Hadoop在Linux环境下的配置
Posted xuanyuandai
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop在Linux环境下的配置相关的知识,希望对你有一定的参考价值。
写在前面:在这之前需要有自己 的Linux环境,了解常用的Linux命令。并且已经配置好了java环境,什么叫配置好呢,就是 echo $JAVA_HOME 命令是可以输出jdk路径的,
才叫配置好。如果只是java -version可以查看java版本,就需要source /etc/profile 命令来使其生效,不生效也是不行滴。
一、下载解压
首先下载Hadoop安装包,直接在Windows官网上下载就行,这是镜像网站,可自取:http://mirror.bit.edu.cn/apache/hadoop/common/,
我下载的版本是2.7.7 
下载完之后,直接将下载下来的压缩文件传到Linux上,我用的传输软件是 WinSCP,长这样: ,至于怎么用,百度一查就很明了了。
,至于怎么用,百度一查就很明了了。
好了,现在就是真正的Linux时间了,cd进到存放Hadoop压缩包的目录下,用解压缩命令(tar -zxvf hadoop-2.7.7-tar.gz)将其进行解压,
二、文件配置
接下来就要开始配置了,cd进到Hadoop路径下的 etc/hadoop 下,
1、首先是java路径配置,vim hadoop-env.sh编辑文件,
这里的java路径一定要自己配一遍,不要用 $JAVA_HOME,否则在集群环境下,启动的时候会找不到java的!!!!
:wq 保存并退出。然后执行 source hadoop-env.sh令其生效(忘了是不是必须的)。
然后 vim /etc/profile 打开系统配置,配置HADOOP环境变量。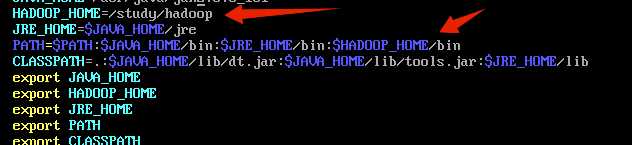 ,source令其生效.
,source令其生效.
2、core-site.xml 文件,打开后是空白的,如下添加
<configuration> <property> <!-- The name of the default file system. A URI whose scheme and authority determine the FileSystem implementation. The uri‘s scheme determines the config property (fs.SCHEME.impl) naming the FileSystem implementation class. The uri‘s authority is used to determine the host, port, etc. for a filesystem.--> <name>fs.defaultFS</name> <value>hdfs://master:9000</value> <!--master是Linux主机名--> </property> <property> <!--Size of read/write buffer used in SequenceFiles. byte --> <name>io.file.buffer.size</name> <value>131072</value> <!-- 大小 --> </property> <property> <!-- A base for other temporary directories. --> <name>hadoop.tmp.dir</name> <value>/study/hadoopWork/hadoop</value> <!-- 路径 -- > </property> </configuration>
3、hdfs-site.xml文件
<configuration> <property> <!-- HDFS blocksize of 256MB for large file-systems. default 128MB--> <name>dfs.blocksize</name> <value>268435456</value> </property> <property> <!-- More NameNode server threads to handle RPCs from large number of DataNodes. default 10--> <name>dfs.namenode.handler.count</name> <value>100</value> </property> </configuration>
4、mapred-site.xml,这个文件没有,需要将mapred-site.xml.template重命名
<configuration> <!-- Configurations for MapReduce Applications --> <property> <!-- Execution framework set to Hadoop YARN. --> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <!-- The amount of memory to request from the scheduler for each map task. --> <name>mapreduce.map.memory.mb</name> <value>1536</value> </property> <property> <!-- Larger heap-size for child jvms of maps. --> <name>mapreduce.map.java.opts</name> <value>-Xmx1024M</value> </property> <property> <!-- Larger resource limit for reduces. --> <name>mapreduce.reduce.memory.mb</name> <value>3072</value> </property> <property> <!-- Larger heap-size for child jvms of reduces. --> <name>mapreduce.reduce.java.opts</name> <value>-Xmx2560M</value> </property> <property> <!-- The total amount of buffer memory to use while sorting files, in megabytes. By default, gives each merge stream 1MB, which should minimize seeks.--> <name>mapreduce.task.io.sort.mb</name> <value>512</value> </property> <property> <!-- The number of streams to merge at once while sorting files. This determines the number of open file handles.--> <name>mapreduce.task.io.sort.factor</name> <value>100</value> </property> <property> <!--The default number of parallel transfers run by reduce during the copy(shuffle) phase.--> <name>mapreduce.reduce.shuffle.parallelcopies</name> <value>50</value> </property> <!--Configurations for MapReduce JobHistory Server--> <property> <!--MapReduce JobHistory Server IPC host:port--> <name>mapreduce.jobhistory.address</name> <value>master:10020</value> </property> <property> <!--MapReduce JobHistory Server Web UI host:port--> <name>mapreduce.jobhistory.webapp.address</name> <value>master:19888</value> </property> <property> <!--Directory where history files are written by MapReduce jobs.--> <name>mapreduce.jobhistory.intermediate-done-dir</name> <value>/study/hadoopWork/hadoop</value> </property> <property> <!--Directory where history files are managed by the MR JobHistory Server.--> <name>mapreduce.jobhistory.done-dir</name> <value>/study/hadoopWork/hadoop</value> </property> </configuration>
5、yarn-site.xml
<configuration> <!-- Configurations for ResourceManager and NodeManager --> <property> <!-- Enable ACLs? Defaults to false. --> <name>yarn.acl.enable</name> <value>false</value> </property> <property> <!-- ACL to set admins on the cluster. ACLs are of for comma-separated-usersspacecomma-separated-groups. Defaults to special value of * which means anyone. Special value of just space means no one has access. --> <name>yarn.admin.acl</name> <value>*</value> </property> <property> <!-- Configuration to enable or disable log aggregation --> <name>yarn.log-aggregation-enable</name> <value>false</value> </property> <!-- Configurations for ResourceManager --> <property> <!-- host Single hostname that can be set in place of setting all yarn.resourcemanager*address resources. Results in default ports for ResourceManager components. --> <name>yarn.resourcemanager.hostname</name> <value>master</value> </property> <property> <!-- CapacityScheduler (recommended), FairScheduler (also recommended), or FifoScheduler --> <name>yarn.resourcemanager.scheduler.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value> </property> <property> <!--The minimum allocation for every container request at the RM, in MBs. Memory requests lower than this will throw a InvalidResourceRequestException.--> <name>yarn.scheduler.minimum-allocation-mb</name> <value>1024</value> </property> <property> <!--The maximum allocation for every container request at the RM, in MBs. Memory requests higher than this will throw a InvalidResourceRequestException.--> <name>yarn.scheduler.maximum-allocation-mb</name> <value>8192</value> </property> <!--Configurations for NodeManager--> <property> <!-- Defines total available resources on the NodeManager to be made available to running containers --> <name>yarn.nodemanager.resource.memory-mb</name> <value>8192</value> </property> <property> <!--Ratio between virtual memory to physical memory when setting memory limits for containers. Container allocations are expressed in terms of physical memory, and virtual memory usage is allowed to exceed this allocation by this ratio.--> <name>yarn.nodemanager.vmem-pmem-ratio</name> <value>2.1</value> </property> <property> <!-- Where to store container logs. An application‘s localized log directory will be found in $yarn.nodemanager.log-dirs/application_$appid. Individual containers‘ log directories will be below this, in directories named container_$contid. Each container directory will contain the files stderr, stdin, and syslog generated by that container.--> <name>yarn.nodemanager.log-dirs</name> <value>/study/hadoopWork/data/hadoop/log</value> </property> <property> <!--HDFS directory where the application logs are moved on application completion. Need to set appropriate permissions. Only applicable if log-aggregation is enabled. --> <name>yarn.nodemanager.remote-app-log-dir</name> <value>/study/hadoopWork/data/hadoop/log</value> </property> </configuration>
至此,基本已经配置完毕,配置文件中遇到的路径等,需要自己在相应目录下去新建,也可以配置成自己的路径。
6、初始化hadoop
hdfs namenode -format。如果报错找不到JAVA路径等,就去看看自己的java环境变量是不是配置正确,hadoop-env.sh文件的java路径是不是正确。
如果百度查到的解决办法都试过了,还是不行,就把安装好的jdk卸载掉,重新下载安装。一定要卸载干净!!卸载方法可自行百度,当时我足足配置了三四遍才成功配置好。
7、启动集群
在sbin路径下,执行 start-all.sh,java报错解决办法同6, 成功啦!
成功啦!
执行jps查看执行状态。
也不是一次就能配置成功,配置过程中,我也是百度了大量的前辈的资料,如本文中有相似之处,请谅解。实在是前辈们的博客地址没记住,
假装这里有参考文献吧
以上是关于Hadoop在Linux环境下的配置的主要内容,如果未能解决你的问题,请参考以下文章
大数据系列在windows下连接linux 下的hadoop环境进行开发