安装关系型数据库MySQL 安装大数据处理框架Hadoop
Posted lys1894
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了安装关系型数据库MySQL 安装大数据处理框架Hadoop相关的知识,希望对你有一定的参考价值。
安装关系型数据库mysql 安装大数据处理框架Hadoop
简述Hadoop平台的起源、发展历史与应用现状。
列举发展过程中重要的事件、主要版本、主要厂商;
国内外Hadoop应用的典型案例。
(1)Hadoop的介绍:
Hadoop最早起源于Nutch,Nutch的设计目标是构建一个大型的全网搜索引擎,包括网页抓取、索引、查询等功能。但随着抓取网页数量的增加,遇到了严重的可扩展性问题——如何解决数十亿网页的存储和索引问题。2003年、2004年谷歌发表的两篇论文为该问题提供了可行的解决方案,即分布式文件系统(GFS),用于处理海量网页的存储。分布式计算框架MAPREDUCE,可用于处理海量网页的索引计算问题。Nutch的开发人员完成了相应的开源实现HDFS和MAPREDUCE,并从Nutch中剥离成为独立项目HADOOP,到2008年1月,HADOOP成为Apache顶级项目,迎来了它的快速发展期。狭义上来说,hadoop就是单独指代hadoop这个软件。广义上来说,hadoop指代大数据的一个生态圈,包括很多其他的软件
(2)Hadoop的起源:
2003-2004年,Google公布了部分GFS和MapReduce思想的细节,受此启发的Doug Cutting等人用2年的业余时间实现了DFS和MapReduce机制,使Nutch性能飙升,于是Yahoo招安Doug Gutting及其项目。
2005年,Hadoop作为Lucene的子项目Nutch的一部分正式引入Apache基金会。
2006年2月被分离出来,成为一套完整独立的软件,起名为Hadoop。Hadoop名字不是一个缩写,而是一个生造出来的词。是Hadoop之父Doug Cutting儿子毛绒玩具象命名的。
(3)Hadoop的发展史:
2004年—最初的版本(现在称为HDFS和MapReduce)由Doug Cutting和Mike Cafarella开始实施。
2005年12月—Nutch移植到新的框架,Hadoop在20个节点上稳定运行。
2006年1月—Doug Cutting加入雅虎。
2006年2月—Apache Hadoop项目正式启动以支持MapReduce和HDFS的独立发展。
2006年2月—雅虎的网格计算团队采用Hadoop。
2006年4月—标准排序(10 GB每个节点)在188个节点上运行47.9个小时。
2006年5月—雅虎建立了一个300个节点的Hadoop研究集群。
2006年5月—标准排序在500个节点上运行42个小时(硬件配置比4月的更好)。
2006年11月—研究集群增加到600个节点。
2006年12月—标准排序在20个节点上运行1.8个小时,100个节点3.3小时,500个节点5.2小时,900个节点7.8个小时。
2007年1月—研究集群到达900个节点。
2007年4月—研究集群达到两个1000个节点的集群。
2008年4月—赢得世界最快1TB数据排序在900个节点上用时209秒。
2008年7月—雅虎测试节点增加到4000个
2008年9月—Hive成为Hadoop的子项目
2008年11月—Google宣布其MapReduce用68秒对1TB的程序进行排序
2008年10月—研究集群每天装载10TB的数据。
2008年—淘宝开始投入研究基于Hadoop的系统–云梯。云梯总容量约9.3PB,共有1100台机器,每天处理18000道作业,扫描500TB数据。
2009年3月—17个集群总共24 000台机器。
2009年3月—Cloudera推出CDH(Cloudera‘s Dsitribution Including Apache Hadoop)。
2009年4月—赢得每分钟排序,雅虎59秒内排序500GB(在1400个节点上)和173分钟内排序100TB数据(在3400个节点上)。
2009年5月—Yahoo的团队使用Hadoop对1 TB的数据进行排序只花了62秒时间。
2009年7月—Hadoop Core项目更名为Hadoop Common。
2009年7月—MapReduce和Hadoop Distributed File System(HDFS)成为Hadoop项目的独立子项目。
2009年7月—Avro和Chukwa成为Hadoop新的子项目。
2009年9月—亚联BI团队开始跟踪研究Hadoop。
2009年12月—亚联提出橘云战略,开始研究Hadoop。
2010年5月—Avro脱离Hadoop项目,成为Apache顶级项目。
2010年5月—HBase脱离Hadoop项目,成为Apache顶级项目。
2010年5月—IBM提供了基于Hadoop 的大数据分析软件——InfoSphere BigInsights,包括基础版和企业版。
2010年9月—Hive( Facebook) 脱离Hadoop,成为Apache顶级项目。
2010年9月—Pig脱离Hadoop,成为Apache顶级项目。
2011年1月—ZooKeeper脱离Hadoop,成为Apache顶级项目。
2011年3月—Apache Hadoop获得Media Guardian Innovation Awards 。
2011年3月—Platform Computing宣布在它的Symphony软件中支持Hadoop MapReduce API。
2011年5月—Mapr Technologies公司推出分布式文件系统和MapReduce引擎——MapR Distribution for Apache Hadoop。
2011年5月—HCatalog 1.0发布。该项目由Hortonworks 在2010年3月份提出,HCatalog主要用于解决数据存储、元数据的问题,主要解决HDFS的瓶颈,它提供了一个地方来存储数据的状态信息,这使得数据清理和归档工具可以很容易的进行处理。
2011年4月— SGI( Silicon Graphics International )基于SGI Rackable和CloudRack服务器产品线提供Hadoop优化的解决方案。
2011年5月— EMC为客户推出一种新的基于开源Hadoop解决方案的数据中心设备——GreenPlum HD,以助其满足客户日益增长的数据分析需求并加快利用开源数据分析软件。Greenplum是EMC在2010年7月收购的一家开源数据仓库公司。
2011年5月— 在收购了Engenio之后,NetApp推出与Hadoop应用结合的产品E5400存储系统。
2011年6月— Calxeda公司(之前公司的名字是Smooth-Stone)发起了"开拓者行动",一个由10家软件公司组成的团队将为基于Calxeda即将推出的ARM系统上芯片设计的服务器提供支持,并为Hadoop提供低功耗服务器技术。
2011年6月— 数据集成供应商Informatica发布了其旗舰产品,产品设计初衷是处理当今事务和社会媒体所产生的海量数据,同时支持Hadoop。
2011年7月— Yahoo!和硅谷风险投资公司Benchmark Capital创建了Hortonworks公司,旨在让Hadoop更加鲁棒(可靠),并让企业用户更容易安装、管理和使用Hadoop。
2011年8月— Cloudera公布了一项有益于合作伙伴生态系统的计划——创建一个生态系统,以便硬件供应商、软件供应商以及系统集成商可以一起探索如何使用Hadoop更好的洞察数据。
2011年8月— Dell与Cloudera联合推出Hadoop解决方案——Cloudera Enterprise。Cloudera Enterprise基于Dell PowerEdge C2100机架服务器以及Dell PowerConnect 6248以太网交换机
(4)Hadoop三大公司发型版本介绍:
A.免费开源版本apache:http://hadoop.apache.org/ 。
优点:拥有全世界的开源贡献者,代码更新迭代版本比较快。
缺点:版本的升级,版本的维护,版本的兼容性,版本的补丁都可能考虑不太周到,学习可以用,实际生产工作环境尽量不要使用。
apache所有软件的下载地址(包括各种历史版本):
http://archive.apache.org/dist/ 。
B.免费开源版本hortonWorks:https://hortonworks.com/ 。
hortonworks主要是雅虎主导Hadoop开发的副总裁,带领二十几个核心成员成立Hortonworks,核心产品软件HDP(ambari),HDF免费开源,并且提供一整套的web管理界面,供我们可以通过web界面管理我们的集群状态,web管理界面软件HDF网址(http://ambari.apache.org/)。
C.软件收费版本ClouderaManager:https://www.cloudera.com/ 。
cloudera主要是美国一家大数据公司在apache开源hadoop的版本上,通过自己公司内部的各种补丁,实现版本之间的稳定运行,大数据生态圈的各个版本的软件都提供了对应的版本,解决了版本的升级困难,版本兼容性等各种问题,生产环境强烈推荐使用。
(5)Hadoop的四大特性:
A.扩容能力(Scalable):Hadoop是在可用的计算机集群间分配数据并完成计算任务的,这些集群可用方便的扩展到数以千计个节点中。
B.成本低(Economical):Hadoop通过普通廉价的机器组成服务器集群来分发以及处理数据,以至于成本很低。
C.高效率(Efficient):通过并发数据,Hadoop可以在节点之间动态并行的移动数据,使得速度非常快。
D.可靠性(Rellable):能自动维护数据的多份复制,并且在任务失败后能自动地重新部署(redeploy)计算任务。所以Hadoop的按位存储和处理数据的能力值得人们信赖。
(6)国内外Hadoop应用典型案例:
Hadoop应用案例1-全球最大超市业者 Wal-Mart:
Wal-Mart分析顾客商品搜索行为,找出超越竞争对手的商机。
全球最大连锁超市Wal-Mart利用Hadoop来分析顾客搜寻商品的行为,以及用户透过搜索引擎寻找到Wal-Mart网站的关键词,利用这些关键词的分析结果发掘顾客需求,以规画下一季商品的促销策略,甚至打算分析顾客在Facebook、Twitter等社交网站上对商品的讨论,期望能比竞争对手提前一步发现顾客需求。Wal-Mart虽然十年前就投入在线电子商务,但在线销售的营收远远落后于Amazon。后来,Wal-Mart决定采用Hadoop来分析顾客搜寻商品的行为,以及用户透过搜索引擎寻找到Wal-Mart网站的关键词,利用这些关键词的分析结果发掘顾客需求,以规画下一季商品的促销策略。他们并进一步打算要分析顾客在Facebook、Twitter等社交网站上对商品的讨论,甚至Wal-Mart能比父亲更快知道女儿怀孕的消息,并且主动寄送相关商品的促销邮件,可说是比竞争对手提前一步发现顾客。
Hadoop应用案例2-全球最大拍卖网站 eBay:
eBay用Hadoop拆解非结构性巨量数据,降低数据仓储负载。
经营拍卖业务的eBay则是用Hadoop来分析买卖双方在网站上的行为。eBay拥有全世界最大的数据仓储系统,每天增加的数据量有50TB,光是储存就是一大挑战,更遑论要分析这些数据,而且更困难的挑战是这些数据报括了结构化的数据和非结构化的数据,如照片、影片、电子邮件、用户的网站浏览Log记录等。eBay是全球最大的拍卖网站,8千万名用户每天产生的数据量就达到50TB,相当于五天就增加了1座美国国会图书馆的数据量。这些数据报括了结构化的数据,和非结构化的数据如照片、影片、电子邮件、用户的网站浏览Log记录等。eBay正是用Hadoop来解决同时要分析大量结构化数据和非结构化的难题。eBay分析平台高级总监Oliver Ratzesberger也坦言,大数据分析最大的挑战就是要同时处理结构化以及非结构化的数据。eBay在5年多前就另外建置了一个软硬件整合的平台Singularity,搭配压缩技术来解决结构化数据和半结构化数据分析问题,3年前更在这个平台整合了Hadoop来处理非结构化数据,透过Hadoop来进行数据预先处理,将大块结构的非结构化数据拆解成小型数据,再放入数据仓储系统的数据模型中分析,来加快分析速度,也减轻对数据仓储系统的分析负载。
Hadoop应用案例3-全球最大信用卡公司 Visa:
Visa快速发现可疑交易,1个月分析时间缩短成13分钟。
Visa公司则是拥有一个全球最大的付费网络系统VisaNet,作为信用卡付款验证之用。2009年时,每天就要处理1.3亿次授权交易和140万台ATM的联机存取。为了降低信用卡各种诈骗、盗领事件的损失,Visa公司得分析每一笔事务数据,来找出可疑的交易。虽然每笔交易的数据记录只有短短200位,但每天VisaNet要处理全球上亿笔交易,2年累积的资料多达36TB,过去光是要分析5亿个用户账号之间的关联,得等1个月才能得到结果,所以,Visa也在2009年时导入了Hadoop,建置了2套Hadoop丛集(每套不到50个节点),让分析时间从1个月缩短到13分钟,更快速地找出了可疑交易,也能更快对银行提出预警,甚至能及时阻止诈骗交易。这套被众多企业赖以解决大数据难题的分布式计算技术,并不是一项全新的技术,早在2006年就出现了,而且Hadoop的核心技术原理,更是源自Google打造搜索引擎的关键技术,后来由Yahoo支持的开源开发团队发展成一套Hadoop分布式计算平台,也成为Yahoo内部打造搜索引擎的关键技术。
(6)应用现状
国外:
Yahoo
Yahoo是Hadoop的最大支持者,截至2012年,Yahoo的Hadoop机器总节点数目超过420000个,有超过10万的核心CPU在运行Hadoop。最大的一个单Master节点集群有4500个节点(每个节点双路4核心CPUboxesw,4×1TB磁盘,16GBRAM)。总的集群存储容量大于350PB,每月提交的作业数目超过1000万个,在Pig中超过60%的Hadoop作业是使用Pig编写提交的。
Yahoo的Hadoop应用主要包括以下几个方面:
支持广告系统
用户行为分析
支持Web搜索
反垃圾邮件系统
会员反滥用
内容敏捷
个性化推荐
同时Pig研究并测试支持超大规模节点集群的Hadoop系统。
Facebook:
Facebook使用Hadoop存储内部日志与多维数据,并以此作为报告、分析和机器学习的数据源。目前Hadoop集群的机器节点超过1400台,共计11?200个核心CPU,超过15PB原始存储容量,每个商用机器节点配置了8核CPU,12TB数据存储,主要使用StreamingAPI和JavaAPI编程接口。Facebook同时在Hadoop基础上建立了一个名为Hive的高级数据仓库框架,Hive已经正式成为基于Hadoop的Apache一级项目。此外,还开发了HDFS上的FUSE实现。
A9.com:
A9.com为Amazon使用Hadoop构建了商品搜索索引,主要使用StreamingAPI以及C++、Perl和Python工具,同时使用Java和StreamingAPI分析处理每日数以百万计的会话。A9.com为Amazon构建的索引服务运行在100节点左右的Hadoop集群上。
EBay:
单集群超过532节点集群,单节点8核心CPU,容量超过5.3PB存储。大量使用的MapReduce的Java接口、Pig、Hive来处理大规模的数据,还使用HBase进行搜索优化和研究。
IBM:
IBM蓝云也利用Hadoop来构建云基础设施。IBM蓝云使用的技术包括:Xen和PowerVM虚拟化的Linux操作系统映像及Hadoop并行工作量调度,并发布了自己的Hadoop发行版及大数据解决方案。
国内:
百度:
百度在2006年就开始关注Hadoop并开始调研和使用,在2012年其总的集群规模达到近十个,单集群超过2800台机器节点,Hadoop机器总数有上万台机器,总的存储容量超过100PB,已经使用的超过74PB,每天提交的作业数目有数千个之多,每天的输入数据量已经超过7500TB,输出超过1700TB。
百度的Hadoop集群为整个公司的数据团队、大搜索团队、社区产品团队、广告团队,以及LBS团体提供统一的计算和存储服务,主要应用包括:
数据挖掘与分析。
日志分析平台。
数据仓库系统。
推荐引擎系统。
用户行为分析系统。
同时百度在Hadoop的基础上还开发了自己的日志分析平台、数据仓库系统,以及统一的C++编程接口,并对Hadoop进行深度改造,开发了HadoopC++扩展HCE系统。
阿里巴巴:
阿里巴巴的Hadoop集群截至2012年大约有3200台服务器,大约30?000物理CPU核心,总内存100TB,总的存储容量超过60PB,每天的作业数目超过150?000个,每天hivequery查询大于6000个,每天扫描数据量约为7.5PB,每天扫描文件数约为4亿,存储利用率大约为80%,CPU利用率平均为65%,峰值可以达到80%。阿里巴巴的Hadoop集群拥有150个用户组、4500个集群用户,为淘宝、天猫、一淘、聚划算、CBU、支付宝提供底层的基础计算和存储服务,主要应用包括:
数据平台系统。
搜索支撑。
广告系统。
数据魔方。
量子统计。
淘数据。
推荐引擎系统。
搜索排行榜。
为了便于开发,其还开发了WebIDE继承开发环境,使用的相关系统包括:Hive、Pig、Mahout、Hbase等。
腾讯:
腾讯也是使用Hadoop最早的中国互联网公司之一,截至2012年年底,腾讯的Hadoop集群机器总量超过5000台,最大单集群约为2000个节点,并利用Hadoop-Hive构建了自己的数据仓库系统TDW,同时还开发了自己的TDW-IDE基础开发环境。腾讯的Hadoop为腾讯各个产品线提供基础云计算和云存储服务
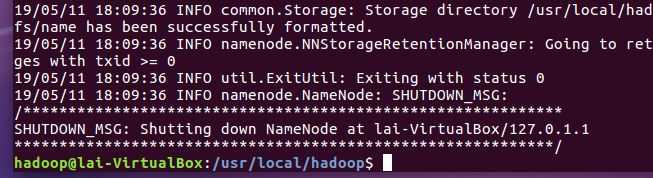
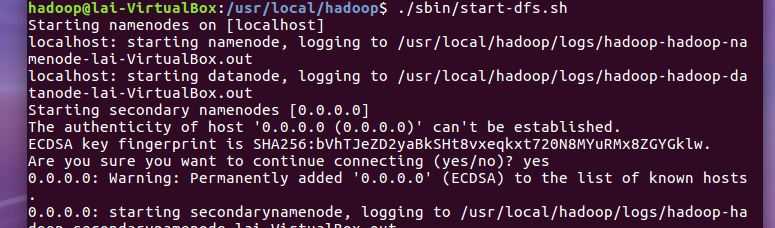
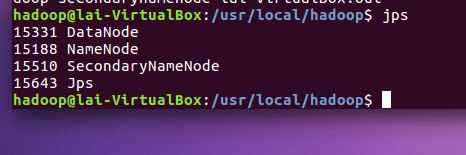
5. 下次上课之前,必须成功完成Hadoop的安装与配置。上截图。

以上是关于安装关系型数据库MySQL 安装大数据处理框架Hadoop的主要内容,如果未能解决你的问题,请参考以下文章