python之初学爬虫
Posted sgy614092725
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python之初学爬虫相关的知识,希望对你有一定的参考价值。
一、开发工具:
- 运行环境: python3.7 win10
- python 第三方库: requests (自行安装 ) >>> cmd --->pip install requests, 具体不做介绍)
二、 检测是否安装成功
在命令行中输入python,敲击回车,进入python环境。
再输入以下指令并回车:
import requests 如果不报错,那一般是已经安装好了。
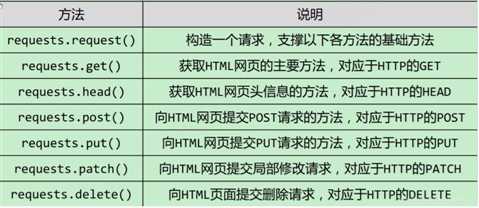
三、request库简介:
四、response属性
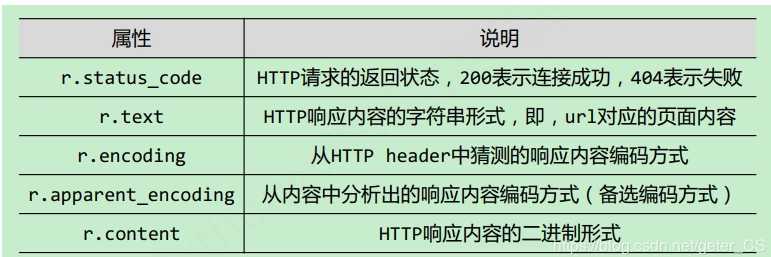
五、我们用requeses库的个体()函数访问必应主页20次,打印返回状态,text内容,并且计算text()属性和content属性返回网页内容的长度
代码如下:
import requests def gethtmlText(url): try: for i in range(0,20): #访问20次 r = requests.get(url, timeout=30) r.raise_for_status() #如果状态不是200,引发异常 r.encoding = ‘utf-8‘ #无论原来用什么编码,都改成utf-8 return r.status_code,r.text,r.content,len(r.text),len(r.content) ##返回状态,text和content内容,text()和content()网页的长度 except: return "" url = "https://cn.bing.com/?toHttps=1&redig=731C98468AFA474D85AECB7DB98B95D9" print(getHTMLText(url))
运行结果如下:


好了,今天的分享就到这里了~~~~~~
以上是关于python之初学爬虫的主要内容,如果未能解决你的问题,请参考以下文章