kafka基础概念(组件名称作用)
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了kafka基础概念(组件名称作用)相关的知识,希望对你有一定的参考价值。
写介绍kafka的几个重要概念(可以参考之前的博文Kafka的简单介绍):Broker:消息中间件处理结点,一个Kafka节点就是一个broker,多个broker可以组成一个Kafka集群;
Topic:一类消息,例如page view日志、click日志等都可以以topic的形式存在,Kafka集群能够同时负责多个topic的分发;
Partition:topic物理上的分组,一个topic可以分为多个partition,每个partition是一个有序的队;
Segment:每个partition又由多个segment file组成;
offset:每个partition都由一系列有序的、不可变的消息组成,这些消息被连续的追加到partition中。partition中的每个消息都有一个连续的序列号叫做offset,用于partition唯一标识一条消息;
message:这个算是kafka文件中最小的存储单位,即是 a commit log。
topic:创建topic名称
partition:分区编号
offset:表示该partition已经消费了多少message
logsize:表示该paritition生产了多少的message
lag:表示有多少条message未被消费
owner:表示消费者
create:表示该partition创建时间
last seen:表示消费状态刷新最新时间
参考链接:
能查看到kafka中生产了,消费了,还剩下多少message中我们用的是kafkaoffsetmonitor这个监控插件Kafka监控工具KafkaOffsetMonitor配置及使用:https://www.cnblogs.com/dadonggg/p/8242682.html
topics是什么?partition是什么?topics是kafka中数据存储的基本单位
写数据,要指定写入哪个topic 读数据,指定从哪个topic去读
我们可以这样简单的理解
topic就类似于数据库中的一张表,可以创建任意多个topic 每一个topic的名字是唯一的
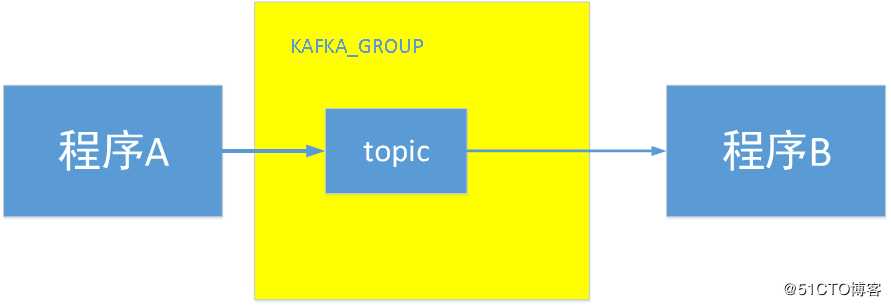
例如:
程序A产生了一类消息,然后把这类消息放在kafka group中 ,这由程序A产生的这个消息就叫一个topic
程序B需要 订阅这个消息,才能成为这个topic的消费者
每个topic的内部都会有一个或多个partitions(分区)
你写入的数据,他其实是写入每一个topic里的其中一个partition,并且当前的数据是有序的写入到paritition中的。
每一个partition内都会维护一个不断增加的ID,每当你写入一个新的数据的时候,这个ID就会增长,这个id就会被称为这个paritition的offset,每个写入partition中的message都会对应一个offset。
不同的partition都会对应他们自己的offset 我们可以利用offset来判断,当前paritition内部的顺序,但是我们不能比较来自不同的两个partition的顺序,这是没有意义的
partition中的数据是有序的,不同partition间的数据丢失了数据的顺序。如果topic有多个partition,消费数据时就不能保证数据的顺序。在需要严格保证消息的消费顺序的场景下,需要将partition数目设为1。
//
每个topic将被分成多个partition(区)
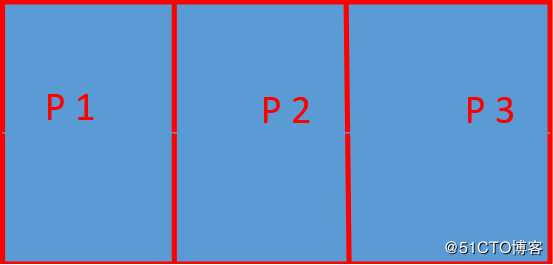
每个topic将被分成多个partition(区),此外kafka还可以配置partitions需要备份的个数(replicas)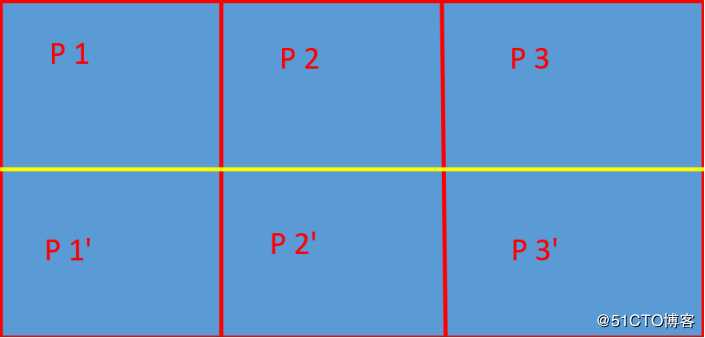
基于replicated方案,那么就意味着需要对多个备份进行调度;每个partition都有一个server为"leader";leader负责所有的读写操作,如果leader失效,那么将会有其他follower来接管(成为新的leader);follower只是单调的和leader跟进,同步消息即可..由此可见作为leader的server承载了全部的请求压力,因此从集群的整体考虑,有多少个partitions就意味着有多少个"leader",kafka会将"leader"均衡的分散在每个实例上,来确保整体的性能稳定.
其中partition leader的位置(host:port)注册在zookeeper中
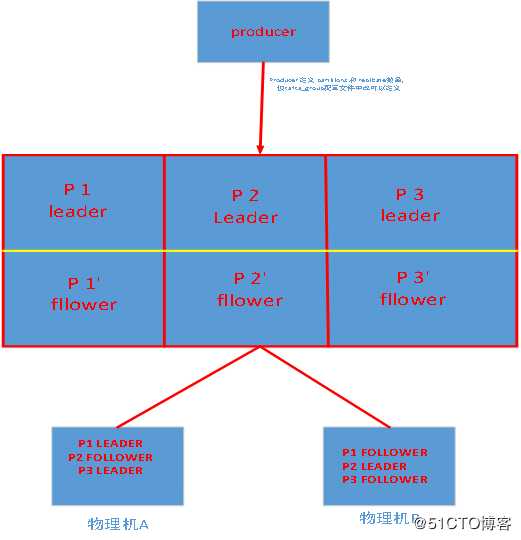
当你讲数据写入kafka中,改数据默认情况下会在kafka中保存2个星期。当然,我们可以去配置的。如果是默认的2个星期,超过2个星期的话,kafka里面的数据就会被无效化。这个时候,该数据对应的offset就没有其他的意义了。
从kafka读取数据后 数据会自动删除吗
不会,kafka中数据的删除跟有没有消费者消费完全无关。数据的删除,只跟kafka broker上面上面的这两个配置有关:
log.retention.hours=48 #数据最多保存48小时
log.retention.bytes=1073741824 #数据最多1G
提示:写入到kafka中的数据,是不可以被改变的。他有一个熟悉就是immutability。也就是说,你没有办法去更改已经写入到kafka中的数据。
如果你想更新一个数据memssage,那你只能重新写入memssage到kafka中,并且这个新的message会有一个新的offset,以区别于之前写入的message。
对于每一个写入kafka中的数据,他们会随机的写入到当前topic中的某一个partition内,有一个例外,你提供一个key给当前的数据,这个时候,你就可以用当前的key去控制当前数据应该传入到哪个partition中。
每一个topic中都可以由多个parititions 这是由你来决定的
以上是关于kafka基础概念(组件名称作用)的主要内容,如果未能解决你的问题,请参考以下文章