kafka系列 -- 基础概念
Posted stillcoolme
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了kafka系列 -- 基础概念相关的知识,希望对你有一定的参考价值。
kafka是一个分布式的、分区化、可复制提交的发布订阅消息系统
传统的消息传递方法包括两种:
- 排队:在队列中,一组用户可以从服务器中读取消息,每条消息都发送给其中一个人。
- 发布-订阅:在这个模型中,消息被广播给所有的用户。
kafka与传统的消息传递技术相比优势之处在于: - 快速:单一的Kafka代理可以处理成千上万的客户端,每秒处理数兆字节的读写操作。
- 可伸缩:在一组机器上对数据进行分区和简化,以支持更大的数据
- 持久:消息是持久性的,并在集群中进行复制,以防止数据丢失。
- 设计:它提供了容错保证和持久性
基本概念
- Topic(话题):Kafka中用于区分不同类别信息的类别名称。由producer指定
- Producer(生产者):将消息发布到Kafka特定的Topic的对象(过程)
- Consumers(消费者):订阅并处理特定的Topic中的消息的对象(过程)
- Broker(Kafka服务集群):已发布的消息保存在一组服务器中,称之为Kafka集群。集群中的每一个服务器都是一个代理(Broker). 消费者可以订阅一个或多个话题,并从Broker拉数据,从而消费这些已发布的消息。
- Partition(分区):Topic物理上的分组,一个topic可以分为多个partition,每个partition是一个有序的队列。partition中的每条消息都会被分配一个有序的id(offset)
- Message:消息,是通信的基本单位,每个producer可以向一个topic(主题)发送一些消息。
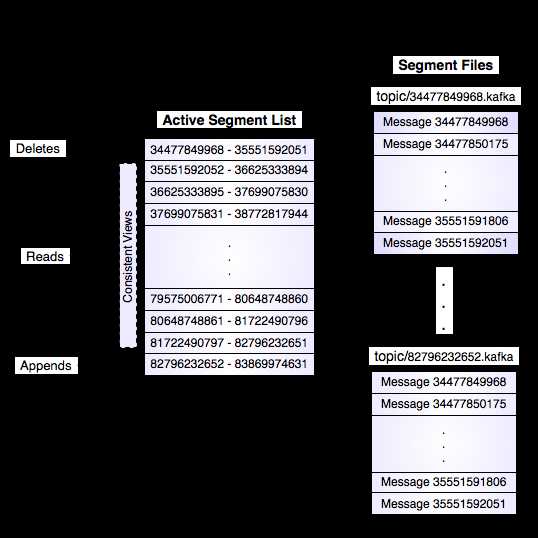
Log(日志)
日志是一个只能增加的,完全按照时间排序的一系列记录。我们可以给日志的末尾添加记录,并且可以从左到右读取日志记录。每一条记录都指定了一个唯一的有一定顺序的日志记录编号。
每个日志文件都是“log entries”序列,每一个log entry包含一个4字节整型数(值为N),其后跟N个字节的消息体。每条消息都有一个当前partition下唯一的64字节的offset,它指明了这条消息的起始位置
这个“log entries”并非由一个文件构成,而是分成多个segment,每个segment名为该segment第一条消息的offset和“.kafka”组成。另外会有一个索引文件,它标明了每个segment下包含的log entry的offset范围。
Topic & Partition
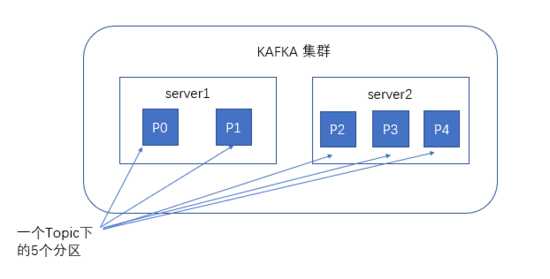
谈到kafka的存储,就不得不提到分区。
创建一个topic时,同时可以指定分区数目,分区数越多,其吞吐量也越大,但是需要的资源也越多,同时也会导致更高的不可用性,kafka在接收到生产者发送的消息之后,会根据均衡策略将消息存储到不同的分区中。
为了使得Kafka的吞吐率可以水平扩展,物理上把topic分成一个或多个partition,每个partition在物理上对应一个文件夹,该文件夹下存储这个partition的所有消息和索引文件。
消息以顺序存储:每一个分区都是一个顺序的、不可变的消息队列, 并且可以持续的添加,,最晚接收的的消息会最后被消费。
分区中的消息都被分配了一个序列号,称之为偏移量(64字节的offset),在每个分区中此偏移量都是唯一的。
因为每条消息都被append到该partition中,是顺序写磁盘,因此效率非常高(经验证,顺序写磁盘效率比随机写内存还要高,这是Kafka高吞吐率的一个很重要的保证)
与生产者的交互
生产者在向kafka集群发送消息的时候,可以通过指定分区来发送到指定的分区中
也可以通过指定均衡策略来将消息发送到不同的分区中
如果不指定,就会采用默认的随机均衡策略,将消息随机的存储到不同的分区中
每一条消息被发送到broker时,会根据paritition规则选择被存储到哪一个partition。
如果partition规则设置的合理,所有消息可以均匀分布到不同的partition里,这样就实现了水平扩展。(如果一个topic对应一个文件,那这个文件所在的机器I/O将会成为这个topic的性能瓶颈,而partition解决了这个问题)。
在发送一条消息时,可以指定这条消息的key,producer根据这个key和partition机制来判断将这条消息发送到哪个parition。
paritition机制可以通过指定producer的paritition. class这一参数来指定,该class必须实现kafka.producer.Partitioner接口。
本例中如果key可以被解析为整数则将对应的整数与partition总数取余,该消息会被发送到该数对应的partition。(每个parition都会有个序号)
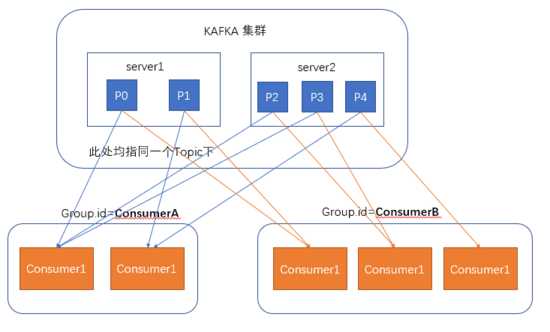
与消费者交互
在消费者消费消息时,kafka使用offset来记录当前消费的位置
在kafka的设计中,可以有多个不同的group来同时消费同一个topic下的消息,
两个不同的group同时消费,他们的的消费的记录位置offset各不项目,不互相干扰。
对于一个group而言,消费者的数量不应该多余分区的数量,
因为每个分区至多只能自动发送消息到一个group中的一个消费者上,即一个消费者可以消费多个分区,一个分区只能给同一个组的一个消费者消费。
因此,若一个group中的消费者数量大于分区数量的话,多余的消费者将不会收到任何消息。
offset偏移量
- 在每个分区中此偏移量都是唯一的。
- 消费者所持有的仅有的元数据就是这个偏移量,也就是消费者在这个log中的位置。
- 偏移量由消费者控制。正常情况当消费者消费消息的时候,偏移量也线性的的增加。消费者可以将偏移量重置为更老的一个偏移量,重新读取消息。
- 一个消费者的操作不会影响其它消费者对此log的处理
- 一个topic中有100条数据,我消费了50条并且提交了,那么此时的kafka服务端记录提交的offset就是49(offset从0开始),那么下次消费的时候offset就从50开始消费。
手动控制Offest
自动提交是在kafka拉取到数据完就直接提交数据偏移量。
而业务系统中,消费数据还伴随着一些逻辑业务处理,插入数据库等。
这事务过程,需要完成才提交。不然还没插进数据库,新的数据又来了。
加入插入数据库还失败了,就没法再消费一次失败的数据了。
所以要严格的不丢数据,需要手动控制offest。
- 手动commit offset,并针对partition_num启同样数目的consumer进程,这样就能保证一个consumer进程占有一个partition,commit offset的时候不会影响别的 partition 的 offset。但这个方法比较局限,因为partition和consumer进程的数目必须严格对应。
- 另一个方法同样需要手动commit offset,另外在consumer端再将所有fetch到的数据缓存到queue里,当把queue里所有的数据处理完之后,再批量提交offset,这样就能保证只有处理完的数据才被commit。
官网还说:
手动控制offest让我们能精确控制消息被消费(能实现 提交了offest的不再消费,没提交过offest的数据会再次消费)。
但这一过程可能在 数据插入数据库后,但是还没commit offset到kafka时 失败了。
那么下一次消费将还是从上次消费的起点取到数据,会重复插入数据库。
kafka提供的是 "at-least once delivery" 保证, 每个消息会被传递至少一次,然而在失败的时候会造成重复。
以上是关于kafka系列 -- 基础概念的主要内容,如果未能解决你的问题,请参考以下文章