高效学习排序算法
Posted haohao111
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了高效学习排序算法相关的知识,希望对你有一定的参考价值。
排序是一个经典的问题,它以一定的顺序对一个数组或列表中的元素进行重新排序。而排序算法也是各有千秋,每个都有自身的优点和局限性。虽然这些算法平常根本就不用自己去编写,但作为一个有追求的程序员,还是要了解它们从不同角度解决排序问题的思想。
学习算法是枯燥的,那怎么高效的理解它的原理呢?显然,如果以动图的方式,生动形象的把算法排序的过程展示出来,非常有助于学习。visualgo.net 就是一个可视化算法的网站,第一次访问的时候,真的是眼前一亮。本文就对常用的排序进行下总结。
1. 冒泡排序
冒泡排序的基本思想就是:把小的元素往前调或者把大的元素往后调。假设数组有 N 个元素,冒泡排序过程如下:
- 从当前元素起,向后依次比较每一对相邻元素(a,b)
- 如果 a>b 则交换这两个数
- 重复步骤1和2,直到比较最后一对元素(第 N-2 和 N-1 元素)
- 此时最大的元素已位于数组最后的位置,然后将 N 减 1,并重复步骤1,直到 N=1
冒泡排序的核心代码:
public static void bubbleSort(int[] a, int n) // 排序趟数,最后一个元素不用比较所以是 (n-1) 趟 for (int i = 0; i < n - 1; i++) // 每趟比较的次数,第 i 趟比较 (n-1-i) 次 for (int j = 0; j < n - 1 - i; j++) // 比较相邻元素,若逆序则交换 if (a[j] > a[j+1]) int tmp = a[j]; a[j] = a[j+1]; a[j+1] = tmp;
难点在于边界的确定,算法分析:
- 平均时间复杂度是 O(n^2),最佳情况是 O(n),最差情况是 O(n^2)
- 空间复杂度 O(1)
- 稳定的排序算法(相等元素的前后顺序排序后不变)
2. 选择排序
选择排序的基本思想就是:每次从未排序的列表中找到最小(大)的元素,放到已排序序列的末尾,直到所有元素排序完毕。假设数组有 N 个元素且 L=0,选择排序过程如下:
- 从 [L...N-1] 范围中找到最小元素的下标 X
- 交换第 X 与第 L 位置的元素值
- L 加 1,重复以上步骤,直到 L=N-2
选择排序的核心代码:
public static void selectionSort(int[] a, int n) // 排序趟数,最后一个元素是最大的不用比较所以是 (n-1) 趟 for (int i = 0; i < n-1; i++) int minIndex = i; // 无序列表中最小元素的下标 for (int j = i+1; j < n; j++) // 在无序列表中查找最小元素的小标并记录 if (a[j] < a[minIndex]) minIndex = j; // 将最小元素交换到本次循环的前端 int tmp = a[minIndex]; a[minIndex] = a[i]; a[i] = tmp;
算法分析:
- 平均时间复杂度是 O(n^2),最佳和最差情况也是一样
- 空间复杂度 O(1)
- 不稳定的排序算法(相等元素的前后顺序排序后可能改变)
3. 插入排序
插入排序的基本思想是:每次将待插入的元素,按照大小插入到前面已排序序列的适当位置上。插入排序过程如下:
- 从第一个元素开始,该元素可认为已排序
- 取出下一个元素,在已排序的元素序列中从后向前扫描
- 如果该元素(已排序)大于待插入元素 ,把它移到下一个位置
- 重复步骤 3,直到找到一个小于或等于待插入元素的位置,将待插入元素插入到下一个位置
- 重复步骤 2~5,直到取完数组元素
插入排序的核心代码:
public static void insertionSort(int[] a, int n) // a[0] 看做已排序 for (int i = 1; i < n; i++) int x = a[i]; // 待插入元素 int j=i-1; // 插入的位置 while (j >= 0 && a[j] > x) a[j+1] = a[j]; // 为待插入元素腾地 j--; a[j+1] = x; // 插入到下一个位置 j+1
算法分析:
- 平均时间复杂度是 O(n^2),最佳情况是 O(n),最差情况是 O(n^2)
- 空间复杂度 O(1)
- 稳定的排序算法
4. 希尔排序
希尔排序也称为增量递减排序,是对直接插入算法的改进,基于以下两点性质:
- 插入排序在对几乎已排好序的数据操作时,效率高,可以达到线性排序的效率
- 但插入排序一般来说是低效的,因为插入排序每次只能移动一位数据
希尔排序的改进是,使用一个增量将数组切分不同的分组,然后在组内进行插入排序,递减增量,直到增量为 1,好处就是数据能跨多个元素移动,一次比较就可能消除多个元素的交换。基本过程如下:
- 选取一个递增序列,一般使用
x/2或者x/3+1 - 使用序列中最大的增量,对数组分组,在组内插入排序,递减增量,直到为 1
核心代码:
public static void shellSort(int[] a, int n) // 计算递增序列,3x+1 : 1, 4, 13, 40, 121, 364, 1093, ... int h = 1; while (h < n/3) h = 3*h + 1; while (h >= 1) // 直到间隔为 1 // 按间隔 h 切分数组 for (int i = h; i < n; i++) // 对 a[i], a[i-h], a[i-2*h], a[i-3*h]...使用插入排序 int x = a[i]; // 待插入元素 int j=i; while (j >=h && x < a[j-h]) a[j] = a[j-h];// 为待插入元素腾地 j -= h; a[j] = x; // 插入 x // 递减增量 h /= 3;
希尔排序数组拆分插入图解,上面的动图可以辅助理解,与下图数据不一致:
算法分析:
- 时间复杂度与选择的增量序列有关,可能的值时 O(n^2) > O(n^1.5) > O(nlg2n)
- 空间复杂度 O(1)
- 不稳定的排序算法
5. 归并排序(递归&非递归)
归并排序是分而治之的排序算法,基本思想是:将待排序序列拆分多个子序列,先使每个子序列有序,再使子序列间有序,最终得到完整的有序序列。归并排序本质就是不断合并两个有序数组的过程,实现时主要分为两个过程:
- 拆分 - 递归的将当前数组二分(如果N是偶数,两边个数平等,如果是奇数,则一边多一个元素),直到只剩 0 或 1 个元素
- 归并 - 分别将左右半边数组排序,然后归并在一起形成一个大的有序数组
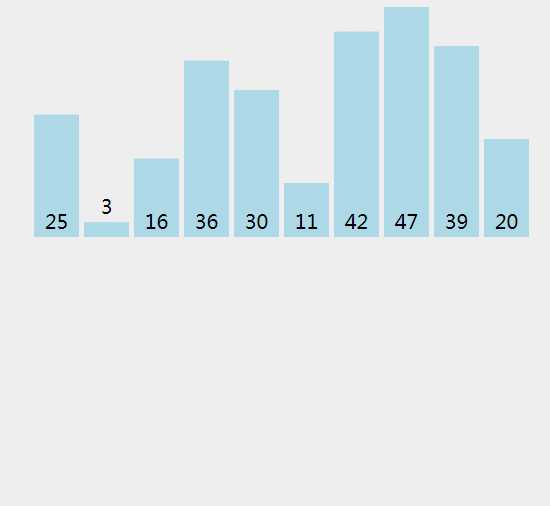
二路归并递归实现,核心代码:
public static void mergeSort(int[] a, int low, int high) // 要排序的数组 a[low..high] if (low < high) // 是否还能再二分 low >= high (0 或 1 个元素) int mid = low + (high - low) / 2; // 取中间值,避免 int 溢出 mergeSort(a, low, mid); // 将左半边排序 mergeSort(a, mid + 1, high); // 将右半边排序 merge(a, low, mid, high); // 归并左右两边 public static void merge(int[] a, int low, int mid, int high) int n = high - low + 1; // 合并后元素总数 int[] b = new int[n]; // 临时合并数组 int left = low, // 左边有序序列起始下标 right = mid + 1, // 右边有序序列起始下标 bIdx = 0; // 按升序归并到新数组 b 中 while (left <= mid && right <= high) b[bIdx++] = (a[left] <= a[right]) ? a[left++] : a[right++]; // 右边序列已拷贝完毕,左边还有剩余,将其依次拷贝到合并数组中 while (left <= mid) b[bIdx++] = a[left++]; // 左边序列已拷贝完毕,右边还有剩余,将其依次拷贝到合并数组中 while (right <= high) b[bIdx++] = a[right++]; // 将归并后的数组元素拷贝到原数组适当位置 for (int k = 0; k < n; k++) a[low + k] = b[k];
数组拆分和方法调用的动态情况如下图(右键查看大图):
递归的本质就是压栈,对于 Java 来说,调用层次太深有可能造成栈溢出。一般的,递归都能转为迭代实现,有时迭代也是对算法的优化。
归并排序中的递归主要是拆分数组,所以,非递归的重点就是把这部分改成迭代,它们的终止条件不同:
- 递归是在遇到基本情况时终止,比如遇到了两个各包含1个元素的数组,从大数组到小数组,自顶向下
- 迭代则相反,自底向上,它首先按 1 切分保证数组中的每2个元素有序,然后按 2 切分,保证数组中的每4个元素有序,以此类推,直到整个数组有序
核心代码:
public static void unRecursiveMergeSort(int[] a, int n) int low = 0, high = 0, mid = 0; // 待归并数组长度,1 2 4 8 ... int len = 1; // 从最小分割单位 1 开始 while(len <= n) // 按分割单位遍历数组并合并 for (int i = 0; i + len <= n; i += len * 2) low = i; // mid 变量主要是在合并时找到右半边数组的起始下标 mid = i + len - 1; high = i + 2 * len - 1; // 防止超过数组长度 if (high > n - 1) high = n - 1; // 归并两个有序的子数组 merge(a, low, mid, high); len *= 2; // 增加切分单位
算法分析:
- 平均时间复杂度,最佳和最差情况都是 O(nlgn)
- 空间复杂度 O(n),需要一个大小为 n 的临时数组
- 归并排序也是一个稳定的排序算法
6. 快速排序
快排可以说是应用最广泛的算法了,它的特点是使用很小的辅助栈原地排序。它也是一个分而治之的排序算法,基本思想是:选取一个关键值,将数组分成两部分,一部分小于关键值,一部分大于关键值,然后递归的对左右两部分排序。过程如下:
- 选取 a[low] 作为关键值-切分元素 p
- 使用两个指针遍历数组(既可一前一后,也可同方向移动),将比 p 小的元素前移,最后交换切分元素
- 递归的对左右部分进行排序
递归实现快排核心代码:
public static void quickSort(int[] a, int low, int high) if (low < high) int m = partition(a, low, high); // 切分 quickSort(a, low, m-1); // 将左半部分排序 quickSort(a, m+1, high); // 将右半部分排序 public static int partition(int[] a, int low, int high) // 将数组切分为 a[low..i-1], a[i], a[i+1..high] int p = a[low]; // 切分元素 int i = low; // 下一个小于切分元素可插入的位置 // 从切分元素下一个位置开始,遍历整个数组,进行分区 for (int j = low + 1; j <= high; j++) // 往前移动比切分元素小的元素 if (a[j] < p && (i++ != j)) int tmp = a[j]; a[j] = a[i]; a[i] = tmp; // 交换中枢(切分)元素 int tmp = a[low]; a[low] = a[i]; a[i] = tmp; return i;
算法分析:
- 平均时间复杂度 O(nlgn),最佳情况 O(nlgn),最差情况是 O(n^2)
- 空间复杂度 O(lgn),因为递归,占用调用栈空间
- 快排是一个不稳定的排序算法
7. 堆排序
堆排序是利用堆这种数据结构设计的算法。堆可看作一个完全二叉树,它按层级在数组中存储,数组下标为 k 的节点的父子节点位置分别如下:
- k 位置的父节点位置在 (k-1)/2 向下取整
- k 位置的左子节点位置在 2k+1
- k 位置的右子节点位置在 2k+2
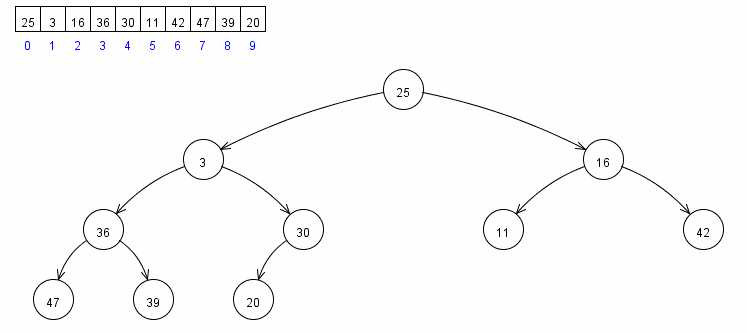
堆的表示如下:
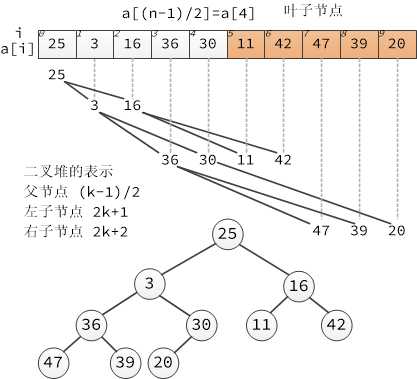
堆有序的定义是每个节点都大于等于它的两个子节点,所以根节点是有序二叉堆中值最大的节点。堆排序就是一个不断移除根节点,使用数组剩余元素重新构建堆的过程,和选择排序有点类似(只不过按降序取元素),构建堆有序数组基本步骤如下:
- 首先使用 (N-1)/2 之前的元素构建堆,完成后,整个堆最大元素位于数组的 0 下标位置
- 把数组首尾数据交换,此时数组最大值以找到
- 把堆的尺寸缩小 1,重复步骤 1 和 2,直到堆的尺寸为 1
核心代码:
public static void heapSort(int[] a) int n = a.length - 1; // 构建堆,一开始可将数组看作无序的堆 // 将从下标为 n/2 开始到 0 的元素下沉到合适的位置 // 因为 n/2 后面的元素都是叶子结点,无需下沉 for (int k = n/2; k >= 0; k--) sink(a, k, n); // 下沉排序 // 堆的根结点永远是最大值,所以只需将最大值和最后一位的元素交换即可 // 然后再维护一个除原最大结点以外的 n-1 的堆,再将新堆的根节点放在倒数第二的位置,如此反复 while (n > 0) // 将 a[1] 与最大的元素 a[n] 交换,并修复堆 int tmp = a[0]; a[0] = a[n]; a[n] = tmp; // 堆大小减1 n--; // 下沉排序,重新构建 sink(a, 0, n); /** 递归的构造大根堆 */ private static void sink(int[] a, int k, int n) // 是否存在左孩子节点 while ((2*k+1) <= n) // 左孩子下标 int left = 2*k+1; // left < n 说明存在右孩子,判断将根节点下沉到左还是右 // 如果左孩子小于右孩子,那么下沉为右子树的根,并且下次从右子树开始判断是否还要下沉 if (left < n && a[left] < a[left + 1]) left = left + 1; // 如果根节点不小于它的子节点,表示这个子树根节点最大 if (a[k] >= a[left]) break; // 不用下沉,跳出 // 否则将根节点下沉为它的左子树或右子树的根,也就是将较大的值上调 int tmp = a[k]; a[k] = a[left]; a[left] = tmp; // 继续从左子树或右子树开始,判断根节点是否还要下沉 k = left;
算法分析:
- 平均时间复杂度、最佳和最坏均是 O(nlgn)
- 空间复杂度 O(1),原地排序
- 不稳定的排序算法
转自:https://www.cnblogs.com/wskwbog
以上是关于高效学习排序算法的主要内容,如果未能解决你的问题,请参考以下文章