本地录音调用百度语音识别接口
Posted dongxixi
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了本地录音调用百度语音识别接口相关的知识,希望对你有一定的参考价值。
#!/usr/bin/env python import requests import json import base64 import pyaudio import wave import os import psutil #首先配置必要的信息 def bat(voice_path): baidu_server = ‘https://aip.baidubce.com/oauth/2.0/token?‘ grant_type = ‘client_credentials‘ client_id = ‘uj70rS1LiwZ9sQDvMSUqKsie‘ #API KEY client_secret = ‘Q88eav41PzeNLczZ3hlRjhR8e4WShXwD‘ #Secret KEY 这里可以自己去百度注册,这里是我的API KEY 和 Secret KEY #合成请求token的url url = baidu_server+‘grant_type=‘+grant_type+‘&client_id=‘+client_id+‘&client_secret=‘+client_secret #获取token res = requests.get(url).text data = json.loads(res) token = data[‘access_token‘] #设置音频的属性,采样率,格式等 VOICE_RATE = 8000 FILE_NAME = voice_path # USER_ID = ‘16241950‘ #这里的id随便填填就好啦,我填的自己昵称 FILE_TYPE = ‘wav‘ CUID="wate_play" #读取文件二进制内容 f_obj = open(FILE_NAME, ‘rb‘) content = base64.b64encode(f_obj.read()) # 百度语音识别需要base64编码格式 speech = content.decode("utf-8") size = os.path.getsize(FILE_NAME) #json封装 datas = json.dumps({ ‘format‘: FILE_TYPE, ‘rate‘: VOICE_RATE, ‘channel‘: 1, ‘cuid‘: CUID, ‘token‘: token, ‘speech‘: speech, ‘len‘: size, "dev_pid":"1536" }) return datas #设置headers和请求地址url def post(datas): headers = {‘Content-Type‘:‘application/json‘} url = ‘https://vop.baidu.com/server_api‘ # url = "http://vop.baidu.com/server_api" #用post方法传数据 request = requests.post(url, datas, headers) result = json.loads(request.text) text = result.get("result") if result[‘err_no‘] == 0: return text else: return "Error" def get_audio(filepath): input("回车开始录音 >>>") #输出提示文本,input接收一个值,转为str,赋值给aa CHUNK = 256 #定义数据流块 FORMAT = pyaudio.paInt16 #量化位数(音量级划分) CHANNELS = 1 # 声道数;声道数:可以是单声道或者是双声道 RATE = 8000 # 采样率;采样率:一秒内对声音信号的采集次数,常用的有8kHz, 16kHz, 32kHz, 48kHz, 11.025kHz, 22.05kHz, 44.1kHz RECORD_SECONDS = 5 #录音秒数 WAVE_OUTPUT_FILENAME = filepath #wav文件路径 p = pyaudio.PyAudio() #实例化 stream = p.open(format=FORMAT, channels=CHANNELS, rate=RATE, input=True, frames_per_buffer=CHUNK) print("*"*10, "开始录音:请在5秒内输入语音") frames = [] #定义一个列表 for i in range(0, int(RATE / CHUNK * RECORD_SECONDS)): #循环,采样率11025 / 256 * 5 data = stream.read(CHUNK) #读取chunk个字节 保存到data中 frames.append(data) #向列表frames中添加数据data # print(frames) print("*" * 10, "录音结束\\n") stream.stop_stream() stream.close() #关闭 p.terminate() #终结 wf = wave.open(WAVE_OUTPUT_FILENAME, ‘wb‘) #打开wav文件创建一个音频对象wf,开始写WAV文件 wf.setnchannels(CHANNELS) #配置声道数 wf.setsampwidth(p.get_sample_size(FORMAT)) #配置量化位数 wf.setframerate(RATE) #配置采样率 wf.writeframes(b‘‘.join(frames)) #转换为二进制数据写入文件 wf.close() #关闭 return def check_disk(): list_drive = psutil.disk_partitions() # 找出本地磁盘列表,保存的是结构体对象 list_disk = [] for drive in list_drive: list_disk.append(drive.device) return list_disk if __name__ == ‘__main__‘: list_disk = check_disk() # 检索本地磁盘 dirname_path = os.path.join(list_disk[0], "voice") # 设置语音文件存放路径, (mac os下需要自己定存储路径) if not os.path.exists(dirname_path): os.makedirs(dirname_path) filename = "voice.wav" # 定义语音文件名 in_path = os.path.join(dirname_path, filename) get_audio(in_path) # 录音 datas = bat(in_path) # 封装百度语音识别需要的配置信息,返回请求头 res = post(datas) # 连接百度语音识别接口,得到识别结果 print("识别结果:",res[0])
实现效果:

在上述代码中,需要装到requests、psutil、pyaudio等库,其中pyaudio这个库在python3环境下装比较特殊,
windows环境下具体步骤如下:
第一步:下载whl文件支持
url:https://www.lfd.uci.edu/~gohlke/pythonlibs/#pyaudio
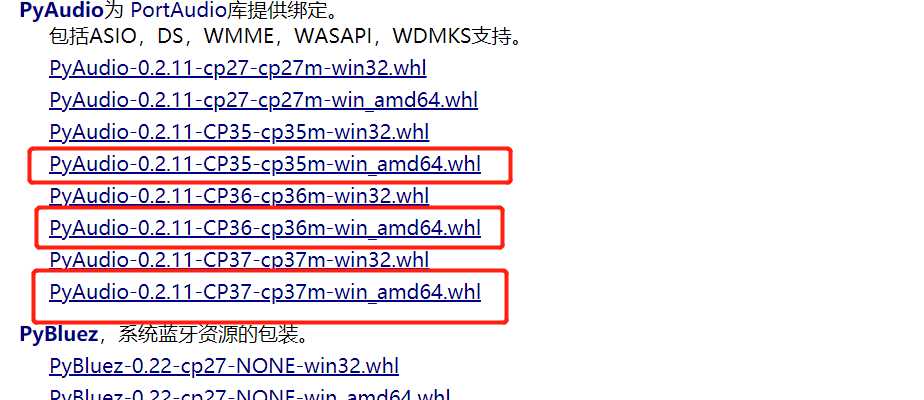
注意不要下载错了,资源很多
第二步:打开cmd,cd 进入下载的whl所在目录
执行命令:pip install Twisted-18.7.0-cp36-cp36m-win_amd64.whl # 下载的什么版本,后面就跟什么版本
第三步:执行命令:pip install pyaudio 安装
如果本地同时装有python2和python3,想装到python3里可以在cmd命令里把 pip 改成 pip3 即可
mac os 下安装pyaudio步骤如下:
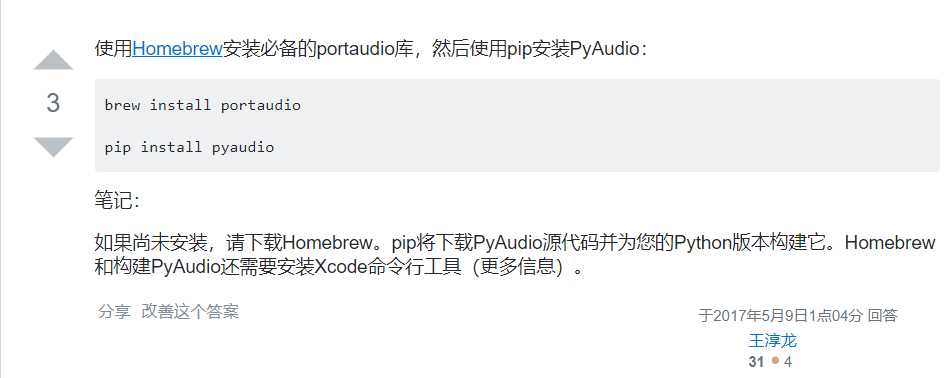
到这里就结束啦!
给个赞呗~
以上是关于本地录音调用百度语音识别接口的主要内容,如果未能解决你的问题,请参考以下文章