吴裕雄 python 神经网络——TensorFlow 数据集高层操作
Posted tszr
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了吴裕雄 python 神经网络——TensorFlow 数据集高层操作相关的知识,希望对你有一定的参考价值。
import tempfile import tensorflow as tf train_files = tf.train.match_filenames_once("E:\\\\output.tfrecords") test_files = tf.train.match_filenames_once("E:\\\\output_test.tfrecords") # 解析一个TFRecord的方法。 def parser(record): features = tf.parse_single_example(record, features={ ‘image_raw‘:tf.FixedLenFeature([],tf.string), ‘pixels‘:tf.FixedLenFeature([],tf.int64), ‘label‘:tf.FixedLenFeature([],tf.int64) }) decoded_images = tf.decode_raw(features[‘image_raw‘],tf.uint8) retyped_images = tf.cast(decoded_images, tf.float32) images = tf.reshape(retyped_images, [784]) labels = tf.cast(features[‘label‘],tf.int32) #pixels = tf.cast(features[‘pixels‘],tf.int32) return images, labels image_size = 299 # 定义神经网络输入层图片的大小。 batch_size = 100 # 定义组合数据batch的大小。 shuffle_buffer = 10000 # 定义随机打乱数据时buffer的大小。 # 定义读取训练数据的数据集。 dataset = tf.data.TFRecordDataset(train_files) dataset = dataset.map(parser) # 对数据进行shuffle和batching操作。这里省略了对图像做随机调整的预处理步骤。 dataset = dataset.shuffle(shuffle_buffer).batch(batch_size) # 重复NUM_EPOCHS个epoch。 NUM_EPOCHS = 10 dataset = dataset.repeat(NUM_EPOCHS) # 定义数据集迭代器。 iterator = dataset.make_initializable_iterator() image_batch, label_batch = iterator.get_next() # 定义神经网络的结构以及优化过程。这里与7.3.4小节相同。 def inference(input_tensor, weights1, biases1, weights2, biases2): layer1 = tf.nn.relu(tf.matmul(input_tensor, weights1) + biases1) return tf.matmul(layer1, weights2) + biases2 INPUT_NODE = 784 OUTPUT_NODE = 10 LAYER1_NODE = 500 REGULARAZTION_RATE = 0.0001 TRAINING_STEPS = 5000 weights1 = tf.Variable(tf.truncated_normal([INPUT_NODE, LAYER1_NODE], stddev=0.1)) biases1 = tf.Variable(tf.constant(0.1, shape=[LAYER1_NODE])) weights2 = tf.Variable(tf.truncated_normal([LAYER1_NODE, OUTPUT_NODE], stddev=0.1)) biases2 = tf.Variable(tf.constant(0.1, shape=[OUTPUT_NODE])) y = inference(image_batch, weights1, biases1, weights2, biases2) # 计算交叉熵及其平均值 cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y, labels=label_batch) cross_entropy_mean = tf.reduce_mean(cross_entropy) # 损失函数的计算 regularizer = tf.contrib.layers.l2_regularizer(REGULARAZTION_RATE) regularaztion = regularizer(weights1) + regularizer(weights2) loss = cross_entropy_mean + regularaztion # 优化损失函数 train_step = tf.train.GradientDescentOptimizer(0.01).minimize(loss) # 定义测试用的Dataset。 test_dataset = tf.data.TFRecordDataset(test_files) test_dataset = test_dataset.map(parser) test_dataset = test_dataset.batch(batch_size) # 定义测试数据上的迭代器。 test_iterator = test_dataset.make_initializable_iterator() test_image_batch, test_label_batch = test_iterator.get_next() # 定义测试数据上的预测结果。 test_logit = inference(test_image_batch, weights1, biases1, weights2, biases2) predictions = tf.argmax(test_logit, axis=-1, output_type=tf.int32) # 声明会话并运行神经网络的优化过程。 with tf.Session() as sess: # 初始化变量。 sess.run((tf.global_variables_initializer(),tf.local_variables_initializer())) # 初始化训练数据的迭代器。 sess.run(iterator.initializer) # 循环进行训练,直到数据集完成输入、抛出OutOfRangeError错误。 while True: try: sess.run(train_step) except tf.errors.OutOfRangeError: break test_results = [] test_labels = [] # 初始化测试数据的迭代器。 sess.run(test_iterator.initializer) # 获取预测结果。 while True: try: pred, label = sess.run([predictions, test_label_batch]) test_results.extend(pred) test_labels.extend(label) except tf.errors.OutOfRangeError: break # 计算准确率 correct = [float(y == y_) for (y, y_) in zip (test_results, test_labels)] accuracy = sum(correct) / len(correct) print("Test accuracy is:", accuracy)
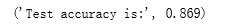
以上是关于吴裕雄 python 神经网络——TensorFlow 数据集高层操作的主要内容,如果未能解决你的问题,请参考以下文章
吴裕雄 python 神经网络——TensorFlow 输入文件队列
吴裕雄 python 机器学习——人工神经网络感知机学习算法的应用
吴裕雄 python 神经网络——TensorFlow 队列操作
吴裕雄 python 神经网络——TensorFlow 数据集高层操作