o`.`supplier_id`
WHERE branch.id NOT IN (select supplier_id from signing where seller_id=6683 and status < 6)
AND `branch`.`group` = ‘SUPPLIER‘
AND `branch_role`.`flag` = ‘ADMINISTRATOR‘
AND `branch`.`status` = ‘NORMAL‘
GROUP BY `branch`.`id`
ORDER BY `branch`.`registered_time` desc
LIMIT 20;
使用explain查看执行计划:
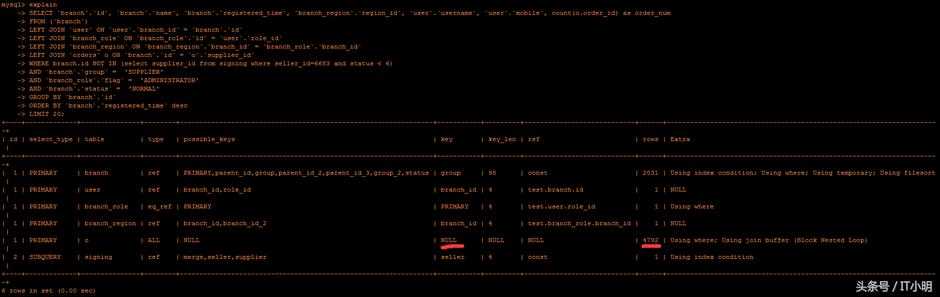
根据“读取尽可能少的数据”的原则,发现读取行数最多的步骤读取了4792行。进而发现这个步骤没有用到索引(NULL)。而这个没有用索引的表是orders的supplier_id列。
加索引试试看:
alter table orders add index(supplier_id);
再次使用explain查看执行计划:
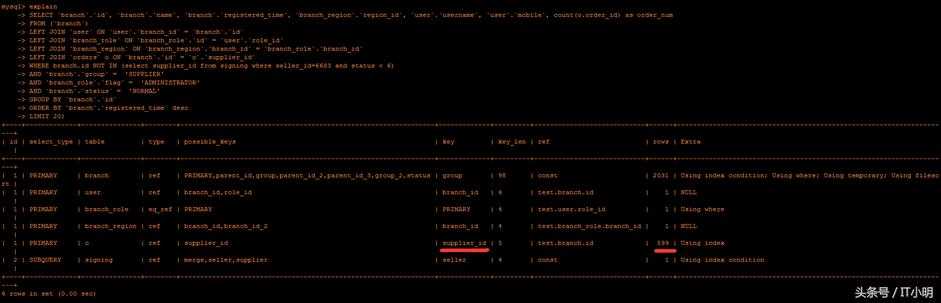
可以看到这个步骤使用了索引,读取的行数减少到了599行。
实际执行一下,秒出。
3.explain执行计划各个字段的意义:
1)id:语句的执行顺序,倒序执行
2)select_type:主要有以下几个类型:
lsimple:表示简单的select,没有union和子查询
lprimary:最外层的select。在有子查询的语句中,最外面的select查询就是primary
lunion:union语句的第二个或者说是后面那一个
lunion result:union的结果
lsubquery: 子查询中的第一个 select
以上是关于通过索引优化sql的主要内容,如果未能解决你的问题,请参考以下文章