[Machine Learning for Trading] {ud501} Lesson 23: 03-03 Assessing a learning algorithm | Lesson 24:
Posted ecoflex
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[Machine Learning for Trading] {ud501} Lesson 23: 03-03 Assessing a learning algorithm | Lesson 24: 相关的知识,希望对你有一定的参考价值。
A closer look at KNN solutions
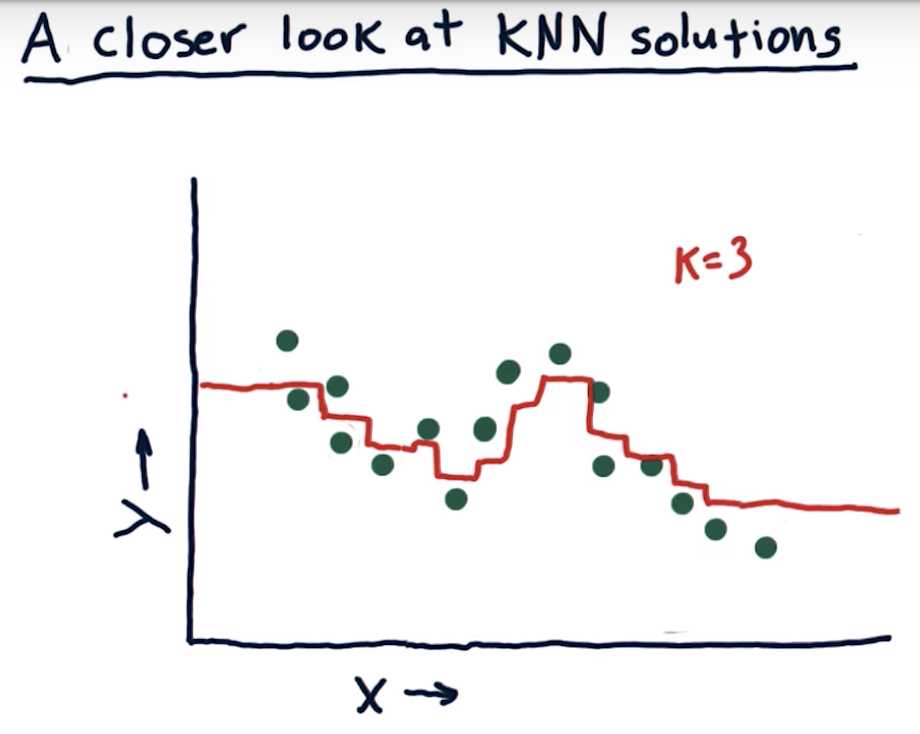
What happens as K varies
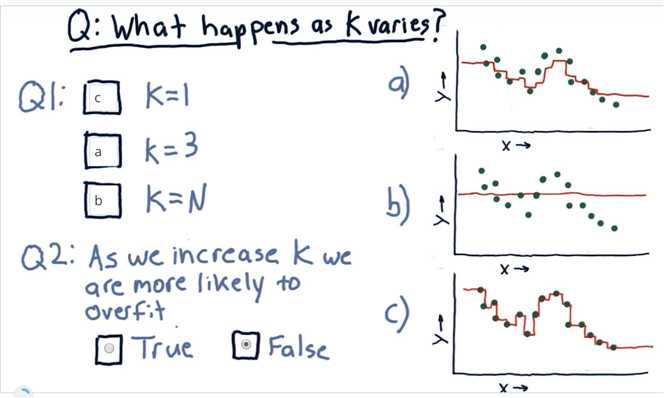
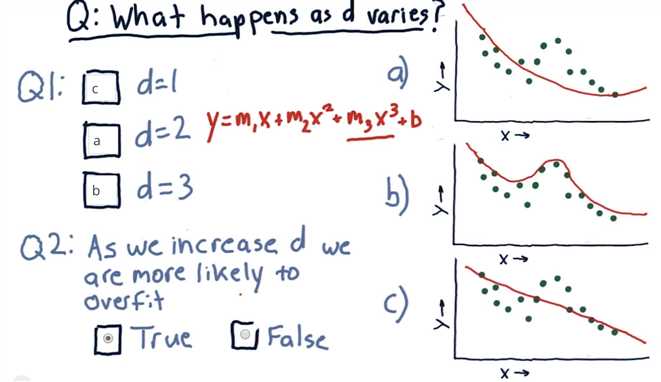
What happens as D varies
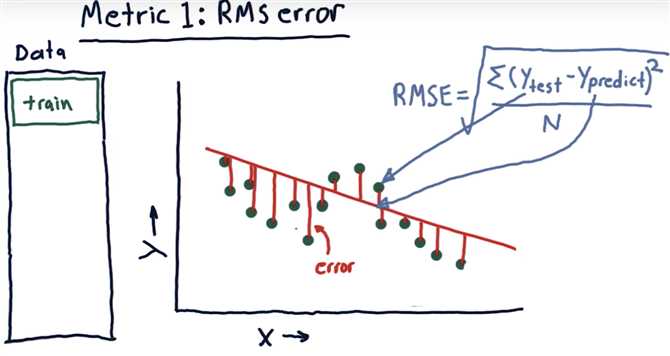
Metric 1 RMS Error
In Sample vs out of sample
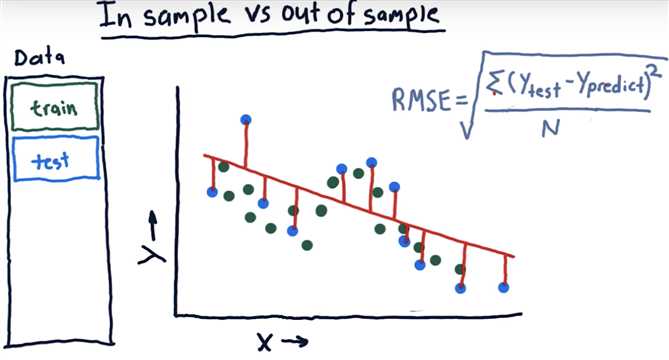
Which is worse?

Cross validation
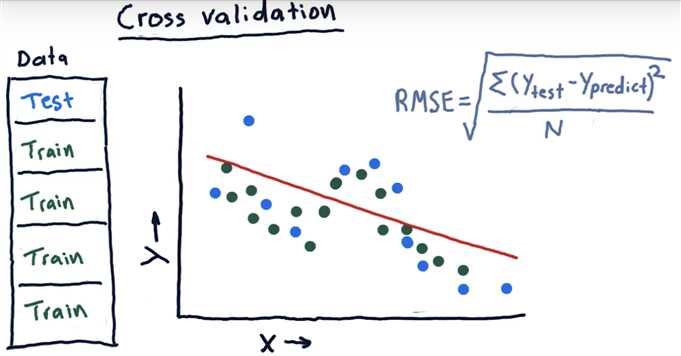
5-fold cross validation
Roll forward cross validation
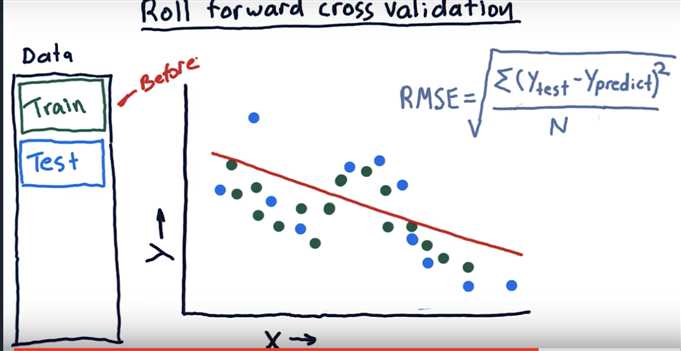
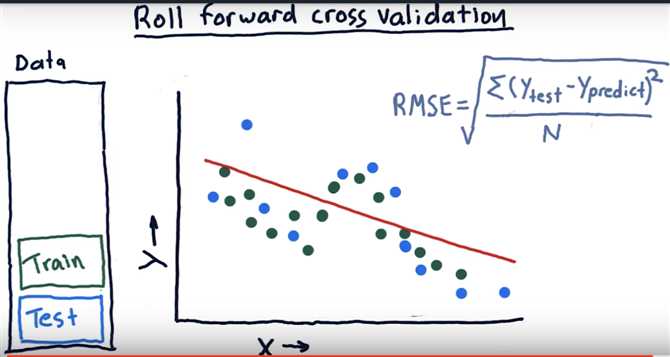
Metric 2: correlation
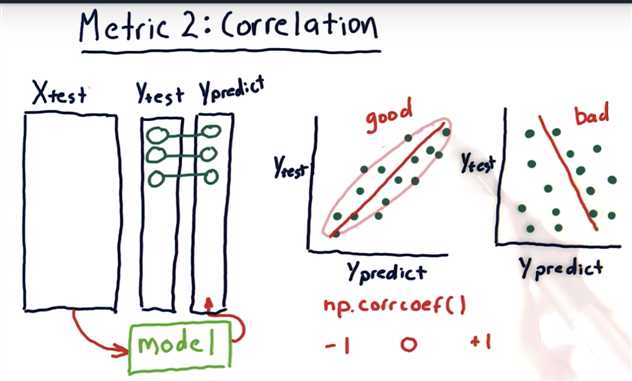
Correlation and RMS error

In most cases, as RMS error increases, correlation goes down. But yes, there are some cases where the opposite might happen (e.g. when there is a large bias).
So it might be hard to say for sure.
Overfitting
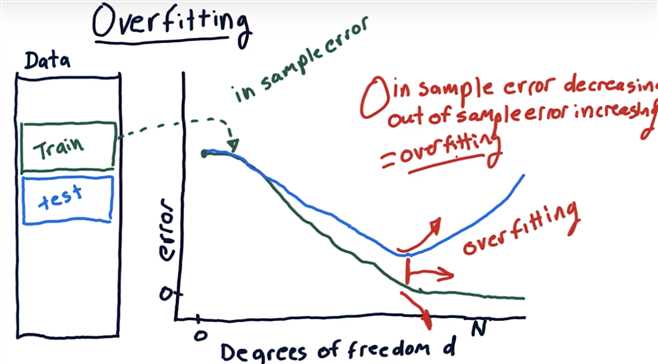
Overfitting Quiz
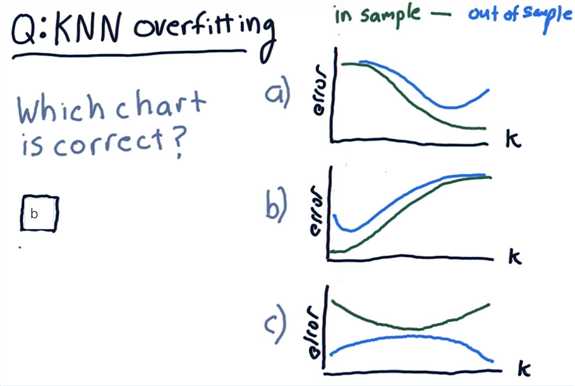
When k = 1, the model fits the training data perfectly, therefore in-sample error is low (ideally, zero). Out-of-sample error can be quite high.
As k increases, the model becomes more generalized, thus out-of-sample error decreases at the cost of slightly increasing in-sample error.
After a certain point, the model becomes too general and starts performing worse on both training and test data.
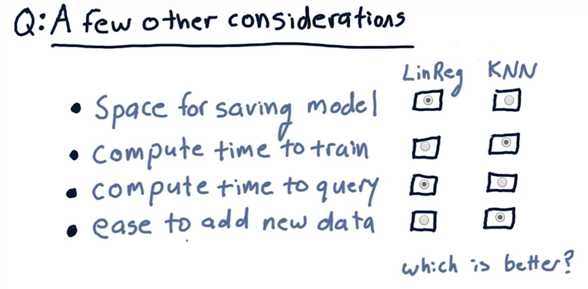
A Few other considerations
Ensemble learners
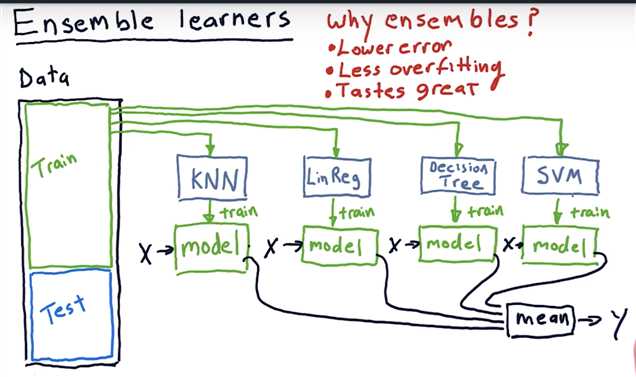
How to build an ensemble

If we combine several models of different types (here parameterized polynomials and non-parameterized kNN models), we can avoid being biased by one approach.
This typically results in less overfitting, and thus better predictions in the long run, especially on unseen data.
Bootstrap aggregating bagging
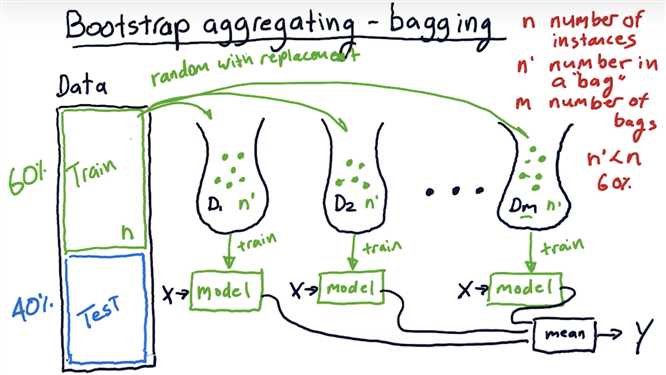
Correction: In the video (around 02:06), the professor mentions that n’ should be set to about 60% of n, the number of training instances. It is more accurate to say that in most implementations, n’ = n. Because the training data is sampled with replacement, about 60% of the instances in each bag are unique.
Overfitting

Yes, as we saw earlier, a 1NN model (kNN with k = 1) matches the training data exactly, thus overfitting.
An ensemble of such learners trained on slightly different datasets will at least be able to provide some generalization, and typically less out-of-sample error.
Correction: As per the question "Which is most likely to overfit?", the correct option to pick is the first one (single 1NN). The second option (ensemble of 10) has been mistakenly marked - but the intent is the same.
Bagging example
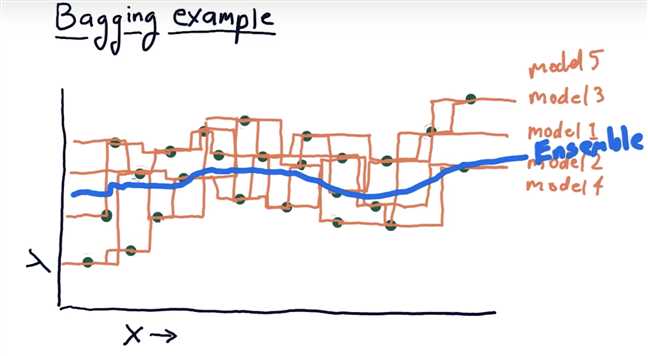
instances that was modelled poorly in the overall system before
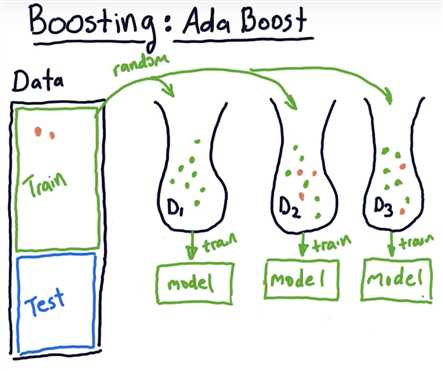
Overfitation

As m increases, AdaBoost tries to assign more and more specific data points to subsequent learners, trying to model all the difficult examples.
Thus, compared to simple bagging, it may result in more overfitting.
Summary

以上是关于[Machine Learning for Trading] {ud501} Lesson 23: 03-03 Assessing a learning algorithm | Lesson 24: 的主要内容,如果未能解决你的问题,请参考以下文章