Hadoop在eclipse中的配置
Posted 夏立
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop在eclipse中的配置相关的知识,希望对你有一定的参考价值。
在安装完linux下的hadoop框架,实现完所现有的wordCount程序,能够完美输出结果之后,我们开始来搭建在window下的eclipse的环境,进行相关程序的编写。
在网上有很多未编译版本,需要手动进行相关编辑,所以特地找了一个已经编译完好的插件
eclipse版本:SR2-kepler
java版本:1.8.101
Hadoop 版本:hadoop2.5.2.tar.gz
需要hadoop的插件:eclipse-hadoop-2.5.2-plugin http://pan.baidu.com/s/1qYMtefq
安装步骤:
一、首先将hadoop-2.5.2.tar.gz解压,作为Hadoop的安装目录。
设置Hadoop的环境变量。在环境变量中,添加HADOOP_HOME=安装目录,然后在PATH的变量中增加%HADOOP_HOME%\\bin
二、修改电脑中hosts文件。
进入到c:/window/system32/drive/etc 文件夹中,可以找到hosts文件。在hosts文件中添加相关的IP设置(主要是虚拟机的IP地址,进行相关的配置,可以将文件进行互相传递)
三、讲下载的hadoop插件复制到eclipse安装目录中的plugin文件夹中,重启eclipse,然后打开window->preferences中可以看到增加了Hadoop mapreduced的选项。结果如图所示:
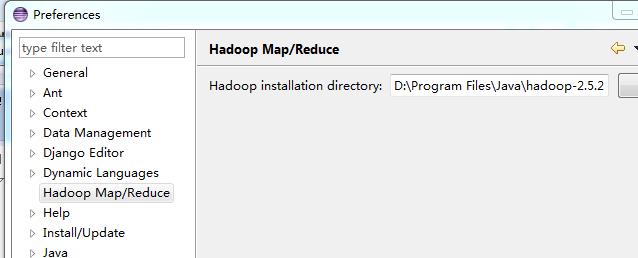
点击该选项后,出现右侧内容,添加hadoop的安装路径。
四、进行hadoop在eclipse中的相关端口配置。
点击window->open perspective->other中,出现如下内容:
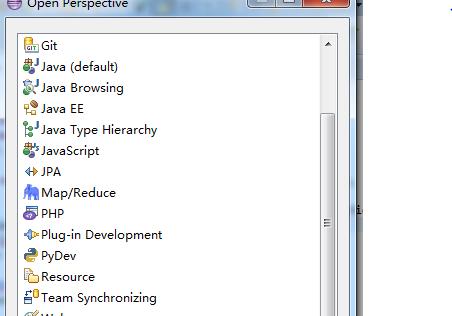
点击Map/Reduce,之后eclipse中的右侧边栏中,会出现DFS locations的选择,然后左键,之后在下方的控制栏中会出现一个Map/Reduced location的控制窗口,点击,在控制窗口下方右键,创建new hadoop location,
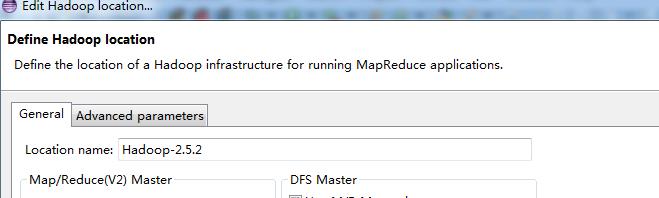
出现如图所示的编辑配置,然后填入你在hadoop中的配置的IP地址和端口号。
直到现在,所有的有关的eclipse的配置已经完成。如果在DFS location 中显示了原有Hadoop集群上的文件个数,那么说明连接是成功,如果没有出现,说明连接是失败的,需要进行相关的查询。纠正错误。
下面需要进入测试阶段。
①、创建新的项目
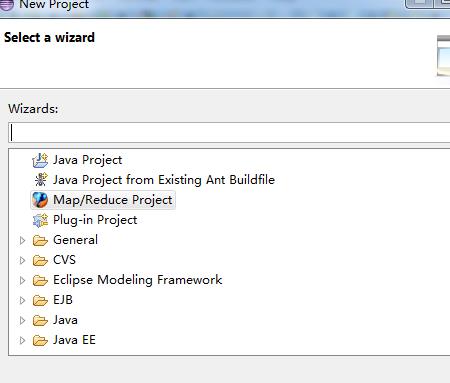
②、选择Map/Reduce Project项目,进行相关的项目创建。
测试WordCount程序,源代码从Hadoop-2.5.2-src文件夹中进行复制。
③、配置运行环境:
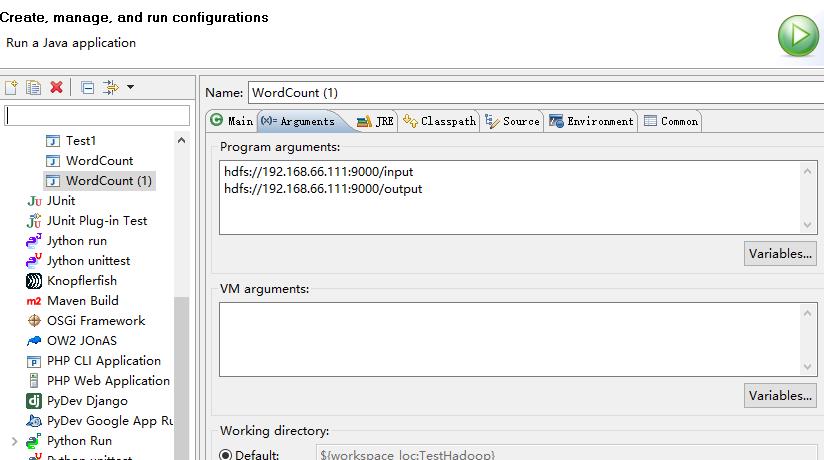
以上配置是为了体现文件中的输入和输出。而且,文件目录必须不存在,重新建立。
在工程创建过程中,不能导入包。手动导入,后续需要进行改进。
成功表现:
控制窗口中:

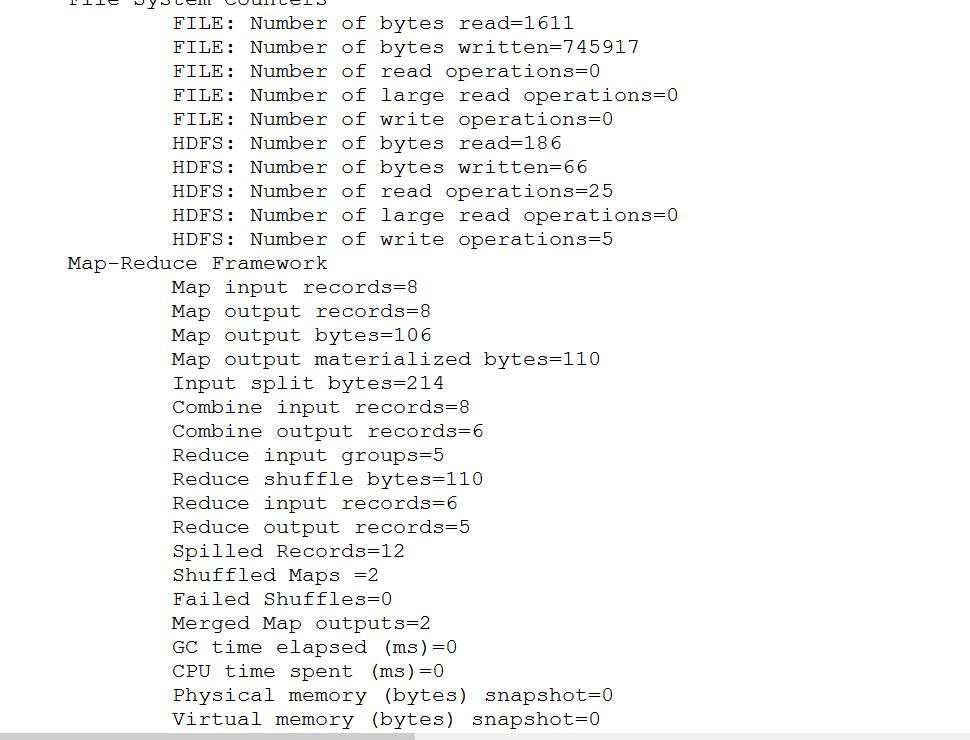
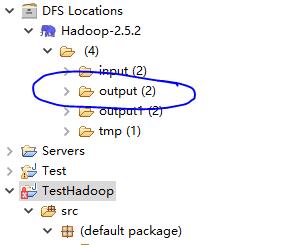
右侧边栏中体现的文件:
出现错误:
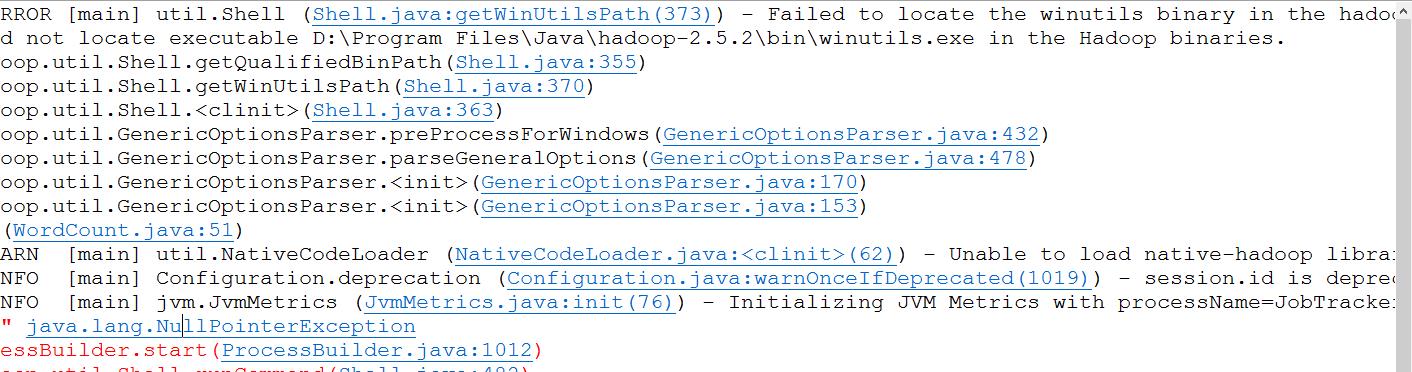
1、Failed to locate the winutils binary in the hadoop binary path
java.io.IOException: Could not locate executable D:\\Program Files\\Java\\hadoop-2.5.2\\bin\\winutils.exe in the Hadoop binaries.
解决办法:下载 hadoop-common-2.2.0-bin-master http://pan.baidu.com/s/1kVNjmAz 将文件解压,然后将winutils.exe,Hadoop.dill文件复制到Hadoop的安装目录下\\bin文件夹中。进行覆盖。
2、Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
INFO [main] Configuration.deprecation (Configuration.java:warnOnceIfDeprecated(1019)) - session.id is deprecated. Instead, use dfs.metrics.session-id
INFO [main] jvm.JvmMetrics (JvmMetrics.java:init(76)) - Initializing JVM Metrics with processName=JobTracker, sessionId=
解决办法:和在Linux下解决问题的方法相同。
解压:hadoop-native-64-2.5.2 http://pan.baidu.com/s/1o7IJkMm 文件,覆盖lib\\native文件。
3、exception in thread "main" java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)Z
at org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Native Method)
解决办法:下载对应hadoop源代码,hadoop-2.5.5-src.tar.gz解压,hadoop-2.5.2-src\\hadoop-common-project\\hadoop-common\\src\\main\\java\\org\\apache\\hadoop\\io\\nativeio下NativeIO.java 复制到对应的Eclipse的project,然后修改public static boolean access(String path, AccessRight desiredAccess)方法返回值为return true
4、hadoop读取的文件格式如果是GBK,且内容含有中文,那么map/reduce程序运行出错,
解决办法:将文件格式改成utf-8,问题解决。
5,创建log4j.properties文件
在src目录下创建log4j.properties文件,内容如下:
log4j.rootLogger=debug,stdout,R
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%5p - %m%n
log4j.appender.R=org.apache.log4j.RollingFileAppender
log4j.appender.R.File=mapreduce_test.log
log4j.appender.R.MaxFileSize=1MB
log4j.appender.R.MaxBackupIndex=1
log4j.appender.R.layout=org.apache.log4j.PatternLayout
log4j.appender.R.layout.ConversionPattern=%p %t %c - %m%n
log4j.logger.com.codefutures=DEBUG
6. in thread "main" java.net.ConnectException: Call From PC/192.168.92.1 to master:8020 failed on connection exception: java.net.ConnectException: Connection refused: no further information; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at org.apache.hadoop.net.NetUtils.wrapWithMessage(NetUtils.java:783)
at org.apache.hadoop.net.NetUtils.wrapException(NetUtils.java:730)
at org.apache.hadoop.ipc.Client.call(Client.java:1415)
at org.apache.hadoop.ipc.Client.call(Client.java:1364)
问题出现原因:端口配置无法进行访问和连接。之后开始配置hadoop的环境配置文件。但本人配置时还修改了如下内容(由于你的环境和我的可能不一致,可以在后面出现相关问题后再进行修改):
a.在master节点上(ubuntu-V01)修改hdfs-site.xml加上以下内容
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
旨在取消权限检查,原因是为了解决我在windows机器上配置eclipse连接hadoop服务器时,配置map/reduce连接后报以下错误,org.apache.hadoop.security.AccessControlException: Permission denied:
b.同样在master节点上(ubuntu-V01)修改hdfs-site.xml加上以下内容
<property>
<name>dfs.web.ugi</name>
<value>jack,supergroup</value>
</property>
原因是运行时,报如下错误 WARN org.apache.hadoop.security.ShellBasedUnixGroupsMapping: got exception trying to get groups for user jack
应该是我的windows的用户名为jack,无访问权限
更多权限配置可参看官方说明文档:
HDFS权限管理用户指南http://hadoop.apache.org/docs/r1.0.4/cn/hdfs_permissions_guide.html
解决办法:配置完成之后,发现仍然有这样的问题。后来发现,是自己eclipse中运行配置有问题。主要测试步骤中的③中的网址配置错误。应该是master:9000访问端口。将其正确配置后,已经可以进行相关编程,错误解决。
以上是关于Hadoop在eclipse中的配置的主要内容,如果未能解决你的问题,请参考以下文章
如何在Windows中使用Eclipse访问虚拟机Linux系统中的hadoop
Hadoop环境 IDE配置(在eclipse中安装hadoop-eclipse-plugin-2.7.3.jar插件)