sql优化---- 索引
Posted 一颗温柔的小番茄
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了sql优化---- 索引相关的知识,希望对你有一定的参考价值。
---
title: 不懂SQL优化?那你就OUT了(二)
-- 索引(一)
date: 2018-10-27
categories: 数据库优化
---


要想让一个较慢的select ... where语句执行效率更快,我们应首先检查是否能增加一个索引。不同表之间的引用通常通过索引来完成。你可以使用explain语句(上一篇已介绍)来确定select语句是否使用索引,使用了哪些索引。
索引
索引是一种特殊的文件,它们包含着对数据表里所有记录的引用指针。
它是对数据库表中一列或多列的值进行排序的一种结构。
简单理解就是:
数据库索引好比是一本书前面的目录,能够加快数据库的查询速度.
数据库索引就是为了提高表的搜索效率而对某些字段中的值建立的目录。
为什么要使用索引
创建索引可以大大提高系统的性能
1. 通过创建唯一索引,可以保证数据库表中每一行数据的唯一性。
2. 可以大大加快数据的检索速度,这也是创建索引的最主要的原因。
3. 可以加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。
4. 显著减少查询中分组和排序的时间。
5. 通过使用索引,可以在查询的过程中,使用优化器,提高系统的性能
索引的分类
索引的类型大体上可分为:
1. 普通索引
2. 唯一索引
3. 主键索引
4. 全文索引。
普通索引
普通索引有分为:单列索引 和 多列索引
1. 单列索引:就是一个索引只包含单个列,一个表可以有多个单列索引。
2. 多列索引:也称组合索引,即一个索引包含多个列。
创建普通索引的语法
查看某张表的索引:show index from 表名;
创建普通索引:
1. create index 索引名 on 表名(表中加索引的列名)
2. alter table 表名 add index 索引名 (表中加索引的列)
3. create table 表名(
列名 列的数据类型 列的约束,
index 索引名(表中加索引的列)
)
创建多列索引:
1. create index 索引名 on 表名(表中加索引的列1,表中加索引的列2,...)
2. alter table 表名 add index 索引名 (表中加索引的列1,表中加索引的列2,...)
3. create table 表名(
列名 列的数据类型 列的约束,
index 索引名(表中加索引的列1,表中加索引的列2,...)
)
删除某张表的索引:
drop index 索引名 ON 表名;
唯一索引
它与前面的普通索引类似,不同的就是:索引列的值必须唯一,但允许有空值。
如果是组合索引,则列值的组合必须唯一
创建唯一索引语法
与前面的普通索引类似,不同的就是:索引列的值必须唯一,但允许有空值。
如果是组合索引,则列值的组合必须唯一.
语法:
1. create unique index 索引名 on 表名(表中加索引的列)
2. alter table 表名 add unique index 索引名 (表中加索引的列)
3. create table 表名(
列名 列的数据类型 列的约束,
unique index 索引名(表中加索引的列)
)
主键索引
它是一种特殊的唯一索引,不允许有空值。
创建主键索引的语法
语法:
1. alter table 表名 add primary key(列名)
2. create table 表名(
列名1 列的数据类型 列的约束(primary key),
列名2 列的数据类型 列的约束
)
全文索引
现在的互联网上,很多网站都提供了全文搜索(全文检索)功能,浏览者可以通过输入关键字或者是短语来搜索特定的资料。
通常的做法是通过 select 查询的 like 语句来进行搜索,这一办法存在搜索不够精确、以及效率非常低下的缺点。
mysql 提供了一个全文索引功能,也就是把字段设置上fullText索引属性,然后通过select的match against语句进行查找。
mysql 支持全文索引和搜索功能,但是 fullText 索引仅能用于 myisam 引擎(数据库引擎以后在介绍)的表。
myisam 引擎支持全文检索(full text index),查询效率高。但是有局限,不支持事务和外键。
创建全文索引的语法
语法:
1.Create fulltext index 索引名 on 表名(表中加索引的列)
2.alter table 表名 add fulltext index 索引名(表中加索引的列)
3. create table 表名(
列名 列的数据类型 列的约束,
fulltext 索引名(表中加索引的列)
)
案列
首先创建一个测试表: t_studentInfo
create table t_studentInfo(
-- 学生编号
studentId int primary key auto_increment, -- 创建了唯一索引(主键)
-- 学生姓名
studentName varchar(20)
-- 学生年龄
studentAge int,
-- 家庭住址
studentAddress varchar(255)
)engine=myisam,default charset=utf8
使用 存储过程添加 1000万条数据
DELIMITER $
CREATE PROCEDURE pro_datas()
BEGIN
DECLARE num INT;
DECLARE age INT;
DECLARE result INT;
DECLARE address VARCHAR(25);
SET num:=1;
WHILE num <= 10000000 DO
SET age:= 18+CEIL(RAND()*10);
SET result:=CEIL(RAND()*100);
IF result < 25 THEN
SET address:="成都市";
ELSEIF result<50 THEN
SET address:="绵阳市";
ELSEIF result<75 THEN
SET address:="昆明市";
ELSE
SET address:="贵阳市" ;
END IF;
INSERT INTO t_studentInfo(studentName,studentAge,studentAddress) VALUES(CONCAT(\'学生\',num),age,address);
SET num=num+1;
END WHILE;
END $
在执行
CALL pro_datas();
执行时间:
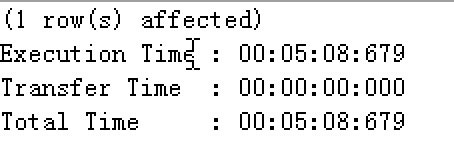

添加1000万条(在myisam引擎)数据花费了大约6分钟。
执行sql :
select * from t_studentInfo where studentName="学生1024"
执行结果:
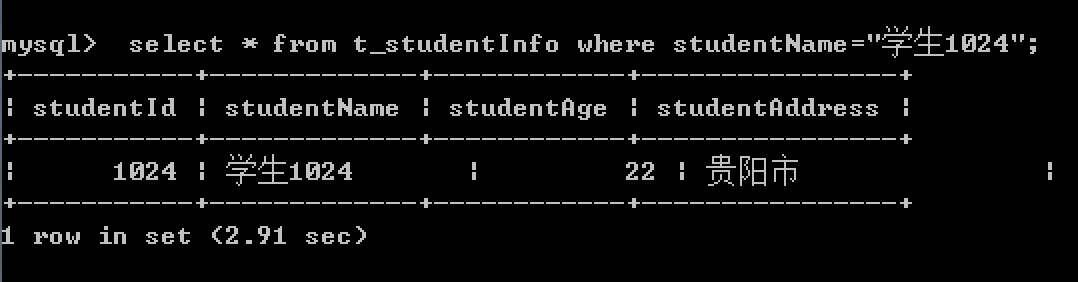

使用explain查看sql语句执行计划
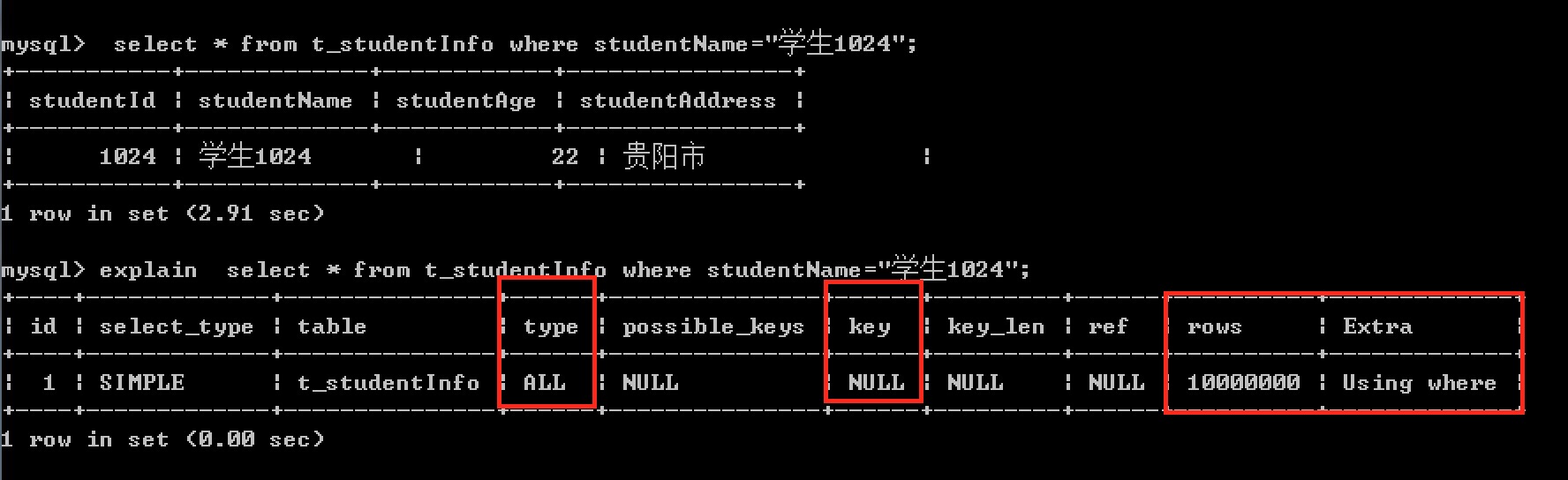

从执行计划中可以看到,该查询未使用索引,而是进行了全表扫描(type=all),并且扫描了1000万条数据,效率低下。
现在为表的学生姓名列添加索引


我们看到添加时间大约4分钟,建索引的过程会全表扫描,逐条建索引,当然慢了。
现在再次执行
select * from t_studentInfo where studentName="学生1024"
执行时间:


发现查询效率快了很多。
查看添加索引后的执行计划
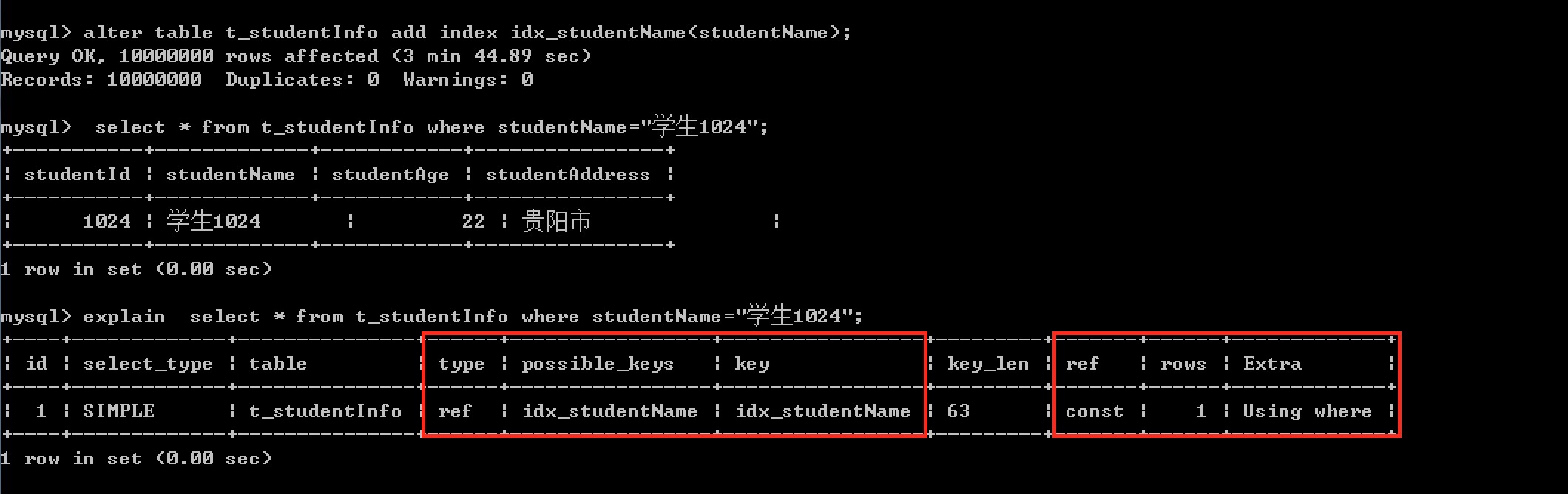

可以从执行计划中看到,此查询使用索引(type=ref),使用了 idx_studentName 索引,并且只扫描了一条数据,效率甚高。
总结
索引的主要作用就是: 加快数据库的查询效率。
以上是关于sql优化---- 索引的主要内容,如果未能解决你的问题,请参考以下文章