第2节 mapreduce深入学习:8手机流量汇总求和
Posted mediocreworld
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第2节 mapreduce深入学习:8手机流量汇总求和相关的知识,希望对你有一定的参考价值。
第2节 mapreduce深入学习:8、手机流量汇总求和
例子:MapReduce综合练习之上网流量统计。
数据格式参见资料夹
需求一:统计求和
统计每个手机号的上行流量总和,下行流量总和,上行总流量之和,下行总流量之和
分析:以手机号码作为key值,上行流量,下行流量,上行总流量,下行总流量四个字段作为value值,然后以这个key,和value作为map阶段的输出,reduce阶段的输入。
data_flow.dat内容类似下面的:
1363157985066 13726230503 00-FD-07-A4-72-B8:CMCC 120.196.100.82 i02.c.aliimg.com 游戏娱乐 24 27 2481 24681 200
字段说明:
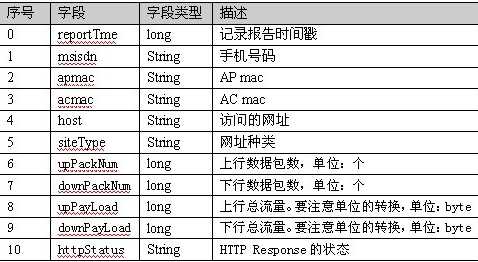
注意:将相同手机号的数据放到一起,以手机号作为key2!
代码:
FlowMain:
package cn.itcast.demo3.flowCount;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class FlowMain extends Configured implements Tool
@Override
public int run(String[] args) throws Exception
Job job = Job.getInstance(this.getConf(), FlowMain.class.getSimpleName());
// job.setJarByClass(FlowMain.class);
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job,new Path("file:///D:\\\\Study\\\\BigData\\\\heima\\\\stage2\\\\4、大数据离线第四天\\\\流量统计\\\\input\\\\data_flow.dat"));
job.setMapperClass(FlowMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(FlowBean.class);
job.setReducerClass(FlowReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job,new Path("file:///D:\\\\Study\\\\BigData\\\\heima\\\\stage2\\\\4、大数据离线第四天\\\\流量统计\\\\1sum"));
boolean b = job.waitForCompletion(true);
return b?0:1;
public static void main(String[] args) throws Exception
int run = ToolRunner.run(new Configuration(), new FlowMain(), args);
System.exit(run);
FlowMapper:
package cn.itcast.demo3.flowCount;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class FlowMapper extends Mapper<LongWritable,Text,Text,FlowBean>
//1363157985066 13726230503 00-FD-07-A4-72-B8:CMCC 120.196.100.82 i02.c.aliimg.com 游戏娱乐 24 27 2481 24681 200
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException
FlowBean flowBean = new FlowBean();
String[] split = value.toString().split("\\t");
flowBean.setUpFlow(Integer.parseInt(split[6]));//上行流量
flowBean.setDownFlow(Integer.parseInt(split[7]));//下行流量
flowBean.setUpCountFlow(Integer.parseInt(split[8]));//上行总流量
flowBean.setDownCountFlow(Integer.parseInt(split[9]));//下行总流量
//split[1] 手机号
//往下一阶段写出我们的数据,key2 是手机号 value2 我们自己封装定义的javaBean
context.write(new Text(split[1]),flowBean);
FlowReducer:
package cn.itcast.demo3.flowCount;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class FlowReducer extends Reducer<Text,FlowBean,Text,FlowBean>
@Override
protected void reduce(Text key, Iterable<FlowBean> values, Context context) throws IOException, InterruptedException
//上行流量
int upFlow = 0;
//下行流量
int downFlow = 0;
//上行总流量
int upCountFlow = 0;
//下行总流量
int downCountFlow = 0;
for(FlowBean flowBean:values)
upFlow += flowBean.getUpFlow();
downFlow += flowBean.getDownFlow();
upCountFlow += flowBean.getUpCountFlow();
downCountFlow += flowBean.getDownCountFlow();
FlowBean flowBean = new FlowBean();
flowBean.setUpFlow(upFlow);
flowBean.setDownFlow(downFlow);
flowBean.setUpCountFlow(upCountFlow);
flowBean.setDownCountFlow(downCountFlow);
context.write(key,flowBean);
FlowBean:
package cn.itcast.demo3.flowCount;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
/**
* 这里暂时不需要做排序,所以直接实现writable接口就可以了
*/
public class FlowBean implements Writable
//上行流量
private Integer upFlow;
//下行流量
private Integer downFlow;
//上行总流量
private Integer upCountFlow;
//下行总流量
private Integer downCountFlow;
/**
* 序列化方法
* @param out
* @throws IOException
*/
@Override
public void write(DataOutput out) throws IOException
out.writeInt(this.upFlow);
out.writeInt(this.downFlow);
out.writeInt(this.upCountFlow);
out.writeInt(this.downCountFlow);
/**
* 反序列化的方法
* @param in
* @throws IOException
*/
@Override
public void readFields(DataInput in) throws IOException
this.upFlow = in.readInt();
this.downFlow = in.readInt();
this.upCountFlow = in.readInt();
this.downCountFlow = in.readInt();
public void setUpFlow(Integer upFlow)
this.upFlow = upFlow;
public void setDownFlow(Integer downFlow)
this.downFlow = downFlow;
public void setUpCountFlow(Integer upCountFlow)
this.upCountFlow = upCountFlow;
public void setDownCountFlow(Integer downCountFlow)
this.downCountFlow = downCountFlow;
public Integer getUpFlow()
return upFlow;
public Integer getDownFlow()
return downFlow;
public Integer getUpCountFlow()
return upCountFlow;
public Integer getDownCountFlow()
return downCountFlow;
@Override
public String toString()
return "上行流量=" + upFlow +
", 下行流量=" + downFlow +
", 上行总流量=" + upCountFlow +
", 下行总流量=" + downCountFlow;
运行结果类似于:
13480253104 上行流量=3, 下行流量=3, 上行总流量=180, 下行总流量=180
以上是关于第2节 mapreduce深入学习:8手机流量汇总求和的主要内容,如果未能解决你的问题,请参考以下文章
第2节 mapreduce深入学习:15reduce端的join算法的实现