如何用python调用百度语音识别
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何用python调用百度语音识别相关的知识,希望对你有一定的参考价值。
1、首先需要打开百度AI语音系统,开始编写代码,如图所示,编写好回车。
2、然后接下来再试一下16k.pcm的音频,开始编写成功回车,如图所示的编写。
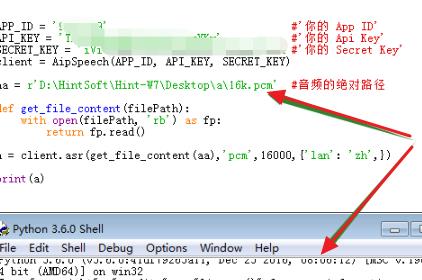
3、最后,查看音频c的属性,可以看到音频持续28秒,这样就是用python调用百度语音识别成功解决问题。
1、首先准备可供测试的音频,百度搜索“百度语音识别-开发文档”。

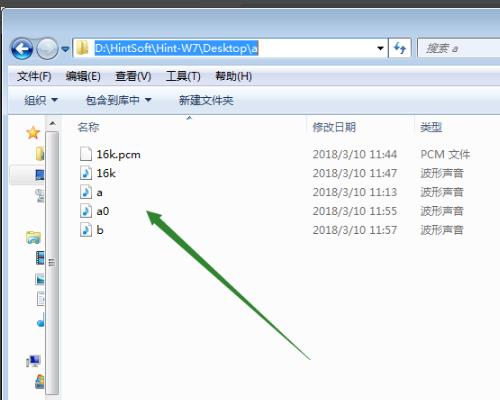
2、从上图网页把音频下载到本地的桌面的文件夹a里面。
3、python调用百度AI语音识别功能的代码,可以按照下面的步骤查看:百度AI开放平台——文档中心——语音识别——SDK文档——PythonSDk里面查看。
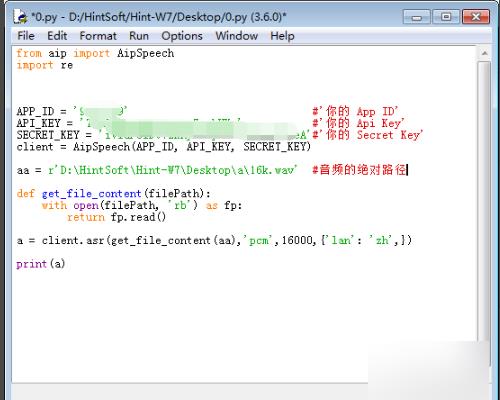
4、具体的python代码如下图所示。
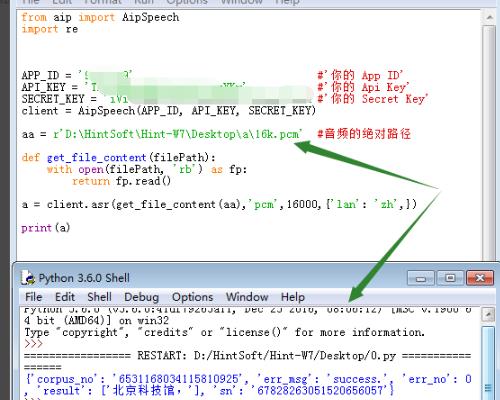
5、再试试16k.pcm,也成功了。
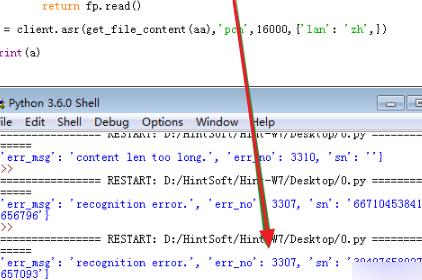
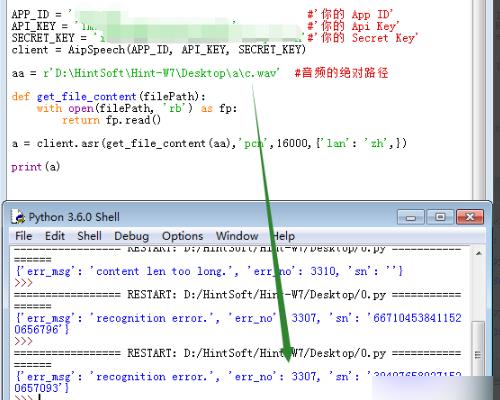
6、再截短音频b,得到c;查看音频c的属性,可以看到音频持续28秒,符合要求;然而还是测试失败。
用你的百度账号登录百度AI开放平台,进控制台,点击人工智能中任意一项
创建一个应用,获得APP_ID,API_KEY、SECRET_KEY

安装百度sdk
pip install baidu_aip
具体的开发文档,参见http://ai.baidu.com/docs#/ASR-Online-Python-SDK/top
代码如下:
给出一个可以解析的音频文件,http://bos.nj.bpc.baidu.com/v1/audio/8k.amr
目前支持的音频格式不多。。
from aip import AipSpeech
# 定义常量,此处替换为你自己的应用信息
APP_ID = 'your_app_id'
API_KEY = 'your_api_key'
SECRET_KEY = 'your_secret_key'
# 初始化AipSpeech对象
aipSpeech = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
# 读取文件
def get_file_content(filePath):
with open(filePath, 'rb') as fp:
return fp.read()
# 识别本地文件
#目前支持的格式较少,原始 PCM 的录音参数必须符合 8k/16k 采样率、16bit 位深、单声道,支持的格式有:pcm(不压缩)、wav(不压缩,pcm编码)、amr(压缩格式)。
result = aipSpeech.asr(get_file_content('C:\\Users\\wangjichong\\Desktop\\8k.amr'), 'amr', 8000,
'lan': 'zh',
)
print result['result'][0]
python调用百度语音(语音识别-斗地主语音记牌器)
一、概述
本篇简要介绍百度语音语音识别的基本使用(其实是斗地主时想弄个记牌器又没money,抓包什么的又不会,只好搞语音识别的了)
二、创建应用
打开百度语音官网,产品与使用->语音识别->立即使用->创建应用
出现如下页面

依照提示依次填写,最终结果
(ps:我就想弄个记牌的,就起了个计数器的名)
点右方的 ‘查看key’ 记下App ID,API Key,Secret Key。接下来要用到

需要安装模块 pip install baidu-aip pip install pyaudio
语音识别代码
from aip import AipSpeech """ 你的 APPID AK SK """ APP_ID = \'你记下的APP_ID\' API_KEY = \'你记下的API_KEY\' SECRET_KEY = \'你记下的SECRET_KEY\' client = AipSpeech(APP_ID, API_KEY, SECRET_KEY) # 读取文件 def get_file_content(filePath): with open(filePath, \'rb\') as fp: return fp.read() # 识别本地文件 li=client.asr(get_file_content(\'01.pcm\'), \'pcm\', 8000, { \'lan\': \'zh\', }) print(li) # 从URL获取文件识别 # client.asr(\'\', \'pcm\', 16000, { # \'url\': \'http://121.40.195.233/res/16k_test.pcm\', # \'callback\': \'http://xxx.com/receive\', # })
python录音代码
import wave from pyaudio import PyAudio,paInt16 framerate=8000 NUM_SAMPLES=2000 channels=1 sampwidth=2 TIME=2 def save_wave_file(filename,data): \'\'\'save the date to the wavfile\'\'\' wf=wave.open(filename,\'wb\') wf.setnchannels(channels) wf.setsampwidth(sampwidth) wf.setframerate(framerate) wf.writeframes(b"".join(data)) wf.close() def my_record(): pa=PyAudio() stream=pa.open(format = paInt16,channels=1, rate=framerate,input=True, frames_per_buffer=NUM_SAMPLES) my_buf=[] count=0 while count<TIME*5:#控制录音时间 string_audio_data = stream.read(NUM_SAMPLES) my_buf.append(string_audio_data) count+=1 print(\'.\') save_wave_file(\'01.pcm\',my_buf) stream.close() chunk=2014 def play(): wf=wave.open(r"01.pcm",\'rb\') p=PyAudio() stream=p.open(format=p.get_format_from_width(wf.getsampwidth()),channels= wf.getnchannels(),rate=wf.getframerate(),output=True) while True: data=wf.readframes(chunk) if data=="":break stream.write(data) stream.close() p.terminate() if __name__ == \'__main__\': my_record() print(\'Over!\') play()
效果如下图:

帮助文档:
三、后记
本代码未完全实现,有兴趣可自行整理,玩斗地主的时候声音可能要大点,因为识别有时候会报3001错误,音频质量过差,不过被打可别找我
以上是关于如何用python调用百度语音识别的主要内容,如果未能解决你的问题,请参考以下文章